マネージド障害復旧
このドキュメントでは、BigQuery のマネージド障害復旧の概要と、データやワークロード用に障害復旧を実装する方法について説明します。
概要
BigQuery は、リージョン全体が停止した場合の障害復旧シナリオに対応しています。BigQuery の障害復旧では、クロスリージョン データセット レプリケーションによってストレージのフェイルオーバーが管理されます。ユーザーはセカンダリ リージョンでデータセット レプリカを作成した後、コンピューティングとストレージのフェイルオーバー動作を設定することにより、リージョンの停止中もビジネスの継続性を維持できます。フェイルオーバーの後は、昇格したリージョンでコンピューティング容量(スロット)とレプリケーションされたデータセットにアクセスできます。障害復旧は Enterprise Plus エディションでのみご利用いただけます。
マネージド障害復旧では、フェイルオーバーが開始されるとハード フェイルオーバーが実行されます。ハード フェイルオーバーでは、以前のプライマリ リージョンがダウンしていても、レプリケーションが完了していないデータのレプリケーションを待たずに、セカンダリ リージョン内の予約とデータセット レプリカがすぐにプライマリに昇格するため、データ損失が発生する可能性があります。レプリカの replication_time 値より前にソースリージョンでデータを commit したジョブは、フェイルオーバー後に宛先リージョンでの再実行が必要となる場合があります。
障害復旧を有効にするには、フェイルオーバーの前にデータセットが存在していたリージョン(プライマリ リージョン)で Enterprise Plus エディションの予約を作成する必要があります。ペアに設定されたリージョンのスタンバイ コンピューティング容量は、Enterprise Plus 予約に含まれます。この予約にデータセットを接続すると、そのデータセットでフェイルオーバーが有効になります。データセットを予約に接続できるのは、そのデータセットがバックフィルされ、プライマリとセカンダリのロケーション ペアが予約と同じである場合だけです。データセットがフェイルオーバー予約に接続された後は、Enterprise Plus 予約だけがそのデータセットに対して書き込みを行えます。そのデータセットに対するクロスリージョン レプリケーション昇格はできません。フェイルオーバー予約に接続されたデータセットからの読み取りは、どの容量モデルでも行えます。予約の詳細については、ワークロード管理の概要をご覧ください。
フェイルオーバーの後は、プライマリ リージョンのコンピューティング容量がセカンダリ リージョンですぐに使用可能になります。この容量は、使用されているかどうかにかかわらず、予約のベースラインに適用されます。
テストの一環として行う場合や、実際の障害に対応する場合は、積極的にフェイルオーバーする必要がありますが、10 分間に 1 回を超える頻度ではフェイルオーバーしないでください。データ レプリケーションのシナリオにおいて、バックフィルとは、データセットのレプリカが作成される前またはアクティブになる前に存在していた過去のデータをレプリカに入力するプロセスを指します。データセットにフェイルオーバーする前に、そのデータセットのバックフィルを完了する必要があります。
次の図は、マネージド障害復旧のアーキテクチャを示しています。
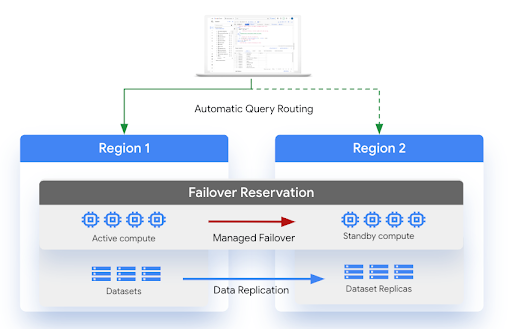
制限事項
BigQuery の障害復旧には次の制限事項が適用されます。
BigQuery の障害復旧には、クロスリージョン データセット レプリケーションと同じ制限事項が適用されます。
フェイルオーバー後の自動スケーリングには、セカンダリ リージョンで使用可能なコンピューティング容量が利用されます。セカンダリ リージョンで使用できるのは予約ベースラインのみです。
INFORMATION_SCHEMA.RESERVATIONSビューには、フェイルオーバーの詳細が含まれません。同じ管理プロジェクトで複数のフェイルオーバー予約を使用し、それぞれに接続されているデータセットが異なるセカンダリ ロケーションを使用している場合は、別のフェイルオーバー予約に接続されているデータセットをフェイルオーバー予約で使用しないでください。
既存の予約をフェイルオーバー予約に変換する場合は、既存の予約に存在する予約割り当てが 1,000 件以下である必要があります。
フェイルオーバー予約に接続できるデータセットは 1,000 件以下です。
ロケーション
フェイルオーバー予約を作成するときは、次のリージョンを選択できます。
| ロケーション コード | リージョン名 | リージョンの説明 |
|---|---|---|
ASIA |
||
ASIA-EAST1 |
台湾 | |
ASIA-SOUTHEAST1 |
シンガポール | |
AU |
||
AUSTRALIA-SOUTHEAST1 |
シドニー | |
AUSTRALIA-SOUTHEAST2 |
メルボルン | |
CA |
||
NORTHAMERICA-NORTHEAST1 |
モントリオール | |
NORTHAMERICA-NORTHEAST2 |
トロント | |
EU |
||
EU |
EU(マルチリージョン) | |
EUROPE-CENTRAL2 |
ワルシャワ | |
EUROPE-NORTH1 |
フィンランド | |
EUROPE-SOUTHWEST1 |
マドリッド | |
EUROPE-WEST1 |
ベルギー | |
EUROPE-WEST3 |
フランクフルト | |
EUROPE-WEST4 |
オランダ | |
EUROPE-WEST8 |
ミラノ | |
EUROPE-WEST9 |
パリ | |
IN |
||
ASIA-SOUTH1 |
ムンバイ | |
ASIA-SOUTH2 |
デリー | |
US |
||
US |
米国(マルチリージョン) | |
US-CENTRAL1 |
アイオワ | |
US-EAST1 |
サウスカロライナ | |
US-EAST4 |
北バージニア | |
US-EAST5 |
コロンバス | |
US-SOUTH1 |
ダラス | |
US-WEST1 |
オレゴン | |
US-WEST2 |
ロサンゼルス | |
US-WEST3 |
ソルトレイクシティ | |
US-WEST4 |
ラスベガス |
リージョンペアは、ASIA、AU、CA、EU、IN、US 内で選択する必要があります。たとえば、US 内のリージョンを EU 内のリージョンとペアにすることはできません。
BigQuery データセットがマルチリージョン ロケーションにある場合、次のリージョンペアは使用できません。この制限により、レプリケーション後にフェイルオーバー予約とデータが地理的に分離されます。マルチリージョンに含まれているリージョンの詳細については、マルチリージョンをご覧ください。
us-central1-usマルチリージョンus-west1-usマルチリージョンeu-west1-euマルチリージョンeu-west4-euマルチリージョン
始める前に
- 予約の更新に必要な
bigquery.reservations.updateIdentity and Access Management(IAM)権限があることを確認します。 - レプリケーション用に構成された既存のデータセットがあることを確認します。詳細については、データセットをレプリケーションするをご覧ください。
ターボ レプリケーション
障害復旧では、ターボ レプリケーションを使用してリージョン間のデータ レプリケーションを高速化します。これにより、データ損失のリスクが軽減され、サービス ダウンタイムが最小限に抑えられ、リージョンで障害が発生した後も中断なくサービスを提供できるよう支援できます。
ターボ レプリケーションは、最初のバックフィル オペレーションには適用されません。最初のバックフィル オペレーションが完了した後で、帯域幅割り当てを超えておらず、ユーザーエラーがなければ、ターボ レプリケーションでは、15 分以内にセカンダリ レプリカを使用して、単一のフェイルオーバー リージョンペアにデータセットをレプリケーションするよう設計されています。
目標復旧時間
目標復旧時間(RTO)は、障害が発生した場合に BigQuery で復旧にかかる時間として許容できる目標時間です。RTO の詳細については、DR 計画の基本をご覧ください。マネージド障害復旧では、フェイルオーバーを開始した後の RTO は 5 分です。RTO により、フェイルオーバー プロセスの開始から 5 分以内にセカンダリ リージョンで容量を使用できるようになります。
目標復旧時点
目標復旧時点(RPO)は、データを復元できる最新の時点です。RPO の詳細については、DR 計画の基本をご覧ください。マネージド障害復旧では、データセットごとに RPO が定義されます。RPO は、セカンダリ レプリカをプライマリから 15 分以内に確保することを目標としています。この RPO を達成するには、帯域幅割り当てを超えないようにし、かつユーザーエラーが発生しないようにする必要があります。
割り当て
フェイルオーバー予約を構成する前に、セカンダリ リージョンで選択したコンピューティング容量を確保する必要があります。セカンダリ リージョンで利用可能な割り当てがない場合は、予約を構成できません。詳細については、割り当てと上限をご覧ください。
ターボ レプリケーションの帯域幅には割り当てがあります。詳細については、割り当てと上限をご覧ください。
料金
マネージド障害復旧を構成するには、次の料金プランが必要です。
コンピューティング容量: Enterprise Plus エディションを購入する必要があります。
ターボ レプリケーション: 障害復旧は、レプリケーション中にターボ レプリケーションを利用します。課金は、物理バイト数とレプリケーションされた物理 GiB 数に基づいて行われます。詳細については、ターボ レプリケーションのデータ レプリケーションのデータ転送料金をご覧ください。
ストレージ: セカンダリ リージョンのストレージ バイトには、プライマリ リージョンのストレージ バイトと同じ料金が請求されます。詳細については、ストレージの料金をご覧ください。
コンピューティング容量の料金が請求されるのは、プライマリ リージョンの容量に対してのみです。セカンダリ リージョンでは、(予約ベースラインに基づく)セカンダリ コンピューティング容量を追加料金なしで使用できます。予約がフェイルオーバーされていない限り、アイドル スロットはセカンダリ コンピューティング容量を使用できません。
セカンダリ リージョンでステイル読み取りを行う必要がある場合は、追加のコンピューティング容量を購入する必要があります。
Enterprise Plus 予約を作成または変更する
データセットを予約に接続する前に、Enterprise Plus 予約を作成するか、既存の予約を変更して障害復旧用に構成する必要があります。
予約を作成する
次のいずれかの方法を選択します。
コンソール
Google Cloud コンソールで、[BigQuery] ページに移動します。
ナビゲーション メニューで、[容量管理]、[予約を作成] の順にクリックします。
[予約名] フィールドに、予約の名前を入力します。
[場所] リストで、ロケーションを選択します。
[エディション] リストで、Enterprise Plus エディションを選択します。
[最大予約サイズ セレクタ] リストで、最大予約サイズを選択します。
省略可: [ベースライン スロット数] フィールドに、予約用のベースライン スロット数を入力します。
使用可能な自動スケーリング スロットの数は、[最大予約サイズ セレクタ] の値から [ベースライン スロット数] の値を引いた数になります。たとえば、ベースライン スロットを 100 個、最大予約サイズを 400 個として予約を作成した場合、その予約には 300 個の自動スケーリング スロットがあります。ベースライン スロットの詳細については、ベースライン スロットと自動スケーリング スロットとともに予約を使用するをご覧ください。
[セカンダリ ロケーション] リストで、セカンダリ ロケーションを選択します。
アイドル スロットの共有を無効にして、指定したスロット容量のみを使用するには、[アイドル スロットを無視する] トグルをクリックします。
[詳細設定] セクションを開くには、 展開矢印をクリックします。
省略可: ターゲット ジョブの同時実行を設定するには、[自動のターゲット ジョブ同時実行をオーバーライドする] トグルをクリックしてオンに切り替えた後、[ターゲット ジョブ同時実行] の値を入力します。スロットの内訳が [費用予測] テーブルに表示され、予約の概要が [容量の概要] テーブルに表示されます。
[保存] をクリックします。
新しい予約が [スロットの予約] タブに表示されます。
SQL
予約を作成するには、データ定義言語(DDL)ステートメントの CREATE RESERVATION を使用します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
CREATE RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` OPTIONS ( slot_capacity = NUMBER_OF_BASELINE_SLOTS, edition = ENTERPRISE_PLUS, secondary_location = SECONDARY_LOCATION);
次のように置き換えます。
ADMIN_PROJECT_ID: 予約リソースを所有する管理プロジェクトのプロジェクト ID。LOCATION: 予約のロケーション。BigQuery Omni のロケーションを選択した場合、エディション オプションは Enterprise エディションに限定されます。RESERVATION_NAME: 予約の名前。名前に使用できるのは英小文字、数字、ダッシュのみです。先頭と末尾は英小文字または数字にしてください。
NUMBER_OF_BASELINE_SLOTS: 予約に割り当てるベースライン スロットの数。slot_capacityオプションとeditionオプションを同じ予約内で設定することはできません。SECONDARY_LOCATION: 予約のセカンダリ ロケーション。リージョンが停止した場合は、この予約に接続されているすべてのデータセットがこのロケーションにフェイルオーバーします。
[実行] をクリックします。
クエリの実行方法の詳細については、インタラクティブ クエリを実行するをご覧ください。
既存の予約を変更する
次のいずれかの方法を選択します。
コンソール
Google Cloud コンソールで、[BigQuery] ページに移動します。
ナビゲーション メニューで、[容量管理] をクリックします。
[スロットの予約] タブをクリックします。
更新する予約を探します。
[ 予約アクション] をクリックしてから、[編集] をクリックします。
[セカンダリ ロケーション] フィールドに、セカンダリ ロケーションを入力します。
[保存] をクリックします。
SQL
予約のセカンダリ ロケーションを追加または変更するには、DDL ステートメントの ALTER RESERVATION SET OPTIONS を使用します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( secondary_location = SECONDARY_LOCATION);
次のように置き換えます。
[実行] をクリックします。
クエリの実行方法の詳細については、インタラクティブ クエリを実行するをご覧ください。
データセットを予約に接続する
以前に作成した予約で障害復旧を有効にする手順は以下のとおりです。予約と同じプライマリ リージョンとセカンダリ リージョンで、データセットがレプリケーション用に構成されている必要があります。詳細については、クロスリージョン データセット レプリケーションをご覧ください。
コンソール
Google Cloud コンソールで、[BigQuery] ページに移動します。
ナビゲーション メニューで [容量管理] をクリックし、[スロットの予約] タブをクリックします。
データセットを接続する予約をクリックします。
[障害復旧] タブをクリックします。
[フェイルオーバー データセットを追加] をクリックします。
予約に関連付けるデータセットの名前を入力します。
[追加] をクリックします。
SQL
データセットを予約に接続するには、DDL ステートメントの ALTER SCHEMA SET OPTIONS を使用します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = ADMIN_PROJECT_ID.RESERVATION_NAME);
次のように置き換えます。
DATASET_NAME: データセットの名前。ADMIN_PROJECT_ID.RESERVATION_NAME: データセットを関連付ける予約の名前。
[実行] をクリックします。
クエリの実行方法については、インタラクティブ クエリを実行するをご覧ください。
データセットの予約を解除する
予約によりデータセットのフェイルオーバー動作の管理を停止するには、データセットの予約を解除します。これにより、データセットの現在のプライマリ レプリカが変更されたり、既存のデータセット レプリカが削除されることはありません。データセットの予約解除後にデータセット レプリカを削除する方法については、データセットのレプリカを削除するをご覧ください。
コンソール
Google Cloud コンソールで、[BigQuery] ページに移動します。
ナビゲーション メニューで [容量管理] をクリックし、[スロットの予約] タブをクリックします。
データセットを解除する予約をクリックします。
[障害復旧] タブをクリックします。
データセットのプライマリ レプリカの アクション オプションを開きます。
[削除] をクリックします。
SQL
データセットの予約を解除するには、DDL ステートメントの ALTER SCHEMA SET OPTIONS を使用します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = NULL);
次のように置き換えます。
DATASET_NAME: データセットの名前。
[実行] をクリックします。
クエリの実行方法の詳細については、インタラクティブ クエリを実行するをご覧ください。
フェイルオーバーを開始する
リージョンが停止した場合は、レプリカが使用するロケーションに予約を手動でフェイルオーバーする必要があります。予約をフェイルオーバーすると、関連するデータセットもフェイルオーバーされます。予約を手動でフェイルオーバーする手順は以下のとおりです。
コンソール
Google Cloud コンソールで、[BigQuery] ページに移動します。
ナビゲーション メニューで、[障害復旧] をクリックします。
フェイルオーバーする予約の名前をクリックします。
[フェイルオーバー] をクリックします。
SQL
予約のセカンダリ ロケーションを追加または変更するには、DDL ステートメントの ALTER RESERVATION SET OPTIONS を使用して is_primary を TRUE に設定します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( is_primary = TRUE);
次のように置き換えます。
[実行] をクリックします。
クエリの実行方法の詳細については、インタラクティブ クエリを実行するをご覧ください。
モニタリング
レプリカの状態を判断するには、INFORMATION_SCHEMA.SCHEMATA_REPLICAS ビューに対してクエリを実行します。例:
SELECT schema_name, replica_name, creation_complete, replica_primary_assigned, replica_primary_assignment_complete FROM `region-LOCATION`.INFORMATION_SCHEMA.SCHEMATA_REPLICAS WHERE schema_name="my_dataset"
次のクエリを実行すると、過去 7 日間のジョブのうち、データセットがフェイルオーバー データセットだった場合に失敗するジョブが返されます。
WITH non_epe_reservations AS ( SELECT project_id, reservation_name FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.RESERVATIONS WHERE edition != 'ENTERPRISE_PLUS' ) SELECT * FROM ( SELECT job_id FROM ( SELECT job_id, reservation_id, ARRAY_CONCAT(referenced_tables, [destination_table]) AS all_referenced_tables, query FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.JOBS WHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP() ) A, UNNEST(all_referenced_tables) AS referenced_table ) jobs LEFT OUTER JOIN non_epe_reservations ON ( jobs.reservation_id = CONCAT( non_epe_reservations.project_id, ':', 'LOCATION', '.', non_epe_reservations.reservation_name)) WHERE CONCAT(jobs.project_id, ':', jobs.dataset_id) IN UNNEST( [ 'PROJECT_ID:DATASET_ID', 'PROJECT_ID:DATASET_ID']);
次のように置き換えます。
PROJECT_ID: プロジェクト ID。DATASET_ID: データセット ID。LOCATION: ロケーション。
次のステップ
クロスリージョン データセット レプリケーションの詳細を確認します。
信頼性の詳細を確認します。