Tabelas do BigLake para o Apache Iceberg no BigQuery
As tabelas do BigLake para o Apache Iceberg no BigQuery (doravante, tabelas do BigLake Iceberg no BigQuery) fornecem a base para criar data lakes de formato aberto no Google Cloud. As tabelas Iceberg do BigLake no BigQuery oferecem a mesma experiência totalmente gerida que as tabelas padrão do BigQuery, mas armazenam dados em contentores de armazenamento pertencentes ao cliente. As tabelas Iceberg do BigLake no BigQuery suportam o formato de tabela Iceberg aberto para uma melhor interoperabilidade com motores de computação de código aberto e de terceiros numa única cópia de dados.
As tabelas do BigLake para o Apache Iceberg no BigQuery são distintas das tabelas externas do Apache Iceberg. As tabelas BigLake para o Apache Iceberg no BigQuery são tabelas totalmente geridas que são modificáveis diretamente no BigQuery, enquanto as tabelas externas do Apache Iceberg são geridas pelo cliente e oferecem acesso só de leitura a partir do BigQuery.
As tabelas Iceberg do BigLake no BigQuery suportam as seguintes funcionalidades:
- Mutações de tabelas através da linguagem de manipulação de dados (DML) do GoogleSQL.
- Processamento em lote unificado e streaming de elevado débito através da API Storage Write através de conetores do BigLake, como o Spark, o Dataflow e outros motores.
- Exportação de instantâneos do Iceberg V2 e atualização automática em cada mutação de tabela para acesso direto a consultas com código aberto e motores de consultas de terceiros.
- Evolução do esquema, que lhe permite adicionar, eliminar e mudar o nome das colunas de acordo com as suas necessidades. Esta funcionalidade também permite alterar o tipo de dados de uma coluna existente e o modo de coluna. Para mais informações, consulte as regras de conversão de tipo.
- Otimização automática do armazenamento, incluindo o dimensionamento adaptativo de ficheiros, o agrupamento automático, a recolha de lixo e a otimização de metadados.
- Viagem no tempo para acesso aos dados do histórico no BigQuery.
- Segurança ao nível da coluna e ocultação de dados.
- Transações com várias declarações (em pré-visualização).
Arquitetura
As tabelas Iceberg do BigLake no BigQuery oferecem a conveniência da gestão de recursos do BigQuery a tabelas que residem nos seus próprios contentores na nuvem. Pode usar o BigQuery e motores de computação de código aberto nestas tabelas sem mover os dados para fora dos contentores que controla. Tem de configurar um contentor do Cloud Storage antes de começar a usar tabelas Iceberg do BigLake no BigQuery.
As tabelas Iceberg do BigLake no BigQuery usam o metastore do BigLake como o metastore de tempo de execução unificado para todos os dados Iceberg. O metastore do BigLake oferece uma única fonte de dados reais para gerir metadados de vários motores e permite a interoperabilidade dos motores.
O diagrama seguinte mostra a arquitetura da tabela gerida a um nível elevado:
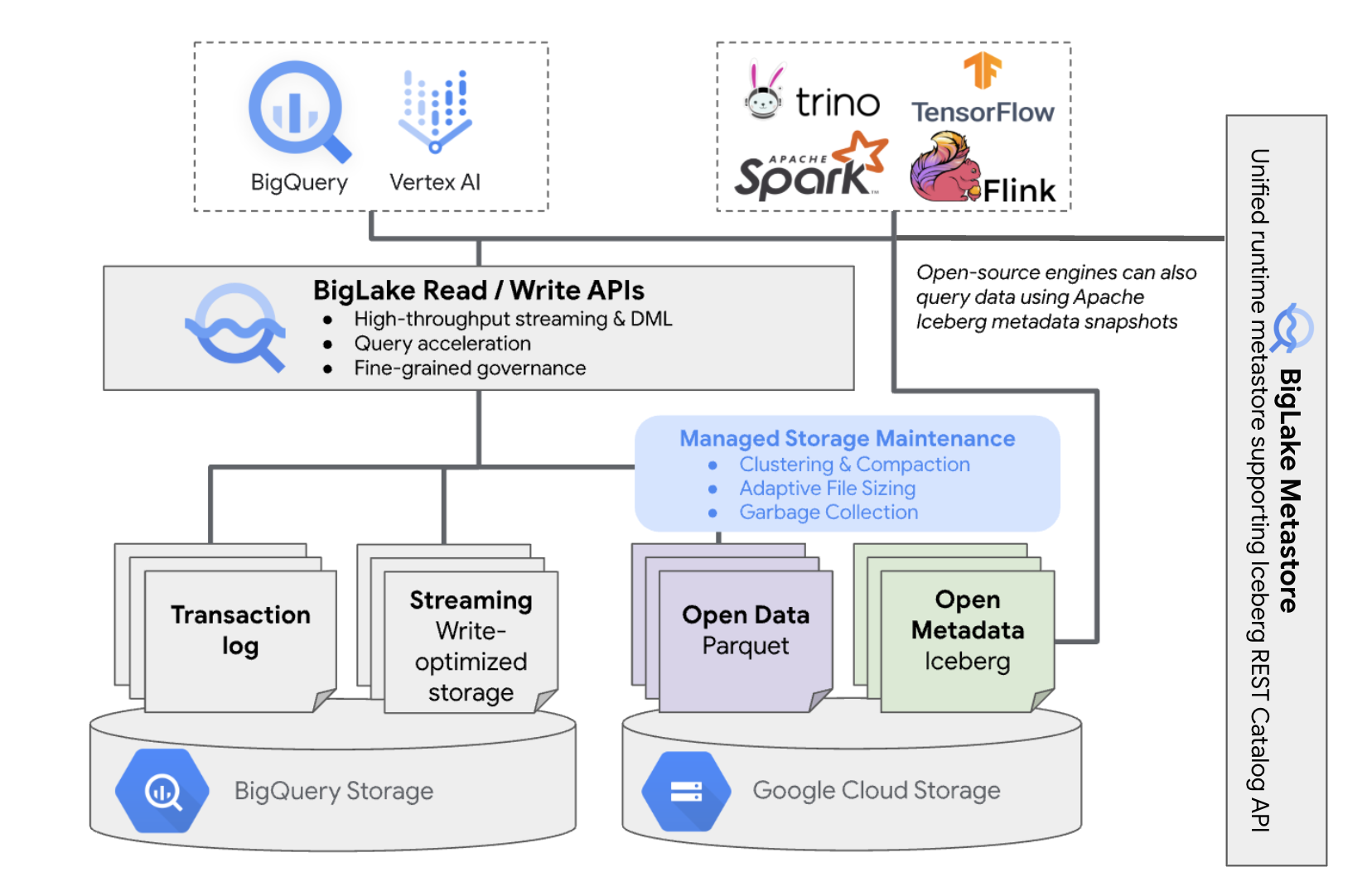
Esta gestão de tabelas tem as seguintes implicações no seu contentor:
- O BigQuery cria novos ficheiros de dados no contentor em resposta a pedidos de escrita e otimizações de armazenamento em segundo plano, como declarações DML e streaming.
- Quando elimina uma tabela gerida no BigQuery, o BigQuery recolhe o lixo dos ficheiros de dados associados no Cloud Storage após a expiração do período de viagem no tempo.
A criação de uma tabela Iceberg do BigLake no BigQuery é semelhante à criação de tabelas do BigQuery. Uma vez que armazena dados em formatos abertos no Cloud Storage, tem de fazer o seguinte:
- Especifique a
associação de recursos da nuvem
com
WITH CONNECTIONpara configurar as credenciais de associação para o BigLake aceder ao Cloud Storage. - Especifique o formato de ficheiro de armazenamento de dados como
PARQUETcom a declaraçãofile_format = PARQUET. - Especifique o formato da tabela de metadados de código aberto como
ICEBERGcom a declaraçãotable_format = ICEBERG.
Práticas recomendadas
A alteração ou a adição direta de ficheiros ao contentor fora do BigQuery pode originar perda de dados ou erros irrecuperáveis. A tabela seguinte descreve possíveis cenários:
| Operação | Consequências | Prevenção |
|---|---|---|
| Adicione novos ficheiros ao contentor fora do BigQuery. | Perda de dados: o BigQuery não acompanha novos ficheiros ou objetos adicionados fora do BigQuery. Os ficheiros não monitorizados são eliminados por processos de recolha de lixo em segundo plano. | Adicionar dados exclusivamente através do BigQuery. Isto permite ao BigQuery monitorizar os ficheiros e impedir que sejam recolhidos como lixo. Para evitar adições acidentais e perda de dados, também recomendamos restringir as autorizações de escrita de ferramentas externas em contentores que contenham tabelas Iceberg do BigLake no BigQuery. |
| Crie uma nova tabela Iceberg do BigLake no BigQuery num prefixo não vazio. | Perda de dados: os dados existentes não são monitorizados pelo BigQuery, pelo que estes ficheiros são considerados não monitorizados e eliminados pelos processos de recolha de lixo em segundo plano. | Crie apenas novas tabelas Iceberg do BigLake no BigQuery em prefixos vazios. |
| Modificar ou substituir a tabela Iceberg do BigLake em ficheiros de dados do BigQuery. | Perda de dados: na modificação ou substituição externa,
a tabela falha numa verificação de consistência e torna-se ilegível. As consultas
na tabela falham. Não existe uma forma autónoma de recuperar a conta a partir deste ponto. Contacte o apoio técnico para receber assistência na recuperação de dados. |
Modificar dados exclusivamente através do BigQuery. Isto permite ao BigQuery monitorizar os ficheiros e impedir que sejam recolhidos como lixo. Para evitar adições acidentais e perda de dados, também recomendamos restringir as autorizações de escrita de ferramentas externas em contentores que contenham tabelas Iceberg do BigLake no BigQuery. |
| Crie duas tabelas Iceberg do BigLake no BigQuery com URIs iguais ou sobrepostas. | Perda de dados: o BigQuery não faz a ponte de instâncias de URI idênticas de tabelas Iceberg do BigLake no BigQuery. Os processos de recolha de lixo em segundo plano para cada tabela consideram os ficheiros da tabela oposta como não monitorizados e eliminam-nos, o que provoca a perda de dados. | Use URIs únicos para cada tabela Iceberg do BigLake no BigQuery. |
Práticas recomendadas de configuração do contentor do Cloud Storage
A configuração do seu contentor do Cloud Storage e a respetiva ligação ao BigLake têm um impacto direto no desempenho, no custo, na integridade dos dados, na segurança e na administração das suas tabelas Iceberg do BigLake no BigQuery. Seguem-se as práticas recomendadas para ajudar com esta configuração:
Selecione um nome que indique claramente que o contentor se destina apenas a tabelas Iceberg do BigLake no BigQuery.
Escolha contentores do Cloud Storage de região única que estejam localizados na mesma região que o seu conjunto de dados do BigQuery. Esta coordenação melhora o desempenho e reduz os custos, evitando cobranças de transferência de dados.
Por predefinição, o Cloud Storage armazena dados na classe de armazenamento Standard, que oferece um desempenho suficiente. Para otimizar os custos de armazenamento de dados, pode ativar a Autoclass para gerir automaticamente as transições da classe de armazenamento. O Autoclass começa com a classe de armazenamento Standard e move os objetos que não são acedidos para classes progressivamente mais frias de modo a reduzir os custos de armazenamento. Quando o objeto é lido novamente, é movido novamente para a classe Standard.
Ative o acesso uniforme ao nível do contentor e a prevenção de acesso público.
Confirme se as funções necessárias estão atribuídas aos utilizadores e às contas de serviço corretos.
Para evitar a eliminação ou a danificação acidental de dados do Iceberg no seu contentor do Cloud Storage, restrinja as autorizações de escrita e eliminação para a maioria dos utilizadores na sua organização. Pode fazê-lo definindo uma política de autorização de contentores com condições que negam pedidos
PUTeDELETEpara todos os utilizadores, exceto os que especificar.Aplique chaves de encriptação geridas pela Google ou geridas pelo cliente para proteção adicional de dados confidenciais.
Ative o registo de auditoria para a transparência operacional, a resolução de problemas e o acesso aos dados de monitorização.
Mantenha a política de eliminação temporária predefinida (retenção de 7 dias) para se proteger contra eliminações acidentais. No entanto, se verificar que os dados do Iceberg foram eliminados, contacte o apoio técnico em vez de restaurar objetos manualmente, uma vez que os objetos adicionados ou modificados fora do BigQuery não são monitorizados pelos metadados do BigQuery.
O dimensionamento adaptativo dos ficheiros, a agrupagem automática e a recolha de lixo são ativados automaticamente e ajudam a otimizar o desempenho e o custo dos ficheiros.
Evite as seguintes funcionalidades do Cloud Storage, uma vez que não são suportadas para tabelas Iceberg do BigLake no BigQuery:
- Espaços de nomes hierárquicos
- Regiões duplas e várias regiões
- Listas de controlo de acesso (LCAs) de objetos
- Chaves de encriptação fornecidas pelos clientes
- Controlo de versões de objetos
- Bloqueio de objetos
- Bloqueio de contentores
- Restaurar objetos eliminados temporariamente com a API BigQuery ou a ferramenta de linhas de comando bq
Pode implementar estas práticas recomendadas criando o seu contentor com o seguinte comando:
gcloud storage buckets create gs://BUCKET_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --enable-autoclass \ --public-access-prevention \ --uniform-bucket-level-access
Substitua o seguinte:
BUCKET_NAME: o nome do seu novo contentorPROJECT_ID: o ID do seu projetoLOCATION: a localização do novo contentor
Tabela Iceberg do BigLake em fluxos de trabalho do BigQuery
As secções seguintes descrevem como criar, carregar, gerir e consultar tabelas geridas.
Antes de começar
Antes de criar e usar tabelas Iceberg do BigLake no BigQuery, certifique-se de que configurou uma ligação de recursos da nuvem a um contentor de armazenamento. A sua associação precisa de autorizações de escrita no contentor de armazenamento, conforme especificado na secção Funções necessárias seguinte. Para mais informações sobre as funções e as autorizações necessárias para as associações, consulte o artigo Gerir associações.
Funções necessárias
Para obter as autorizações de que precisa para permitir que o BigQuery faça a gestão de tabelas no seu projeto, peça ao administrador que lhe conceda as seguintes funções de IAM:
-
Para criar tabelas Iceberg do BigLake no BigQuery:
-
Proprietário de dados do BigQuery (
roles/bigquery.dataOwner) no seu projeto -
Administrador da associação do BigQuery (
roles/bigquery.connectionAdmin) no seu projeto
-
Proprietário de dados do BigQuery (
-
Para consultar tabelas Iceberg do BigLake no BigQuery:
-
Visualizador de dados do BigQuery (
roles/bigquery.dataViewer) no seu projeto -
Utilizador do BigQuery (
roles/bigquery.user) no seu projeto
-
Visualizador de dados do BigQuery (
-
Conceda à conta de serviço de associação as seguintes funções para que possa ler e escrever dados no Cloud Storage:
-
Utilizador de objetos de armazenamento (
roles/storage.objectUser) no contentor -
Leitor do contentor antigo de armazenamento (
roles/storage.legacyBucketReader) no contentor
-
Utilizador de objetos de armazenamento (
Para mais informações sobre a atribuição de funções, consulte o artigo Faça a gestão do acesso a projetos, pastas e organizações.
Estas funções predefinidas contêm as autorizações necessárias para permitir que o BigQuery faça a gestão de tabelas no seu projeto. Para ver as autorizações exatas que são necessárias, expanda a secção Autorizações necessárias:
Autorizações necessárias
As seguintes autorizações são necessárias para permitir que o BigQuery faça a gestão de tabelas no seu projeto:
-
bigquery.connections.delegateno seu projeto -
bigquery.jobs.createno seu projeto -
bigquery.readsessions.createno seu projeto -
bigquery.tables.createno seu projeto -
bigquery.tables.getno seu projeto -
bigquery.tables.getDatano seu projeto -
storage.buckets.getno seu contentor -
storage.objects.createno seu contentor -
storage.objects.deleteno seu contentor -
storage.objects.getno seu contentor -
storage.objects.listno seu contentor
Também pode conseguir estas autorizações com funções personalizadas ou outras funções predefinidas.
Crie tabelas Iceberg do BigLake no BigQuery
Para criar uma tabela Iceberg do BigLake no BigQuery, selecione um dos seguintes métodos:
SQL
CREATE TABLE [PROJECT_ID.]DATASET_ID.TABLE_NAME ( COLUMN DATA_TYPE[, ...] ) CLUSTER BY CLUSTER_COLUMN_LIST WITH CONNECTION {CONNECTION_NAME | DEFAULT} OPTIONS ( file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'STORAGE_URI');
Substitua o seguinte:
- PROJECT_ID: o projeto que contém o conjunto de dados. Se não estiver definido, o comando assume o projeto predefinido.
- DATASET_ID: um conjunto de dados existente.
- TABLE_NAME: o nome da tabela que está a criar.
- DATA_TYPE: o tipo de dados das informações contidas na coluna.
- CLUSTER_COLUMN_LIST: uma lista separada por vírgulas que contém até quatro colunas. Têm de ser colunas de nível superior não repetidas.
CONNECTION_NAME: o nome da associação. Por exemplo,
myproject.us.myconnection.Para usar uma ligação predefinida, especifique
DEFAULTem vez da string de ligação que contém PROJECT_ID.REGION.CONNECTION_ID.STORAGE_URI: um URI do Cloud Storage totalmente qualificado. Por exemplo,
gs://mybucket/table.
bq
bq --project_id=PROJECT_ID mk \ --table \ --file_format=PARQUET \ --table_format=ICEBERG \ --connection_id=CONNECTION_NAME \ --storage_uri=STORAGE_URI \ --schema=COLUMN_NAME:DATA_TYPE[, ...] \ --clustering_fields=CLUSTER_COLUMN_LIST \ DATASET_ID.MANAGED_TABLE_NAME
Substitua o seguinte:
- PROJECT_ID: o projeto que contém o conjunto de dados. Se não estiver definido, o comando assume o projeto predefinido.
- CONNECTION_NAME: o nome da associação. Por
exemplo,
myproject.us.myconnection. - STORAGE_URI: um URI do Cloud Storage totalmente qualificado.
Por exemplo,
gs://mybucket/table. - COLUMN_NAME: o nome da coluna.
- DATA_TYPE: o tipo de dados das informações contidas na coluna.
- CLUSTER_COLUMN_LIST: uma lista separada por vírgulas que contém até quatro colunas. Têm de ser colunas de nível superior não repetidas.
- DATASET_ID: o ID de um conjunto de dados existente.
- MANAGED_TABLE_NAME: o nome da tabela que está a criar.
API
Chame o método
tables.insert'
com um recurso de tabela definido, semelhante ao seguinte:
{ "tableReference": { "tableId": "TABLE_NAME" }, "biglakeConfiguration": { "connectionId": "CONNECTION_NAME", "fileFormat": "PARQUET", "tableFormat": "ICEBERG", "storageUri": "STORAGE_URI" }, "schema": { "fields": [ { "name": "COLUMN_NAME", "type": "DATA_TYPE" } [, ...] ] } }
Substitua o seguinte:
- TABLE_NAME: o nome da tabela que está a criar.
- CONNECTION_NAME: o nome da associação. Por
exemplo,
myproject.us.myconnection. - STORAGE_URI: um URI do Cloud Storage totalmente qualificado.
Os carateres universais
também são suportados. Por exemplo,
gs://mybucket/table. - COLUMN_NAME: o nome da coluna.
- DATA_TYPE: o tipo de dados das informações contidas na coluna.
Importe dados para tabelas Iceberg do BigLake no BigQuery
As secções seguintes descrevem como importar dados de vários formatos de tabelas para tabelas Iceberg do BigLake no BigQuery.
Carregue dados padrão de ficheiros simples
As tabelas Iceberg do BigLake no BigQuery usam tarefas de carregamento do BigQuery para
carregar ficheiros externos
em tabelas Iceberg do BigLake no BigQuery. Se tiver uma tabela Iceberg do BigLake existente no BigQuery, siga o
bq load guia da CLI
ou o
LOAD guia de SQL
para carregar dados externos. Depois de carregar os dados, são escritos novos ficheiros Parquet
na pasta STORAGE_URI/data.
Se as instruções anteriores forem usadas sem uma tabela Iceberg do BigLake existente no BigQuery, é criada uma tabela do BigQuery.
Veja o seguinte para obter exemplos específicos de ferramentas de carregamentos em lote em tabelas geridas:
SQL
LOAD DATA INTO MANAGED_TABLE_NAME FROM FILES ( uris=['STORAGE_URI'], format='FILE_FORMAT');
Substitua o seguinte:
- MANAGED_TABLE_NAME: o nome de uma tabela Iceberg do BigLake existente no BigQuery.
- STORAGE_URI: um URI do Cloud Storage totalmente qualificado ou uma lista de URIs separados por vírgulas.
Os carateres universais
também são suportados. Por exemplo,
gs://mybucket/table. - FILE_FORMAT: o formato da tabela de origem. Para ver os formatos suportados,
consulte a linha
formatdeload_option_list.
bq
bq load \ --source_format=FILE_FORMAT \ MANAGED_TABLE \ STORAGE_URI
Substitua o seguinte:
- FILE_FORMAT: o formato da tabela de origem. Para ver os formatos suportados,
consulte a linha
formatdeload_option_list. - MANAGED_TABLE_NAME: o nome de uma tabela Iceberg do BigLake existente no BigQuery.
- STORAGE_URI: um URI do Cloud Storage totalmente qualificado ou uma lista de URIs separados por vírgulas.
Os carateres universais
também são suportados. Por exemplo,
gs://mybucket/table.
Carregamento padrão a partir de ficheiros com partições do Hive
Pode carregar ficheiros com partições do Hive em tabelas Iceberg do BigLake no BigQuery usando tarefas de carregamento padrão do BigQuery. Para mais informações, consulte o artigo Carregar dados particionados externamente.
Carregue dados de streaming do Pub/Sub
Pode carregar dados de streaming em tabelas Iceberg do BigLake no BigQuery através de uma subscrição do Pub/Sub do BigQuery.
Exporte dados de tabelas Iceberg do BigLake no BigQuery
As secções seguintes descrevem como exportar dados de tabelas Iceberg do BigLake no BigQuery para vários formatos de tabelas.
Exporte dados para formatos simples
Para exportar uma tabela Iceberg do BigLake no BigQuery para um formato simples, use a declaração EXPORT DATA e selecione um formato de destino. Para mais informações, consulte o artigo
Exportar dados.
Crie uma tabela Iceberg do BigLake em instantâneos de metadados do BigQuery
Para criar uma tabela Iceberg do BigLake na captura instantânea de metadados do BigQuery, siga estes passos:
Exporte os metadados para o formato Iceberg V2 com a declaração SQL
EXPORT TABLE METADATA.Opcional: agende a atualização da captura instantânea dos metadados do Iceberg. Para atualizar um instantâneo de metadados do Iceberg com base num intervalo de tempo definido, use uma consulta agendada.
Opcional: ative a atualização automática de metadados para o seu projeto para atualizar automaticamente o resumo dos metadados da tabela Iceberg em cada mutação da tabela. Para ativar a atualização automática de metadados, contacte bigquery-tables-for-apache-iceberg-help@google.com. Os custos são aplicados em cada operação de atualização.
EXPORT METADATA
O exemplo seguinte cria uma consulta agendada denominada My Scheduled Snapshot Refresh Query
através da declaração LDD EXPORT TABLE METADATA FROM mydataset.test. A declaração DDL é executada a cada 24 horas.
bq query \ --use_legacy_sql=false \ --display_name='My Scheduled Snapshot Refresh Query' \ --schedule='every 24 hours' \ 'EXPORT TABLE METADATA FROM mydataset.test'
Veja a tabela Iceberg do BigLake na captura instantânea de metadados do BigQuery
Depois de atualizar a tabela Iceberg do BigLake na captura instantânea de metadados do BigQuery, pode
encontrar a captura instantânea no URI do Cloud Storage
em que a tabela Iceberg do BigLake no BigQuery foi originalmente criada. A pasta /data contém os fragmentos de dados do ficheiro Parquet e a pasta /metadata contém a tabela Iceberg do BigLake na captura instantânea de metadados do BigQuery.
SELECT table_name, REGEXP_EXTRACT(ddl, r"storage_uri\s*=\s*\"([^\"]+)\"") AS storage_uri FROM `mydataset`.INFORMATION_SCHEMA.TABLES;
Tenha em atenção que mydataset e table_name são marcadores de posição para o conjunto de dados e a tabela reais.
Leia tabelas Iceberg do BigLake no BigQuery com o Apache Spark
O exemplo seguinte configura o seu ambiente para usar o Spark SQL com o Apache Iceberg e, em seguida, executa uma consulta para obter dados de uma tabela Iceberg do BigLake especificada no BigQuery.
spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-ICEBERG_VERSION_NUMBER \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.type=hadoop \ --conf spark.sql.catalog.CATALOG_NAME.warehouse='BUCKET_PATH' \ # Query the table SELECT * FROM CATALOG_NAME.FOLDER_NAME;
Substitua o seguinte:
- ICEBERG_VERSION_NUMBER: a versão atual do tempo de execução do Apache Spark Iceberg. Transfira a versão mais recente a partir das versões do Spark.
- CATALOG_NAME: o catálogo para referenciar a sua tabela Iceberg do BigLake no BigQuery.
- BUCKET_PATH: o caminho para o contentor que contém os ficheiros de tabela. Por exemplo,
gs://mybucket/. - FOLDER_NAME: a pasta que contém os ficheiros de tabelas.
Por exemplo,
myfolder.
Modifique tabelas Iceberg do BigLake no BigQuery
Para modificar uma tabela Iceberg do BigLake no BigQuery, siga os passos apresentados no artigo Modificar esquemas de tabelas.
Use transações com várias declarações
Para obter acesso a transações com várias declarações para tabelas Iceberg do BigLake no BigQuery, preencha o formulário de inscrição.
Preços
O preço da tabela Iceberg do BigLake no BigQuery consiste em armazenamento, otimização do armazenamento e consultas e tarefas.
Armazenamento
As tabelas Iceberg do BigLake no BigQuery armazenam todos os dados no Cloud Storage. É-lhe cobrado o armazenamento de todos os dados, incluindo os dados da tabela do histórico. Também podem aplicar-se o tratamento de dados e os custos de transferência do Cloud Storage. Algumas taxas de operações do Cloud Storage podem ser dispensadas para operações que são processadas através do BigQuery ou da API BigQuery Storage. Não existem taxas de armazenamento específicas do BigQuery. Para mais informações, consulte os preços do Cloud Storage.
Otimização do armazenamento
As tabelas Iceberg do BigLake no BigQuery fazem a otimização automática do armazenamento, incluindo o dimensionamento adaptativo de ficheiros, o agrupamento automático, a recolha de lixo e a otimização de metadados. Estas operações de otimização usam intervalos de pagamento conforme o uso da edição Enterprise e não usam reservas BACKGROUND existentes.
As operações de exportação de dados realizadas durante o streaming através da API Storage Write do BigQuery estão incluídas nos preços da API Storage Write e não são cobradas como manutenção em segundo plano. Para mais informações, consulte os preços de carregamento de dados.
A otimização do armazenamento e a utilização de EXPORT TABLE METADATA são visíveis na vista INFORMATION_SCHEMA.JOBS.
Consultas e tarefas
Tal como acontece com as tabelas do BigQuery, são-lhe cobradas as consultas e os bytes lidos (por TiB) se estiver a usar os preços a pedido do BigQuery ou o consumo de slots (por hora de slot) se estiver a usar os preços de computação de capacidade do BigQuery.
Os preços do BigQuery também se aplicam à API BigQuery Storage Read e à API BigQuery Storage Write.
As operações de carregamento e exportação (como EXPORT METADATA) usam slots de pagamento mediante utilização da edição Enterprise.
Isto difere das tabelas do BigQuery, que não são cobradas por estas operações. Se estiverem disponíveis PIPELINEreservas com espaços do Enterprise ou Enterprise Plus, as operações de carregamento e exportação usam preferencialmente estes espaços de reserva.
Limitações
As tabelas Iceberg do BigLake no BigQuery têm as seguintes limitações:
- As tabelas Iceberg do BigLake no BigQuery não suportam
operações de mudança de nome nem
declarações
ALTER TABLE RENAME TO. - As tabelas Iceberg do BigLake no BigQuery não suportam
cópias de tabelas nem
declarações
CREATE TABLE COPY. - As tabelas Iceberg do BigLake no BigQuery não suportam
clones de tabelas nem
declarações
CREATE TABLE CLONE. - As tabelas Iceberg do BigLake no BigQuery não suportam
instantâneos de tabelas nem
declarações
CREATE SNAPSHOT TABLE. - As tabelas Iceberg do BigLake no BigQuery não suportam o seguinte esquema de tabela:
- Esquema vazio
- Esquema com tipos de dados
BIGNUMERIC,INTERVAL,JSON,RANGEouGEOGRAPHY. - Esquema com intercalações de campos.
- Esquema com expressões de valor predefinido.
- As tabelas Iceberg do BigLake no BigQuery não suportam os seguintes casos de evolução do esquema:
NUMERICcoerções de tipoFLOATINTcoerções de tipoFLOAT- Adicionar novos campos aninhados a colunas
RECORDexistentes através de declarações SQL DDL
- As tabelas Iceberg do BigLake no BigQuery apresentam um tamanho de armazenamento de 0 bytes quando consultadas pela consola ou pelas APIs.
- As tabelas Iceberg do BigLake no BigQuery não suportam vistas materializadas.
- As tabelas Iceberg do BigLake no BigQuery não suportam vistas autorizadas, mas o controlo de acesso ao nível da coluna é suportado.
- As tabelas Iceberg do BigLake no BigQuery não suportam atualizações de captura de dados de alterações (CDC).
- As tabelas Iceberg do BigLake no BigQuery não suportam a recuperação de desastres gerida
- As tabelas Iceberg do BigLake no BigQuery não suportam particionamento. Considere a agrupagem como uma alternativa.
- As tabelas Iceberg do BigLake no BigQuery não suportam a segurança ao nível da linha.
- As tabelas Iceberg do BigLake no BigQuery não suportam janelas de segurança.
- As tabelas Iceberg do BigLake no BigQuery não suportam tarefas de extração.
- A vista
INFORMATION_SCHEMA.TABLE_STORAGEnão inclui tabelas Iceberg do BigLake no BigQuery. - As tabelas Iceberg do BigLake no BigQuery não são suportadas como destinos
de resultados de consultas. Em alternativa, pode usar a declaração
CREATE TABLEcom o argumentoAS query_statementpara criar uma tabela como o destino do resultado da consulta. CREATE OR REPLACEnão suporta a substituição de tabelas padrão por tabelas Iceberg do BigLake no BigQuery, nem de tabelas Iceberg do BigLake no BigQuery por tabelas padrão.- O carregamento em lote e as
declarações
LOAD DATAsó suportam a anexação de dados a tabelas Iceberg do BigLake existentes no BigQuery. - O carregamento em lote e as declarações
LOAD DATAnão suportam atualizações de esquemas. - O
TRUNCATE TABLEnão suporta tabelas Iceberg do BigLake no BigQuery. Existem duas alternativas:CREATE OR REPLACE TABLE, usando as mesmas opções de criação de tabelas.DELETE FROMtabelaWHEREtrue
- A
APPENDSfunção com valor de tabela (TVF) não suporta tabelas Iceberg do BigLake no BigQuery. - Os metadados do Iceberg podem não conter dados que foram transmitidos para o BigQuery pela API Storage Write nos últimos 90 minutos.
- O acesso paginado baseado em registos através de
tabledata.listnão suporta tabelas Iceberg do BigLake no BigQuery. - As tabelas Iceberg do BigLake no BigQuery não suportam conjuntos de dados associados.
- Apenas uma declaração DML de mutação concorrente (
UPDATE,DELETEeMERGE) é executada para cada tabela Iceberg do BigLake no BigQuery. As declarações DML de mutação adicionais são colocadas em fila.