可匯出模型
本頁說明如何匯出 BigQuery ML 模型。您可以將 BigQuery ML 模型匯出至 Cloud Storage,並用於線上預測,或在 Python 中編輯模型。您可以透過下列方式匯出 BigQuery ML 模型:
- 使用Google Cloud 控制台。
- 使用
EXPORT MODEL陳述式。 - 在 bq 指令列工具中使用
bq extract指令。 - 透過 API 或用戶端程式庫提交
extract工作。
您可以匯出下列模型類型:
AUTOENCODERAUTOML_CLASSIFIERAUTOML_REGRESSORBOOSTED_TREE_CLASSIFIERBOOSTED_TREE_REGRESSORDNN_CLASSIFIERDNN_REGRESSORDNN_LINEAR_COMBINED_CLASSIFIERDNN_LINEAR_COMBINED_REGRESSORKMEANSLINEAR_REGLOGISTIC_REGMATRIX_FACTORIZATIONRANDOM_FOREST_CLASSIFIERRANDOM_FOREST_REGRESSORTENSORFLOW(匯入的 TensorFlow 模型)PCATRANSFORM_ONLY
匯出模型格式和範例
下表列出各 BigQuery ML 模型類型的匯出目的地格式,並提供寫入 Cloud Storage bucket 的檔案範例。
| 模型類型 | 匯出模型格式 | 匯出檔案範例 |
|---|---|---|
| AUTOML_CLASSIFIER | TensorFlow SavedModel (TF 2.1.0) | gcs_bucket/
|
| AUTOML_REGRESSOR | ||
| 自動編碼器 | TensorFlow SavedModel (TF 1.15 以上版本) | |
| DNN_CLASSIFIER | ||
| DNN_REGRESSOR | ||
| DNN_LINEAR_COMBINED_CLASSIFIER | ||
| DNN_LINEAR_COMBINED_REGRESSOR | ||
| KMEANS | ||
| LINEAR_REGRESSOR | ||
| LOGISTIC_REG | ||
| MATRIX_FACTORIZATION | ||
| PCA | ||
| TRANSFORM_ONLY | ||
| BOOSTED_TREE_CLASSIFIER | Booster (XGBoost 0.82) | gcs_bucket/
main.py 適用於在本機執行。詳情請參閱「模型部署」。
|
| BOOSTED_TREE_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| TENSORFLOW (已匯入) | TensorFlow SavedModel | 與匯入模型時完全相同的檔案 |
匯出透過「TRANSFORM」訓練的模型
如果模型是使用 TRANSFORM 子句訓練,則額外的預先處理模型會執行 TRANSFORM 子句中的相同邏輯,並以 TensorFlow SavedModel 格式儲存於 transform 子目錄下。您也可以將使用 TRANSFORM 子句訓練的模型部署至 Vertex AI 和本機。詳情請參閱模型部署。
| 匯出模型格式 | 匯出檔案範例 |
|---|---|
|
預測模型:TensorFlow SavedModel 或 Booster (XGBoost 0.82)。
TRANSFORM 子句的預先處理模型:TensorFlow SavedModel (TF 2.5 以上版本) |
gcs_bucket/
|
模型不包含在訓練期間於 TRANSFORM 子句外執行的特徵工程相關資訊。例如 SELECT 陳述式中的任何內容。因此,您需要先手動轉換輸入資料,再提供給預先處理模型。
支援的資料類型
匯出以 TRANSFORM 子句訓練的模型時,系統支援下列資料類型,可饋送至 TRANSFORM 子句。
| TRANSFORM 輸入類型 | TRANSFORM 輸入範例 | 匯出的前處理模型輸入樣本 |
|---|---|---|
| INT64 |
10,
|
tf.constant(
|
| NUMERIC |
NUMERIC 10,
|
tf.constant(
|
| BIGNUMERIC |
BIGNUMERIC 10,
|
tf.constant(
|
| FLOAT64 |
10.0,
|
tf.constant(
|
| BOOL |
TRUE,
|
tf.constant(
|
| STRING |
'abc',
|
tf.constant(
|
| BYTES |
b'abc',
|
tf.constant(
|
| 日期 |
DATE '2020-09-27',
|
tf.constant(
|
| DATETIME |
DATETIME '2023-02-02 02:02:01.152903',
|
tf.constant(
|
| 時間 |
TIME '16:32:36.152903',
|
tf.constant(
|
| 時間戳記 |
TIMESTAMP '2017-02-28 12:30:30.45-08',
|
tf.constant(
|
| ARRAY |
['a', 'b'],
|
tf.constant(
|
| ARRAY< STRUCT< INT64, FLOAT64>> |
[(1, 1.0), (2, 1.0)],
|
tf.sparse.from_dense(
|
| NULL |
NULL,
|
tf.constant(
|
支援的 SQL 函式
匯出使用 TRANSFORM 子句訓練的模型時,可以在 TRANSFORM 子句中使用下列 SQL 函式。
- 運算子
+、-、*、/、=、<、>、<=、>=、!=、<>、[NOT] BETWEEN、[NOT] IN、IS [NOT] NULL、IS [NOT] TRUE、IS [NOT] FALSE、NOT、AND、OR。
- 條件運算式
CASE expr、CASE、COALESCE、IF、IFNULL、NULLIF。
- 數學函式
ABS、ACOS、ACOSH、ASINH、ATAN、ATAN2、ATANH、CBRT、CEIL、CEILING、COS、COSH、COT、COTH、CSC、CSCH、EXP、FLOOR、IS_INF、IS_NAN、LN、LOG、LOG10、MOD、POW、POWER、SEC、SECH、SIGN、SIN、SINH、SQRT、TAN、TANH。
- 轉換函式
CAST AS INT64、CAST AS FLOAT64、CAST AS NUMERIC、CAST AS BIGNUMERIC、CAST AS STRING、SAFE_CAST AS INT64、SAFE_CAST AS FLOAT64
- 字串函式
CONCAT、LEFT、LENGTH、LOWER、REGEXP_REPLACE、RIGHT、SPLIT、SUBSTR、SUBSTRING、TRIM、UPPER。
- 日期函式
Date、DATE_ADD、DATE_SUB、DATE_DIFF、DATE_TRUNC、EXTRACT、FORMAT_DATE、PARSE_DATE、SAFE.PARSE_DATE。
- 日期時間函式
DATETIME、DATETIME_ADD、DATETIME_SUB、DATETIME_DIFF、DATETIME_TRUNC、EXTRACT、PARSE_DATETIME、SAFE.PARSE_DATETIME。
- 時間函式
TIME、TIME_ADD、TIME_SUB、TIME_DIFF、TIME_TRUNC、EXTRACT、FORMAT_TIME、PARSE_TIME、SAFE.PARSE_TIME。
- 時間戳記函式
TIMESTAMP、TIMESTAMP_ADD、TIMESTAMP_SUB、TIMESTAMP_DIFF、TIMESTAMP_TRUNC、FORMAT_TIMESTAMP、PARSE_TIMESTAMP、SAFE.PARSE_TIMESTAMP、TIMESTAMP_MICROS、TIMESTAMP_MILLIS、TIMESTAMP_SECONDS、EXTRACT、STRING、UNIX_MICROS、UNIX_MILLIS、UNIX_SECONDS。
- 手動預先處理函式
ML.IMPUTER、ML.HASH_BUCKETIZE、ML.LABEL_ENCODER、ML.MULTI_HOT_ENCODER、ML.NGRAMS、ML.ONE_HOT_ENCODER、ML.BUCKETIZE、ML.MAX_ABS_SCALER、ML.MIN_MAX_SCALER、ML.NORMALIZER、ML.QUANTILE_BUCKETIZE、ML.ROBUST_SCALER、ML.STANDARD_SCALER。
限制
匯出模型時,請注意下列限制:
如果訓練期間使用下列任何功能,系統就不支援匯出模型:
- 輸入資料中含有
ARRAY、TIMESTAMP或GEOGRAPHY特徵類型。
- 輸入資料中含有
匯出的
AUTOML_REGRESSOR和AUTOML_CLASSIFIER模型類型不支援 Vertex AI 部署,無法用於線上預測。匯出矩陣分解模型時,模型大小上限為 1 GB。 模型大小與
num_factors大致成正比,因此如果達到上限,可以在訓練期間減少num_factors,縮減模型大小。如要瞭解使用 BigQuery ML
TRANSFORM子句訓練的模型 (用於手動預先處理特徵),請參閱支援匯出的資料類型和函式。使用 2023 年 9 月 18 日前的 BigQuery ML
TRANSFORM子句訓練的模型,必須重新訓練,才能透過模型登錄服務部署,以進行線上預測。匯出模型時,系統支援
ARRAY<STRUCT<INT64, FLOAT64>>、ARRAY和TIMESTAMP做為預先轉換的資料,但不支援做為轉換後的資料。
匯出 BigQuery ML 模型
如要匯出模型,請按照下列步驟操作:
主控台
在 Google Cloud 控制台開啟 BigQuery 頁面。
在導覽面板的「Resources」(資源) 區段,展開您的專案並選取資料集。找出並點選要匯出的模型。
按一下視窗右側的「匯出模型」。
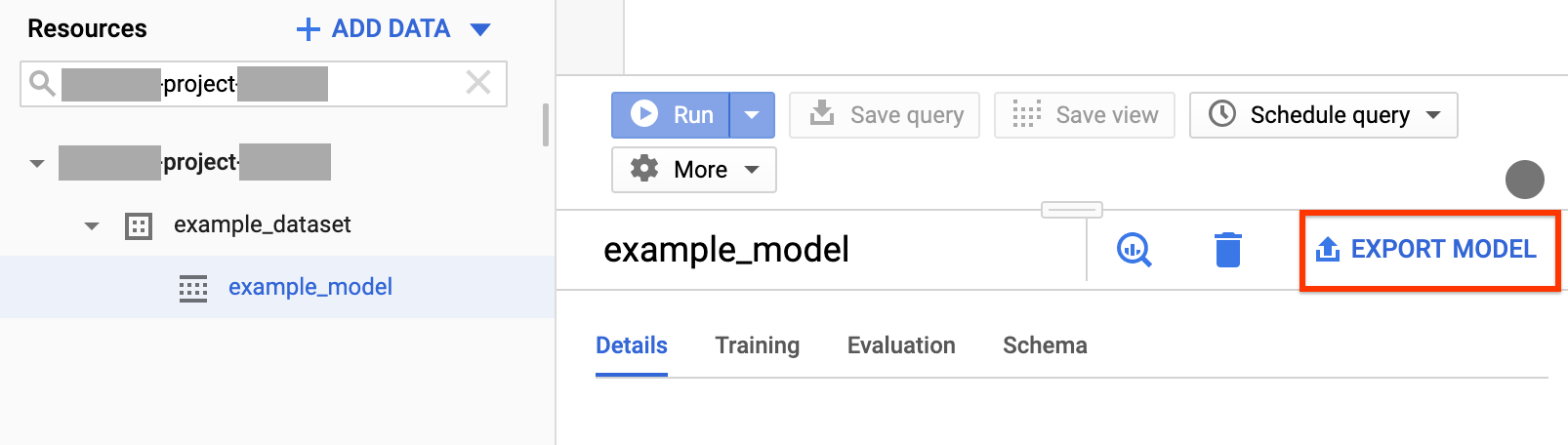
在「Export model to Cloud Storage」(將模型匯出至 Cloud Storage) 對話方塊中:
- 針對「Select Cloud Storage location」(選取 Cloud Storage 位置),請瀏覽至您要匯出模型的值區或資料夾位置。
- 按一下「匯出」即可匯出模型。
如要查看工作進度,請查看「Export」(匯出) 工作的「Job history」(工作記錄) 導覽區頂端附近。
SQL
EXPORT MODEL 陳述式可讓您使用 GoogleSQL 查詢語法,將 BigQuery ML 模型匯出至 Cloud Storage。
如要在 Google Cloud 控制台中使用 EXPORT MODEL 陳述式匯出 BigQuery ML 模型,請按照下列步驟操作:
在 Google Cloud 控制台開啟「BigQuery」頁面。
按一下 [Compose new query] (撰寫新查詢)。
在「Query editor」(查詢編輯器) 欄位中,輸入您的
EXPORT MODEL陳述式。以下查詢會將名為
myproject.mydataset.mymodel的模型匯出至 URI 為gs://bucket/path/to/saved_model/的 Cloud Storage 值區。EXPORT MODEL `myproject.mydataset.mymodel` OPTIONS(URI = 'gs://bucket/path/to/saved_model/')
按一下「執行」。查詢完成時,「Query results」(查詢結果) 窗格會顯示
Successfully exported model。
bq
請使用 bq extract 指令,並加上 --model 旗標。
(選用) 提供 --destination_format 旗標,並選擇匯出模型的格式。(選用) 加上 --location 旗標,並將該旗標值設為您的位置。
bq --location=location extract \ --destination_format format \ --model project_id:dataset.model \ gs://bucket/model_folder
其中:
- location 是您的位置名稱。
--location是選用旗標。舉例來說,如果您在東京地區使用 BigQuery,就可以將旗標的值設為asia-northeast1。您可以使用 .bigqueryrc 檔案,設定該位置的預設值。 - destination_format 是匯出模型的格式:
ML_TF_SAVED_MODEL(預設) 或ML_XGBOOST_BOOSTER。 - project_id 是您的專案 ID。
- dataset 是來源資料集的名稱。
- model 是您要匯出的模型。
- bucket 是匯出資料的目標 Cloud Storage 值區名稱。BigQuery 資料集與 Cloud Storage 值區必須位於相同的位置。
- model_folder 是要寫入匯出模型檔案的資料夾名稱。
範例:
舉例來說,下列指令會將 TensorFlow SavedModel 格式的 mydataset.mymodel 匯出至名為 mymodel_folder 的 Cloud Storage 值區。
bq extract --model \ 'mydataset.mymodel' \ gs://example-bucket/mymodel_folder
destination_format 的預設值為 ML_TF_SAVED_MODEL。
下列指令會以 XGBoost Booster 格式將 mydataset.mymodel 匯出至名為 mymodel_folder 的 Cloud Storage bucket。
bq extract --model \ --destination_format ML_XGBOOST_BOOSTER \ 'mydataset.mytable' \ gs://example-bucket/mymodel_folder
API
如要匯出模型,請建立 extract 工作,並填入工作設定。
(選用) 在工作資源的 jobReference 區段中,於 location 屬性內指定您的位置。
建立指向 BigQuery ML 模型和 Cloud Storage 目的地的擷取工作。
指定來源模型,方法是使用包含專案 ID、資料集 ID 和模型 ID 的
sourceModel設定物件。destination URI(s)屬性必須是完整的,且必須符合下列格式:gs://bucket/model_folder。設定
configuration.extract.destinationFormat屬性以指定目的地格式。舉例來說,如要匯出提升樹狀結構模型,請將此屬性值設為ML_XGBOOST_BOOSTER。如要查看工作狀態,請利用初始要求所傳回的工作 ID 來呼叫 jobs.get(job_id)。
- 如果是
status.state = DONE,代表工作已順利完成。 - 如果出現
status.errorResult屬性,代表要求執行失敗,且該物件將包含所發生錯誤的相關訊息。 - 如果沒有出現
status.errorResult,代表工作已順利完成,但過程中可能發生了幾個不嚴重的錯誤。不嚴重的錯誤都會列在已傳回工作物件的status.errors屬性中。
- 如果是
API 附註:
最佳做法就是產生唯一識別碼,並在呼叫
jobs.insert來建立工作時,將該唯一識別碼當做jobReference.jobId傳送。這個方法較不受網路故障問題的影響,因為用戶端可使用已知的工作 ID 進行輪詢或重試。針對指定的工作 ID 呼叫
jobs.insert算是種冪等運算;換句話說,您可以針對同一個工作 ID 重試作業無數次,但在這些作業中最多只會有一個成功。
Java
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Java 設定說明進行操作。詳情請參閱 BigQuery Java API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
模型部署
您可以將匯出的模型部署至 Vertex AI 和本機。如果模型的 TRANSFORM 子句包含日期函式、日期時間函式、時間函式或時間戳記函式,您必須在容器中使用 bigquery-ml-utils 程式庫。但如果您是透過 Model Registry 部署,則不需要匯出模型或提供模型的容器。
Vertex AI 部署作業
| 匯出模型格式 | 部署作業 |
|---|---|
| TensorFlow SavedModel (非 AutoML 模型) | 部署 TensorFlow SavedModel。 您必須使用 支援的 TensorFlow 版本建立 SavedModel 檔案。 |
| TensorFlow SavedModel (AutoML 模型) | 不支援。 |
| XGBoost Booster |
使用自訂預測處理常式。如果是 XGBoost Booster 模型,預先處理和後續處理資訊會儲存在匯出的檔案中,而自訂預測處理常式可讓您部署模型和額外匯出的檔案。 您必須使用支援的 XGBoost 版本建立模型檔案。 |
地端部署作業
| 匯出模型格式 | 部署作業 |
|---|---|
| TensorFlow SavedModel (非 AutoML 模型) |
SavedModel 是標準格式,您可以在 TensorFlow Serving Docker 容器中部署模型。 您也可以運用 Vertex AI 線上預測的本機執行功能。 |
| TensorFlow SavedModel (AutoML 模型) | 將模型容器化並執行。 |
| XGBoost Booster |
如要在本機執行 XGBoost Booster 模型,可以使用匯出的 main.py 檔案:
|
預測輸出格式
本節提供各模型類型的預測輸出格式。所有匯出的模型都支援批次預測,可一次處理多個輸入資料列。舉例來說,在下列輸出格式範例中,每個範例都有兩個輸入資料列。
自動編碼器
| 預測輸出格式 | 輸出範例 |
|---|---|
+------------------------+------------------------+------------------------+
| LATENT_COL_1 | LATENT_COL_2 | ... |
+------------------------+------------------------+------------------------+
| [FLOAT] | [FLOAT] | ... |
+------------------------+------------------------+------------------------+
|
+------------------+------------------+------------------+------------------+
| LATENT_COL_1 | LATENT_COL_2 | LATENT_COL_3 | LATENT_COL_4 |
+------------------------+------------+------------------+------------------+
| 0.21384512 | 0.93457112 | 0.64978097 | 0.00480489 |
+------------------+------------------+------------------+------------------+
|
AUTOML_CLASSIFIER
| 預測輸出格式 | 輸出範例 |
|---|---|
+------------------------------------------+
| predictions |
+------------------------------------------+
| [{"scores":[FLOAT], "classes":[STRING]}] |
+------------------------------------------+
|
+---------------------------------------------+
| predictions |
+---------------------------------------------+
| [{"scores":[1, 2], "classes":['a', 'b']}, |
| {"scores":[3, 0.2], "classes":['a', 'b']}] |
+---------------------------------------------+
|
AUTOML_REGRESSOR
| 預測輸出格式 | 輸出範例 |
|---|---|
+-----------------+
| predictions |
+-----------------+
| [FLOAT] |
+-----------------+
|
+-----------------+
| predictions |
+-----------------+
| [1.8, 2.46] |
+-----------------+
|
BOOSTED_TREE_CLASSIFIER 和 RANDOM_FOREST_CLASSIFIER
| 預測輸出格式 | 輸出範例 |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
BOOSTED_TREE_REGRESSOR 和 RANDOM_FOREST_REGRESSOR
| 預測輸出格式 | 輸出範例 |
|---|---|
+-----------------+
| predicted_label |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| predicted_label |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_CLASSIFIER
| 預測輸出格式 | 輸出範例 |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_REGRESSOR
| 預測輸出格式 | 輸出範例 |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_LINEAR_COMBINED_CLASSIFIER
| 預測輸出格式 | 輸出範例 |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_LINEAR_COMBINED_REGRESSOR
| 預測輸出格式 | 輸出範例 |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
KMEANS
| 預測輸出格式 | 輸出範例 |
|---|---|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [FLOAT] | [INT64] | INT64 |
+--------------------+--------------+---------------------+
|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [1.2, 1.3] | [1, 2] | [1] |
+--------------------+--------------+---------------------+
| [0.4, 0.1] | [1, 2] | [2] |
+--------------------+--------------+---------------------+
|
LINEAR_REG
| 預測輸出格式 | 輸出範例 |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
LOGISTIC_REG
| 預測輸出格式 | 輸出範例 |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
MATRIX_FACTORIZATION
注意:我們目前僅支援輸入使用者,並輸出前 50 個 (predicted_rating、predicted_item) 配對,並依 predicted_rating 降序排序。
| 預測輸出格式 | 輸出範例 |
|---|---|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [FLOAT] | [STRING] |
+------------------+----------------+
|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [5.5, 1.7] | ['A', 'B'] |
+------------------+----------------+
| [7.2, 2.7] | ['B', 'A'] |
+------------------+----------------+
|
TENSORFLOW (已匯入)
| 預測輸出格式 |
|---|
| 與匯入的模型相同 |
PCA
| 預測輸出格式 | 輸出範例 |
|---|---|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [INT64] | [FLOAT] |
+-------------------------+---------------------------------+
|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [1, 2] | [1.2, 5.0] |
+-------------------------+---------------------------------+
|
TRANSFORM_ONLY
| 預測輸出格式 |
|---|
與模型 TRANSFORM 子句中指定的資料欄相同
|
XGBoost 模型視覺化
模型匯出後,您可以使用 plot_tree Python API,以圖表呈現提升樹。舉例來說,您可以在不安裝依附元件的情況下使用 Colab:
- 將升級樹狀結構模型匯出至 Cloud Storage bucket。
- 從 Cloud Storage bucket 下載
model.bst檔案。 - 在 Colab 筆記本中,將
model.bst檔案上傳至Files。 在筆記本中執行下列程式碼:
import xgboost as xgb import matplotlib.pyplot as plt model = xgb.Booster(model_file="model.bst") num_iterations = <iteration_number> for tree_num in range(num_iterations): xgb.plot_tree(model, num_trees=tree_num) plt.show
這個範例會繪製多個樹狀結構 (每個疊代一個樹狀結構):
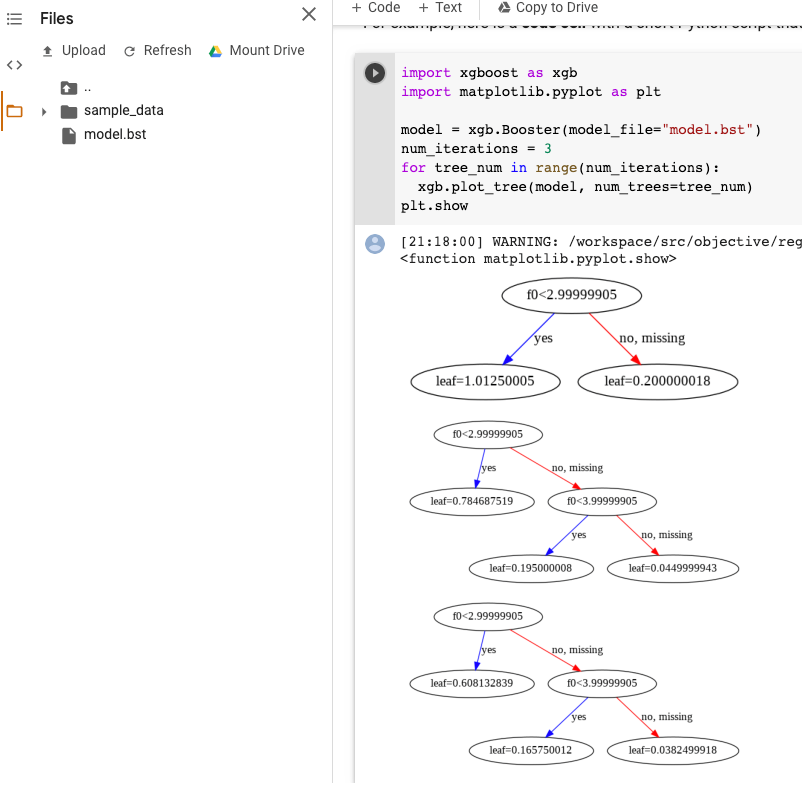
目前我們不會在模型中儲存特徵名稱,因此您會看到「f0」、「f1」等名稱。您可以使用這些名稱 (例如「f0」) 做為索引,在assets/model_metadata.json匯出的檔案中找到對應的特徵名稱。
所需權限
如要將 BigQuery ML 模型匯出至 Cloud Storage,您必須擁有存取 BigQuery ML 模型的權限、執行匯出工作的權限,以及將資料寫入 Cloud Storage bucket 的權限。
BigQuery 權限
您至少必須擁有
bigquery.models.export權限,才能匯出模型。以下是擁有bigquery.models.export權限的預先定義 Identity and Access Management (IAM) 角色:bigquery.dataViewerbigquery.dataOwnerbigquery.dataEditorbigquery.admin
您至少必須擁有
bigquery.jobs.create權限,才能執行匯出工作。以下是擁有bigquery.jobs.create權限的預先定義 IAM 角色:bigquery.userbigquery.jobUserbigquery.admin
Cloud Storage 權限
如要將資料寫入現有的 Cloud Storage 值區,您必須擁有
storage.objects.create權限。以下是擁有storage.objects.create權限的預先定義 IAM 角色:storage.objectCreatorstorage.objectAdminstorage.admin
如要進一步瞭解 BigQuery ML 中的身分與存取權管理角色和權限,請參閱存取權控管。
在不同位置之間移動 BigQuery 資料
資料集建立之後,即無法更改位置,但您可以建立資料集副本。
配額政策
如要瞭解匯出工作配額,請參閱「配額與限制」頁面的匯出工作一節。
定價
匯出 BigQuery ML 模型不會產生費用,但匯出作業須遵循 BigQuery 的配額與限制。如要進一步瞭解 BigQuery 定價,請參閱定價頁面。
匯出資料之後,系統會因您在 Cloud Storage 中儲存資料而向您收取費用。如要進一步瞭解 Cloud Storage 的計價方式,請參閱 Cloud Storage 定價頁面。
後續步驟
- 逐步完成「匯出 BigQuery ML 模型以進行線上預測」教學課程。