Tutorial ini mengajarkan cara menggunakan model k-means di BigQuery ML untuk mengidentifikasi cluster dalam sekumpulan data.
Algoritma k-means yang mengelompokkan data Anda ke dalam cluster adalah bentuk unsupervised machine learning. Tidak seperti supervised machine learning yang berfokus pada analisis prediktif, unsupervised machine learning berfokus pada analisis deskriptif. Machine learning tanpa pengawasan dapat membantu Anda memahami data sehingga Anda dapat membuat keputusan berbasis data.
Kueri dalam tutorial ini menggunakan fungsi geografi yang tersedia dalam analisis geospasial. Untuk mengetahui informasi selengkapnya, lihat Pengantar analisis geospasial.
Tutorial ini menggunakan set data publik London Bicycle Hires. Data ini mencakup stempel waktu mulai dan berhenti, nama stasiun, serta durasi perjalanan.
Tujuan
Tutorial ini memandu Anda menyelesaikan tugas-tugas berikut:- Periksa data yang digunakan untuk melatih model.
- Membuat model pengelompokan k-means.
- Menafsirkan cluster data yang dihasilkan, menggunakan visualisasi cluster BigQuery ML.
- Jalankan
fungsi
ML.PREDICTpada model k-means untuk memprediksi kemungkinan cluster untuk sekumpulan stasiun penyewaan sepeda.
Biaya
Tutorial ini menggunakan komponen Google Cloudyang dapat ditagih, termasuk:
- BigQuery
- BigQuery ML
Untuk mengetahui informasi tentang biaya BigQuery, lihat halaman harga BigQuery.
Untuk mengetahui informasi tentang biaya BigQuery ML, lihat Harga BigQuery ML.
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery secara otomatis diaktifkan dalam project baru.
Untuk mengaktifkan BigQuery dalam project yang sudah ada, buka
Enable the BigQuery API.
Untuk membuat set data, Anda memerlukan izin IAM
bigquery.datasets.create.Untuk membuat model, Anda memerlukan izin berikut:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Untuk menjalankan inferensi, Anda memerlukan izin berikut:
bigquery.models.getDatabigquery.jobs.create
Izin yang Diperlukan
Untuk mengetahui informasi lebih lanjut tentang peran dan izin IAM di BigQuery, baca Pengantar IAM.
Membuat set data
Buat set data BigQuery untuk menyimpan model k-means Anda:
Di konsol Google Cloud , buka halaman BigQuery.
Di panel Explorer, klik nama project Anda.
Klik View actions > Create dataset.
Di halaman Create dataset, lakukan hal berikut:
Untuk ID Set Data, masukkan
bqml_tutorial.Untuk Jenis lokasi, pilih Multi-region, lalu pilih UE (beberapa region di Uni Eropa).
Set data publik London Bicycle Hires disimpan di multi-region
EU. Set data Anda harus berada di lokasi yang sama.Jangan ubah setelan default yang tersisa, lalu klik Buat set data.

Periksa data pelatihan
Periksa data yang akan Anda gunakan untuk melatih model k-means. Dalam tutorial ini, Anda akan mengelompokkan stasiun sepeda berdasarkan atribut berikut:
- Durasi penyewaan
- Jumlah perjalanan per hari
- Jarak dari pusat kota
SQL
Kueri ini mengekstrak data tentang penyewaan sepeda, termasuk kolom start_station_name
dan duration, lalu menggabungkan data ini dengan informasi stasiun. Hal ini mencakup pembuatan kolom kalkulasi yang berisi jarak stasiun dari pusat kota. Kemudian, kueri ini menghitung atribut
stasiun di kolom stationstats, termasuk durasi rata-rata
perjalanan dan jumlah perjalanan, serta kolom distance_from_city_center
yang dihitung.
Ikuti langkah-langkah berikut untuk memeriksa data pelatihan:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
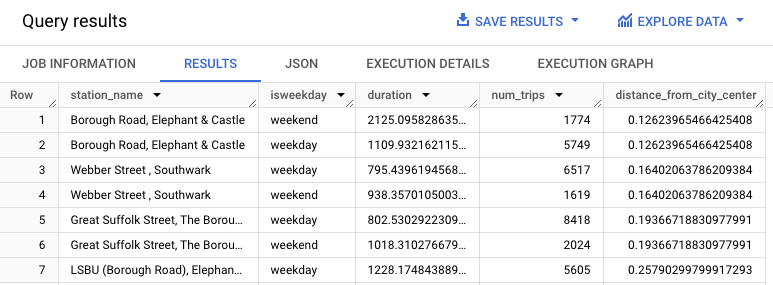
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * FROM stationstats ORDER BY distance_from_city_center ASC;
Hasilnya akan terlihat seperti berikut:
DataFrame BigQuery
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Membuat model k-means
Buat model k-means menggunakan data pelatihan London Bicycle Hires.
SQL
Dalam kueri berikut, pernyataan CREATE MODEL menentukan jumlah
cluster yang akan digunakan — empat. Dalam pernyataan SELECT, klausa EXCEPT
mengecualikan kolom station_name karena kolom ini tidak berisi
fitur. Kueri ini membuat baris unik per station_name, dan hanya
fitur yang disebutkan dalam pernyataan SELECT.
Ikuti langkah-langkah berikut untuk membuat model k-means:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
CREATE OR REPLACE MODEL `bqml_tutorial.london_station_clusters` OPTIONS ( model_type = 'kmeans', num_clusters = 4) AS WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (station_name, isweekday) FROM stationstats;
DataFrame BigQuery
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Menafsirkan kelompok data
Informasi di tab Evaluasi model dapat membantu Anda menafsirkan kelompok yang dihasilkan oleh model.
Ikuti langkah-langkah berikut untuk melihat informasi evaluasi model:
Di konsol Google Cloud , buka halaman BigQuery.
Di panel Explorer, luaskan project Anda, luaskan set data
bqml_tutorial, lalu luaskan folder Models.Pilih model
london_station_clusters.Pilih tab Evaluasi. Tab ini menampilkan visualisasi cluster yang diidentifikasi oleh model k-means. Di bagian Fitur numerik, grafik batang menampilkan nilai fitur numerik terpenting untuk setiap sentroid. Setiap centroid mewakili cluster data tertentu. Anda dapat memilih fitur yang akan divisualisasikan dari menu drop-down.
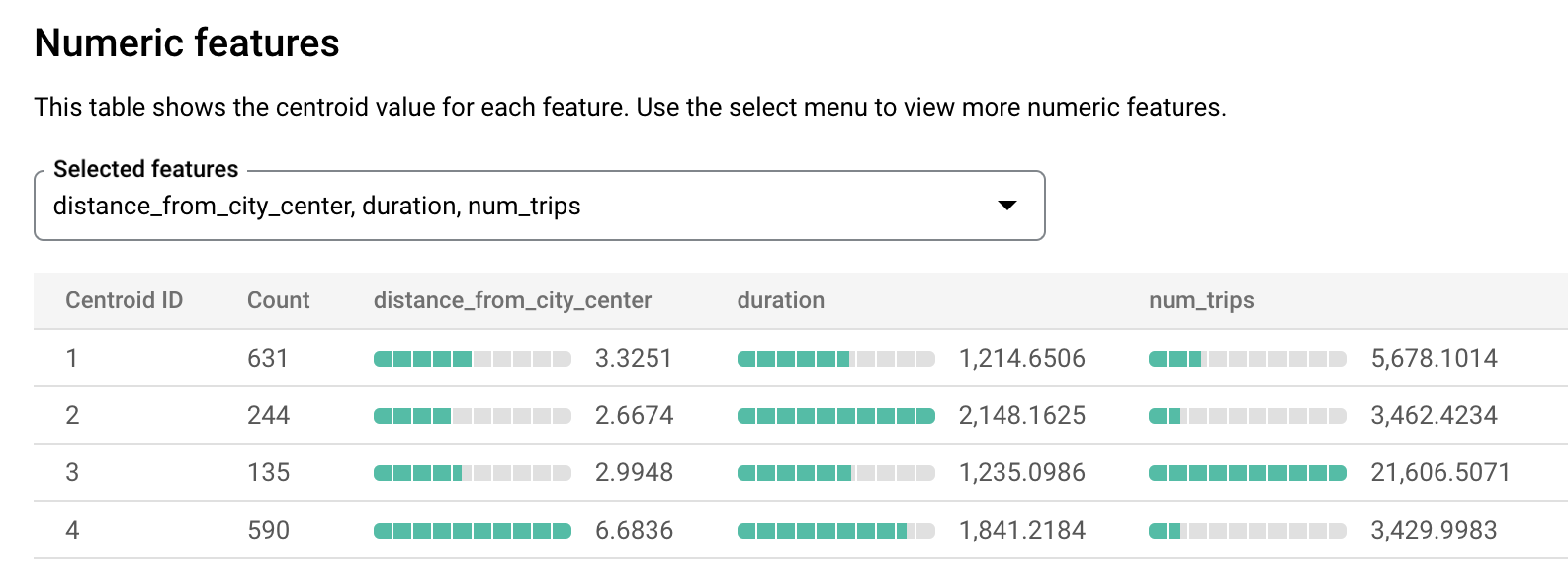
Model ini membuat centroid berikut:
- Sentroid 1 menampilkan stasiun kota yang tidak terlalu ramai, dengan penyewaan berdurasi lebih singkat.
- Sentroid 2 menunjukkan stasiun kota kedua yang tidak terlalu ramai dan digunakan untuk penyewaan berdurasi lebih lama.
- Sentroid 3 menunjukkan stasiun kota yang ramai dan dekat dengan pusat kota.
- Sentroid 4 menampilkan stasiun pinggiran kota dengan perjalanan yang lebih panjang.
Jika menjalankan bisnis penyewaan sepeda, Anda dapat menggunakan informasi ini untuk mendukung keputusan bisnis. Contoh:
Anggaplah Anda perlu bereksperimen dengan jenis kunci baru. Cluster stasiun mana yang akan Anda pilih sebagai subjek untuk eksperimen ini? Stasiun di sentroid 1, sentroid 2, atau sentroid 4 tampak seperti pilihan logis karena bukan stasiun tersibuk.
Anggaplah Anda ingin mengisi beberapa stasiun dengan sepeda balap. Stasiun mana yang harus Anda pilih? Centroid 4 adalah kelompok stasiun yang jauh dari pusat kota, dan memiliki perjalanan terpanjang. Kelompok ini adalah kandidat untuk sepeda balap.
Gunakan fungsi ML.PREDICT untuk memprediksi cluster stasiun
Identifikasi cluster tempat stasiun tertentu berada menggunakan fungsi SQL
ML.PREDICT atau fungsi BigQuery DataFrames
predict.
SQL
Kueri berikut menggunakan
fungsi REGEXP_CONTAINS
untuk menemukan semua entri dalam kolom station_name yang berisi
string Kennington. Fungsi ML.PREDICT menggunakan nilai tersebut untuk memprediksi
cluster mana yang mungkin berisi stasiun tersebut.
Ikuti langkah-langkah berikut untuk memprediksi cluster setiap stasiun yang memiliki
string Kennington dalam namanya:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, tempel kueri berikut, lalu klik Run:
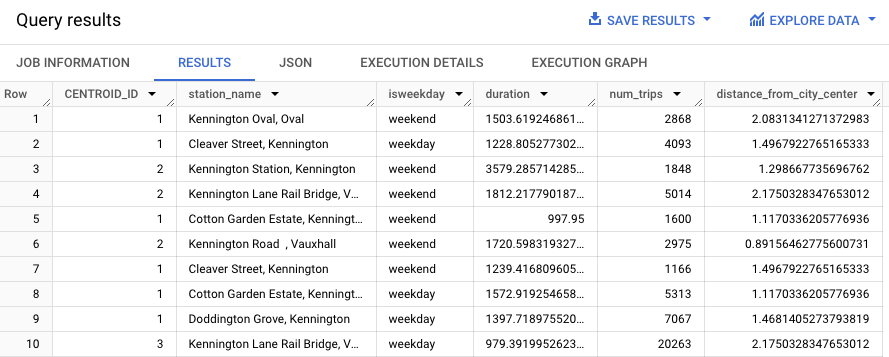
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (nearest_centroids_distance) FROM ML.PREDICT( MODEL `bqml_tutorial.london_station_clusters`, ( SELECT * FROM stationstats WHERE REGEXP_CONTAINS(station_name, 'Kennington') ));
Hasilnya akan terlihat seperti berikut.
DataFrame BigQuery
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Pembersihan
Agar akun Google Cloud Anda tidak dikenai biaya untuk resource yang digunakan dalam tutorial ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus resource satu per satu.
- Anda dapat menghapus project yang dibuat.
- Atau, Anda dapat menyimpan project dan menghapus set data.
Menghapus set data
Jika project Anda dihapus, semua set data dan semua tabel dalam project akan dihapus. Jika ingin menggunakan kembali project tersebut, Anda dapat menghapus set data yang dibuat dalam tutorial ini:
Jika perlu, buka halaman BigQuery di konsolGoogle Cloud .
Di navigasi, klik set data bqml_tutorial yang telah Anda buat.
Klik Hapus set data di sisi kanan jendela. Tindakan ini akan menghapus set data dan model.
Pada dialog Hapus set data, konfirmasi perintah hapus dengan mengetikkan nama set data Anda (
bqml_tutorial), lalu klik Hapus.
Menghapus project Anda
Untuk menghapus project:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Langkah berikutnya
- Untuk ringkasan BigQuery ML, lihat Pengantar BigQuery ML.
- Untuk informasi tentang cara membuat model, lihat
halaman sintaksis
CREATE MODEL.