Recuperação de desastres gerenciada
Neste documento, apresentamos uma visão geral da recuperação de desastres gerenciada do BigQuery e como implementá-la para seus dados e cargas de trabalho.
Informações gerais
O BigQuery oferece suporte a cenários de recuperação de desastres no caso de uma interrupção total da região. A recuperação de desastres do BigQuery depende da replicação do conjunto de dados entre regiões para gerenciar o failover de armazenamento. Depois de criar uma réplica de conjunto de dados em uma região secundária, é possível controlar o comportamento do failover para computação e armazenamento para manter a continuidade de negócios durante uma interrupção. Após um failover, é possível acessar a capacidade de computação (slots) e os conjuntos de dados replicados na região promovida. A recuperação de desastres só é compatível com a edição Enterprise Plus.
A recuperação de desastres gerenciada oferece duas opções de failover: rígido e
suave. Um failover rígido promove imediatamente as réplicas de reserva e do conjunto de dados da região secundária para se tornarem as principais. Essa ação continua
mesmo que a região primária atual esteja off-line e não aguarde a
replicação de dados não replicados. Por isso, pode ocorrer perda de dados
durante o failover rígido.
Todos os jobs que confirmaram dados na região de origem antes do valor de
replication_time
da réplica podem precisar ser executados novamente na região de destino após o failover.
Ao contrário de um failover rígido, um failover suave espera até que todas as alterações de reserva
e do conjunto de dados confirmadas na região principal sejam replicadas para a
região secundária antes de concluir o processo de failover. Um failover parcial
exige que as regiões principal e secundária estejam disponíveis.
Ao iniciar um failover parcial, o softFailoverStartTime
da reserva é definido. O softFailoverStartTime
é limpo quando o failover reversível é concluído.
Para ativar a recuperação de desastres, é necessário criar uma reserva da edição Enterprise Plus na região principal, que é a região em que o conjunto de dados se encontra antes do failover. A capacidade de computação em espera na região pareada está incluída na reserva do Enterprise Plus. Em seguida, anexe um conjunto de dados a essa reserva para ativar o failover para esse conjunto de dados. Só é possível anexar um conjunto de dados a uma reserva se ele tiver sido preenchido e tiver os mesmos locais primário e secundário pareado que a reserva. Depois que um conjunto de dados é anexado a uma reserva de failover, somente as reservas do Enterprise Plus podem gravar nesses conjuntos de dados, e não é possível realizar uma promoção de replicação entre regiões. É possível ler conjuntos de dados anexados a uma reserva de failover com qualquer modelo de capacidade. Para mais informações sobre reservas, consulte Introdução ao gerenciamento de cargas de trabalho.
A capacidade de computação da região principal fica disponível na região secundária imediatamente após um failover. Essa disponibilidade se aplica ao valor de referência da reserva, seja ela usada ou não.
Você precisa optar ativamente pelo failover como parte do teste ou em resposta a um desastre real. Você não deve fazer o failover mais de uma vez em um intervalo de 10 minutos. Em cenários de replicação de dados, o preenchimento refere-se ao processo de preencher uma réplica de um conjunto de dados com dados históricos que existiam antes da réplica ser criada ou ficar ativa. Os conjuntos de dados precisam concluir o preenchimento antes que você possa fazer o failover para o conjunto de dados.
O diagrama a seguir mostra a arquitetura da recuperação de desastres gerenciada:
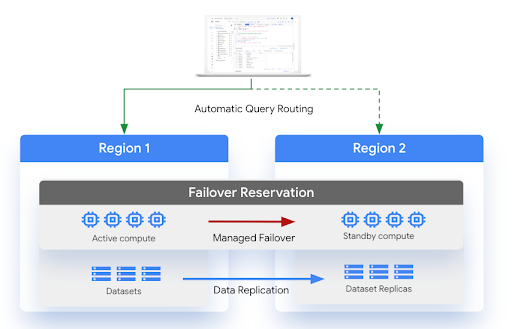
Limitações
As seguintes limitações se aplicam à recuperação de desastres do BigQuery:
A recuperação de desastres do BigQuery está sujeita às mesmas limitações da replicação de conjuntos de dados entre regiões.
O escalonamento automático após um failover depende da disponibilidade da capacidade de computação na região secundária. Apenas o valor de referência da reserva está disponível na região secundária.
A visualização
INFORMATION_SCHEMA.RESERVATIONSnão tem detalhes de failover.Se você tiver várias reservas de failover com o mesmo projeto de administração, mas com conjuntos de dados anexados que usam locais secundários diferentes, não use uma reserva de failover com os conjuntos de dados anexados a uma outra reserva de failover.
Se você quiser converter uma reserva atual em uma reserva de failover, ela não poderá ter mais de 1.000 atribuições de reserva.
Uma reserva de failover não pode ter mais de 1.000 conjuntos de dados anexados.
O failover parcial só pode ser acionado se as regiões de origem e de destino estiverem disponíveis.
O failover suave não pode ser acionado se houver erros temporários ou de outra forma durante a replicação da reserva. Por exemplo, se não houver cota de slots suficiente na região secundária para a atualização da reserva.
A reserva e os conjuntos de dados anexados não podem ser atualizados durante um failover suave ativo, mas ainda podem ser lidos.
Os jobs em execução em uma reserva de failover durante um failover flexível ativo podem não ser executados na reserva devido a mudanças temporárias no conjunto de dados e no roteamento da reserva durante a operação de failover. No entanto, esses jobs vão usar os slots de reserva antes e depois de qualquer failover parcial.
Locais
As seguintes regiões estão disponíveis ao criar uma reserva de failover:
| Código de localização | Nome da região | Descrição do local regional |
|---|---|---|
ASIA |
||
ASIA-EAST1 |
Taiwan | |
ASIA-SOUTHEAST1 |
Singapura | |
AU |
||
AUSTRALIA-SOUTHEAST1 |
Sydney | |
AUSTRALIA-SOUTHEAST2 |
Melbourne | |
CA |
||
NORTHAMERICA-NORTHEAST1 |
Montreal | |
NORTHAMERICA-NORTHEAST2 |
Toronto | |
DE |
||
EUROPE-WEST3 |
Frankfurt | |
EUROPE-WEST10 |
Berlim | |
EU |
||
EU |
UE multirregião | |
EUROPE-CENTRAL2 |
Varsóvia | |
EUROPE-NORTH1 |
Finlândia | |
EUROPE-SOUTHWEST1 |
Madri | |
EUROPE-WEST1 |
Bélgica | |
EUROPE-WEST3 |
Frankfurt | |
EUROPE-WEST4 |
Países Baixos | |
EUROPE-WEST8 |
Milão | |
EUROPE-WEST9 |
Paris | |
IN |
||
ASIA-SOUTH1 |
Mumbai | |
ASIA-SOUTH2 |
Délhi | |
US |
||
US |
EUA multirregião | |
US-CENTRAL1 |
Iowa | |
US-EAST1 |
Carolina do Sul | |
US-EAST4 |
Norte da Virgínia | |
US-EAST5 |
Columbus | |
US-SOUTH1 |
Dallas | |
US-WEST1 |
Oregon | |
US-WEST2 |
Los Angeles | |
US-WEST3 |
Salt Lake City | |
US-WEST4 |
Las Vegas |
Os pares de regiões precisam ser selecionados em ASIA, AU, CA, DE, EU, IN ou US. Por exemplo, uma região em US não pode ser pareada com uma região em EU.
Se o conjunto de dados do BigQuery estiver em um local multirregional, não será possível usar os seguintes pares de regiões. Essa limitação é necessária para garantir que sua reserva de failover e seus dados sejam separados geograficamente após a replicação. Para mais informações sobre regiões contidas em multirregiões, consulte Multirregiões.
us-central1-usmultirregionalus-west1-usmultirregionaleu-west1-eumultirregionaleu-west4-eumultirregional
Antes de começar
- Verifique se você tem a permissão
bigquery.reservations.updatedo Identity and Access Management (IAM) para atualizar reservas. - Verifique se você tem conjuntos de dados configurados para replicação. Para mais informações, consulte Criar um conjunto de dados
Replicação turbo
A recuperação de desastres usa a replicação turbo para acelerar a replicação de dados entre regiões, o que reduz o risco de exposição à perda de dados, minimiza o tempo de inatividade do serviço e ajuda a oferecer suporte a serviços sem interrupções após uma falha temporária regional.
A replicação turbo não se aplica à operação inicial de preenchimento. Depois que a operação inicial de preenchimento for concluída, a replicação turbo vai replicar conjuntos de dados para um único par de região de failover com uma réplica secundária em até 15 minutos, desde que a cota de largura de banda não seja excedida e não haja erros do usuário.
Objetivo do tempo de recuperação
Um objetivo de tempo de recuperação (RTO) é o tempo pretendido permitido para recuperação no BigQuery em caso de desastre. Para mais informações sobre o RTO, consulte Noções básicas do planejamento de DR.A recuperação de desastres gerenciada tem um RTO de cinco minutos depois que você inicia um failover. Devido ao RTO, a capacidade fica disponível na região secundária em até cinco minutos após o início do processo de failover.
Objetivo do ponto de recuperação
Um objetivo do ponto de recuperação (RPO) é o ponto mais recente em que os dados precisam ser restaurados. Para mais informações sobre o RPO, consulte Princípios básicos do planejamento de DR. A recuperação de desastres gerenciada tem um RPO definido por conjunto de dados. O RPO visa manter a réplica secundária em até 15 minutos da primária. Para atender a esse RPO, não é possível exceder a cota de largura de banda, e não pode haver erros do usuário.
Cota
Escolha a capacidade de computação na região secundária antes de configurar uma reserva de failover. Se não houver cota disponível na região secundária, não será possível configurar ou atualizar a reserva. Para mais informações, consulte Cotas e limites.
A largura de banda da replicação turbo tem cota. Para mais informações, consulte Cotas e limites.
Preços
A configuração da recuperação de desastres gerenciada requer os seguintes planos de preços:
Capacidade de computação: você precisa comprar a edição Enterprise Plus.
Replicação turbo: a recuperação de desastres depende da replicação turbo durante a replicação. A cobrança é feita com base em bytes físicos e por GiB replicado. Para mais informações, consulte Preços de transferência de dados de replicação para replicação turbo.
Armazenamento: os bytes de armazenamento na região secundária são cobrados com o mesmo preço que os bytes de armazenamento na região principal. Para mais informações, consulte preços de armazenamento.
Os clientes só precisam pagar pela capacidade de computação na região principal. A capacidade de computação secundária (com base no valor de referência de reserva) está disponível na região secundária sem custo extra. Slots inativos não podem usar a capacidade de computação secundária, a menos que a reserva tenha falhado.
Se você precisar executar leituras desatualizadas na região secundária, compre capacidade de computação adicional.
Criar ou alterar uma reserva do Enterprise Plus
Antes de anexar um conjunto de dados a uma reserva, crie uma reserva do Enterprise Plus ou altere uma reserva atual e configure-a para recuperação de desastres.
Criar uma reserva
Selecione uma destas opções:
Console
No console do Google Cloud , acesse a página BigQuery.
No menu de navegação, clique em Gerenciamento de capacidade e em Criar reserva.
No campo Nome da reserva, insira um nome para a reserva.
Na lista Local, selecione um local.
Na lista Edição, selecione a edição Enterprise Plus.
Na lista Seletor de tamanho máximo da reserva, escolha o tamanho máximo da reserva.
Opcional: no campo Slots de valor de referência, insira o número de slots de valor de referência para a reserva.
O número de slots de escalonamento automático disponíveis é determinado subtraindo o valor Slots de referência do valor do Tamanho máximo da reserva. Por exemplo, se você criar uma reserva com 100 slots de valor de referência e um tamanho máximo de 400, sua reserva terá 300 slots de escalonamento automático. Para mais informações sobre slots de valor de referência, consulte Como usar reservas com slots de valor de referência e de escalonamento automático.
Na lista Local secundário, selecione o local secundário.
Para desativar o compartilhamento de slots inativos e usar apenas a capacidade de slot especificada, clique em Ignorar slots inativos.
Para expandir a seção Configurações avançadas, clique na seta .
Opcional: para definir a simultaneidade do job de destino, ative a opção Modificar simultaneidade automática do job de destino e insira um valor em Simultaneidade do job de destino. O detalhamento de slots é exibido na tabela Estimativa de custo. Um resumo da reserva será exibido na tabela Resumo da capacidade.
Clique em Salvar.
A nova reserva fica visível na guia Reservas de slots.
SQL
Para criar uma reserva, use a
instrução de linguagem de definição de dados (DDL) CREATE RESERVATION.
No console do Google Cloud , acesse a página BigQuery.
No editor de consultas, digite a seguinte instrução:
CREATE RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` OPTIONS ( slot_capacity = NUMBER_OF_BASELINE_SLOTS, edition = ENTERPRISE_PLUS, secondary_location = SECONDARY_LOCATION);
Substitua:
ADMIN_PROJECT_ID: o ID do projeto de administração que é proprietário do recurso de reserva.LOCATION: o local da reserva. Se você selecionar um local do BigQuery Omni, sua opção de edição será limitada à edição Enterprise.RESERVATION_NAME: o nome da reserva.Ele precisa começar e terminar com uma letra minúscula ou um número e conter apenas letras minúsculas, números e traços.
NUMBER_OF_BASELINE_SLOTS: o número de slots de referência que serão alocados para a reserva. Não é possível definir a opçãoslot_capacityeeditionna mesma reserva.SECONDARY_LOCATION: o local secundário da reserva. Em caso de interrupção, todos os conjuntos de dados anexados a essa reserva vão fazer failover para esse local.
Clique em Executar.
Para mais informações sobre como executar consultas, acesse Executar uma consulta interativa.
Alterar uma reserva existente
Selecione uma destas opções:
Console
No console do Google Cloud , acesse a página BigQuery.
No menu de navegação, clique em Gerenciamento de capacidade.
Clique na guia Reservas de slots.
Encontre a reserva que você quer atualizar.
Clique em Ações de reservas e em Editar.
No campo Local secundário, insira o local secundário.
Clique em Salvar.
SQL
Para adicionar ou alterar um local secundário de uma reserva, use a
instrução DDL ALTER RESERVATION SET OPTIONS.
No console do Google Cloud , acesse a página BigQuery.
No editor de consultas, digite a seguinte instrução:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( secondary_location = SECONDARY_LOCATION);
Substitua:
ADMIN_PROJECT_ID: o ID do projeto de administração que é proprietário do recurso de reserva.LOCATION: o local da reserva, por exemplo,europe-west9.RESERVATION_NAME: o nome da reserva. Ele precisa começar e terminar com uma letra minúscula ou um número e conter apenas letras minúsculas, números e traços.SECONDARY_LOCATION: o local secundário da reserva. Em caso de interrupção, todos os conjuntos de dados anexados a essa reserva vão fazer failover para esse local.
Clique em Executar.
Para mais informações sobre como executar consultas, acesse Executar uma consulta interativa.
Anexar um conjunto de dados a uma reserva
Para ativar a recuperação de desastres para a reserva criada anteriormente, conclua as etapas a seguir. O conjunto de dados já precisa estar configurado para replicação nas mesmas regiões primária e secundária que a reserva. Para mais informações, consulte Replicação de conjuntos de dados entre regiões.
Console
No console do Google Cloud , acesse a página BigQuery.
No menu de navegação, clique em Gerenciamento de capacidade e, em seguida, na guia Reservas de slot.
Clique na reserva a que você quer anexar um conjunto de dados.
Clique na guia Recuperação de desastres.
Clique em Adicionar conjunto de dados de failover.
Insira o nome do conjunto de dados que você quer associar à reserva.
Clique em Adicionar.
SQL
Para anexar um conjunto de dados a uma reserva, use a
instrução DDL ALTER SCHEMA SET OPTIONS.
No console do Google Cloud , acesse a página BigQuery.
No editor de consultas, digite a seguinte instrução:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = ADMIN_PROJECT_ID.RESERVATION_NAME);
Substitua:
DATASET_NAME: o nome do conjunto de dados.ADMIN_PROJECT_ID.RESERVATION_NAME: o nome da reserva a que você quer associar o conjunto de dados.
Clique em Executar.
Para mais informações sobre como executar consultas, acesse Executar uma consulta interativa.
Desvincular um conjunto de dados de uma reserva
Para interromper o gerenciamento do comportamento de failover de um conjunto de dados por meio de uma reserva, desvincule o conjunto de dados da reserva. Isso não muda a réplica principal atual do conjunto de dados nem remove as réplicas do conjunto de dados. Para mais informações sobre como remover réplicas de conjuntos de dados depois de desconectar um conjunto de dados, consulte Remover réplica de conjunto de dados.
Console
No console do Google Cloud , acesse a página BigQuery.
No menu de navegação, clique em Gerenciamento de capacidade e, em seguida, na guia Reservas de slot.
Clique na reserva de que você quer remover um conjunto de dados.
Clique na guia Recuperação de desastres.
Expanda a opção Ações para a réplica principal do conjunto de dados.
Clique em Remover.
SQL
Para desconectar um conjunto de dados de uma reserva, use a
instrução DDL ALTER SCHEMA SET OPTIONS.
No console do Google Cloud , acesse a página BigQuery.
No editor de consultas, digite a seguinte instrução:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = NULL);
Substitua:
DATASET_NAME: o nome do conjunto de dados.
Clique em Executar.
Para mais informações sobre como executar consultas, acesse Executar uma consulta interativa.
Iniciar um failover
No caso de uma interrupção regional, você precisa fazer o failover manual de sua reserva para o local usado pela réplica. O failover da reserva também inclui todos os conjuntos de dados associados. Para fazer o failover manual de uma reserva, faça o seguinte:
Console
No console do Google Cloud , acesse a página BigQuery.
No menu de navegação, clique em Recuperação de desastres.
Clique no nome da reserva em que você quer fazer o failover.
Selecione Modo de failover rígido (padrão) ou Modo de failover flexível.
Clique em Failover.
SQL
Para adicionar ou alterar um local secundário de uma reserva, use a
instrução DDL ALTER RESERVATION SET OPTIONS e defina is_primary como TRUE.
No console do Google Cloud , acesse a página BigQuery.
No editor de consultas, digite a seguinte instrução:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( is_primary = TRUE, failover_mode=FAILOVER_MODE);
Substitua:
ADMIN_PROJECT_ID: o ID do projeto de administração que é proprietário do recurso de reserva.LOCATION: o novo local principal da reserva, ou seja, o local secundário atual antes do failover. Por exemplo,europe-west9.RESERVATION_NAME: o nome da reserva. Ele precisa começar e terminar com uma letra minúscula ou um número e conter apenas letras minúsculas, números e traços.PRIMARY_STATUS: um status booleano que declara se a reserva é a réplica principal.FAILOVER_MODE: um parâmetro opcional usado para descrever o modo de failover. Pode ser definido comoHARDouSOFT. Se esse parâmetro não for especificado,HARDserá usado por padrão.
Clique em Executar.
Para mais informações sobre como executar consultas, acesse Executar uma consulta interativa.
Monitoramento
Para determinar o estado das réplicas, consulte a
visualização INFORMATION_SCHEMA.SCHEMATA_REPLICAS. Exemplo:
SELECT schema_name, replica_name, creation_complete, replica_primary_assigned, replica_primary_assignment_complete FROM `region-LOCATION`.INFORMATION_SCHEMA.SCHEMATA_REPLICAS WHERE schema_name="my_dataset"
A consulta a seguir retorna os jobs dos últimos sete dias que falhariam se os conjuntos de dados fossem de failover:
WITH non_epe_reservations AS ( SELECT project_id, reservation_name FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.RESERVATIONS WHERE edition != 'ENTERPRISE_PLUS' ) SELECT * FROM ( SELECT job_id FROM ( SELECT job_id, reservation_id, ARRAY_CONCAT(referenced_tables, [destination_table]) AS all_referenced_tables, query FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.JOBS WHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP() ) A, UNNEST(all_referenced_tables) AS referenced_table ) jobs LEFT OUTER JOIN non_epe_reservations ON ( jobs.reservation_id = CONCAT( non_epe_reservations.project_id, ':', 'LOCATION', '.', non_epe_reservations.reservation_name)) WHERE CONCAT(jobs.project_id, ':', jobs.dataset_id) IN UNNEST( [ 'PROJECT_ID:DATASET_ID', 'PROJECT_ID:DATASET_ID']);
Substitua:
PROJECT_ID: o ID do projeto;DATASET_ID: o código do conjunto de dados.LOCATION: o local.
A seguir
Saiba mais sobre a replicação de conjuntos de dados entre regiões.
Saiba mais sobre confiabilidade.