Tabel BigLake untuk Apache Iceberg di BigQuery
Tabel BigLake untuk Apache Iceberg di BigQuery, (selanjutnya disebut tabel BigLake Iceberg di BigQuery) memberikan fondasi untuk membangun lakehouse berformat terbuka di Google Cloud. Tabel Iceberg BigLake di BigQuery menawarkan pengalaman terkelola sepenuhnya yang sama dengan tabel BigQuery standar, tetapi menyimpan data di bucket penyimpanan milik pelanggan. Tabel Iceberg BigLake di BigQuery mendukung format tabel Iceberg terbuka untuk interoperabilitas yang lebih baik dengan mesin komputasi open source dan pihak ketiga pada satu salinan data.
Tabel BigLake untuk Apache Iceberg di BigQuery berbeda dengan tabel eksternal Apache Iceberg. Tabel BigLake untuk Apache Iceberg di BigQuery adalah tabel terkelola sepenuhnya yang dapat dimodifikasi langsung di BigQuery, sedangkan tabel eksternal Apache Iceberg dikelola pelanggan dan menawarkan akses hanya baca dari BigQuery.
Tabel Iceberg BigLake di BigQuery mendukung fitur berikut:
- Mutasi tabel menggunakan bahasa pengolahan data (DML) GoogleSQL.
- Streaming batch dan throughput tinggi terpadu menggunakan Storage Write API melalui konektor BigLake seperti Spark, Dataflow, dan mesin lainnya.
- Ekspor snapshot Iceberg V2 dan refresh otomatis pada setiap mutasi tabel untuk akses kueri langsung dengan mesin kueri open source dan pihak ketiga.
- Evolusi skema, yang memungkinkan Anda menambahkan, menghapus, dan mengganti nama kolom agar sesuai dengan kebutuhan Anda. Fitur ini juga memungkinkan Anda mengubah jenis data kolom yang ada dan mode kolom. Untuk mengetahui informasi selengkapnya, lihat aturan konversi jenis.
- Pengoptimalan penyimpanan otomatis, termasuk penentuan ukuran file adaptif, pengelompokan otomatis, pengumpulan sampah, dan pengoptimalan metadata.
- Perjalanan waktu untuk akses data historis di BigQuery.
- Keamanan tingkat kolom dan penyamaran data.
- Transaksi multi-pernyataan (dalam Pratinjau).
Arsitektur
Tabel BigLake Iceberg di BigQuery menghadirkan kemudahan pengelolaan resource BigQuery untuk tabel yang berada di bucket cloud Anda sendiri. Anda dapat menggunakan BigQuery dan mesin komputasi open source di tabel ini tanpa memindahkan data dari bucket yang Anda kontrol. Anda harus mengonfigurasi bucket Cloud Storage sebelum mulai menggunakan tabel BigLake Iceberg di BigQuery.
Tabel BigLake Iceberg di BigQuery menggunakan BigLake Metastore sebagai metastore runtime terpadu untuk semua data Iceberg. Metastore BigLake menyediakan satu sumber kebenaran untuk mengelola metadata dari beberapa mesin dan memungkinkan interoperabilitas mesin.
Diagram berikut menunjukkan arsitektur tabel terkelola secara umum:
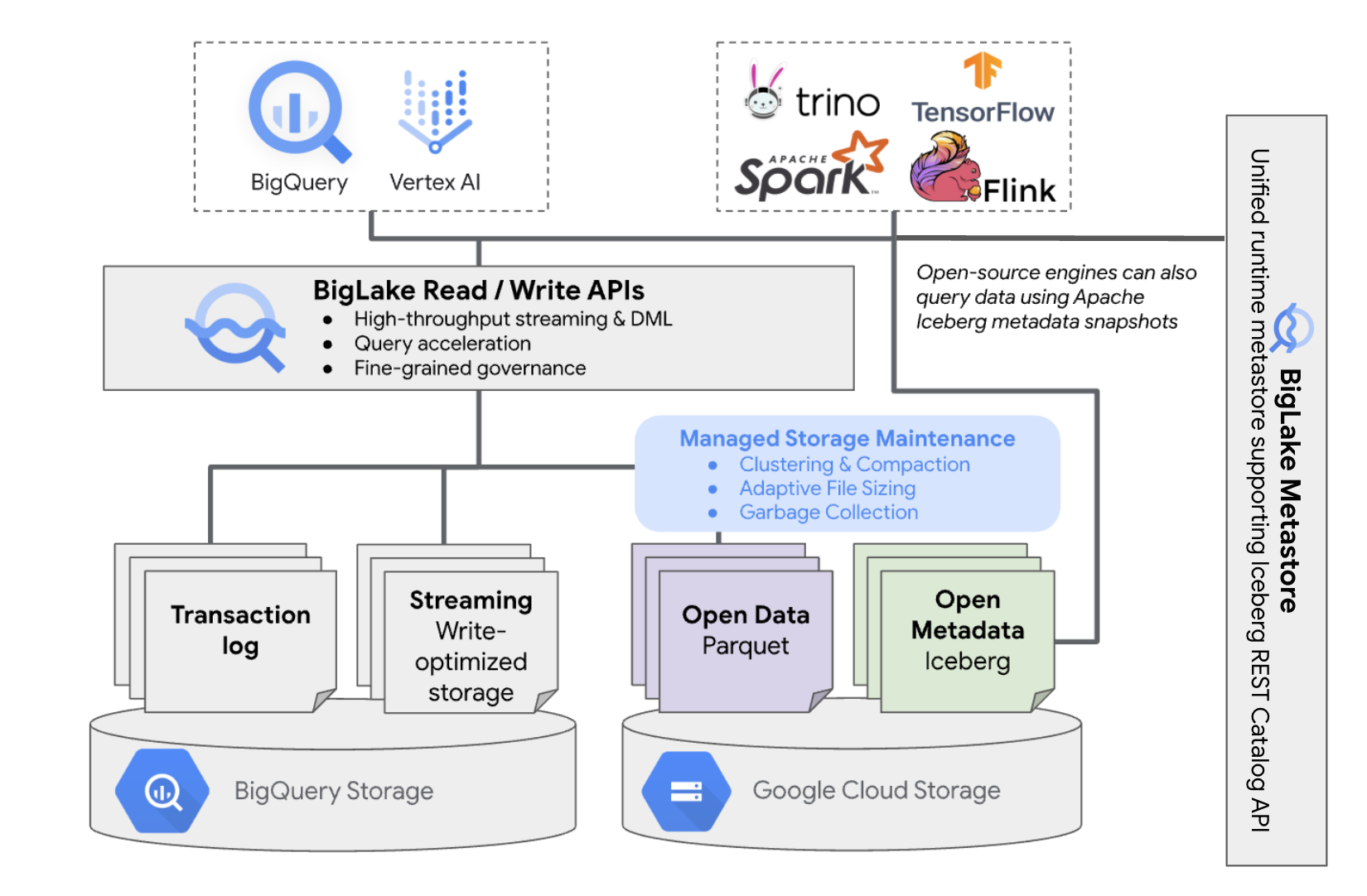
Pengelolaan tabel ini memiliki implikasi berikut pada bucket Anda:
- BigQuery membuat file data baru di bucket sebagai respons terhadap permintaan penulisan dan pengoptimalan penyimpanan di latar belakang, seperti pernyataan DML dan streaming.
- Saat Anda menghapus tabel terkelola di BigQuery, BigQuery akan mengumpulkan sampah file data terkait di Cloud Storage setelah berakhirnya periode perjalanan waktu.
Membuat tabel BigLake Iceberg di BigQuery mirip dengan membuat tabel BigQuery. Karena menyimpan data dalam format terbuka di Cloud Storage, Anda harus melakukan hal berikut:
- Tentukan
koneksi resource Cloud
dengan
WITH CONNECTIONuntuk mengonfigurasi kredensial koneksi agar BigLake dapat mengakses Cloud Storage. - Tentukan format file penyimpanan data sebagai
PARQUETdengan pernyataanfile_format = PARQUET. - Tentukan format tabel metadata open source sebagai
ICEBERGdengan pernyataantable_format = ICEBERG.
Praktik terbaik
Mengubah atau menambahkan file secara langsung ke bucket di luar BigQuery dapat menyebabkan hilangnya data atau error yang tidak dapat dipulihkan. Tabel berikut menjelaskan kemungkinan skenario:
| Operasi | Konsekuensi | Pencegahan |
|---|---|---|
| Tambahkan file baru ke bucket di luar BigQuery. | Kehilangan data: File atau objek baru yang ditambahkan di luar BigQuery tidak dilacak oleh BigQuery. File yang tidak dilacak akan dihapus oleh proses pengumpulan sampah di latar belakang. | Tambahkan data secara eksklusif melalui BigQuery. Hal ini memungkinkan
BigQuery melacak file dan mencegahnya dikumpulkan sampah. Untuk mencegah penambahan yang tidak disengaja dan kehilangan data, sebaiknya batasi izin tulis alat eksternal pada bucket yang berisi tabel BigLake Iceberg di BigQuery. |
| Buat tabel BigLake Iceberg baru di BigQuery dalam awalan yang tidak kosong. | Kehilangan data: Data yang ada tidak dilacak oleh BigQuery, sehingga file ini dianggap tidak dilacak, dan dihapus oleh proses pengumpulan sampah di latar belakang. | Buat hanya tabel BigLake Iceberg baru di BigQuery dalam awalan yang kosong. |
| Ubah atau ganti tabel Iceberg BigLake dalam file data BigQuery. | Kehilangan data: Saat modifikasi atau penggantian eksternal,
tabel gagal dalam pemeriksaan konsistensi dan menjadi tidak dapat dibaca. Kueri
terhadap tabel gagal. Tidak ada cara layanan mandiri untuk memulihkan dari titik ini. Hubungi dukungan untuk mendapatkan bantuan pemulihan data. |
Ubah data secara eksklusif melalui BigQuery. Hal ini memungkinkan
BigQuery melacak file dan mencegahnya dikumpulkan sampah. Untuk mencegah penambahan yang tidak disengaja dan kehilangan data, sebaiknya batasi izin tulis alat eksternal pada bucket yang berisi tabel BigLake Iceberg di BigQuery. |
| Buat dua tabel BigLake Iceberg di BigQuery dengan URI yang sama atau tumpang-tindih. | Kehilangan data: BigQuery tidak menjembatani instance URI identik dari tabel Iceberg BigLake di BigQuery. Proses pengumpulan sampah di latar belakang untuk setiap tabel akan menganggap file tabel yang berlawanan sebagai tidak terlacak, dan menghapusnya, sehingga menyebabkan kehilangan data. | Gunakan URI unik untuk setiap tabel BigLake Iceberg di BigQuery. |
Praktik terbaik konfigurasi bucket Cloud Storage
Konfigurasi bucket Cloud Storage dan koneksinya dengan BigLake memiliki dampak langsung pada performa, biaya, integritas data, keamanan, dan tata kelola tabel BigLake Iceberg Anda di BigQuery. Berikut adalah praktik terbaik untuk membantu konfigurasi ini:
Pilih nama yang dengan jelas menunjukkan bahwa bucket hanya ditujukan untuk tabel Iceberg BigLake di BigQuery.
Pilih bucket Cloud Storage satu region yang ditempatkan bersama di region yang sama dengan set data BigQuery Anda. Koordinasi ini meningkatkan performa dan menurunkan biaya dengan menghindari biaya transfer data.
Secara default, Cloud Storage menyimpan data di class penyimpanan Standard, yang memberikan performa yang memadai. Untuk mengoptimalkan biaya penyimpanan data, Anda dapat mengaktifkan Autoclass untuk mengelola transisi kelas penyimpanan secara otomatis. Autoclass dimulai dengan kelas penyimpanan Standard dan memindahkan objek yang tidak diakses ke kelas yang semakin jarang diakses untuk mengurangi biaya penyimpanan. Saat objek dibaca lagi, objek tersebut akan dipindahkan kembali ke kelas Standard.
Aktifkan akses level bucket yang seragam dan pencegahan akses publik.
Pastikan peran yang diperlukan ditetapkan ke pengguna dan akun layanan yang benar.
Untuk mencegah penghapusan atau kerusakan data Iceberg yang tidak disengaja di bucket Cloud Storage Anda, batasi izin tulis dan hapus bagi sebagian besar pengguna di organisasi Anda. Anda dapat melakukannya dengan menetapkan kebijakan izin bucket dengan kondisi yang menolak permintaan
PUTdanDELETEuntuk semua pengguna, kecuali pengguna yang Anda tentukan.Terapkan kunci enkripsi yang dikelola Google atau yang dikelola pelanggan untuk perlindungan ekstra data sensitif.
Aktifkan logging audit untuk transparansi operasional, pemecahan masalah, dan pemantauan akses data.
Pertahankan kebijakan penghapusan sementara default (retensi 7 hari) untuk melindungi dari penghapusan yang tidak disengaja. Namun, jika Anda menemukan bahwa data Iceberg telah dihapus, hubungi dukungan, bukan memulihkan objek secara manual, karena objek yang ditambahkan atau diubah di luar BigQuery tidak dilacak oleh metadata BigQuery.
Penentuan ukuran file adaptif, pengelompokan otomatis, dan pengumpulan sampah diaktifkan secara otomatis dan membantu mengoptimalkan performa dan biaya file.
Hindari fitur Cloud Storage berikut, karena tidak didukung untuk tabel Iceberg BigLake di BigQuery:
- Namespace hierarkis
- Region ganda dan multi-region
- Daftar kontrol akses (ACL) objek
- Kunci enkripsi yang disediakan pelanggan
- Pembuatan versi objek
- Kunci objek
- Kunci bucket
- Memulihkan objek yang dihapus sementara dengan BigQuery API atau alat command line bq
Anda dapat menerapkan praktik terbaik ini dengan membuat bucket menggunakan perintah berikut:
gcloud storage buckets create gs://BUCKET_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --enable-autoclass \ --public-access-prevention \ --uniform-bucket-level-access
Ganti kode berikut:
BUCKET_NAME: nama untuk bucket baru AndaPROJECT_ID: ID project AndaLOCATION: lokasi untuk bucket baru Anda
Tabel Iceberg BigLake dalam alur kerja BigQuery
Bagian berikut menjelaskan cara membuat, memuat, mengelola, dan membuat kueri tabel terkelola.
Sebelum memulai
Sebelum membuat dan menggunakan tabel BigLake Iceberg di BigQuery, pastikan Anda telah menyiapkan Koneksi resource cloud ke bucket penyimpanan. Koneksi Anda memerlukan izin tulis pada bucket penyimpanan, seperti yang ditentukan di bagian Peran yang diperlukan berikut. Untuk mengetahui informasi selengkapnya tentang peran dan izin yang diperlukan untuk koneksi, lihat Mengelola koneksi.
Peran yang diperlukan
Untuk mendapatkan izin yang Anda perlukan agar BigQuery dapat mengelola tabel di project Anda, minta administrator Anda untuk memberi Anda peran IAM berikut:
-
Untuk membuat tabel BigLake Iceberg di BigQuery:
-
BigQuery Data Owner (
roles/bigquery.dataOwner) di project Anda -
BigQuery Connection Admin (
roles/bigquery.connectionAdmin) di project Anda
-
BigQuery Data Owner (
-
Untuk membuat kueri tabel BigLake Iceberg di BigQuery:
-
BigQuery Data Viewer (
roles/bigquery.dataViewer) di project Anda -
Pengguna BigQuery (
roles/bigquery.user) di project Anda
-
BigQuery Data Viewer (
-
Beri akun layanan koneksi peran berikut agar dapat membaca dan menulis data di Cloud Storage:
-
Storage Object User (
roles/storage.objectUser) di bucket -
Storage Legacy Bucket Reader (
roles/storage.legacyBucketReader) di bucket
-
Storage Object User (
Untuk mengetahui informasi selengkapnya tentang cara memberikan peran, baca artikel Mengelola akses ke project, folder, dan organisasi.
Peran bawaan ini berisi izin yang diperlukan agar BigQuery dapat mengelola tabel di project Anda. Untuk melihat izin yang benar-benar diperlukan, luaskan bagian Izin yang diperlukan:
Izin yang diperlukan
Izin berikut diperlukan agar BigQuery dapat mengelola tabel di project Anda:
-
bigquery.connections.delegatedi project Anda -
bigquery.jobs.createdi project Anda -
bigquery.readsessions.createdi project Anda -
bigquery.tables.createdi project Anda -
bigquery.tables.getdi project Anda -
bigquery.tables.getDatadi project Anda -
storage.buckets.getdi bucket Anda -
storage.objects.createdi bucket Anda -
storage.objects.deletedi bucket Anda -
storage.objects.getdi bucket Anda -
storage.objects.listdi bucket Anda
Anda mungkin juga bisa mendapatkan izin ini dengan peran khusus atau peran bawaan lainnya.
Membuat tabel Iceberg BigLake di BigQuery
Untuk membuat tabel BigLake Iceberg di BigQuery, pilih salah satu metode berikut:
SQL
CREATE TABLE [PROJECT_ID.]DATASET_ID.TABLE_NAME ( COLUMN DATA_TYPE[, ...] ) CLUSTER BY CLUSTER_COLUMN_LIST WITH CONNECTION {CONNECTION_NAME | DEFAULT} OPTIONS ( file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'STORAGE_URI');
Ganti kode berikut:
- PROJECT_ID: project yang berisi set data. Jika tidak ditentukan, perintah akan mengasumsikan project default.
- DATASET_ID: set data yang sudah ada.
- TABLE_NAME: nama tabel yang Anda buat.
- DATA_TYPE: jenis data informasi yang terkandung dalam kolom.
- CLUSTER_COLUMN_LIST (opsional): daftar yang dipisahkan koma yang berisi hingga empat kolom. Kolom ini harus berupa kolom tingkat atas yang tidak berulang.
CONNECTION_NAME: nama koneksi. Contoh,
myproject.us.myconnection.Untuk menggunakan koneksi default, tentukan
DEFAULT, bukan string koneksi yang berisi PROJECT_ID.REGION.CONNECTION_ID.STORAGE_URI: Cloud Storage URI yang sepenuhnya memenuhi syarat. Misalnya,
gs://mybucket/table.
bq
bq --project_id=PROJECT_ID mk \ --table \ --file_format=PARQUET \ --table_format=ICEBERG \ --connection_id=CONNECTION_NAME \ --storage_uri=STORAGE_URI \ --schema=COLUMN_NAME:DATA_TYPE[, ...] \ --clustering_fields=CLUSTER_COLUMN_LIST \ DATASET_ID.MANAGED_TABLE_NAME
Ganti kode berikut:
- PROJECT_ID: project yang berisi set data. Jika tidak ditentukan, perintah akan mengasumsikan project default.
- CONNECTION_NAME: nama koneksi. Contoh,
myproject.us.myconnection. - STORAGE_URI: Cloud Storage URI
yang sepenuhnya memenuhi syarat.
Misalnya,
gs://mybucket/table. - COLUMN_NAME: nama kolom.
- DATA_TYPE: jenis data informasi yang ada dalam kolom.
- CLUSTER_COLUMN_LIST (opsional): daftar yang dipisahkan koma yang berisi hingga empat kolom. Kolom ini harus berupa kolom tingkat atas yang tidak berulang.
- DATASET_ID: ID set data yang sudah ada.
- MANAGED_TABLE_NAME: nama tabel yang Anda buat.
API
Panggil metode
tables.insert'
dengan resource tabel yang ditentukan, mirip dengan
berikut ini:
{ "tableReference": { "tableId": "TABLE_NAME" }, "biglakeConfiguration": { "connectionId": "CONNECTION_NAME", "fileFormat": "PARQUET", "tableFormat": "ICEBERG", "storageUri": "STORAGE_URI" }, "schema": { "fields": [ { "name": "COLUMN_NAME", "type": "DATA_TYPE" } [, ...] ] } }
Ganti kode berikut:
- TABLE_NAME: nama tabel yang Anda buat.
- CONNECTION_NAME: nama koneksi. Contoh,
myproject.us.myconnection. - STORAGE_URI: Cloud Storage URI
yang sepenuhnya memenuhi syarat.
Karakter pengganti
juga didukung. Contoh,
gs://mybucket/table. - COLUMN_NAME: nama kolom.
- DATA_TYPE: jenis data informasi yang ada dalam kolom.
Mengimpor data ke tabel Iceberg BigLake di BigQuery
Bagian berikut menjelaskan cara mengimpor data dari berbagai format tabel ke dalam tabel Iceberg BigLake di BigQuery.
Memuat data standar dari file datar
Tabel Iceberg BigLake di BigQuery menggunakan tugas pemuatan BigQuery untuk memuat file eksternal ke tabel Iceberg BigLake di BigQuery. Jika Anda memiliki tabel Iceberg BigLake yang sudah ada di BigQuery, ikuti
panduan CLI bq load
atau
panduan SQL LOAD
untuk memuat data eksternal. Setelah memuat data, file Parquet baru akan ditulis
ke folder STORAGE_URI/data.
Jika petunjuk sebelumnya digunakan tanpa tabel BigLake Iceberg yang ada di BigQuery, tabel BigQuery akan dibuat.
Lihat contoh khusus alat berikut untuk pemuatan batch ke dalam tabel terkelola:
SQL
LOAD DATA INTO MANAGED_TABLE_NAME FROM FILES ( uris=['STORAGE_URI'], format='FILE_FORMAT');
Ganti kode berikut:
- MANAGED_TABLE_NAME: nama tabel Iceberg BigLake yang sudah ada di BigQuery.
- STORAGE_URI: Cloud Storage URI
yang sepenuhnya memenuhi syarat
atau daftar URI yang dipisahkan koma.
Karakter pengganti
juga didukung. Contoh,
gs://mybucket/table. - FILE_FORMAT: format tabel sumber. Untuk format yang didukung, lihat baris
formatdiload_option_list.
bq
bq load \ --source_format=FILE_FORMAT \ MANAGED_TABLE \ STORAGE_URI
Ganti kode berikut:
- FILE_FORMAT: format tabel sumber. Untuk format yang didukung, lihat baris
formatdiload_option_list. - MANAGED_TABLE_NAME: nama tabel Iceberg BigLake yang sudah ada di BigQuery.
- STORAGE_URI: Cloud Storage URI
yang sepenuhnya memenuhi syarat
atau daftar URI yang dipisahkan koma.
Karakter pengganti
juga didukung. Contoh,
gs://mybucket/table.
Pemuatan standar dari file yang dipartisi Hive
Anda dapat memuat file yang dipartisi Hive ke dalam tabel Iceberg BigLake di BigQuery menggunakan tugas pemuatan BigQuery standar. Untuk informasi selengkapnya, lihat Memuat data yang dipartisi secara eksternal.
Memuat data streaming dari Pub/Sub
Anda dapat memuat data streaming ke dalam tabel BigLake Iceberg di BigQuery menggunakan langganan Pub/Sub BigQuery.
Mengekspor data dari tabel BigLake Iceberg di BigQuery
Bagian berikut menjelaskan cara mengekspor data dari tabel Iceberg BigLake di BigQuery ke berbagai format tabel.
Mengekspor data ke dalam format datar
Untuk mengekspor tabel BigLake Iceberg di BigQuery ke dalam format datar, gunakan
pernyataan EXPORT DATA
dan pilih format tujuan. Untuk mengetahui informasi selengkapnya, lihat
Mengekspor data.
Membuat tabel Iceberg BigLake di snapshot metadata BigQuery
Untuk membuat tabel BigLake Iceberg di snapshot metadata BigQuery, ikuti langkah-langkah berikut:
Ekspor metadata ke format Iceberg V2 dengan pernyataan SQL
EXPORT TABLE METADATA.Opsional: Jadwalkan refresh snapshot metadata Iceberg. Untuk memuat ulang snapshot metadata Iceberg berdasarkan interval waktu yang ditetapkan, gunakan kueri terjadwal.
Opsional: Aktifkan pemuatan ulang otomatis metadata untuk project Anda guna memperbarui snapshot metadata tabel Iceberg secara otomatis pada setiap mutasi tabel. Untuk mengaktifkan pemuatan ulang otomatis metadata, hubungi bigquery-tables-for-apache-iceberg-help@google.com. Biaya
EXPORT METADATAditerapkan pada setiap operasi pemuatan ulang.
Contoh berikut membuat kueri terjadwal bernama My Scheduled Snapshot Refresh Query
menggunakan pernyataan DDL EXPORT TABLE METADATA FROM mydataset.test. Pernyataan DDL
dijalankan setiap 24 jam.
bq query \ --use_legacy_sql=false \ --display_name='My Scheduled Snapshot Refresh Query' \ --schedule='every 24 hours' \ 'EXPORT TABLE METADATA FROM mydataset.test'
Melihat tabel BigLake Iceberg di snapshot metadata BigQuery
Setelah memperbarui tabel BigLake Iceberg di snapshot metadata BigQuery, Anda dapat menemukan snapshot di URI Cloud Storage tempat tabel BigLake Iceberg di BigQuery awalnya dibuat. Folder /data
berisi sharding data file Parquet, dan folder /metadata berisi
snapshot metadata tabel BigLake Iceberg di BigQuery.
SELECT table_name, REGEXP_EXTRACT(ddl, r"storage_uri\s*=\s*\"([^\"]+)\"") AS storage_uri FROM `mydataset`.INFORMATION_SCHEMA.TABLES;
Perhatikan bahwa mydataset dan table_name adalah placeholder untuk set data dan tabel Anda yang sebenarnya.
Membaca tabel Iceberg BigLake di BigQuery dengan Apache Spark
Contoh berikut menyiapkan lingkungan Anda untuk menggunakan Spark SQL dengan Apache Iceberg, lalu menjalankan kueri untuk mengambil data dari tabel BigLake Iceberg tertentu di BigQuery.
spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-ICEBERG_VERSION_NUMBER \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.type=hadoop \ --conf spark.sql.catalog.CATALOG_NAME.warehouse='BUCKET_PATH' \ # Query the table SELECT * FROM CATALOG_NAME.FOLDER_NAME;
Ganti kode berikut:
- ICEBERG_VERSION_NUMBER: versi runtime Apache Spark Iceberg saat ini. Download versi terbaru dari Rilis Spark.
- CATALOG_NAME: katalog untuk mereferensikan tabel Iceberg BigLake Anda di BigQuery.
- BUCKET_PATH: jalur ke bucket yang berisi file tabel. Contoh,
gs://mybucket/. - FOLDER_NAME: folder yang berisi file tabel.
Contoh,
myfolder.
Mengubah tabel BigLake Iceberg di BigQuery
Untuk mengubah tabel BigLake Iceberg di BigQuery, ikuti langkah-langkah yang ditunjukkan di Mengubah skema tabel.
Menggunakan transaksi multi-pernyataan
Untuk mendapatkan akses ke transaksi multi-pernyataan untuk tabel Iceberg BigLake di BigQuery, isi formulir pendaftaran.
Harga
Harga tabel BigLake Iceberg di BigQuery terdiri dari penyimpanan, pengoptimalan penyimpanan, serta kueri dan pekerjaan.
Penyimpanan
Tabel Iceberg BigLake di BigQuery menyimpan semua data di Cloud Storage. Anda akan ditagih untuk semua data yang disimpan, termasuk data tabel historis. Biaya pemrosesan data dan transfer Cloud Storage juga mungkin berlaku. Beberapa biaya operasi Cloud Storage mungkin dibebaskan untuk operasi yang diproses melalui BigQuery atau BigQuery Storage API. Tidak ada biaya penyimpanan khusus BigQuery. Untuk mengetahui informasi selengkapnya, lihat Harga Cloud Storage.
Pengoptimalan penyimpanan
Tabel Iceberg BigLake di BigQuery melakukan pengelolaan tabel otomatis, termasuk pemadatan, pengelompokan, pengumpulan sampah, dan pembuatan/pembaruan metadata BigQuery untuk mengoptimalkan performa kueri dan mengurangi biaya penyimpanan. Penggunaan resource komputasi untuk pengelolaan tabel BigLake ditagih dalam Unit Komputasi Data (DCU) dari waktu ke waktu, dalam peningkatan per detik. Untuk mengetahui detail selengkapnya, lihat Harga tabel Iceberg BigLake di BigQuery.
Operasi ekspor data yang terjadi saat melakukan streaming melalui BigQuery Storage Write API disertakan dalam harga Storage Write API dan tidak ditagih sebagai pemeliharaan latar belakang. Untuk mengetahui informasi selengkapnya, lihat Harga penyerapan data.
Pengoptimalan penyimpanan dan penggunaan EXPORT TABLE METADATA dapat dilihat di tampilan INFORMATION_SCHEMA.JOBS.
Kueri dan tugas
Mirip dengan tabel BigQuery, Anda akan ditagih untuk kueri dan byte yang dibaca (per TiB) jika Anda menggunakan harga BigQuery sesuai permintaan, atau penggunaan slot (per jam slot) jika Anda menggunakan harga komputasi kapasitas BigQuery.
Harga BigQuery juga berlaku untuk BigQuery Storage Read API dan BigQuery Storage Write API.
Operasi pemuatan dan ekspor (seperti EXPORT METADATA) menggunakan
slot bayar sesuai penggunaan edisi Enterprise.
Hal ini berbeda dengan tabel BigQuery, yang tidak dikenai biaya untuk
operasi ini. Jika pemesanan PIPELINE dengan slot Enterprise atau Enterprise Plus tersedia, operasi pemuatan dan ekspor akan lebih memilih menggunakan slot pemesanan ini.
Batasan
Tabel BigLake Iceberg di BigQuery memiliki batasan berikut:
- Tabel Iceberg BigLake di BigQuery tidak mendukung
operasi penggantian nama atau
pernyataan
ALTER TABLE RENAME TO. - Tabel Iceberg BigLake di BigQuery tidak mendukung
salinan tabel atau
pernyataan
CREATE TABLE COPY. - Tabel Iceberg BigLake di BigQuery tidak mendukung
klon tabel atau
pernyataan
CREATE TABLE CLONE. - Tabel Iceberg BigLake di BigQuery tidak mendukung
snapshot tabel atau
pernyataan
CREATE SNAPSHOT TABLE. - Tabel Iceberg BigLake di BigQuery tidak mendukung skema tabel berikut:
- Skema kosong
- Skema dengan jenis data
BIGNUMERIC,INTERVAL,JSON,RANGE, atauGEOGRAPHY. - Skema dengan kolasi kolom.
- Skema dengan ekspresi nilai default.
- Tabel Iceberg BigLake di BigQuery tidak mendukung kasus evolusi skema berikut:
- Pemaksaan jenis
NUMERICkeFLOAT - Pemaksaan jenis
INTkeFLOAT - Menambahkan kolom bertingkat baru ke kolom
RECORDyang sudah ada menggunakan pernyataan DDL SQL
- Pemaksaan jenis
- Tabel Iceberg BigLake di BigQuery menampilkan ukuran penyimpanan 0 byte saat dikueri oleh konsol atau API.
- Tabel Iceberg BigLake di BigQuery tidak mendukung tampilan terwujud.
- Tabel Iceberg BigLake di BigQuery tidak mendukung tampilan yang diotorisasi, tetapi kontrol akses tingkat kolom didukung.
- Tabel Iceberg BigLake di BigQuery tidak mendukung pembaruan change data capture (CDC).
- Tabel BigLake Iceberg di BigQuery tidak mendukung pemulihan dari bencana yang dikelola
- Tabel BigLake Iceberg di BigQuery tidak mendukung partisi. Pertimbangkan pengelompokan sebagai alternatif.
- Tabel Iceberg BigLake di BigQuery tidak mendukung keamanan tingkat baris.
- Tabel Iceberg BigLake di BigQuery tidak mendukung periode fail-safe.
- Tabel Iceberg BigLake di BigQuery tidak mendukung tugas ekstrak.
- Tampilan
INFORMATION_SCHEMA.TABLE_STORAGEtidak menyertakan tabel Iceberg BigLake di BigQuery. - Tabel Iceberg BigLake di BigQuery tidak didukung sebagai tujuan hasil kueri. Sebagai gantinya, Anda dapat menggunakan pernyataan
CREATE TABLEdengan argumenAS query_statementuntuk membuat tabel sebagai tujuan hasil kueri. CREATE OR REPLACEtidak mendukung penggantian tabel standar dengan tabel BigLake Iceberg di BigQuery, atau tabel BigLake Iceberg di BigQuery dengan tabel standar.- Pemuatan batch dan
pernyataan
LOAD DATAhanya mendukung penambahan data ke tabel BigLake Iceberg yang ada di BigQuery. - Pemuatan batch dan
pernyataan
LOAD DATAtidak mendukung pembaruan skema. TRUNCATE TABLEtidak mendukung tabel BigLake Iceberg di BigQuery. Ada dua alternatif:CREATE OR REPLACE TABLE, menggunakan opsi pembuatan tabel yang sama.DELETE FROMtabelWHEREbenar (true)
- Fungsi bernilai tabel (TVF)
APPENDStidak mendukung tabel Iceberg BigLake di BigQuery. - Metadata Iceberg mungkin tidak berisi data yang di-streaming ke BigQuery oleh Storage Write API dalam 90 menit terakhir.
- Akses berpenomoran halaman berbasis rekaman menggunakan
tabledata.listtidak mendukung tabel BigLake Iceberg di BigQuery. - Tabel Iceberg BigLake di BigQuery tidak mendukung set data tertaut.
- Hanya satu pernyataan DML bermutasi serentak (
UPDATE,DELETE, danMERGE) yang dijalankan untuk setiap tabel BigLake Iceberg di BigQuery. Pernyataan DML bermutasi tambahan dimasukkan ke dalam antrean.