生成 AI の概要
このドキュメントでは、BigQuery ML がサポートする生成 AI(人工知能)機能について説明します。これらの機能を使用すると、事前トレーニング済みの Vertex AI モデルと組み込みの BigQuery ML モデルを使用して、BigQuery ML で AI タスクを実行できます。
サポートされているタスクは次のとおりです。
Vertex AI モデルにアクセスして、BigQuery ML で Vertex AI モデルのエンドポイントを表すリモートモデルを作成し、これらの関数のいずれかを実行します。使用する Vertex AI モデルでリモートモデルを作成後、リモートモデルに対して BigQuery ML 関数を実行して、そのモデルの機能にアクセスします。
この方法では、SQL クエリでこれらの Vertex AI モデルの機能を使用することで、BigQuery データを分析できます。
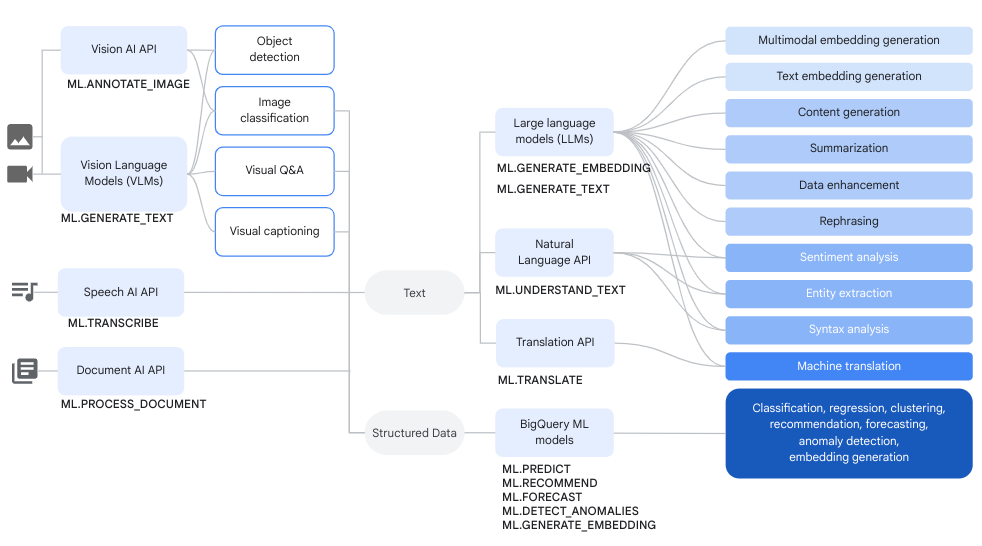
ワークフロー
複雑なデータ分析や生成 AI タスクを実行するには、Vertex AI モデルのリモートモデルと Cloud AI サービスに対するリモートモデルを BigQuery ML 関数とともに使用できます。
次の図は、これらの機能を組み合わせて使用する一般的なワークフローを示しています。
テキストを生成する
テキスト生成は、プロンプトまたはデータの分析に基づいてテキストを生成する生成 AI の一種です。テキストとマルチモーダル データの両方を使用してテキスト生成を実行できます。
テキスト生成の一般的なユースケースは次のとおりです。
- クリエイティブ コンテンツの生成
- コードの生成
- チャットまたはメールの返信の生成
- 今後の商品やサービスの可能性の提案など、ブレインストーミング
- コンテンツのパーソナライズ(商品の候補など)
- コンテンツに 1 つ以上のラベルを適用してカテゴリに並べ替えることで、データを分類する
- コンテンツで表現されている主な感情を特定する
- コンテンツで伝えられた主なアイデアや印象を要約する
- テキストデータまたは画像データ内の 1 つ以上の重要なエンティティを特定する
- テキストデータまたは音声データのコンテンツを別の言語に翻訳する
- 音声データの音声コンテンツに一致するテキストを生成する
- 画像キャプションや画像データに関する Q&A の実行
テキスト生成後の一般的な次のステップはデータ拡充です。ここでは、初期分析からの分析情報を追加データと組み合わせて拡充します。たとえば、家具の画像を分析して design_type 列のテキストを生成すると、家具の SKU に mid-century modern や farmhouse などの説明が関連付けられます。
サポートされているモデル
生成 AI タスクを実行するには、BigQuery ML のリモートモデルを使用して、Vertex AI にデプロイまたはホストされているモデルを参照します。次のタイプのリモートモデルを作成できます。
テキスト生成モデルを使用する
リモートモデルを作成したら、ML.GENERATE_TEXT 関数を使用してそのモデルを操作できます。
Gemini モデルに基づくリモートモデルでは、次のことができます。
ML.GENERATE_TEXT関数を使用して、クエリで指定したプロンプトまたは標準テーブルの列で取得したプロンプトからテキストを生成します。クエリでプロンプトを指定するときに、プロンプトで次のタイプのテーブル列を参照できます。- テキストデータを提供する
STRING。 ObjectRef形式で非構造化データを提供するSTRUCT列。プロンプト内でOBJ.GET_ACCESS_URL関数を使用して、ObjectRef値をObjectRefRuntime値に変換する必要があります。
- テキストデータを提供する
ML.GENERATE_TEXT関数に関数引数として指定されたプロンプトを使用して、オブジェクト テーブルのテキスト、画像、音声、動画、PDF コンテンツを分析します。
他のすべてのタイプのリモートモデルの場合、クエリで指定したプロンプトまたは標準テーブルの列で
ML.GENERATE_TEXT関数を使用できます。
次のトピックを使用して、BigQuery ML でテキスト生成を試すことができます。
- Gemini モデルと
ML.GENERATE_TEXT関数を使用してテキストを生成する。 - Gemma モデルと
ML.GENERATE_TEXT関数を使用してテキストを生成する。 - Gemini モデルを使用して画像を分析する。
- 独自のデータで
ML.GENERATE_TEXT関数を使用してテキストを生成する。 - 独自のデータを使用してモデルをチューニングする。
グラウンディングと安全属性
ML.GENERATE_TEXT 関数で Gemini モデルを使用する際に入力として標準テーブルを使用している場合は、グラウンディングと安全属性を使用できます。グラウンディングにより、Gemini モデルはインターネットから追加情報を取得し、より具体的で事実に基づく回答を生成できます。安全属性を使用すると、Gemini モデルは、指定された属性に基づいてレスポンスをフィルタできます。
教師ありチューニング
次のいずれかのモデルを参照するリモートモデルを作成するときに、必要に応じて教師ありチューニングを同時に構成することもできます。
gemini-2.5-progemini-2.5-flash-litegemini-2.0-flash-001gemini-2.0-flash-lite-001
推論はすべて Vertex AI で行われます。結果は BigQuery に保存されます。
Vertex AI のプロビジョニングされたスループット
サポートされている Gemini モデルに対して、Vertex AI プロビジョンド スループットと ML.GENERATE_TEXT 関数を使用することで、リクエストに一貫した高スループットを提供できます。詳細については、Vertex AI プロビジョンド スループットを使用するをご覧ください。
構造化データを生成する
構造化データの生成はテキスト生成とよく似ていますが、SQL スキーマを指定してモデルからのレスポンスをフォーマットすることもできます。
構造化データを生成するには、一般提供またはプレビューの Gemini モデルのいずれかを使用してリモートモデルを作成します。その後、AI.GENERATE_TABLE 関数を使用して、そのモデルを操作できます。構造化データの作成を試すには、AI.GENERATE_TABLE 関数を使用して構造化データを生成するをご覧ください。
AI.GENERATE_TABLE 関数で Gemini モデルを使用する際に安全属性を指定すると、モデルのレスポンスをフィルタできます。
特定の型の値を行ごとに生成する
スカラー生成 AI 関数を Gemini モデルで使用して、BigQuery 標準テーブルのデータを分析できます。データには、ObjectRef 値を含む列のテキストデータと非構造化データの両方が含まれます。テーブルの各行に対して、これらの関数は特定の型を含む出力を生成します。
次の AI 関数を使用できます。
AI.GENERATE。STRING値を生成します。AI.GENERATE_BOOLAI.GENERATE_DOUBLEAI.GENERATE_INT
サポートされている Gemini モデルで AI.GENERATE 関数を使用する場合は、Vertex AI プロビジョンド スループットを使用して、リクエストに一貫した高スループットを提供できます。詳細については、Vertex AI プロビジョンド スループットを使用するをご覧ください。
エンベディングを生成する
エンベディングは、テキストや音声ファイルなど、特定のエンティティを表す高次元の数値ベクトルです。エンベディングを生成すると、データを推論して比較しやすくするように、データのセマンティクスをキャプチャできます。
エンベディング生成の一般的なユースケースは次のとおりです。
- 検索拡張生成(RAG)を使用して、信頼できるソースの追加データを参照し、ユーザーのクエリに対するモデルのレスポンスを拡張する。RAG は、事実の精度とレスポンスの一貫性を高め、モデルのトレーニング データよりも新しいデータにアクセスできるようにします。
- マルチモーダル検索の実行。たとえば、テキスト入力を使用して画像を検索します。
- セマンティック検索を実行して、レコメンデーション、置換、レコードの重複除去に類似したアイテムを見つける。
- クラスタリング用の K 平均法モデルで使用するエンベディングを作成する。
サポートされているモデル
次のモデルがサポートされています。
テキスト エンベディングを作成するには、次の Vertex AI モデルを使用できます。
gemini-embedding-001(プレビュー)text-embeddingtext-multilingual-embedding- サポートされているオープンモデル (プレビュー)
テキスト、画像、動画を同じセマンティック空間に埋め込むマルチモーダル エンベディングを作成するには、Vertex AI
multimodalembeddingモデルを使用します。構造化された独立同分布確率変数(IID)データのエンベディングを作成するには、BigQuery ML 主成分分析(PCA)モデルまたはオートエンコーダ モデルを使用します。
ユーザーデータまたはアイテムデータのエンベディングを作成するには、BigQuery ML の行列分解モデルを使用します。
よりサイズが小さく軽量のテキスト埋め込みには、NNLM、SWIVEL、BERT などの事前トレーニング済み TensorFlow モデルを使用してみてください。
エンベディング生成モデルを使用する
モデルを作成したら、ML.GENERATE_EMBEDDING 関数を使用して操作できます。サポートされているすべてのタイプのモデルについて、ML.GENERATE_EMBEDDING は標準テーブルで構造化データを処理します。マルチモーダル エンベディング モデルの場合、ML.GENERATE_EMBEDDING は、標準テーブルの ObjectRef 値を含む列、またはオブジェクト テーブルの視覚的なコンテンツにも対応しています。
リモートモデルの場合、すべての推論は Vertex AI で行われます。他のモデルタイプの場合、すべての推論は BigQuery で行われます。結果は BigQuery に保存されます。
次のトピックを使用して、BigQuery ML でテキスト生成を試すことができます。
ML.GENERATE_EMBEDDING関数を使用してテキスト エンベディングを生成するML.GENERATE_EMBEDDING関数を使用して画像エンベディングを生成するML.GENERATE_EMBEDDING関数を使用して動画エンベディングを生成する- マルチモーダル エンベディングの生成と検索
- セマンティック検索と検索拡張生成を行う
予測
予測とは、過去の時系列データを分析して将来の傾向を予測する手法です。BigQuery ML の組み込みの TimesFM 時系列モデル(プレビュー)を使用すると、独自のモデルを作成しなくても予測を実行できます。組み込みの TimesFM モデルは、AI.FORECAST 関数を使用して、データに基づいて予測を生成します。
ロケーション
テキスト生成モデルとエンベディング モデルでサポートされているロケーションは、使用するモデルのタイプとバージョンによって異なります。詳細については、ロケーションをご覧ください。他の生成 AI モデルとは異なり、ロケーションのサポートは組み込みの TimesFM 時系列モデルには適用されません。TimesFM モデルは、BigQuery でサポートされているすべてのリージョンで利用できます。
料金
モデルに対してクエリを実行するために使用したコンピューティング リソースに対して課金されます。リモートモデルは Vertex AI モデルを呼び出すため、リモートモデルに対するクエリでも Vertex AI の料金が発生します。
詳細については、BigQuery ML の料金をご覧ください。
次のステップ
- BigQuery の AI と ML の概要については、BigQuery の AI と ML の概要をご覧ください。
- ML モデルに対する推論の実行について詳しくは、モデル推論の概要をご覧ください。
- 生成 AI モデルでサポートされている SQL ステートメントと関数の詳細については、生成 AI モデルのエンドツーエンドのユーザー ジャーニーをご覧ください。