Neste tutorial, mostramos como importar um modelo Open Neural Network Exchange (ONNX) treinado com scikit-learn. Você importa o modelo para um conjunto de dados do BigQuery e o usa para fazer previsões com uma consulta SQL.
O ONNX fornece um formato uniforme projetado para representar qualquer framework de machine learning (ML). Com o suporte do BigQuery ML para ONNX, você pode fazer o seguinte:
- Treine um modelo usando seu framework favorito.
- Converta o modelo no formato ONNX.
- Importe o modelo ONNX para o BigQuery e faça previsões usando o BigQuery ML.
Objetivos
- Crie e treine um modelo usando o scikit-learn.
- Converta o modelo para o formato ONNX usando sklearn-onnx.
- Use a instrução
CREATE MODELpara importar o modelo ONNX para o BigQuery. - Use a função
ML.PREDICTpara fazer previsões com o modelo ONNX importado.
Custos
Neste documento, você vai usar os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Ao concluir as tarefas descritas neste documento, é possível evitar o faturamento contínuo excluindo os recursos criados. Para mais informações, consulte Limpeza.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and Cloud Storage APIs.
- Verifique se você tem as permissões necessárias para realizar as tarefas neste documento.
- BigQuery Studio Admin (
roles/bigquery.studioAdmin) - Storage Object Creator (
roles/storage.objectCreator) -
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
-
In the Google Cloud console, go to the IAM page.
Acessar o IAM - Selecione o projeto.
- Clique em Conceder acesso.
-
No campo Novos principais, digite seu identificador de usuário. Normalmente, é o endereço de e-mail de uma Conta do Google.
- Na lista Selecionar papel, escolha um.
- Para conceder outros papéis, clique em Adicionar outro papel e adicione cada papel adicional.
- Clique em Salvar.
- Crie um bucket do Cloud Storage para armazenar o modelo.
- Faça upload do modelo ONNX para seu bucket do Cloud Storage.
No console do Google Cloud , acesse a página BigQuery.
No painel Explorer, clique no nome do seu projeto.
Clique em Conferir ações > Criar conjunto de dados.
Na página Criar conjunto de dados, faça o seguinte:
Para o código do conjunto de dados, insira
bqml_tutorial.Em Tipo de local, selecione Multirregião e EUA (várias regiões nos Estados Unidos).
Mantenha as configurações padrão restantes e clique em Criar conjunto de dados.
Crie um conjunto de dados chamado
bqml_tutorialcom o local dos dados definido comoUSe uma descrição deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Em vez de usar a flag
--dataset, o comando usa o atalho-d. Se você omitir-de--dataset, o comando vai criar um conjunto de dados por padrão.Confirme se o conjunto de dados foi criado:
bq lsNo console do Google Cloud , acesse a página BigQuery Studio.
No editor de consultas, insira a seguinte instrução
CREATE MODEL.CREATE OR REPLACE MODEL `bqml_tutorial.imported_onnx_model` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='BUCKET_PATH')
Substitua
BUCKET_PATHpelo caminho para o modelo que você fez upload para o Cloud Storage. Se você estiver usando o modelo de exemplo, substituaBUCKET_PATHpelo seguinte valor:gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx.Quando a operação for concluída, uma mensagem semelhante a esta será exibida:
Successfully created model named imported_onnx_model.Seu novo modelo vai aparecer no painel Recursos. Os modelos são indicados pelo ícone:
 Se você selecionar o novo modelo no painel Recursos, as informações
sobre o modelo vão aparecer ao lado do Editor de consultas.
Se você selecionar o novo modelo no painel Recursos, as informações
sobre o modelo vão aparecer ao lado do Editor de consultas.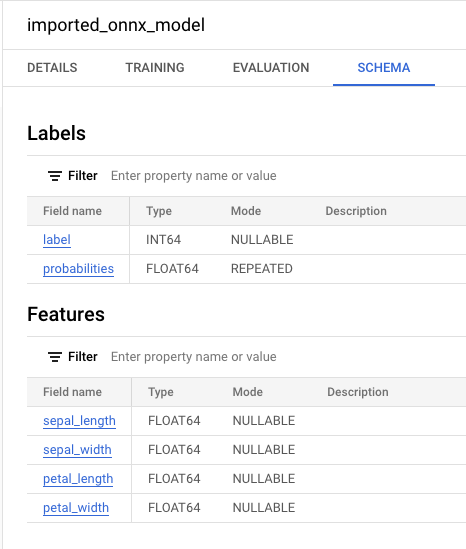
Importe o modelo ONNX do Cloud Storage inserindo a seguinte instrução
CREATE MODEL.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.imported_onnx_model` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='BUCKET_PATH')"
Substitua
BUCKET_PATHpelo caminho para o modelo que você fez upload para o Cloud Storage. Se você estiver usando o modelo de exemplo, substituaBUCKET_PATHpelo seguinte valor:gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx.Quando a operação for concluída, uma mensagem semelhante a esta será exibida:
Successfully created model named imported_onnx_model.Depois de importar o modelo, verifique se ele aparece no conjunto de dados.
bq ls bqml_tutorial
O resultado será assim:
tableId Type --------------------- ------- imported_onnx_model MODEL
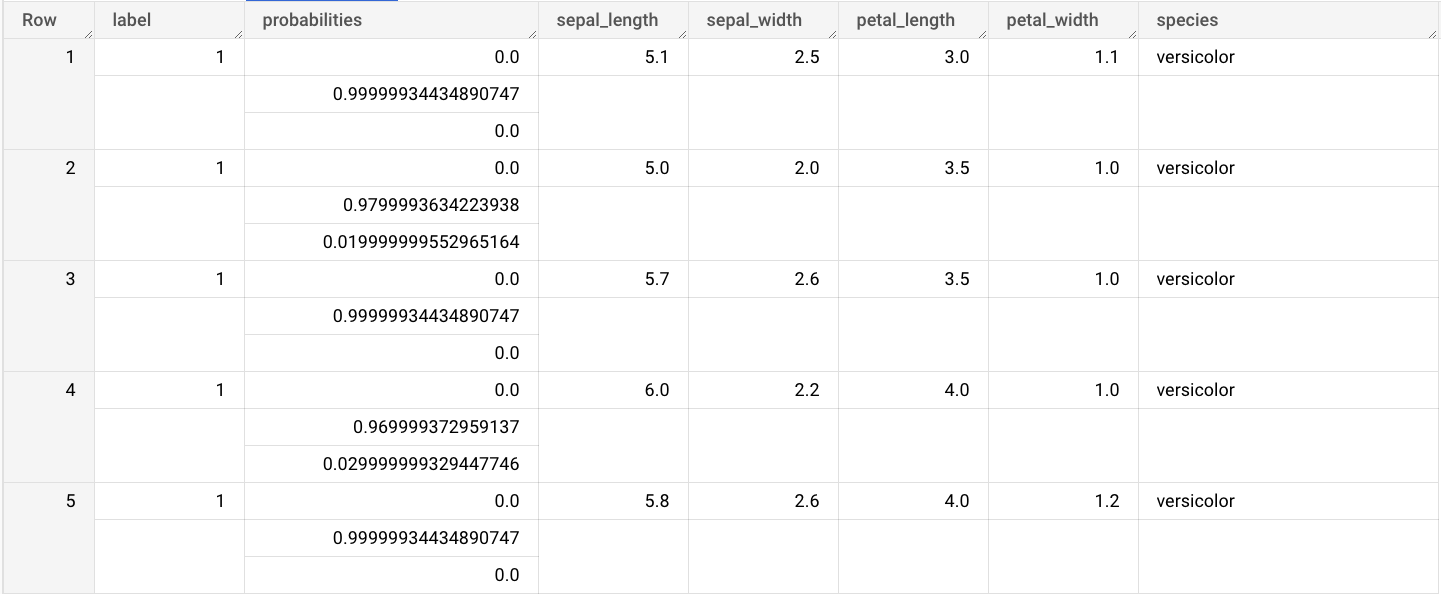
sepal_lengthsepal_widthpetal_lengthpetal_widthAcesse a página do BigQuery Studio.
No editor de consultas, insira esta consulta que usa a função
ML.PREDICT.SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.imported_onnx_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.iris` ) )
Os resultados da consulta são semelhantes a estes:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Opcional: exclua o conjunto de dados.
- Para mais informações sobre como importar modelos ONNX, consulte
A instrução
CREATE MODELpara modelos ONNX. - Para mais informações sobre conversores e tutoriais ONNX disponíveis, consulte Como converter para o formato ONNX.
- Para uma visão geral sobre ML do BigQuery, consulte Introdução ao ML do BigQuery.
- Para começar a usar o BigQuery ML, consulte Criar modelos de machine learning no BigQuery ML.
Funções exigidas
Se você criar um projeto, será o proprietário dele e terá todas as permissões necessárias do Identity and Access Management (IAM) para concluir este tutorial.
Se você estiver usando um projeto atual, faça o seguinte:
Make sure that you have the following role or roles on the project:
Check for the roles
Grant the roles
Para mais informações sobre as permissões do IAM no BigQuery, consulte Permissões do IAM.
Opcional: treinar um modelo e convertê-lo para o formato ONNX
Os exemplos de código a seguir mostram como treinar um modelo de classificação com
scikit-learn e como converter o pipeline resultante para o formato ONNX. Este tutorial usa um modelo de exemplo pré-criado armazenado em gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx. Não é necessário concluir essas etapas se você estiver usando o modelo de amostra.
Treinar um modelo de classificação com o scikit-learn
Use o exemplo de código a seguir para criar e treinar um pipeline do scikit-learn no conjunto de dados Iris. Para instruções sobre como instalar e usar o scikit-learn, consulte o guia de instalação do scikit-learn.
import numpy
from sklearn.datasets import load_iris
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
data = load_iris()
X = data.data[:, :4]
y = data.target
ind = numpy.arange(X.shape[0])
numpy.random.shuffle(ind)
X = X[ind, :].copy()
y = y[ind].copy()
pipe = Pipeline([('scaler', StandardScaler()),
('clr', RandomForestClassifier())])
pipe.fit(X, y)
Converter o pipeline em um modelo ONNX
Use o exemplo de código a seguir em sklearn-onnx para converter o pipeline do scikit-learn em um modelo ONNX chamado pipeline_rf.onnx.
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
# Disable zipmap as it is not supported in BigQuery ML.
options = {id(pipe): {'zipmap': False}}
# Define input features. scikit-learn does not store information about the
# training dataset. It is not always possible to retrieve the number of features
# or their types. That's why the function needs another argument called initial_types.
initial_types = [
('sepal_length', FloatTensorType([None, 1])),
('sepal_width', FloatTensorType([None, 1])),
('petal_length', FloatTensorType([None, 1])),
('petal_width', FloatTensorType([None, 1])),
]
# Convert the model.
model_onnx = convert_sklearn(
pipe, 'pipeline_rf', initial_types=initial_types, options=options
)
# And save.
with open('pipeline_rf.onnx', 'wb') as f:
f.write(model_onnx.SerializeToString())
Faça o upload do modelo ONNX para o Cloud Storage.
Depois de salvar o modelo, faça o seguinte:
crie um conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar seu modelo de ML.
Console
bq
Para criar um novo conjunto de dados, utilize o
comando bq mk
com a sinalização --location. Para obter uma lista completa de parâmetros, consulte a
referência
comando bq mk --dataset.
API
Chame o método datasets.insert com um recurso de conjunto de dados definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
Importar o modelo ONNX para o BigQuery
As etapas a seguir mostram como importar o modelo ONNX de exemplo do Cloud Storage usando uma instrução CREATE MODEL.
Para importar o modelo do ONNX para seu conjunto de dados, selecione uma das seguintes opções:
Console
bq
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
Importe o modelo usando o objeto ONNXModel.
Para mais informações sobre como importar modelos ONNX para o BigQuery, incluindo requisitos de formato e armazenamento, consulte A instrução CREATE MODEL para importar modelos ONNX.
Fazer previsões com o modelo ONNX importado
Depois de importar o modelo ONNX, use a função ML.PREDICT para fazer previsões com ele.
A consulta nas etapas a seguir usa imported_onnx_model para fazer previsões com base nos dados de entrada da tabela iris no conjunto de dados público ml_datasets. O modelo ONNX espera quatro valores FLOAT como entrada:
Essas entradas correspondem às initial_types definidas quando você converteu o
modelo para o formato ONNX.
As saídas incluem as colunas label e probabilities, além das colunas da tabela de entrada. label representa o rótulo de classe previsto.
probabilities é uma matriz de probabilidades que representa probabilidades para cada classe.
Para fazer previsões com o modelo importado do TensorFlow, escolha uma das seguintes opções:
Console
bq
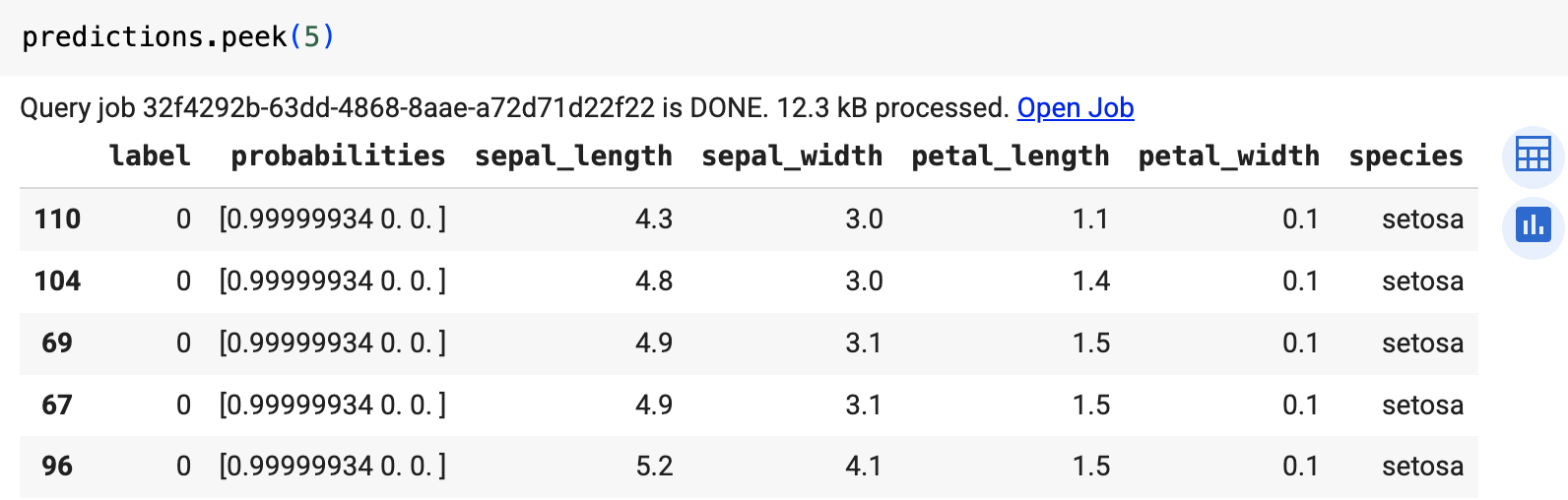
Execute a consulta que usa ML.PREDICT.
bq query --use_legacy_sql=false \ 'SELECT * FROM ML.PREDICT( MODEL `example_dataset.imported_onnx_model`, (SELECT * FROM `bigquery-public-data.ml_datasets.iris`))'
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
Use a função predict para executar o modelo remoto.
O resultado será semelhante ao seguinte:
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
Excluir o projeto
Console
gcloud
Excluir recursos individuais
Como alternativa, para remover os recursos individuais usados neste tutorial, faça o seguinte: