Questo tutorial mostra come importare un modello Open Neural Network Exchange (ONNX) addestrato con scikit-learn. Importa il modello in un set di dati BigQuery e utilizzalo per fare previsioni utilizzando una query SQL.
ONNX fornisce un formato uniforme progettato per rappresentare qualsiasi framework di machine learning (ML). Il supporto di BigQuery ML per ONNX ti consente di:
- Addestra un modello utilizzando il tuo framework preferito.
- Converti il modello nel formato ONNX.
- Importa il modello ONNX in BigQuery ed esegui previsioni utilizzando BigQuery ML.
Obiettivi
- Crea e addestra un modello utilizzando scikit-learn.
- Converti il modello nel formato ONNX utilizzando sklearn-onnx.
- Utilizza l'istruzione
CREATE MODELper importare il modello ONNX in BigQuery. - Utilizza la funzione
ML.PREDICTper fare previsioni con il modello ONNX importato.
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Al termine delle attività descritte in questo documento, puoi evitare l'addebito di ulteriori costi eliminando le risorse che hai creato. Per ulteriori informazioni, vedi Pulizia.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Assicurati di disporre delle autorizzazioni necessarie per eseguire le attività descritte in questo documento.
- BigQuery Studio Admin (
roles/bigquery.studioAdmin) - Storage Object Creator (
roles/storage.objectCreator) -
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
-
In the Google Cloud console, go to the IAM page.
Vai a IAM - Seleziona il progetto.
- Fai clic su Concedi l'accesso.
-
Nel campo Nuove entità, inserisci il tuo identificatore dell'utente. In genere si tratta dell'indirizzo email di un Account Google.
- Nell'elenco Seleziona un ruolo, seleziona un ruolo.
- Per concedere altri ruoli, fai clic su Aggiungi un altro ruolo e aggiungi ogni ruolo aggiuntivo.
- Fai clic su Salva.
- Crea un bucket Cloud Storage per archiviare il modello.
- Carica il modello ONNX nel bucket Cloud Storage.
Nella console Google Cloud , vai alla pagina BigQuery.
Nel riquadro Explorer, fai clic sul nome del progetto.
Fai clic su Visualizza azioni > Crea set di dati.
Nella pagina Crea set di dati:
In ID set di dati, inserisci
bqml_tutorial.Per Tipo di località, seleziona Multi-regione e poi Stati Uniti (più regioni negli Stati Uniti).
Lascia invariate le restanti impostazioni predefinite e fai clic su Crea set di dati.
Crea un set di dati denominato
bqml_tutorialcon la località dei dati impostata suUSe una descrizione diBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Anziché utilizzare il flag
--dataset, il comando utilizza la scorciatoia-d. Se ometti-de--dataset, il comando crea per impostazione predefinita un dataset.Verifica che il set di dati sia stato creato:
bq lsNella console Google Cloud , vai alla pagina BigQuery Studio.
Nell'editor di query, inserisci la seguente istruzione
CREATE MODEL.CREATE OR REPLACE MODEL `bqml_tutorial.imported_onnx_model` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='BUCKET_PATH')
Sostituisci
BUCKET_PATHcon il percorso del modello che hai caricato su Cloud Storage. Se utilizzi il modello di esempio, sostituisciBUCKET_PATHcon il seguente valore:gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx.Al termine dell'operazione, viene visualizzato un messaggio simile al seguente:
Successfully created model named imported_onnx_model.Il nuovo modello viene visualizzato nel riquadro Risorse. I modelli sono indicati dall'icona del modello:
 Se selezioni il nuovo modello nel riquadro Risorse, le informazioni
sul modello vengono visualizzate accanto all'editor query.
Se selezioni il nuovo modello nel riquadro Risorse, le informazioni
sul modello vengono visualizzate accanto all'editor query.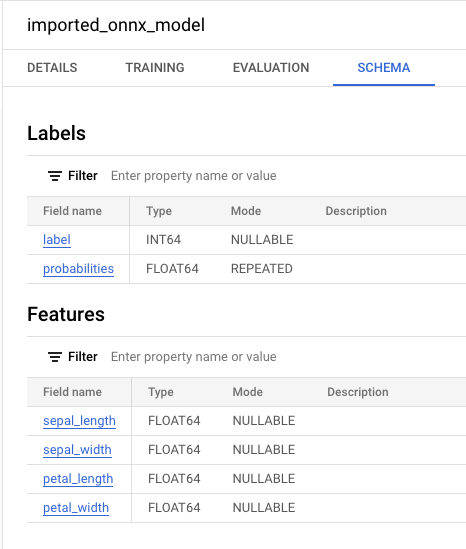
Importa il modello ONNX da Cloud Storage inserendo la seguente istruzione
CREATE MODEL.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.imported_onnx_model` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='BUCKET_PATH')"
Sostituisci
BUCKET_PATHcon il percorso del modello che hai caricato su Cloud Storage. Se utilizzi il modello di esempio, sostituisciBUCKET_PATHcon il seguente valore:gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx.Al termine dell'operazione, viene visualizzato un messaggio simile al seguente:
Successfully created model named imported_onnx_model.Dopo aver importato il modello, verifica che venga visualizzato nel set di dati.
bq ls -m bqml_tutorial
L'output è simile al seguente:
tableId Type --------------------- ------- imported_onnx_model MODEL
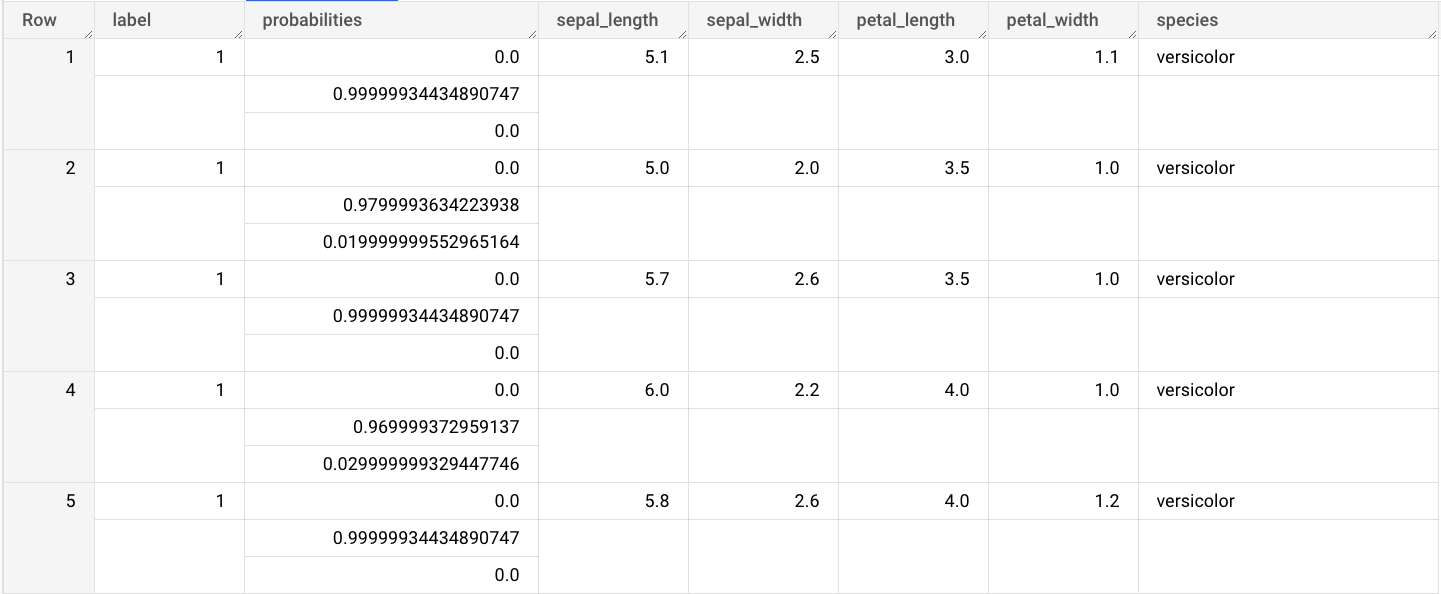
sepal_lengthsepal_widthpetal_lengthpetal_widthVai alla pagina BigQuery Studio.
Nell'editor di query, inserisci questa query che utilizza la funzione
ML.PREDICT.SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.imported_onnx_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.iris` ) )
I risultati della query sono simili ai seguenti:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
(Facoltativo) Elimina il set di dati.
- Per ulteriori informazioni sull'importazione di modelli ONNX, consulta
L'istruzione
CREATE MODELper i modelli ONNX. - Per ulteriori informazioni sui convertitori ONNX e sui tutorial disponibili, consulta Conversione nel formato ONNX.
- Per una panoramica di BigQuery ML, consulta Introduzione a BigQuery ML.
- Per iniziare a utilizzare BigQuery ML, consulta Creare modelli di machine learning in BigQuery ML.
Ruoli obbligatori
Se crei un nuovo progetto, ne sei il proprietario e ti vengono concesse tutte le autorizzazioni Identity and Access Management (IAM) necessarie per completare questo tutorial.
Se utilizzi un progetto esistente, procedi nel seguente modo.
Make sure that you have the following role or roles on the project:
Check for the roles
Grant the roles
Per saperne di più sulle autorizzazioni IAM in BigQuery, consulta Autorizzazioni IAM.
(Facoltativo) Addestra un modello e convertilo nel formato ONNX
I seguenti esempi di codice mostrano come addestrare un modello di classificazione con
scikit-learn e come convertire la pipeline risultante nel formato ONNX. Questo
tutorial utilizza un modello di esempio predefinito archiviato in
gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx. Non devi
completare questi passaggi se utilizzi il modello di esempio.
Addestrare un modello di classificazione con scikit-learn
Utilizza il seguente codice campione per creare e addestrare una pipeline scikit-learn sul set di dati Iris. Per istruzioni sull'installazione e l'utilizzo di scikit-learn, consulta la guida all'installazione di scikit-learn.
import numpy
from sklearn.datasets import load_iris
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
data = load_iris()
X = data.data[:, :4]
y = data.target
ind = numpy.arange(X.shape[0])
numpy.random.shuffle(ind)
X = X[ind, :].copy()
y = y[ind].copy()
pipe = Pipeline([('scaler', StandardScaler()),
('clr', RandomForestClassifier())])
pipe.fit(X, y)
Converti la pipeline in un modello ONNX
Utilizza il seguente codice campione in sklearn-onnx per convertire la pipeline scikit-learn in un modello ONNX denominato pipeline_rf.onnx.
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
# Disable zipmap as it is not supported in BigQuery ML.
options = {id(pipe): {'zipmap': False}}
# Define input features. scikit-learn does not store information about the
# training dataset. It is not always possible to retrieve the number of features
# or their types. That's why the function needs another argument called initial_types.
initial_types = [
('sepal_length', FloatTensorType([None, 1])),
('sepal_width', FloatTensorType([None, 1])),
('petal_length', FloatTensorType([None, 1])),
('petal_width', FloatTensorType([None, 1])),
]
# Convert the model.
model_onnx = convert_sklearn(
pipe, 'pipeline_rf', initial_types=initial_types, options=options
)
# And save.
with open('pipeline_rf.onnx', 'wb') as f:
f.write(model_onnx.SerializeToString())
Carica il modello ONNX su Cloud Storage
Dopo aver salvato il modello:
Crea un set di dati
Crea un set di dati BigQuery per archiviare il tuo modello ML.
Console
bq
Per creare un nuovo set di dati, utilizza il
comando bq mk
con il flag --location. Per un elenco completo dei possibili parametri, consulta la
documentazione di riferimento del
comando bq mk --dataset.
API
Chiama il metodo datasets.insert con una risorsa dataset definita.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
Importa il modello ONNX in BigQuery
I passaggi seguenti mostrano come importare il modello ONNX di esempio da
Cloud Storage utilizzando un'istruzione CREATE MODEL.
Per importare il modello ONNX nel set di dati, seleziona una delle seguenti opzioni:
Console
bq
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
Importa il modello utilizzando l'oggetto ONNXModel.
Per ulteriori informazioni sull'importazione di modelli ONNX in BigQuery, inclusi i requisiti di formato e archiviazione, consulta l'istruzione CREATE MODEL per
l'importazione di modelli ONNX.
Fare previsioni con il modello ONNX importato
Dopo aver importato il modello ONNX, utilizza la funzione ML.PREDICT per fare previsioni con il modello.
La query nei passaggi successivi utilizza imported_onnx_model per fare previsioni
utilizzando i dati di input della tabella iris nel set di dati pubblico ml_datasets. Il modello
ONNX prevede quattro valori FLOAT come input:
Questi input corrispondono a initial_types definiti durante la conversione del
modello nel formato ONNX.
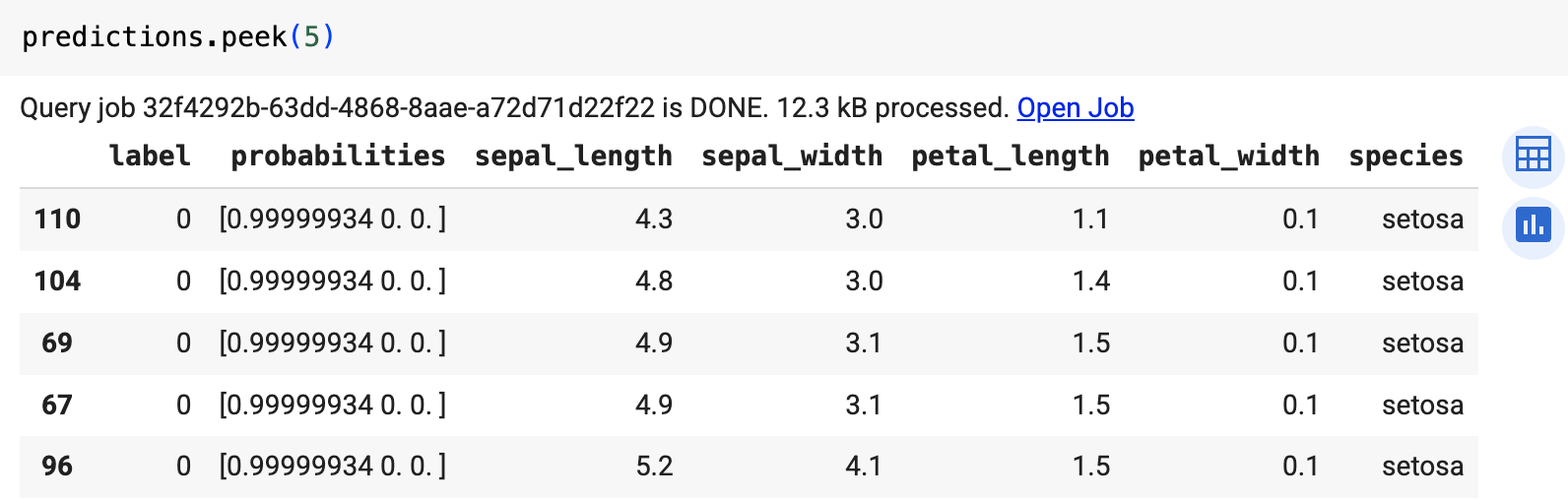
Gli output includono le colonne label e probabilities e le colonne
della tabella di input. label rappresenta l'etichetta della classe prevista.
probabilities è un array di probabilità che rappresentano le probabilità per
ogni classe.
Per fare previsioni con il modello ONNX importato, scegli una delle seguenti opzioni:
Console
bq
Esegui la query che utilizza ML.PREDICT.
bq query --use_legacy_sql=false \ 'SELECT * FROM ML.PREDICT( MODEL `example_dataset.imported_onnx_model`, (SELECT * FROM `bigquery-public-data.ml_datasets.iris`))'
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
Utilizza la funzione predict per eseguire il modello ONNX.
Il risultato è simile al seguente:
Esegui la pulizia
Per evitare che al tuo Account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina il progetto
Console
gcloud
Elimina singole risorse
In alternativa, per rimuovere le singole risorse utilizzate in questo tutorial: