Exportar modelos
Nesta página, você aprenderá como exportar modelos do BigQuery ML. É possível exportar modelos do BigQuery ML para o Cloud Storage e usá-los para realizar previsões on-line ou editá-los no Python. Há três maneiras de exportar modelos:
- Com o console doGoogle Cloud .
- usando a instrução
EXPORT MODEL. - usando o comando
bq extractna ferramenta de linha de comando bq; - enviando um
job
extractpor meio da API ou das bibliotecas de cliente.
Os seguintes tipos de modelo podem ser exportados:
AUTOENCODERAUTOML_CLASSIFIERAUTOML_REGRESSORBOOSTED_TREE_CLASSIFIERBOOSTED_TREE_REGRESSORDNN_CLASSIFIERDNN_REGRESSORDNN_LINEAR_COMBINED_CLASSIFIERDNN_LINEAR_COMBINED_REGRESSORKMEANSLINEAR_REGLOGISTIC_REGMATRIX_FACTORIZATIONRANDOM_FOREST_CLASSIFIERRANDOM_FOREST_REGRESSORTENSORFLOW(modelos importados do TensorFlow)PCATRANSFORM_ONLY
Exportar formatos de modelos e amostras
A tabela a seguir mostra os formatos finais de exportação para cada tipo de modelo do BigQuery ML, bem como uma amostra dos arquivos que são gravados no bucket do Cloud Storage.
| Tipo de modelo | Formato do modelo para exportação | Amostra de arquivos exportados |
|---|---|---|
| AUTOML_CLASSIFIER | SavedModel do TensorFlow (TF 2.1.0) | gcs_bucket/
|
| AUTOML_REGRESSOR | ||
| AUTOENCODER | SavedModel do TensorFlow (TF 1.15 ou superior) | |
| DNN_CLASSIFIER | ||
| DNN_REGRESSOR | ||
| DNN_LINEAR_COMBINED_CLASSIFIER | ||
| DNN_LINEAR_COMBINED_REGRESSOR | ||
| KMEANS | ||
| LINEAR_REGRESSOR | ||
| LOGISTIC_REG | ||
| MATRIX_FACTORIZATION | ||
| PCA | ||
| TRANSFORM_ONLY | ||
| BOOSTED_TREE_CLASSIFIER | Otimizador (XGBoost 0,82) | gcs_bucket/
main.py é para execução local. Consulte Implantação de modelos para mais detalhes.
|
| BOOSTED_TREE_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| TENSORFLOW (importado) | TensorFlow SavedModel | Exatamente os mesmos arquivos que estavam presentes ao importar o modelo |
Exporte o modelo treinado com TRANSFORM
Se o modelo for treinado com a
cláusula TRANSFORM,
outro modelo de pré-processamento realiza a mesma lógica na
cláusula TRANSFORM e é salvo no formato SavedModel do Tensorflow no
subdiretório transform.
É possível implantar um modelo treinado com a cláusula TRANSFORM
na Vertex AI e também no local. Para mais informações, consulte
Implantação de modelos.
| Formato do modelo para exportação | Amostra de arquivos exportados |
|---|---|
|
Modelo de previsão: SavedModel do TensorFlow ou Booster (XGBoost 0,82).
Modelo de pré-processamento para a cláusula TRANSFORM: SavedModel do TensorFlow (TF 2.5 ou mais recente) |
gcs_bucket/
|
O modelo não contém as informações sobre a engenharia de atributos
realizada fora da cláusula TRANSFORM
durante o treinamento. Por exemplo, qualquer item na instrução SELECT. Portanto,
é necessário converter manualmente os dados de entrada antes de alimentar o modelo de
pré-processamento.
Tipos de dados compatíveis
Ao exportar modelos treinados com a cláusula TRANSFORM,
os seguintes tipos de dados são compatíveis para serem incluídos na
cláusula TRANSFORM.
| Tipo de entrada TRANSFORM | Exemplos de entrada TRANSFORM | Exemplos de entrada de modelo de pré-processamento exportadas |
|---|---|---|
| INT64 |
10,
|
tf.constant(
|
| NUMERIC |
NUMERIC 10,
|
tf.constant(
|
| BIGNUMERIC |
BIGNUMERIC 10,
|
tf.constant(
|
| FLOAT64 |
10.0,
|
tf.constant(
|
| BOOL |
TRUE,
|
tf.constant(
|
| STRING |
'abc',
|
tf.constant(
|
| BYTES |
b'abc',
|
tf.constant(
|
| DATE |
DATE '2020-09-27',
|
tf.constant(
|
| DATETIME |
DATETIME '2023-02-02 02:02:01.152903',
|
tf.constant(
|
| TIME |
TIME '16:32:36.152903',
|
tf.constant(
|
| TIMESTAMP |
TIMESTAMP '2017-02-28 12:30:30.45-08',
|
tf.constant(
|
| ARRAY |
['a', 'b'],
|
tf.constant(
|
| ARRAY< STRUCT< INT64, FLOAT64>> |
[(1, 1.0), (2, 1.0)],
|
tf.sparse.from_dense(
|
| NULL |
NULL,
|
tf.constant(
|
Funções SQL compatíveis
Ao exportar modelos treinados com a cláusula TRANSFORM,
é possível usar as seguintes funções SQL dentro da cláusula TRANSFORM.
- Operadores
+,-,*,/,=,<,>,<=,>=,!=,<>,[NOT] BETWEEN,[NOT] IN,IS [NOT] NULL,IS [NOT] TRUE,IS [NOT] FALSE,NOT,AND,OR.
- Expressões condicionais
CASE expr,CASE,COALESCE,IF,IFNULL,NULLIF.
- Funções matemáticas
ABS,ACOS,ACOSH,ASINH,ATAN,ATAN2,ATANH,CBRT,CEIL,CEILING,COS,COSH,COT,COTH,CSC,CSCH,EXP,FLOOR,IS_INF,IS_NAN,LN,LOG,LOG10,MOD,POW,POWER,SEC,SECH,SIGN,SIN,SINH,SQRT,TAN,TANH.
- Funções de conversão
CAST AS INT64,CAST AS FLOAT64,CAST AS NUMERIC,CAST AS BIGNUMERIC,CAST AS STRING,SAFE_CAST AS INT64,SAFE_CAST AS FLOAT64
- Funções de string
CONCAT,LEFT,LENGTH,LOWER,REGEXP_REPLACE,RIGHT,SPLIT,SUBSTR,SUBSTRING,TRIM,UPPER.
- Funções de data
Date,DATE_ADD,DATE_SUB,DATE_DIFF,DATE_TRUNC,EXTRACT,FORMAT_DATE,PARSE_DATE,SAFE.PARSE_DATE.
- Funções de data/hora
DATETIME,DATETIME_ADD,DATETIME_SUB,DATETIME_DIFF,DATETIME_TRUNC,EXTRACT,PARSE_DATETIME,SAFE.PARSE_DATETIME.
- Funções de hora
TIME,TIME_ADD,TIME_SUB,TIME_DIFF,TIME_TRUNC,EXTRACT,FORMAT_TIME,PARSE_TIME,SAFE.PARSE_TIME.
- Funções de carimbo de data/hora
TIMESTAMP,TIMESTAMP_ADD,TIMESTAMP_SUB,TIMESTAMP_DIFF,TIMESTAMP_TRUNC,FORMAT_TIMESTAMP,PARSE_TIMESTAMP,SAFE.PARSE_TIMESTAMP,TIMESTAMP_MICROS,TIMESTAMP_MILLIS,TIMESTAMP_SECONDS,EXTRACT,STRING,UNIX_MICROS,UNIX_MILLIS,UNIX_SECONDS.
- Funções de pré-processamento manuais
ML.IMPUTER,ML.HASH_BUCKETIZE,ML.LABEL_ENCODER,ML.MULTI_HOT_ENCODER,ML.NGRAMS,ML.ONE_HOT_ENCODER,ML.BUCKETIZE,ML.MAX_ABS_SCALER,ML.MIN_MAX_SCALER,ML.NORMALIZER,ML.QUANTILE_BUCKETIZE,ML.ROBUST_SCALER,ML.STANDARD_SCALER.
Limitações
As limitações a seguir são aplicadas na exportação de modelos:
Não será possível exportar modelos se qualquer um dos recursos a seguir for usado durante o treinamento:
- Os tipos de recurso
ARRAY,TIMESTAMPouGEOGRAPHYestavam presentes nos dados de entrada.
- Os tipos de recurso
Os modelos exportados para os tipos de modelo
AUTOML_REGRESSOReAUTOML_CLASSIFIERnão são compatíveis com a implantação da Vertex AI para previsão on-line.O limite de tamanho do modelo para a exportação do modelo de fatoração de matrizes é 1 GB. O tamanho do modelo é quase proporcional a
num_factors, então será possível reduzirnum_factorsdurante o treinamento para diminuir o tamanho do modelo se você atingir o limite.Para modelos treinados com a cláusula
TRANSFORMdo BigQuery ML para pré-processamento de atributos manual, consulte os tipos de dados e funções compatíveis com exportação.Modelos treinados com a cláusula
TRANSFORMdo BigQuery ML antes de 18 de setembro de 2023 precisam ser treinados novamente antes de serem implantados pelo Model Registry para previsão on-line.Durante a exportação do modelo,
ARRAY<STRUCT<INT64, FLOAT64>>,ARRAYeTIMESTAMPsão aceitos como dados pré-transformados, mas não como dados pós-transformados.
Exportar modelos do BigQuery ML
Para exportar um modelo, selecione uma das seguintes opções:
Console
Abra a página do BigQuery no console do Google Cloud .
No painel à esquerda, clique em Explorer:

Se o painel esquerdo não aparecer, clique em Expandir painel esquerdo para abrir.
No painel Explorer, expanda o projeto, clique em Conjuntos de dados e selecione seu conjunto de dados.
Clique em Visão geral > Modelos e clique no nome do modelo que você quer exportar.
Clique em Mais > Exportar:
Na caixa de diálogo Exportar modelo para o Google Cloud Storage:
- Em Selecionar local do GCS, procure o local do bucket ou da pasta em que você quer exportar o modelo e clique em Selecionar.
- Clique em Enviar para exportar o modelo.
Para verificar o andamento do job, no painel Explorer, clique em Histórico de jobs e procure um job do tipo EXTRAÇÃO.
SQL
A instrução EXPORT MODEL permite exportar modelos do BigQuery ML para o
Cloud Storage usando a sintaxe de consulta do
GoogleSQL.
Para exportar um modelo do BigQuery ML no console Google Cloud usando a instrução EXPORT MODEL, siga estas etapas:
No console do Google Cloud , abra a página do BigQuery.
Clique em Escrever nova consulta.
No campo Editor de consultas, digite a instrução
EXPORT MODEL.A consulta a seguir exporta um modelo chamado
myproject.mydataset.mymodelpara um bucket do Cloud Storage com o URIgs://bucket/path/to/saved_model/.EXPORT MODEL `myproject.mydataset.mymodel` OPTIONS(URI = 'gs://bucket/path/to/saved_model/')
Clique em Executar. Quando a consulta for concluída, o seguinte aparecerá no painel Resultados da consulta:
Successfully exported model.
bq
Use o comando bq extractcom a sinalização --model.
(Opcional) Forneça a sinalização --destination_format e escolha o formato do modelo exportado.
(Opcional) Forneça a sinalização --location e defina o valor para seu local.
bq --location=location extract \ --destination_format format \ --model project_id:dataset.model \ gs://bucket/model_folder
Em que:
- location é o nome do local. A sinalização
--locationé opcional. Por exemplo, se você estiver usando o BigQuery na região de Tóquio, defina o valor da sinalização comoasia-northeast1. Defina um valor padrão para a unidade usando o arquivo .bigqueryr. - destination_format é o formato do modelo exportado:
ML_TF_SAVED_MODEL(padrão) ouML_XGBOOST_BOOSTER. - project_id é o ID do projeto;
- dataset é o nome do conjunto de dados de origem;
- model é o modelo que você está exportando.
- bucket é o nome do bucket do Cloud Storage para o qual você está exportando os dados. O conjunto de dados do BigQuery e o bucket do Cloud Storage precisam estar no mesmo local;
- model_folder é o nome da pasta em que os arquivos de modelo exportados serão gravados.
Exemplos:
O comando a seguir exporta mydataset.mymodel no formato SavedModel do TensorFlow para um bucket do Cloud Storage chamado mymodel_folder.
bq extract --model \ 'mydataset.mymodel' \ gs://example-bucket/mymodel_folder
O valor padrão de destination_format é ML_TF_SAVED_MODEL.
O comando a seguir exporta mydataset.mymodel no formato XGBoost Booster para um bucket do Cloud Storage chamado mymodel_folder.
bq extract --model \ --destination_format ML_XGBOOST_BOOSTER \ 'mydataset.mytable' \ gs://example-bucket/mymodel_folder
API
Para exportar um modelo, crie um job extract e preencha a configuração dele.
(Opcional) Especifique seu local na propriedade location na seção jobReference do recurso job.
Crie um job de extração que aponte para o modelo do BigQuery ML e o destino do Cloud Storage.
Especifique o modelo de origem usando o objeto de configuração
sourceModel, que contém os IDs do projeto, do conjunto de dados e do modelo.A propriedade
destination URI(s)precisa ser totalmente qualificada no formato gs://bucket/model_folder.Especifique o formato de destino definindo a propriedade
configuration.extract.destinationFormat. Por exemplo, para exportar um modelo de árvore otimizada, defina essa propriedade com o valorML_XGBOOST_BOOSTER.Para verificar o status do job, chame jobs.get(job_id) com o ID do job retornado pela solicitação inicial.
status.state = DONEindica que o job foi concluído.- Se a propriedade
status.errorResultaparecer, isso indica que houve falha na solicitação, e o objeto incluirá informações que descrevem o erro. - Se
status.errorResultnão aparecer, o job foi concluído com sucesso, mesmo se tiver ocorrido erros não fatais. Tais erros são listados na propriedadestatus.errorsdo objeto do job retornado.
Observações sobre a API:
Como prática recomendada, gere um ID exclusivo e transmita-o como
jobReference.jobIdao chamarjobs.insertpara criar um job. Essa abordagem é mais resistente a falhas de rede porque o cliente pode pesquisar ou tentar novamente com o ID do job conhecido.Chamar
jobs.insertem um determinado ID de job é idempotente, ou seja, mesmo que você repita o processo inúmeras vezes com o mesmo ID, somente uma das operações, no máximo, será bem-sucedida.
Java
Antes de testar esta amostra, siga as instruções de configuração do Java no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Java.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Implantação do modelo
É possível implantar o modelo exportado na Vertex AI e no local. Se a
cláusula TRANSFORM do modelo contém funções de data, funções de data e hora, funções de hora ou funções de carimbo de data e hora, é preciso
usar a Biblioteca bigquery-ml-utils
no contêiner. A exceção é se você estiver implantando por meio do Model Registry,
que não precisa de modelos exportados ou de exibição de contêineres.
Implantação da Vertex AI
| Formato do modelo para exportação | Implantação |
|---|---|
| SavedModel do Tensorflow (exceto modelos AutoML) | Implantar um SavedModel do TensorFlow. É necessário criar o arquivo SavedModel usando uma versão com suporte do TensorFlow. |
| SavedModel do Tensorflow (modelos AutoML) | Incompatível. |
| XGBoost Booster |
usar uma rotina de previsão personalizada. Para modelos do XGBoost Booster, as informações de pré-processamento e pós-processamento são salvas nos arquivos exportados, e uma rotina de predição personalizada permite implantar o modelo com os arquivos extras exportados.
É preciso criar os arquivos de modelo usando uma versão compatível do XGBoost. |
Implantação local
| Formato do modelo para exportação | Implantação |
|---|---|
| SavedModel do Tensorflow (exceto modelos AutoML) |
O SavedModel é um formato padrão que pode ser implantado no contêiner Docker do Tensorflow Serving. Também é possível aproveitar a execução local da Vertex AI online prediction. |
| SavedModel do Tensorflow (modelos AutoML) | Coloque o modelo em um contêiner e execute-o. |
| XGBoost Booster |
Para executar modelos do XGBoost Booster localmente, use o arquivo main.py exportado:
|
Formato de saída da previsão
Nesta seção, você verá o formato de saída da previsão para cada tipo de modelo exportado. Todos os tipos de modelo exportado são compatíveis com a previsão em lote, podendo processar várias linhas de entrada por vez. Por exemplo, há duas linhas de entrada em cada um dos exemplos de formato de saída a seguir.
AUTOENCODER
| Formato de saída da previsão | Amostra de saída |
|---|---|
+------------------------+------------------------+------------------------+
| LATENT_COL_1 | LATENT_COL_2 | ... |
+------------------------+------------------------+------------------------+
| [FLOAT] | [FLOAT] | ... |
+------------------------+------------------------+------------------------+
|
+------------------+------------------+------------------+------------------+
| LATENT_COL_1 | LATENT_COL_2 | LATENT_COL_3 | LATENT_COL_4 |
+------------------------+------------+------------------+------------------+
| 0.21384512 | 0.93457112 | 0.64978097 | 0.00480489 |
+------------------+------------------+------------------+------------------+
|
AUTOML_CLASSIFIER
| Formato de saída da previsão | Amostra de saída |
|---|---|
+------------------------------------------+
| predictions |
+------------------------------------------+
| [{"scores":[FLOAT], "classes":[STRING]}] |
+------------------------------------------+
|
+---------------------------------------------+
| predictions |
+---------------------------------------------+
| [{"scores":[1, 2], "classes":['a', 'b']}, |
| {"scores":[3, 0.2], "classes":['a', 'b']}] |
+---------------------------------------------+
|
AUTOML_REGRESSOR
| Formato de saída da previsão | Amostra de saída |
|---|---|
+-----------------+
| predictions |
+-----------------+
| [FLOAT] |
+-----------------+
|
+-----------------+
| predictions |
+-----------------+
| [1.8, 2.46] |
+-----------------+
|
BOOSTED_TREE_CLASSIFIER e RANDOM_FOREST_CLASSIFIER
| Formato de saída da previsão | Amostra de saída |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
BOOSTED_TREE_REGRESSOR E RANDOM_FOREST_REGRESSOR
| Formato de saída da previsão | Amostra de saída |
|---|---|
+-----------------+
| predicted_label |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| predicted_label |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_CLASSIFIER
| Formato de saída da previsão | Amostra de saída |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_REGRESSOR
| Formato de saída da previsão | Amostra de saída |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_LINEAR_COMBINED_CLASSIFIER
| Formato de saída da previsão | Amostra de saída |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_LINEAR_COMBINED_REGRESSOR
| Formato de saída da previsão | Amostra de saída |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
KMEANS
| Formato de saída da previsão | Amostra de saída |
|---|---|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [FLOAT] | [INT64] | INT64 |
+--------------------+--------------+---------------------+
|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [1.2, 1.3] | [1, 2] | [1] |
+--------------------+--------------+---------------------+
| [0.4, 0.1] | [1, 2] | [2] |
+--------------------+--------------+---------------------+
|
LINEAR_REG
| Formato de saída da previsão | Amostra de saída |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
LOGISTIC_REG
| Formato de saída da previsão | Amostra de saída |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
MATRIX_FACTORIZATION
Observação: no momento, é possível usar apenas um usuário de entrada e gerar os 50 principais pares (predicted_rating, predicted_item) classificados por predicted_rating em ordem decrescente.
| Formato de saída da previsão | Amostra de saída |
|---|---|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [FLOAT] | [STRING] |
+------------------+----------------+
|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [5.5, 1.7] | ['A', 'B'] |
+------------------+----------------+
| [7.2, 2.7] | ['B', 'A'] |
+------------------+----------------+
|
TENSORFLOW (importado)
| Formato de saída da previsão |
|---|
| Igual ao modelo importado |
PCA
| Formato de saída da previsão | Amostra de saída |
|---|---|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [INT64] | [FLOAT] |
+-------------------------+---------------------------------+
|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [1, 2] | [1.2, 5.0] |
+-------------------------+---------------------------------+
|
TRANSFORM_ONLY
| Formato de saída da previsão |
|---|
Igual às colunas especificadas na cláusula TRANSFORM do modelo
|
Visualização do modelo XGBoost
Para visualizar as árvores otimizadas, use a API Python plot_tree após a exportação do modelo. Por exemplo, é possível aproveitar o Colab sem instalar as dependências:
- Exporte o modelo de árvore otimizada para um bucket do Cloud Storage.
- Faça o download do arquivo
model.bsta partir do bucket do Cloud Storage. - Em um bloco do Colab, faça o upload do arquivo
model.bstparaFiles. Execute o seguinte código no notebook:
import xgboost as xgb import matplotlib.pyplot as plt model = xgb.Booster(model_file="model.bst") num_iterations = <iteration_number> for tree_num in range(num_iterations): xgb.plot_tree(model, num_trees=tree_num) plt.show
Este exemplo representa várias árvores (uma árvore por iteração):
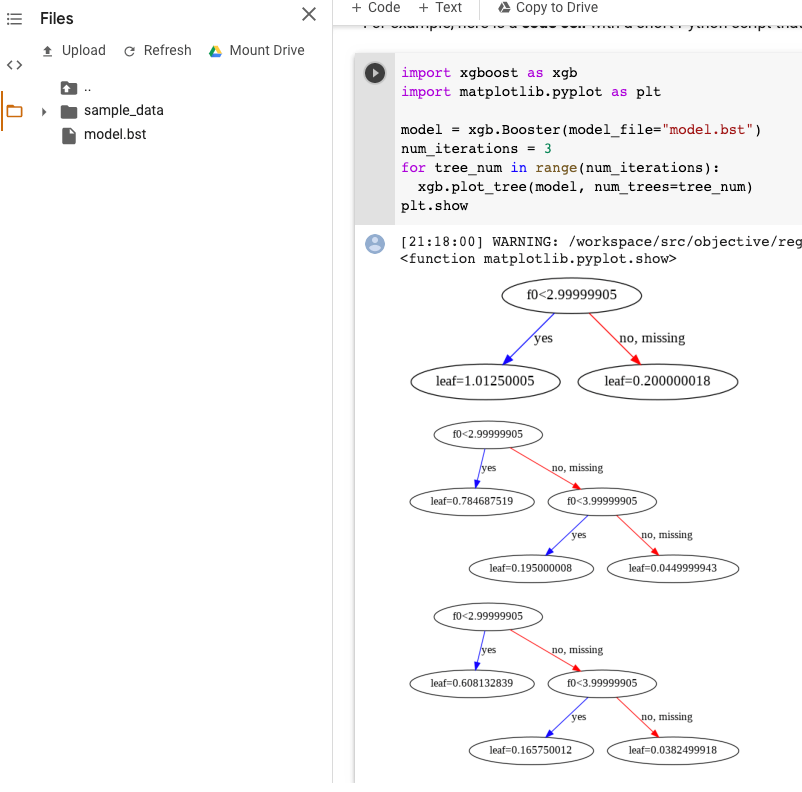
No momento, não salvamos nomes de recursos no modelo. Portanto, você verá nomes como "f0", "f1" e assim por diante. Você encontra os nomes dos recursos correspondentes no arquivo exportado assets/model_metadata.json que tenham esses nomes (como "f0") como índices.
Permissões necessárias
Para exportar um modelo do BigQuery ML para o Cloud Storage, você precisa ter permissões para acessar o modelo, executar jobs de extração e gravar os dados no bucket do Cloud Storage.
Permissões do BigQuery
Para exportar modelos, é necessário ter, no mínimo, as permissões
bigquery.models.export. Os seguintes papéis predefinidos do Identity and Access Management (IAM) recebem permissõesbigquery.models.export:bigquery.dataViewerbigquery.dataOwnerbigquery.dataEditorbigquery.admin
Para executar um job de exportação, é necessário ter, no mínimo, as permissões
bigquery.jobs.create. Os papéis predefinidos do IAM a seguir tem as permissõesbigquery.jobs.create:bigquery.userbigquery.jobUserbigquery.admin
Permissões do Cloud Storage
Para gravar dados em um bucket do Cloud Storage, é necessário ter as permissões
storage.objects.create. Os seguintes papéis predefinidos do IAM tem as permissõesstorage.objects.create:storage.objectCreatorstorage.objectAdminstorage.admin
Para mais informações sobre papéis e permissões do IAM no BigQuery ML, consulte Controle de acesso.
Mover dados do BigQuery entre locais
Não é possível alterar o local de um conjunto de dados após a criação, mas tem como fazer uma cópia dele.
Política de cotas
Para informações sobre cotas de jobs de extração, consulte Jobs de extração na página "Cotas e limites".
Preços
Não há cobrança pela exportação de modelos do BigQuery ML. No entanto, as exportações estão sujeitas a cotas e limites do BigQuery. Consulte a página de preços do BigQuery para mais informações.
Depois que os dados forem exportados, você será cobrado pelo armazenamento deles no Cloud Storage. Consulte a página de preços do Cloud Storage para mais informações.
A seguir
- Acompanhe o tutorial Como exportar um modelo do BigQuery ML para previsão on-line.