모델 내보내기
이 페이지에서는 BigQuery ML 모델을 내보내는 방법을 설명합니다. BigQuery ML 모델을 Cloud Storage로 내보내서 온라인 예측에 사용하거나 Python에서 수정할 수 있습니다. 다음 방법으로 BigQuery ML 모델을 내보낼 수 있습니다.
- Google Cloud 콘솔 사용
EXPORT MODEL문 사용- bq 명령줄 도구에서
bq extract명령어 사용 - API 또는 클라이언트 라이브러리를 통해
extract작업 제출
다음 모델 유형을 내보낼 수 있습니다.
AUTOENCODERAUTOML_CLASSIFIERAUTOML_REGRESSORBOOSTED_TREE_CLASSIFIERBOOSTED_TREE_REGRESSORDNN_CLASSIFIERDNN_REGRESSORDNN_LINEAR_COMBINED_CLASSIFIERDNN_LINEAR_COMBINED_REGRESSORKMEANSLINEAR_REGLOGISTIC_REGMATRIX_FACTORIZATIONRANDOM_FOREST_CLASSIFIERRANDOM_FOREST_REGRESSORTENSORFLOW(가져온 TensorFlow 모델)PCATRANSFORM_ONLY
내보내기 모델 형식 및 샘플
다음 표는 각 BigQuery ML 모델 유형의 내보내기 대상 형식을 보여주고 Cloud Storage 버킷에 작성된 파일의 샘플을 제공합니다.
| 모델 유형 | 내보내기 모델 형식 | 내보낸 파일 샘플 |
|---|---|---|
| AUTOML_CLASSIFIER | TensorFlow 저장된 모델 (TF 2.1.0) | gcs_bucket/
|
| AUTOML_REGRESSOR | ||
| AUTOENCODER | TensorFlow SavedModel (TF 1.15 이상) | |
| DNN_CLASSIFIER | ||
| DNN_REGRESSOR | ||
| DNN_LINEAR_COMBINED_CLASSIFIER | ||
| DNN_LINEAR_COMBINED_REGRESSOR | ||
| KMEANS | ||
| LINEAR_REGRESSOR | ||
| LOGISTIC_REG | ||
| MATRIX_FACTORIZATION | ||
| PCA | ||
| TRANSFORM_ONLY | ||
| BOOSTED_TREE_CLASSIFIER | 부스터(XGBoost 0.82) | gcs_bucket/
main.py는 로컬 실행용입니다. 자세한 내용은 모델 배포를 참조하세요.
|
| BOOSTED_TREE_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| TENSORFLOW(가져옴) | TensorFlow 저장된 모델 | 모델을 가져올 때 존재한 파일과 정확히 같은 파일 |
TRANSFORM으로 학습된 모델 내보내기
모델이 TRANSFORM 절로 학습되면 추가 사전 처리 모델은 TRANSFORM 절에서 동일한 로직을 수행하고 하위 디렉터리 transform 아래의 TensorFlow SavedModel 형식으로 저장됩니다.
TRANSFORM 절로 학습된 모델을 Vertex AI는 물론 로컬에도 배포할 수 있습니다. 자세한 내용은 모델 배포를 참조하세요.
| 내보내기 모델 형식 | 내보낸 파일 샘플 |
|---|---|
|
예측 모델: TensorFlow SavedModel 또는 부스터(XGBoost 0.82)
TRANSFORM 절의 사전 처리 모델: TensorFlow SavedModel(TF 2.5 이상) |
gcs_bucket/
|
모델에는 학습 중에 TRANSFORM 절 외부에서 실행된 특성 추출에 관한 정보가 포함되어 있지 않습니다. 예를 들어 SELECT 문의 모든 항목이 이에 해당합니다. 따라서 사전 처리 모델로 피드하기 전에 입력 데이터를 수동으로 변환해야 합니다.
지원되는 데이터 유형
TRANSFORM 절로 학습된 모델을 내보낼 때 TRANSFORM 절에 피드할 수 있도록 지원되는 데이터 유형은 다음과 같습니다.
| TRANSFORM 입력 유형 | TRANSFORM 입력 샘플 | 내보낸 전처리 모델 입력 샘플 |
|---|---|---|
| INT64 |
10,
|
tf.constant(
|
| NUMERIC |
NUMERIC 10,
|
tf.constant(
|
| BIGNUMERIC |
BIGNUMERIC 10,
|
tf.constant(
|
| FLOAT64 |
10.0,
|
tf.constant(
|
| BOOL |
TRUE,
|
tf.constant(
|
| STRING |
'abc',
|
tf.constant(
|
| BYTES |
b'abc',
|
tf.constant(
|
| DATE |
DATE '2020-09-27',
|
tf.constant(
|
| DATETIME |
DATETIME '2023-02-02 02:02:01.152903',
|
tf.constant(
|
| TIME |
TIME '16:32:36.152903',
|
tf.constant(
|
| TIMESTAMP |
TIMESTAMP '2017-02-28 12:30:30.45-08',
|
tf.constant(
|
| ARRAY |
['a', 'b'],
|
tf.constant(
|
| ARRAY< STRUCT< INT64, FLOAT64>> |
[(1, 1.0), (2, 1.0)],
|
tf.sparse.from_dense(
|
| NULL |
NULL,
|
tf.constant(
|
지원되는 SQL 함수
TRANSFORM 절로 학습된 모델을 내보낼 때 TRANSFORM 절 내에서 다음 SQL 함수를 사용할 수 있습니다.
- 연산자
+,-,*,/,=,<,>,<=,>=,!=,<>,[NOT] BETWEEN,[NOT] IN,IS [NOT] NULL,IS [NOT] TRUE,IS [NOT] FALSE,NOT,AND,OR.
- 조건식
CASE expr,CASE,COALESCE,IF,IFNULL,NULLIF.
- 수학 함수
ABS,ACOS,ACOSH,ASINH,ATAN,ATAN2,ATANH,CBRT,CEIL,CEILING,COS,COSH,COT,COTH,CSC,CSCH,EXP,FLOOR,IS_INF,IS_NAN,LN,LOG,LOG10,MOD,POW,POWER,SEC,SECH,SIGN,SIN,SINH,SQRT,TAN,TANH.
- 변환 함수
CAST AS INT64,CAST AS FLOAT64,CAST AS NUMERIC,CAST AS BIGNUMERIC,CAST AS STRING,SAFE_CAST AS INT64,SAFE_CAST AS FLOAT64
- 문자열 함수
CONCAT,LEFT,LENGTH,LOWER,REGEXP_REPLACE,RIGHT,SPLIT,SUBSTR,SUBSTRING,TRIM,UPPER.
- 날짜 함수
Date,DATE_ADD,DATE_SUB,DATE_DIFF,DATE_TRUNC,EXTRACT,FORMAT_DATE,PARSE_DATE,SAFE.PARSE_DATE.
- 날짜/시간 함수
DATETIME,DATETIME_ADD,DATETIME_SUB,DATETIME_DIFF,DATETIME_TRUNC,EXTRACT,PARSE_DATETIME,SAFE.PARSE_DATETIME.
- 시간 함수
TIME,TIME_ADD,TIME_SUB,TIME_DIFF,TIME_TRUNC,EXTRACT,FORMAT_TIME,PARSE_TIME,SAFE.PARSE_TIME.
- 타임스탬프 함수
TIMESTAMP,TIMESTAMP_ADD,TIMESTAMP_SUB,TIMESTAMP_DIFF,TIMESTAMP_TRUNC,FORMAT_TIMESTAMP,PARSE_TIMESTAMP,SAFE.PARSE_TIMESTAMP,TIMESTAMP_MICROS,TIMESTAMP_MILLIS,TIMESTAMP_SECONDS,EXTRACT,STRING,UNIX_MICROS,UNIX_MILLIS,UNIX_SECONDS.
- 수동 사전 처리 함수
ML.IMPUTER,ML.HASH_BUCKETIZE,ML.LABEL_ENCODER,ML.MULTI_HOT_ENCODER,ML.NGRAMS,ML.ONE_HOT_ENCODER,ML.BUCKETIZE,ML.MAX_ABS_SCALER,ML.MIN_MAX_SCALER,ML.NORMALIZER,ML.QUANTILE_BUCKETIZE,ML.ROBUST_SCALER,ML.STANDARD_SCALER.
제한사항
모델을 내보낼 때 다음 제한사항이 적용됩니다.
학습 중에 다음 특성 중 하나라도 사용된 경우에는 모델 내보내기가 지원되지 않습니다.
- 입력 데이터에
ARRAY,TIMESTAMP또는GEOGRAPHY특성 유형이 있었습니다.
- 입력 데이터에
모델 유형
AUTOML_REGRESSOR및AUTOML_CLASSIFIER의 내보낸 모델은 온라인 예측을 위한 Vertex AI 배포를 지원하지 않습니다.행렬 분해 모델 내보내기의 모델 크기 한도는 1GB입니다. 모델 크기는 대략
num_factors에 비례하기 때문에 학습 중에num_factors를 줄여 한도에 도달하면 모델 크기를 줄일 수 있습니다.수동 특성 사전 처리를 위해 BigQuery ML
TRANSFORM절로 학습된 모델의 경우 내보내기에 지원되는 데이터 유형 및 함수를 참조하세요.2023년 9월 18일 전에 BigQuery ML
TRANSFORM절로 학습한 모델은 온라인 예측용으로 Model Registry를 통해 배포하기 전에 반드시 재학습해야 합니다.모델을 내보내는 동안
ARRAY<STRUCT<INT64, FLOAT64>>,ARRAY,TIMESTAMP는 사전 변환된 데이터로 지원되지만 사후 변환된 데이터로는 지원되지 않습니다.
BigQuery ML 모델 내보내기
모델을 내보내려면 다음 안내를 따르세요.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지를 엽니다.
탐색 패널의 리소스 섹션에서 프로젝트를 펼치고 데이터 세트를 클릭하여 펼칩니다. 내보낼 모델을 찾아 클릭합니다.
창 오른쪽에서 모델 내보내기를 클릭합니다.
Cloud Storage로 모델 내보내기 대화상자에서 다음 안내를 따르세요.
- Cloud Storage 위치 선택에서 모델을 내보낼 버킷 또는 폴더 위치를 찾습니다.
- 내보내기를 클릭하여 모델을 내보냅니다.
작업의 진행 상황을 확인하려면 내보내기 작업의 작업 기록 탐색창에서 맨 위쪽을 확인하세요.
SQL
EXPORT MODEL 문을 사용하면 GoogleSQL 쿼리 구문을 사용하여 BigQuery ML 모델을 Cloud Storage로 내보낼 수 있습니다.
Google Cloud 콘솔에서 EXPORT MODEL 문을 사용하여 BigQuery ML 모델을 내보내려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지를 엽니다.
새 쿼리 작성을 클릭합니다.
쿼리 편집기 필드에
EXPORT MODEL문을 입력합니다.다음 쿼리는 이름이
myproject.mydataset.mymodel인 모델을 URIgs://bucket/path/to/saved_model/가 있는 Cloud Storage 버킷으로 내보냅니다.EXPORT MODEL `myproject.mydataset.mymodel` OPTIONS(URI = 'gs://bucket/path/to/saved_model/')
실행을 클릭합니다. 쿼리가 완료되면 쿼리 결과 창에
Successfully exported model가 나타납니다.
bq
bq extract 명령어를 --model 플래그와 함께 사용합니다.
(선택사항) --destination_format 플래그를 지정하고 모델 내보내기 형식을 선택합니다.
(선택사항) --location 플래그를 지정하고 값을 사용자 위치로 설정합니다.
bq --location=location extract \ --destination_format format \ --model project_id:dataset.model \ gs://bucket/model_folder
각 항목의 의미는 다음과 같습니다.
- location: 사용자 위치의 이름.
--location플래그는 선택사항입니다. 예를 들어 도쿄 리전에서 BigQuery를 사용한다면 플래그 값을asia-northeast1로 설정할 수 있습니다. .bigqueryrc 파일을 사용하여 위치 기본값을 설정할 수 있습니다. - destination_format:
ML_TF_SAVED_MODEL(기본값) 또는ML_XGBOOST_BOOSTER인 내보내는 모델 형식 - project_id: 프로젝트 ID
- dataset: 소스 데이터 세트의 이름
- model: 내보내는 모델
- bucket: 데이터를 내보내는 Cloud Storage 버킷 이름. BigQuery 데이터 세트와 Cloud Storage 버킷은 같은 위치에 있어야 합니다.
- model_folder: 내보내는 모델 파일이 기록되는 폴더의 이름
예를 들면 다음과 같습니다.
예를 들어 다음 명령어는 TensorFlow 저장된 모델 형식의 mydataset.mymodel를 mymodel_folder이라는 Cloud Storage 버킷으로 내보냅니다.
bq extract --model \ 'mydataset.mymodel' \ gs://example-bucket/mymodel_folder
destination_format의 기본값은 ML_TF_SAVED_MODEL입니다.
다음 명령어는 XGBoost Booster 형식의 mydataset.mymodel을 mymodel_folder라는 Cloud Storage 버킷으로 내보냅니다.
bq extract --model \ --destination_format ML_XGBOOST_BOOSTER \ 'mydataset.mytable' \ gs://example-bucket/mymodel_folder
API
모델을 내보내려면 extract 작업을 만들고 작업 구성을 채웁니다.
(선택사항) 작업 리소스의 jobReference 섹션에 있는 location 속성에 사용자 위치를 지정합니다.
BigQuery ML 모델 및 Cloud Storage 대상을 가리키는 추출 작업을 만듭니다.
프로젝트 ID, 데이터 세트 ID, 모델 ID가 포함된
sourceModel구성 객체를 사용하여 소스 모델을 지정합니다.destination URI(s)속성은 gs://bucket/model_folder 형식으로 정규화되어야 합니다.configuration.extract.destinationFormat속성을 설정하여 대상 형식을 지정합니다. 예를 들어 부스티드 트리 모델을 내보내려면 이 속성을ML_XGBOOST_BOOSTER값으로 설정합니다.작업 상태를 확인하려면 초기 요청이 반환한 작업 ID를 사용하여 jobs.get(job_id)을 호출합니다.
status.state = DONE이면 작업이 성공적으로 완료된 것입니다.status.errorResult속성이 있으면 요청이 실패한 것이며 해당 객체에 문제를 설명하는 정보가 포함됩니다.status.errorResult가 없으면 작업은 성공적으로 끝났지만 심각하지 않은 오류가 발생했을 수 있다는 의미입니다. 심각하지 않은 오류는 반환된 작업 객체의status.errors속성에 나열됩니다.
API 참고:
jobs.insert를 호출하여 작업을 만들 때 고유 ID를 생성하여jobReference.jobId로 전달하는 것이 가장 좋습니다. 클라이언트가 알려진 작업 ID로 폴링하거나 재시도할 수 있으므로 이 방법은 네트워크 장애 시에 더욱 안정적입니다.특정한 작업 ID에 대한
jobs.insert호출은 멱등성을 지닙니다. 즉, 같은 작업 ID로 원하는 만큼 다시 시도할 수 있으며 최대 한 번만 성공합니다.
자바
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 BigQuery Java API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
모델 배포
내보낸 모델을 Vertex AI는 물론 로컬에도 배포할 수 있습니다. 모델의 TRANSFORM 절에 날짜 함수, 날짜/시간 함수, 시간 함수 또는 타임스탬프 함수를 포함하면 컨테이너의 bigquery-ml-utils 라이브러리를 사용해야 합니다. 내보낸 모델이나 서빙 컨테이너가 필요하지 않은 Model Registry를 통해 배포하는 경우에는 예외입니다.
Vertex AI 배포
| 내보내기 모델 형식 | 배포 |
|---|---|
| TensorFlow SavedModel(비AutoML 모델) | TensorFlow SavedModel 배포 TensorFlow의 지원되는 버전을 사용하여 SavedModel 파일을 만들어야 합니다. |
| TensorFlow SavedModel(AutoML 모델) | 지원되지 않음. |
| XGBoost Booster |
커스텀 예측 루틴을 사용합니다. XGBoost Booster 모델의 경우 사전 처리 및 후처리 정보가 내보낸 파일에 저장되며 커스텀 예측 루틴을 사용하면 추가로 내보낸 파일로 모델을 배포할 수 있습니다.
XGBoost의 지원되는 버전을 사용하여 모델 파일을 만들어야 합니다. |
로컬 배포
| 내보내기 모델 형식 | 배포 |
|---|---|
| TensorFlow SavedModel(비AutoML 모델) |
SavedModel은 표준 형식이며 TensorFlow Serving Docker 컨테이너에 배포할 수 있습니다. Vertex AI 온라인 예측의 로컬 실행도 활용할 수 있습니다. |
| TensorFlow SavedModel(AutoML 모델) | 모델을 컨테이너화하고 실행합니다. |
| XGBoost Booster | XGBoost Booster 모델을 로컬로 실행하려면 내보낸 main.py 파일을 사용할 수 있습니다.
|
예측 출력 형식
이 섹션에서는 각 모델 유형의 내보낸 모델 예측 출력 형식을 제공합니다. 내보낸 모든 모델은 일괄 예측을 지원합니다. 여러 입력 행을 한 번에 처리할 수 있습니다. 예를 들어 다음 각 출력 형식의 예시에는 두 개의 입력 행이 있습니다.
AUTOENCODER
| 예측 출력 형식 | 출력 샘플 |
|---|---|
+------------------------+------------------------+------------------------+
| LATENT_COL_1 | LATENT_COL_2 | ... |
+------------------------+------------------------+------------------------+
| [FLOAT] | [FLOAT] | ... |
+------------------------+------------------------+------------------------+
|
+------------------+------------------+------------------+------------------+
| LATENT_COL_1 | LATENT_COL_2 | LATENT_COL_3 | LATENT_COL_4 |
+------------------------+------------+------------------+------------------+
| 0.21384512 | 0.93457112 | 0.64978097 | 0.00480489 |
+------------------+------------------+------------------+------------------+
|
AUTOML_CLASSIFIER
| 예측 출력 형식 | 출력 샘플 |
|---|---|
+------------------------------------------+
| predictions |
+------------------------------------------+
| [{"scores":[FLOAT], "classes":[STRING]}] |
+------------------------------------------+
|
+---------------------------------------------+
| predictions |
+---------------------------------------------+
| [{"scores":[1, 2], "classes":['a', 'b']}, |
| {"scores":[3, 0.2], "classes":['a', 'b']}] |
+---------------------------------------------+
|
AUTOML_REGRESSOR
| 예측 출력 형식 | 출력 샘플 |
|---|---|
+-----------------+
| predictions |
+-----------------+
| [FLOAT] |
+-----------------+
|
+-----------------+
| predictions |
+-----------------+
| [1.8, 2.46] |
+-----------------+
|
BOOSTED_TREE_CLASSIFIER 및 RANDOM_FOREST_CLASSIFIER
| 예측 출력 형식 | 출력 샘플 |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
BOOSTED_TREE_REGRESSOR 및 RANDOM_FOREST_REGRESSOR
| 예측 출력 형식 | 출력 샘플 |
|---|---|
+-----------------+
| predicted_label |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| predicted_label |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_CLASSIFIER
| 예측 출력 형식 | 출력 샘플 |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_REGRESSOR
| 예측 출력 형식 | 출력 샘플 |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_LINEAR_COMBINED_CLASSIFIER
| 예측 출력 형식 | 출력 샘플 |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_LINEAR_COMBINED_REGRESSOR
| 예측 출력 형식 | 출력 샘플 |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
KMEANS
| 예측 출력 형식 | 출력 샘플 |
|---|---|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [FLOAT] | [INT64] | INT64 |
+--------------------+--------------+---------------------+
|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [1.2, 1.3] | [1, 2] | [1] |
+--------------------+--------------+---------------------+
| [0.4, 0.1] | [1, 2] | [2] |
+--------------------+--------------+---------------------+
|
LINEAR_REG
| 예측 출력 형식 | 출력 샘플 |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
LOGISTIC_REG
| 예측 출력 형식 | 출력 샘플 |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
MATRIX_FACTORIZATION
참고: 현재는 predicted_rating를 기준으로 입력 사용자 및 출력(predicted_rating, predicted_item)의 상위 50개 쌍만 내림차순으로 정렬하도록 지원합니다.
| 예측 출력 형식 | 출력 샘플 |
|---|---|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [FLOAT] | [STRING] |
+------------------+----------------+
|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [5.5, 1.7] | ['A', 'B'] |
+------------------+----------------+
| [7.2, 2.7] | ['B', 'A'] |
+------------------+----------------+
|
TENSORFLOW(가져옴)
| 예측 출력 형식 |
|---|
| 가져온 모델과 동일 |
PCA
| 예측 출력 형식 | 출력 샘플 |
|---|---|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [INT64] | [FLOAT] |
+-------------------------+---------------------------------+
|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [1, 2] | [1.2, 5.0] |
+-------------------------+---------------------------------+
|
TRANSFORM_ONLY
| 예측 출력 형식 |
|---|
모델의 TRANSFORM 절에 지정된 열과 동일
|
XGBoost 모델 시각화
모델 내보내기 이후 plot_tree Python API를 사용하여 부스티드 트리를 시각화할 수 있습니다. 예를 들어 종속 항목을 설치하지 않고도 Colab을 사용할 수 있습니다.
- 부스티드 트리 모델을 Cloud Storage 버킷으로 내보냅니다.
- Cloud Storage 버킷에서
model.bst파일을 다운로드합니다. - Colab 메모장에서
model.bst파일을Files에 업로드합니다. 노트북에서 다음 코드를 실행합니다.
import xgboost as xgb import matplotlib.pyplot as plt model = xgb.Booster(model_file="model.bst") num_iterations = <iteration_number> for tree_num in range(num_iterations): xgb.plot_tree(model, num_trees=tree_num) plt.show
이 예시에서는 다중 트리(반복당 트리 한 개)를 구성합니다.
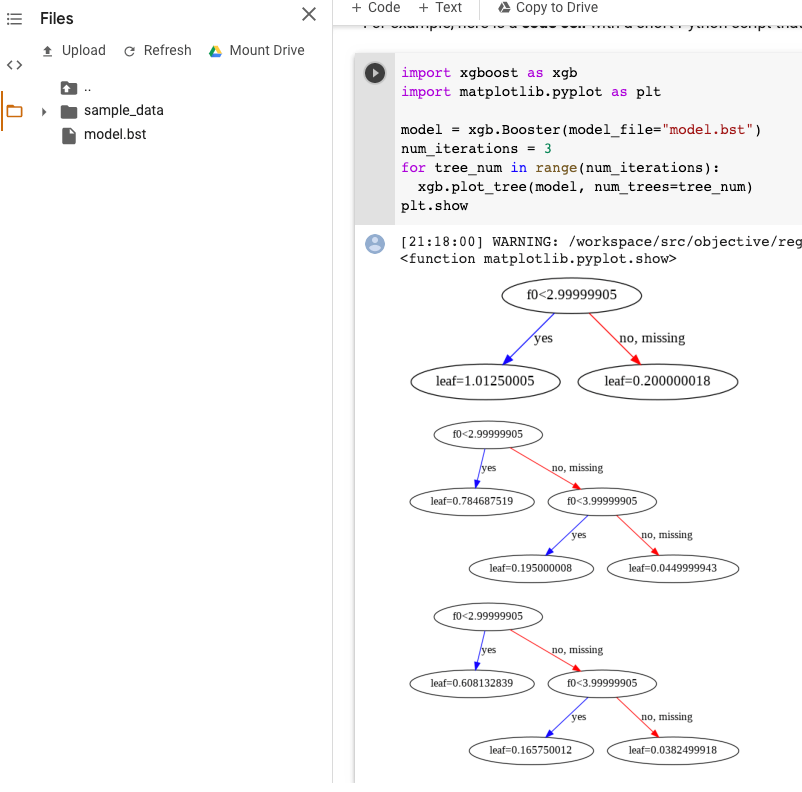
현재는 모델에 특성 이름이 저장되지 않으므로, 'f0', 'f1', 등의 이름이 표시됩니다. 이러한 이름(예: 'f0')을 색인으로 사용해서 assets/model_metadata.json 내보낸 파일에서 해당 특성 이름을 찾을 수 있습니다.
필수 권한
BigQuery ML 모델을 Cloud Storage로 내보내려면 BigQuery ML 모델에 액세스할 수 있는 권한, 내보내기 작업을 실행할 수 있는 권한, Cloud Storage 버킷에 데이터를 쓸 수 있는 권한이 필요합니다.
BigQuery 권한
모델을 내보내려면 최소한
bigquery.models.export권한을 부여받아야 합니다. 사전 정의된 Identity and Access Management(IAM) 역할에bigquery.models.export권한이 부여됩니다.bigquery.dataViewerbigquery.dataOwnerbigquery.dataEditorbigquery.admin
내보내기 작업을 실행하려면 최소한
bigquery.jobs.create권한이 부여되어 있어야 합니다. 사전 정의된 다음 IAM 역할에bigquery.jobs.create권한이 부여됩니다.bigquery.userbigquery.jobUserbigquery.admin
Cloud Storage 권한
기존 Cloud Storage 버킷에 데이터를 쓰려면
storage.objects.create권한이 부여되어 있어야 합니다. 사전 정의된 다음 IAM 역할에storage.objects.create권한이 부여됩니다.storage.objectCreatorstorage.objectAdminstorage.admin
BigQuery ML의 IAM 역할과 권한에 대한 자세한 내용은 액세스 제어를 참조하세요.
다른 위치 간 BigQuery 데이터 이동
데이터세트가 생성된 후에는 데이터세트 위치를 변경할 수 없지만 데이터세트를 복사할 수 있습니다.
할당량 정책
내보내기 작업 할당량에 대한 자세한 내용은 할당량 및 한도 페이지의 내보내기 작업을 참조하세요.
가격 책정
BigQuery ML 모델 내보내기는 무료지만 내보내기에는 BigQuery의 할당량 및 한도가 적용됩니다. BigQuery 가격에 대한 자세한 내용은 가격 책정 페이지를 참조하세요.
데이터를 내보낸 후 Cloud Storage에 데이터를 저장하는 데는 요금이 청구됩니다. Cloud Storage 가격에 대한 자세한 내용은 Cloud Storage 가격 책정 페이지를 참조하세요.
다음 단계
- 온라인 예측을 위한 BigQuery ML 모델 내보내기 튜토리얼 살펴보기