Tabelas do BigLake para Apache Iceberg no BigQuery
As tabelas do BigLake para Apache Iceberg no BigQuery (doravante tabelas do BigLake Iceberg no BigQuery) fornecem a base para criar lakehouses de formato aberto no Google Cloud. As tabelas do BigLake Iceberg no BigQuery oferecem a mesma experiência totalmente gerenciada das tabelas padrão do BigQuery, mas armazenam dados em buckets de armazenamento de propriedade do cliente. As tabelas do BigLake Iceberg no BigQuery são compatíveis com o formato de tabela aberta do Iceberg para melhorar a interoperabilidade com mecanismos de computação de código aberto e de terceiros em uma única cópia de dados.
As tabelas do BigLake para Apache Iceberg no BigQuery são diferentes das tabelas externas do Apache Iceberg. As tabelas do BigLake para Apache Iceberg no BigQuery são totalmente gerenciadas e podem ser modificadas diretamente no BigQuery. Já as tabelas externas do Apache Iceberg são gerenciadas pelo cliente e oferecem acesso somente leitura do BigQuery.
As tabelas do BigLake Iceberg no BigQuery oferecem suporte aos seguintes recursos:
- Mutações de tabela usando a linguagem de manipulação de dados (DML) do GoogleSQL.
- Streaming unificado de lote e de alta capacidade de processamento usando a API StorageWrite com os conectores do BigLake como Spark, Dataflow e outros mecanismos.
- Exportação de snapshots do Iceberg V2 e atualização automática em cada mutação de tabela para acesso direto a consultas com mecanismos de consulta de código aberto e de terceiros.
- Evolução do esquema, que permite adicionar, soltar e renomear colunas para atender às suas necessidades. Com esse recurso, também é possível mudar o tipo de dados de uma coluna atual e o modo de coluna. Para mais informações, consulte as regras de conversão de tipo.
- Otimização automática de armazenamento, incluindo dimensionamento adaptável de arquivos, clustering automático, coleta de lixo e otimização de metadados.
- Viagem no tempo para acesso a dados históricos no BigQuery.
- Segurança no nível da coluna e mascaramento de dados.
- Transações com várias instruções (em pré-lançamento).
Arquitetura
As tabelas do BigLake Iceberg no BigQuery trazem a conveniência do gerenciamento de recursos do BigQuery para tabelas que residem nos seus próprios buckets da nuvem. É possível usar o BigQuery e mecanismos de computação de código aberto nessas tabelas sem mover os dados dos buckets que você controla. É necessário configurar um bucket do Cloud Storage antes de começar a usar tabelas do BigLake Iceberg no BigQuery.
As tabelas do BigLake Iceberg no BigQuery usam o metastore do BigLake como o metastore unificado de tempo de execução para todos os dados do Iceberg. O BigLake Metastore oferece uma única fonte de verdade para gerenciar metadados de vários mecanismos e permite a interoperabilidade entre eles.
O diagrama a seguir mostra a arquitetura da tabela gerenciada em um nível alto:
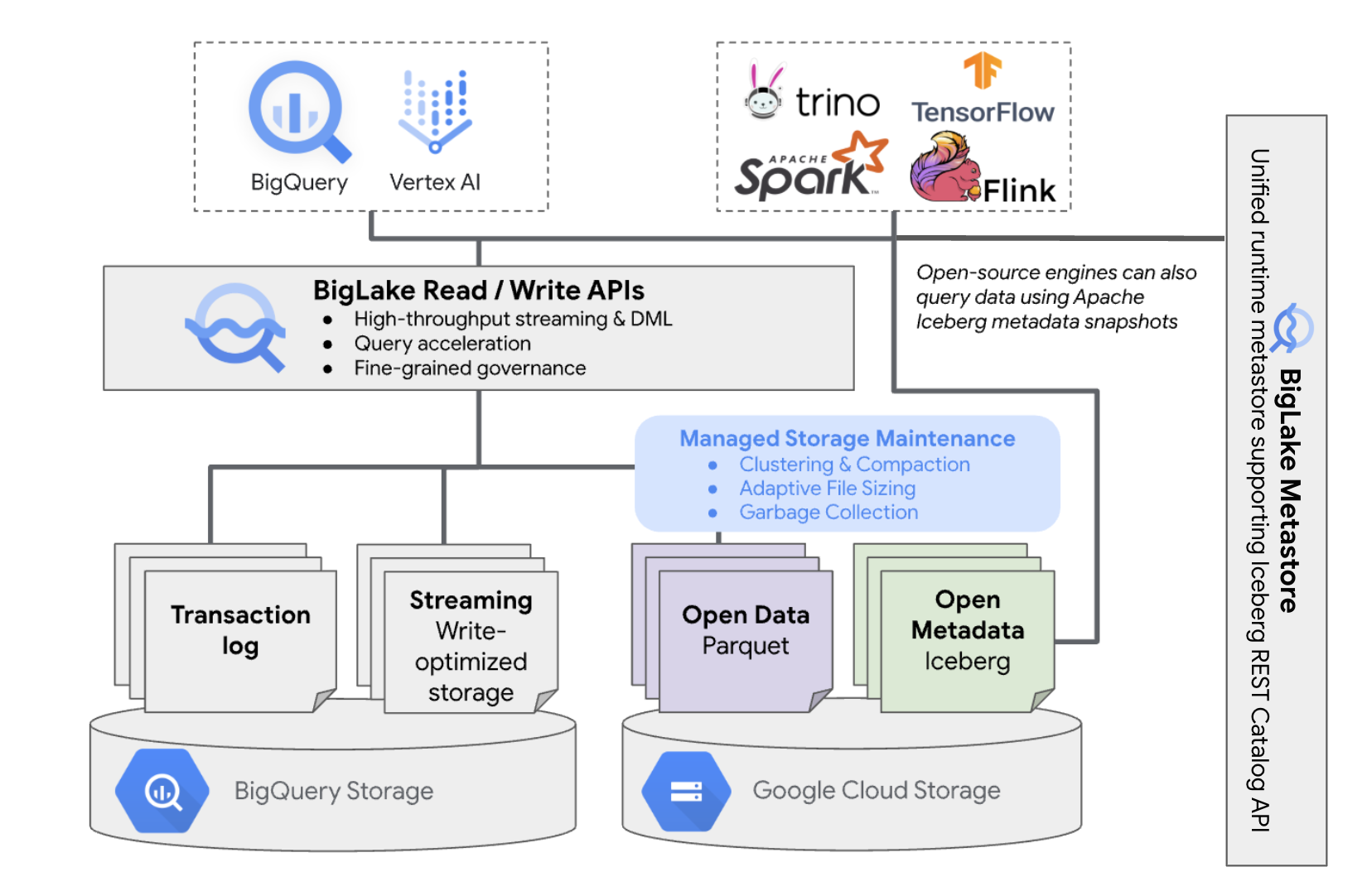
O gerenciamento de tabelas tem as seguintes implicações no seu bucket:
- O BigQuery cria novos arquivos de dados no bucket em resposta a solicitações de gravação e otimizações de armazenamento em segundo plano, como instruções DML e streaming.
- Quando você exclui uma tabela gerenciada no BigQuery, o BigQuery coleta lixo dos arquivos de dados associados no Cloud Storage após o vencimento do período de viagem no tempo.
Criar uma tabela do BigLake Iceberg no BigQuery é semelhante a criar tabelas do BigQuery. Como ele armazena dados em formatos abertos no Cloud Storage, você precisa fazer o seguinte:
- Especifique a
conexão de recurso do Cloud
com
WITH CONNECTIONpara configurar as credenciais de conexão para o BigLake acessar o Cloud Storage. - Especifique o formato do arquivo de armazenamento de dados como
PARQUETcom a instruçãofile_format = PARQUET. - Especifique o formato da tabela de metadados de código aberto como
ICEBERGcom a instruçãotable_format = ICEBERG.
Práticas recomendadas
Mudar ou adicionar arquivos diretamente ao bucket fora do BigQuery pode causar perda de dados ou erros irrecuperáveis. A tabela a seguir descreve os possíveis cenários:
| Operação | Consequências | Prevenção |
|---|---|---|
| Adicione novos arquivos ao bucket fora do BigQuery. | Perda de dados:novos arquivos ou objetos adicionados fora do BigQuery não são rastreados por ele. Os arquivos não rastreados são excluídos por processos de coleta de lixo em segundo plano. | Adicione dados exclusivamente pelo BigQuery. Isso permite que o
BigQuery rastreie os arquivos e evite que eles sejam
coletados como lixo. Para evitar adições acidentais e perda de dados, também recomendamos restringir as permissões de gravação de ferramentas externas em buckets que contenham tabelas Iceberg do BigLake no BigQuery. |
| Crie uma tabela do BigLake Iceberg no BigQuery em um prefixo não vazio. | Perda de dados:os dados atuais não são rastreados pelo BigQuery. Portanto, esses arquivos são considerados não rastreados e excluídos por processos de coleta de lixo em segundo plano. | Crie apenas tabelas do BigLake Iceberg no BigQuery em prefixos vazios. |
| Modificar ou substituir a tabela do BigLake Iceberg em arquivos de dados do BigQuery. | Perda de dados:em caso de modificação ou substituição externa,
a tabela não passa em uma verificação de consistência e fica ilegível. As consultas na tabela falham. Não há uma maneira de se recuperar desse ponto por conta própria. Entre em contato com o suporte para receber ajuda com a recuperação de dados. |
Modifique os dados exclusivamente pelo BigQuery. Isso permite que o
BigQuery rastreie os arquivos e evite que eles sejam
coletados como lixo. Para evitar adições acidentais e perda de dados, também recomendamos restringir as permissões de gravação de ferramentas externas em buckets que contenham tabelas Iceberg do BigLake no BigQuery. |
| Crie duas tabelas do BigLake Iceberg no BigQuery com URIs iguais ou sobrepostos. | Perda de dados:o BigQuery não faz ponte entre instâncias de URI idênticas de tabelas do BigLake Iceberg no BigQuery. Os processos de coleta de lixo em segundo plano de cada tabela vão considerar os arquivos da tabela oposta como não rastreados e os excluir, causando perda de dados. | Use URIs exclusivos para cada tabela do BigLake Iceberg no BigQuery. |
Práticas recomendadas para a configuração de buckets do Cloud Storage
A configuração do bucket do Cloud Storage e a conexão dele com o BigLake têm um impacto direto no desempenho, custo, integridade, segurança e governança dos dados das tabelas do BigLake Iceberg no BigQuery. Confira a seguir as práticas recomendadas para ajudar nessa configuração:
Escolha um nome que indique claramente que o bucket é destinado apenas a tabelas Iceberg do BigLake no BigQuery.
Escolha buckets do Cloud Storage de região única que estejam localizados na mesma região que o conjunto de dados do BigQuery. Essa coordenação melhora o desempenho e reduz os custos evitando cobranças de transferência de dados.
Por padrão, o Cloud Storage armazena dados na classe de armazenamento Standard, que oferece desempenho suficiente. Para otimizar os custos de armazenamento de dados, ative a Classe automática para gerenciar automaticamente as transições de classe de armazenamento. A classe automática começa com a classe de armazenamento padrão e move objetos que não são acessados para classes progressivamente mais frias para reduzir os custos de armazenamento. Quando o objeto é lido novamente, ele é movido de volta para a classe Standard.
Ative o acesso uniforme no nível do bucket e a prevenção de acesso público.
Verifique se os papéis necessários estão atribuídos aos usuários e contas de serviço corretos.
Para evitar a exclusão ou corrupção acidental de dados do Iceberg no bucket do Cloud Storage, restrinja as permissões de gravação e exclusão para a maioria dos usuários na sua organização. Para isso, defina uma política de permissão de bucket com condições que neguem solicitações
PUTeDELETEpara todos os usuários, exceto aqueles que você especificar.Aplique chaves de criptografia gerenciadas pelo Google ou pelo cliente para ter mais proteção de dados sensíveis.
Ative o registro de auditoria para ter transparência operacional, resolver problemas e monitorar o acesso a dados.
Mantenha a política de exclusão reversível padrão (retenção de 7 dias) para proteger contra exclusões acidentais. No entanto, se você descobrir que os dados do Iceberg foram excluídos, entre em contato com o suporte em vez de restaurar objetos manualmente. Isso porque os objetos adicionados ou modificados fora do BigQuery não são rastreados pelos metadados do BigQuery.
O dimensionamento adaptativo de arquivos, o clustering automático e a coleta de lixo são ativados automaticamente e ajudam a otimizar o desempenho e o custo dos arquivos.
Evite os seguintes recursos do Cloud Storage, porque eles não são compatíveis com tabelas do BigLake Iceberg no BigQuery:
- Namespaces hierárquicos
- Birregionais e multirregionais
- Listas de controle de acesso (ACLs) de objetos
- Chaves de criptografia fornecidas pelo cliente
- Controle de versões de objetos
- Bloqueio de objeto
- Bloqueio de bucket
- Como restaurar objetos excluídos temporariamente com a API BigQuery ou a ferramenta de linha de comando bq
Para implementar essas práticas recomendadas, crie seu bucket com o seguinte comando:
gcloud storage buckets create gs://BUCKET_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --enable-autoclass \ --public-access-prevention \ --uniform-bucket-level-access
Substitua:
BUCKET_NAME: o nome do novo bucketPROJECT_ID: ID do projetoLOCATION: o local do novo bucket
Tabela do BigLake Iceberg em fluxos de trabalho do BigQuery
As seções a seguir descrevem como criar, carregar, gerenciar e consultar tabelas gerenciadas.
Antes de começar
Antes de criar e usar tabelas Iceberg do BigLake no BigQuery, verifique se você configurou uma conexão de recursos do Cloud com um bucket de armazenamento. Sua conexão precisa de permissões de gravação no bucket de armazenamento, conforme especificado na seção Funções necessárias a seguir. Para mais informações sobre os papéis e as permissões necessárias para conexões, consulte Gerenciar conexões.
Funções exigidas
Para ter as permissões necessárias para permitir que o BigQuery gerencie tabelas no seu projeto, peça ao administrador para conceder a você os seguintes papéis do IAM:
-
Para criar tabelas do BigLake Iceberg no BigQuery:
-
Proprietário de dados do BigQuery (
roles/bigquery.dataOwner) no seu projeto -
Administrador de conexão do BigQuery (
roles/bigquery.connectionAdmin) no seu projeto
-
Proprietário de dados do BigQuery (
-
Para consultar tabelas do BigLake Iceberg no BigQuery:
-
Leitor de dados do BigQuery (
roles/bigquery.dataViewer) no seu projeto -
Usuário do BigQuery (
roles/bigquery.user) no seu projeto
-
Leitor de dados do BigQuery (
-
Conceda à conta de serviço de conexão os seguintes papéis para que ela possa ler e gravar dados no Cloud Storage:
-
Usuário do objeto de armazenamento (
roles/storage.objectUser) no bucket -
Leitor de bucket legado do Storage (
roles/storage.legacyBucketReader) no bucket
-
Usuário do objeto de armazenamento (
Para mais informações sobre a concessão de papéis, consulte Gerenciar o acesso a projetos, pastas e organizações.
Esses papéis predefinidos contêm as permissões necessárias para permitir que o BigQuery gerencie tabelas no seu projeto. Para conferir as permissões exatas necessárias, expanda a seção Permissões necessárias:
Permissões necessárias
As seguintes permissões são necessárias para permitir que o BigQuery gerencie tabelas no seu projeto:
-
bigquery.connections.delegateno seu projeto -
bigquery.jobs.createno seu projeto -
bigquery.readsessions.createno seu projeto -
bigquery.tables.createno seu projeto -
bigquery.tables.getno seu projeto -
bigquery.tables.getDatano seu projeto -
storage.buckets.getno seu bucket -
storage.objects.createno seu bucket -
storage.objects.deleteno seu bucket -
storage.objects.getno seu bucket -
storage.objects.listno seu bucket
Essas permissões também podem ser concedidas com funções personalizadas ou outros papéis predefinidos.
Criar tabelas do BigLake Iceberg no BigQuery
Para criar uma tabela do BigLake Iceberg no BigQuery, selecione um dos seguintes métodos:
SQL
CREATE TABLE [PROJECT_ID.]DATASET_ID.TABLE_NAME ( COLUMN DATA_TYPE[, ...] ) CLUSTER BY CLUSTER_COLUMN_LIST WITH CONNECTION {CONNECTION_NAME | DEFAULT} OPTIONS ( file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'STORAGE_URI');
Substitua:
- PROJECT_ID: o projeto que contém o conjunto de dados. Se não for definido, o comando vai usar o projeto padrão.
- DATASET_ID: um conjunto de dados existente.
- TABLE_NAME: o nome da tabela que você está criando;
- DATA_TYPE: o tipo de dados das informações contidas na coluna.
- CLUSTER_COLUMN_LIST: uma lista separada por vírgulas com até quatro colunas. Elas precisam ser de nível superior e sem repetição.
CONNECTION_NAME: o nome da conexão. Por exemplo,
myproject.us.myconnection.Para usar uma conexão padrão, especifique
DEFAULTem vez da string de conexão que contém PROJECT_ID.REGION.CONNECTION_ID.STORAGE_URI: um URI do Cloud Storage totalmente qualificado. Por exemplo,
gs://mybucket/table.
bq
bq --project_id=PROJECT_ID mk \ --table \ --file_format=PARQUET \ --table_format=ICEBERG \ --connection_id=CONNECTION_NAME \ --storage_uri=STORAGE_URI \ --schema=COLUMN_NAME:DATA_TYPE[, ...] \ --clustering_fields=CLUSTER_COLUMN_LIST \ DATASET_ID.MANAGED_TABLE_NAME
Substitua:
- PROJECT_ID: o projeto que contém o conjunto de dados. Se não for definido, o comando vai usar o projeto padrão.
- CONNECTION_NAME: o nome da conexão. Por exemplo,
myproject.us.myconnection. - STORAGE_URI: um URI do Cloud Storage totalmente qualificado.
Por exemplo,
gs://mybucket/table. - COLUMN_NAME: o nome da coluna.
- DATA_TYPE: o tipo de dados das informações contidas na coluna.
- CLUSTER_COLUMN_LIST: uma lista separada por vírgulas com até quatro colunas. Elas precisam ser de nível superior e sem repetição.
- DATASET_ID: o ID de um conjunto de dados.
- MANAGED_TABLE_NAME: o nome da tabela que você está criando.
API
Chame o método
tables.insert
com um
recurso de tabela definido, semelhante ao
seguinte:
{ "tableReference": { "tableId": "TABLE_NAME" }, "biglakeConfiguration": { "connectionId": "CONNECTION_NAME", "fileFormat": "PARQUET", "tableFormat": "ICEBERG", "storageUri": "STORAGE_URI" }, "schema": { "fields": [ { "name": "COLUMN_NAME", "type": "DATA_TYPE" } [, ...] ] } }
Substitua:
- TABLE_NAME: o nome da tabela que você está criando.
- CONNECTION_NAME: o nome da conexão. Por exemplo,
myproject.us.myconnection. - STORAGE_URI: um URI do Cloud Storage totalmente qualificado.
Os caracteres curinga também são compatíveis. Por exemplo,
gs://mybucket/table. - COLUMN_NAME: o nome da coluna.
- DATA_TYPE: o tipo de dados das informações contidas na coluna.
Importar dados para tabelas do BigLake Iceberg no BigQuery
As seções a seguir descrevem como importar dados de vários formatos de tabela para tabelas Iceberg do BigLake no BigQuery.
Carregar dados padrão de arquivos simples
As tabelas do BigLake Iceberg no BigQuery usam jobs de carregamento do BigQuery para
carregar arquivos externos
em tabelas do BigLake Iceberg no BigQuery. Se você já tiver uma tabela do BigLake Iceberg no BigQuery, siga o guia da CLI bq load ou o guia de SQL LOAD para carregar dados externos. Depois de carregar os dados, novos arquivos Parquet são gravados na pasta STORAGE_URI/data.
Se as instruções anteriores forem usadas sem uma tabela do BigLake Iceberg no BigQuery, uma tabela do BigQuery será criada.
Confira a seguir exemplos específicos de ferramentas de carregamentos em lote para tabelas gerenciadas:
SQL
LOAD DATA INTO MANAGED_TABLE_NAME FROM FILES ( uris=['STORAGE_URI'], format='FILE_FORMAT');
Substitua:
- MANAGED_TABLE_NAME: o nome de uma tabela do BigLake Iceberg no BigQuery.
- STORAGE_URI: um
URI do Cloud Storage
totalmente qualificado ou uma lista de URIs
separados por vírgulas.
Os caracteres curinga também são compatíveis. Por exemplo,
gs://mybucket/table. - FILE_FORMAT: o formato da tabela de origem. Para saber quais formatos são aceitos,
consulte a linha
formatdeload_option_list.
bq
bq load \ --source_format=FILE_FORMAT \ MANAGED_TABLE \ STORAGE_URI
Substitua:
- FILE_FORMAT: o formato da tabela de origem. Para saber quais formatos são aceitos,
consulte a linha
formatdeload_option_list. - MANAGED_TABLE_NAME: o nome de uma tabela do BigLake Iceberg no BigQuery.
- STORAGE_URI: um
URI do Cloud Storage
totalmente qualificado ou uma lista de URIs
separados por vírgulas.
Os caracteres curinga também são compatíveis. Por exemplo,
gs://mybucket/table.
Carga padrão de arquivos particionados do Hive
É possível carregar arquivos particionados pelo Hive em tabelas do BigLake Iceberg no BigQuery usando jobs de carregamento padrão do BigQuery. Para mais informações, consulte Como carregar dados particionados externamente.
Carregar dados de streaming do Pub/Sub
É possível carregar dados de streaming em tabelas do BigLake Iceberg no BigQuery usando uma assinatura do Pub/Sub BigQuery.
Exportar dados de tabelas do BigLake Iceberg no BigQuery
As seções a seguir descrevem como exportar dados de tabelas Iceberg do BigLake no BigQuery para vários formatos de tabela.
Exportar dados para formatos simples
Para exportar uma tabela Iceberg do BigLake no BigQuery para um formato simples, use a
instrução EXPORT DATA
e selecione um formato de destino. Para mais informações, consulte
Como exportar dados.
Criar uma tabela do BigLake Iceberg em snapshots de metadados do BigQuery
Para criar uma tabela do BigLake Iceberg em um snapshot de metadados do BigQuery, siga estas etapas:
Exporte os metadados para o formato Iceberg V2 com a instrução SQL
EXPORT TABLE METADATA.Opcional: agende a atualização do snapshot de metadados do Iceberg. Para atualizar um snapshot de metadados do Iceberg com base em um intervalo de tempo definido, use uma consulta programada.
Opcional: ative a atualização automática de metadados para que seu projeto atualize automaticamente o snapshot de metadados da tabela do Iceberg em cada mutação de tabela. Para ativar a atualização automática de metadados, entre em contato com bigquery-tables-for-apache-iceberg-help@google.com. Os custos do
EXPORT METADATAsão aplicados em cada operação de atualização.
O exemplo a seguir cria uma consulta programada chamada My Scheduled Snapshot Refresh Query
usando a instrução DDL EXPORT TABLE METADATA FROM mydataset.test. A instrução DDL é executada a cada 24 horas.
bq query \ --use_legacy_sql=false \ --display_name='My Scheduled Snapshot Refresh Query' \ --schedule='every 24 hours' \ 'EXPORT TABLE METADATA FROM mydataset.test'
Ver a tabela do BigLake Iceberg no snapshot de metadados do BigQuery
Depois de atualizar o snapshot de metadados da tabela do BigLake Iceberg no BigQuery, você pode encontrar o snapshot no URI do Cloud Storage em que a tabela do BigLake Iceberg no BigQuery foi criada originalmente. A pasta /data contém os fragmentos de dados do arquivo Parquet, e a pasta /metadata contém a tabela do BigLake Iceberg no snapshot de metadados do BigQuery.
SELECT table_name, REGEXP_EXTRACT(ddl, r"storage_uri\s*=\s*\"([^\"]+)\"") AS storage_uri FROM `mydataset`.INFORMATION_SCHEMA.TABLES;
mydataset e table_name são marcadores de posição para seu conjunto de dados e tabela reais.
Ler tabelas do BigLake Iceberg no BigQuery com o Apache Spark
O exemplo a seguir configura seu ambiente para usar o Spark SQL com o Apache Iceberg e executa uma consulta para buscar dados de uma tabela especificada do BigLake Iceberg no BigQuery.
spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-ICEBERG_VERSION_NUMBER \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.type=hadoop \ --conf spark.sql.catalog.CATALOG_NAME.warehouse='BUCKET_PATH' \ # Query the table SELECT * FROM CATALOG_NAME.FOLDER_NAME;
Substitua:
- ICEBERG_VERSION_NUMBER: a versão atual do ambiente de execução do Apache Spark Iceberg. Faça o download da versão mais recente em Lançamentos do Spark.
- CATALOG_NAME: o catálogo para referenciar sua tabela Iceberg do BigLake no BigQuery.
- BUCKET_PATH: o caminho para o bucket que contém os arquivos da tabela. Por exemplo,
gs://mybucket/. - FOLDER_NAME: a pasta que contém os arquivos da tabela.
Por exemplo,
myfolder.
Modificar tabelas do BigLake Iceberg no BigQuery
Para modificar uma tabela do BigLake Iceberg no BigQuery, siga as etapas mostradas em Como modificar esquemas de tabelas.
Usar transações com várias instruções
Para ter acesso a transações com várias instruções para tabelas do BigLake Iceberg no BigQuery, preencha o formulário de inscrição.
Preços
O preço da tabela do BigLake Iceberg no BigQuery consiste em armazenamento, otimização de armazenamento e consultas e jobs.
Armazenamento
As tabelas do BigLake Iceberg no BigQuery armazenam todos os dados no Cloud Storage. Você recebe cobranças por todos os dados armazenados, incluindo dados históricos de tabelas. Também podem ser aplicadas taxas de processamento e transferência de dados do Cloud Storage. Algumas taxas de operação do Cloud Storage podem ser dispensadas para operações processadas pelo BigQuery ou pela API BigQuery Storage. Não há taxas de armazenamento específicas do BigQuery. Para mais informações, consulte Preços do Cloud Storage.
Otimização de armazenamento
As tabelas do BigLake Iceberg no BigQuery realizam a otimização automática do armazenamento, incluindo dimensionamento adaptativo de arquivos, clustering automático, coleta de lixo e otimização de metadados. Essas operações de otimização usam slots de pagamento por uso da edição Enterprise e não usam reservas BACKGROUND atuais.
As operações de exportação de dados realizadas durante o streaming pela API BigQuery Storage Write estão incluídas nos preços da API Storage Write e não são cobradas como manutenção em segundo plano. Para mais informações, consulte Preços de ingestão de dados do BigQuery.
A otimização de armazenamento e o uso do EXPORT TABLE METADATA são visíveis na visualização INFORMATION_SCHEMA.JOBS.
Consultas e jobs
Assim como nas tabelas do BigQuery, você vai receber cobranças por consultas e bytes lidos (por TiB) se estiver usando o preço on demand do BigQuery ou o consumo de slots (por hora de slot) se estiver usando o preço de computação de capacidade do BigQuery.
Os preços do BigQuery também se aplicam à API BigQuery Storage Read e à API BigQuery Storage Write.
As operações de carga e exportação (como EXPORT METADATA) usam slots de pagamento por uso da edição Enterprise.
Isso é diferente das tabelas do BigQuery, que não são cobradas por essas operações. Se houver reservas PIPELINE com slots do Enterprise ou do Enterprise Plus disponíveis, as operações de carga e exportação usarão preferencialmente esses slots de reserva.
Limitações
As tabelas do BigLake Iceberg no BigQuery têm as seguintes limitações:
- As tabelas do BigLake Iceberg no BigQuery não são compatíveis com
operações de renomeação nem
instruções
ALTER TABLE RENAME TO. - As tabelas do BigLake Iceberg no BigQuery não são compatíveis com
cópias de tabelas nem com
instruções
CREATE TABLE COPY. - As tabelas do BigLake Iceberg no BigQuery não são compatíveis com
clones de tabela nem com
instruções
CREATE TABLE CLONE. - As tabelas do BigLake Iceberg no BigQuery não são compatíveis com
snapshots de tabela nem com
instruções
CREATE SNAPSHOT TABLE. - As tabelas do BigLake Iceberg no BigQuery não oferecem suporte ao seguinte esquema de tabela:
- Esquema vazio
- Esquema com tipos de dados
BIGNUMERIC,INTERVAL,JSON,RANGEouGEOGRAPHY. - Esquema com agrupamentos de campos.
- Esquema com expressões de valor padrão.
- As tabelas do BigLake Iceberg no BigQuery não são compatíveis com os seguintes casos de evolução de esquema:
- Coerções de tipo de
NUMERICparaFLOAT - Coerções de tipo de
INTparaFLOAT - Adicionar novos campos aninhados a colunas
RECORDusando instruções DDL SQL
- Coerções de tipo de
- As tabelas do BigLake Iceberg no BigQuery mostram um tamanho de armazenamento de 0 byte quando consultadas pelo console ou pelas APIs.
- As tabelas do BigLake Iceberg no BigQuery não são compatíveis com visualizações materializadas.
- As tabelas do BigLake Iceberg no BigQuery não são compatíveis com visualizações autorizadas, mas controle de acesso no nível da coluna é compatível.
- As tabelas do BigLake Iceberg no BigQuery não são compatíveis com atualizações de captura de dados alterados (CDC).
- As tabelas do BigLake Iceberg no BigQuery não são compatíveis com a recuperação de desastres gerenciada.
- As tabelas do BigLake Iceberg no BigQuery não são compatíveis com particionamento. Considere o clustering como uma alternativa.
- As tabelas do BigLake Iceberg no BigQuery não são compatíveis com a segurança no nível da linha.
- As tabelas do BigLake Iceberg no BigQuery não são compatíveis com janelas à prova de falhas.
- As tabelas do BigLake Iceberg no BigQuery não são compatíveis com jobs de extração.
- A visualização
INFORMATION_SCHEMA.TABLE_STORAGEnão inclui tabelas do BigLake Iceberg no BigQuery. - As tabelas do BigLake Iceberg no BigQuery não são compatíveis como destinos de resultados de consultas. Em vez disso, use a instrução
CREATE TABLEcom o argumentoAS query_statementpara criar uma tabela como o destino do resultado da consulta. - O
CREATE OR REPLACEnão permite substituir tabelas padrão por tabelas Iceberg do BigLake no BigQuery, nem tabelas Iceberg do BigLake no BigQuery por tabelas padrão. - O carregamento em lote e as
instruções
LOAD DATAsó permitem anexar dados a tabelas atuais do BigLake Iceberg no BigQuery. - O carregamento em lote e as
instruções
LOAD DATAnão são compatíveis com atualizações de esquema. - O
TRUNCATE TABLEnão é compatível com tabelas do BigLake Iceberg no BigQuery. Existem duas alternativas:CREATE OR REPLACE TABLE, usando as mesmas opções de criação de tabela.DELETE FROMtabelaWHEREtrue
- A
função com valor de tabela (TVF)
APPENDSnão é compatível com tabelas do BigLake Iceberg no BigQuery. - Os metadados do Iceberg podem não conter dados transmitidos para o BigQuery pela API Storage Write nos últimos 90 minutos.
- O acesso paginado com base em registros usando
tabledata.listnão é compatível com tabelas do BigLake Iceberg no BigQuery. - As tabelas do BigLake Iceberg no BigQuery não são compatíveis com conjuntos de dados vinculados.
- Apenas uma instrução DML mutante simultânea (
UPDATE,DELETEeMERGE) é executada para cada tabela do BigLake Iceberg no BigQuery. Outras instruções DML mutantes são enfileiradas.