Modelle exportieren
Auf dieser Seite wird gezeigt, wie Sie BigQuery ML-Modelle exportieren. Sie können BigQuery ML-Modelle nach Cloud Storage exportieren und dann für Onlinevorhersagen verwenden oder in Python bearbeiten. So exportieren Sie ein BigQuery ML-Modell:
- Google Cloud Console verwenden
- Anweisung
EXPORT MODELverwenden - Mit dem Befehl
bq extractim bq-Befehlszeilentool. - Durch Senden eines
extract-Jobs über die API oder die Clientbibliotheken
Sie können die folgenden Modelltypen exportieren:
AUTOENCODERAUTOML_CLASSIFIERAUTOML_REGRESSORBOOSTED_TREE_CLASSIFIERBOOSTED_TREE_REGRESSORDNN_CLASSIFIERDNN_REGRESSORDNN_LINEAR_COMBINED_CLASSIFIERDNN_LINEAR_COMBINED_REGRESSORKMEANSLINEAR_REGLOGISTIC_REGMATRIX_FACTORIZATIONRANDOM_FOREST_CLASSIFIERRANDOM_FOREST_REGRESSORTENSORFLOW(importierte TensorFlow-Modelle)PCATRANSFORM_ONLY
Exportmodellformate und Beispiele
Die folgende Tabelle enthält die Exportzielformate für die verschiedenen BigQuery ML-Modelltypen sowie ein Beispiel für Dateien, die in den Cloud Storage-Bucket geschrieben werden.
| Modelltyp | Exportmodellformat | Beispiel für exportierte Dateien |
|---|---|---|
| AUTOML_CLASSIFIER | TensorFlow SavedModel (TF 2.1.0) | gcs_bucket/
|
| AUTOML_REGRESSOR | ||
| AUTOENCODER | TensorFlow SavedModel (TF 1.15 oder höher) | |
| DNN_CLASSIFIER | ||
| DNN_REGRESSOR | ||
| DNN_LINEAR_COMBINED_CLASSIFIER | ||
| DNN_LINEAR_COMBINED_REGRESSOR | ||
| KMEANS | ||
| LINEAR_REGRESSOR | ||
| LOGISTIC_REG | ||
| MATRIX_FACTORIZATION | ||
| PCA | ||
| TRANSFORM_ONLY | ||
| BOOSTED_TREE_CLASSIFIER | Booster (XGBoost 0.82) | gcs_bucket/
main.py dient der lokalen Ausführung. Weitere Informationen finden Sie unter Modellbereitstellung.
|
| BOOSTED_TREE_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| TENSORFLOW (importiert) | TensorFlow SavedModel | Exakt die gleichen Dateien, die beim Importieren des Modells vorhanden waren |
Mit TRANSFORM trainiertes Modell exportieren
Wenn das Modell mit der TRANSFORM-Anweisung trainiert wird, führt ein zusätzliches Vorverarbeitungsmodell die gleiche Logik in der TRANSFORM-Klausel aus und wird im TensorFlow-SavedModel-Format im Unterverzeichnis transform gespeichert.
Sie können ein mit der TRANSFORM-Anweisung trainiertes Modell sowohl in Vertex AI als auch lokal bereitstellen. Weitere Informationen finden Sie unter Modellbereitstellung.
| Exportmodellformat | Beispiel für exportierte Dateien |
|---|---|
|
Vorhersagemodell: TensorFlow SavedModel oder Booster (XGBoost 0.82).
Vorverarbeitungsmodell für TRANSFORM-Klausel: TensorFlow SavedModel (TF 2.5 oder höher) |
gcs_bucket/
|
Das Modell enthält nicht die Informationen zum Feature Engineering, das während des Trainings außerhalb der TRANSFORM-Klausel ausgeführt wird. Beispiel: Alles in der SELECT-Anweisung. Sie müssen also die Eingabedaten manuell konvertieren, bevor Sie sie in das Vorverarbeitungsmodell einspeisen.
Unterstützte Datentypen
Beim Exportieren von Modellen, die mit der TRANSFORM-Klausel trainiert wurden, werden die folgenden Datentypen für die Einspeisung in die TRANSFORM-Anweisung unterstützt.
| Eingabetyp TRANSFORM | Eingabebeispiele TRANSFORM | Eingabebeispiele für exportierte Vorverarbeitungsmodellen |
|---|---|---|
| INT64 |
10,
|
tf.constant(
|
| NUMERIC |
NUMERIC 10,
|
tf.constant(
|
| BIGNUMERIC |
BIGNUMERIC 10,
|
tf.constant(
|
| FLOAT64 |
10.0,
|
tf.constant(
|
| BOOL |
TRUE,
|
tf.constant(
|
| STRING |
'abc',
|
tf.constant(
|
| BYTES |
b'abc',
|
tf.constant(
|
| DATE |
DATE '2020-09-27',
|
tf.constant(
|
| DATETIME |
DATETIME '2023-02-02 02:02:01.152903',
|
tf.constant(
|
| TIME |
TIME '16:32:36.152903',
|
tf.constant(
|
| TIMESTAMP |
TIMESTAMP '2017-02-28 12:30:30.45-08',
|
tf.constant(
|
| ARRAY |
['a', 'b'],
|
tf.constant(
|
| ARRAY< STRUCT< INT64, FLOAT64>> |
[(1, 1.0), (2, 1.0)],
|
tf.sparse.from_dense(
|
| NULL |
NULL,
|
tf.constant(
|
Unterstützte SQL-Funktionen
Beim Exportieren von Modellen, die mit der TRANSFORM-Anweisung trainiert wurden, können Sie die folgenden SQL-Funktionen in der TRANSFORM-Anweisung verwenden.
- Operatoren
+,-,*,/,=,<,>,<=,>=,!=,<>,[NOT] BETWEEN,[NOT] IN,IS [NOT] NULL,IS [NOT] TRUE,IS [NOT] FALSE,NOT,AND,OR.
- Bedingte Ausdrücke
CASE expr,CASE,COALESCE,IF,IFNULL,NULLIF.
- Mathematische Funktionen
ABS,ACOS,ACOSH,ASINH,ATAN,ATAN2,ATANH,CBRT,CEIL,CEILING,COS,COSH,COT,COTH,CSC,CSCH,EXP,FLOOR,IS_INF,IS_NAN,LN,LOG,LOG10,MOD,POW,POWER,SEC,SECH,SIGN,SIN,SINH,SQRT,TAN,TANH.
- Umrechnungsfunktionen
CAST AS INT64,CAST AS FLOAT64,CAST AS NUMERIC,CAST AS BIGNUMERIC,CAST AS STRING,SAFE_CAST AS INT64,SAFE_CAST AS FLOAT64
- Stringfunktionen
CONCAT,LEFT,LENGTH,LOWER,REGEXP_REPLACE,RIGHT,SPLIT,SUBSTR,SUBSTRING,TRIM,UPPER.
- Datumsfunktionen
Date,DATE_ADD,DATE_SUB,DATE_DIFF,DATE_TRUNC,EXTRACT,FORMAT_DATE,PARSE_DATE,SAFE.PARSE_DATE.
- Datums-/Zeitfunktionen
DATETIME,DATETIME_ADD,DATETIME_SUB,DATETIME_DIFF,DATETIME_TRUNC,EXTRACT,PARSE_DATETIME,SAFE.PARSE_DATETIME.
- Zeitfunktionen
TIME,TIME_ADD,TIME_SUB,TIME_DIFF,TIME_TRUNC,EXTRACT,FORMAT_TIME,PARSE_TIME,SAFE.PARSE_TIME.
- Zeitstempelfunktionen
TIMESTAMP,TIMESTAMP_ADD,TIMESTAMP_SUB,TIMESTAMP_DIFF,TIMESTAMP_TRUNC,FORMAT_TIMESTAMP,PARSE_TIMESTAMP,SAFE.PARSE_TIMESTAMP,TIMESTAMP_MICROS,TIMESTAMP_MILLIS,TIMESTAMP_SECONDS,EXTRACT,STRING,UNIX_MICROS,UNIX_MILLIS,UNIX_SECONDS.
- Manuelle Vorverarbeitungsfunktionen
ML.IMPUTER,ML.HASH_BUCKETIZE,ML.LABEL_ENCODER,ML.MULTI_HOT_ENCODER,ML.NGRAMS,ML.ONE_HOT_ENCODER,ML.BUCKETIZE,ML.MAX_ABS_SCALER,ML.MIN_MAX_SCALER,ML.NORMALIZER,ML.QUANTILE_BUCKETIZE,ML.ROBUST_SCALER,ML.STANDARD_SCALER.
Beschränkungen
Beim Exportieren von Modellen gelten folgende Beschränkungen:
Der Modellexport wird nicht unterstützt, wenn für das Training eines der folgenden Features verwendet wurde:
- Die Eingabedatentypen
ARRAY,TIMESTAMPoderGEOGRAPHYwaren in den Eingabedaten vorhanden.
- Die Eingabedatentypen
Die exportierten Modelle für die Modelltypen
AUTOML_REGRESSORundAUTOML_CLASSIFIERunterstützen keine Vertex AI-Bereitstellung für Onlinevorhersagen.Der Modellgrößenlimit beträgt 1 GB für das Exportieren des Matrixfaktorisierungsmodells. Die Modellgröße ist ungefähr proportional zu
num_factors. Sie können alsonum_factorswährend des Trainings reduzieren, um die Modellgröße zu verkleinern, wenn Sie das Limit erreichen.Für Modelle, die mit der BigQuery ML
TRANSFORM-Klausel für die Manuelle Vorverarbeitung von Features trainiert wurden, beachten Sie die für den Export unterstützten Datentypen und Funktionen.Modelle, die vor dem 18. September 2023 mit der BigQuery
TRANSFORM-Klausel trainiert wurden, müssen neu trainiert werden, bevor sie für Online-Vorhersagen über Model Registry bereitgestellt werden können.Beim Modellexport werden
ARRAY<STRUCT<INT64, FLOAT64>>ARRAYundTIMESTAMPals vor-transformierte Daten unterstützt, aber nicht als nach-transformierte Daten.
BigQuery ML-Modelle exportieren
So exportieren Sie ein Modell:
Console
Öffnen Sie in der Google Cloud Console die Seite „BigQuery“.
Maximieren Sie im Navigationsbereich im Abschnitt Ressourcen Ihr Projekt und klicken Sie dann zum Maximieren auf Ihr Dataset. Ermitteln Sie das Modell, das Sie exportieren möchten, und klicken Sie darauf.
Klicken Sie rechts im Fenster auf Modell exportieren.
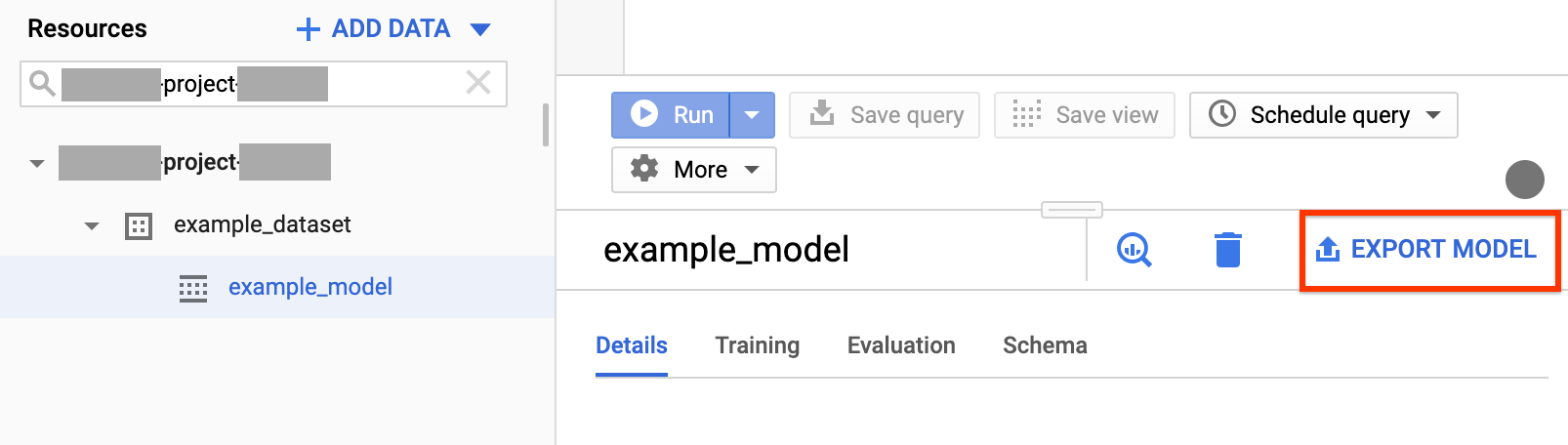
Gehen Sie im Dialogfeld Modell nach Cloud Storage exportieren so vor:
- Ermitteln Sie unter Cloud Storage-Speicherort auswählen den Bucket- oder Ordnerstandort, in den Sie das Modell exportieren möchten.
- Klicken Sie auf Exportieren, um das Modell zu exportieren.
Für einen Exportjob können Sie unter Jobverlauf oben in der Navigation den Status des Jobs prüfen.
SQL
Mit der EXPORT MODEL-Anweisung können Sie BigQuery ML-Modelle über die GoogleSQL-Abfragesyntax nach Cloud Storage exportieren.
So exportieren Sie ein BigQuery ML-Modell mithilfe der Anweisung EXPORT MODEL in die Google Cloud -Konsole:
Öffnen Sie in der Google Cloud Console die Seite „BigQuery“.
Klicken Sie auf Neue Abfrage erstellen.
Geben Sie im Feld Abfrageeditor die Anweisung
EXPORT MODELein.Die folgende Abfrage exportiert ein Modell mit dem Namen
myproject.mydataset.mymodelin einen Cloud Storage-Bucket mit URIgs://bucket/path/to/saved_model/.EXPORT MODEL `myproject.mydataset.mymodel` OPTIONS(URI = 'gs://bucket/path/to/saved_model/')
Klicken Sie auf Ausführen. Wenn die Abfrage abgeschlossen ist, wird Folgendes im Bereich Abfrageergebnisse angezeigt:
Successfully exported model.
bq
Führen Sie den Befehl bq extract mit dem Flag --model aus.
(Optional) Geben Sie das Flag --destination_format an und wählen Sie das Format des exportierten Modells aus.
(Optional) Geben Sie das Flag --location an und legen Sie als Wert Ihren Standort fest.
bq --location=location extract \ --destination_format format \ --model project_id:dataset.model \ gs://bucket/model_folder
Dabei gilt:
- location ist der Name Ihres Standorts. Das Flag
--locationist optional. Wenn Sie BigQuery z. B. in der Region Tokio verwenden, können Sie für das Flag den Wertasia-northeast1festlegen. Mit der Datei .bigqueryrc können Sie einen Standardwert für den Standort festlegen. - destination_format ist das Format für das exportierte Modell:
ML_TF_SAVED_MODEL(Standard) oderML_XGBOOST_BOOSTER. - project_id ist die Projekt-ID.
- dataset ist der Name des Quell-Datasets.
- model ist das Modell, das Sie exportieren.
- bucket ist der Name des Cloud Storage-Buckets, in den Sie Daten exportieren. Das BigQuery-Dataset und der Cloud Storage-Bucket müssen sich am selben Standort befinden.
- model_folder ist der Name des Ordners, in den die exportierten Modelldateien geschrieben werden.
Beispiele:
Der folgende Befehl exportiert mydataset.mymodel im SavedModel-Format von TensorFlow in einen Cloud Storage-Bucket mit dem Namen mymodel_folder.
bq extract --model \ 'mydataset.mymodel' \ gs://example-bucket/mymodel_folder
Der Standardwert von destination_format ist ML_TF_SAVED_MODEL.
Der folgende Befehl exportiert mydataset.mymodel im Booster-Format von XGBoost in einen Cloud Storage-Bucket namens mymodel_folder.
bq extract --model \ --destination_format ML_XGBOOST_BOOSTER \ 'mydataset.mytable' \ gs://example-bucket/mymodel_folder
API
Zum Exportieren eines Modells erstellen Sie einen extract-Job und legen dafür die Jobkonfiguration fest.
Optional: Geben Sie im Attribut location im Abschnitt jobReference der Jobressource Ihren Standort an.
Erstellen Sie einen Extrahierungsjob, der auf das BigQuery ML-Modell und auf das Cloud Storage-Ziel verweist.
Geben Sie das Quellmodell mithilfe des Konfigurationsobjekts
sourceModelan, das die Projekt-ID, die Dataset-ID und die Modell-ID enthält.Das Attribut
destination URI(s)muss voll qualifiziert sein und das Format gs://bucket/model_folder haben.Geben Sie das Zielformat an, indem Sie das Attribut
configuration.extract.destinationFormatfestlegen. Wenn Sie beispielsweise ein Boosted Tree-Modell exportieren möchten, legen Sie dieses Attribut auf den WertML_XGBOOST_BOOSTERfest.Rufen Sie zur Prüfung des Jobstatus jobs.get(job_id) mit der ID des Jobs auf, die von der ursprünglichen Anfrage zurückgegeben wurde.
- Wenn
status.state = DONEzurückgegeben wird, wurde der Job erfolgreich abgeschlossen. - Wenn das Attribut
status.errorResultzurückgegeben wird, ist die Anfrage fehlgeschlagen. Das Objekt enthält in diesem Fall Angaben zur Fehlerursache. - Wenn
status.errorResultnicht zurückgegeben wird, wurde der Job erfolgreich abgeschlossen, obwohl einige nicht schwerwiegende Fehler aufgetreten sein können. Nicht schwerwiegende Fehler werden im Attributstatus.errorsdes Objekts für den zurückgegebenen Job aufgeführt.
- Wenn
API-Hinweise:
Als Best Practice generieren Sie eine eindeutige ID und übergeben Sie diese als
jobReference.jobId, wenn Siejobs.insertzum Erstellen eines Ladejobs aufrufen. Diese Vorgehensweise ist weniger anfällig für Netzwerkfehler, da der Client anhand der bekannten Job-ID einen Abruf oder einen neuen Versuch ausführen kann.Das Aufrufen von
jobs.insertfür eine bestimmte Job-ID ist idempotent. Das bedeutet, dass Sie den Aufruf für eine bestimmte Job-ID beliebig oft wiederholen können. Maximal einer dieser Vorgänge wird erfolgreich sein.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Modellbereitstellung
Sie können das exportierte Modell sowohl in Vertex AI als auch lokal bereitstellen. Wenn die TRANSFORM-Klausel des Modells Datumsfunktionen, Datums-/Uhrzeitfunktionen, Uhrzeitfunktionen und Zeitstempelfunktionen enthält, müssen Sie die Bibliothek bigquery-ml-utils im Container verwenden. Davon ausgenommen sind Bereitstellungen über Model Registry, für die keine exportierten Modelle oder Bereitstellungscontainer erforderlich sind.
Vertex AI-Bereitstellung
| Exportmodellformat | Bereitstellung |
|---|---|
| TensorFlow SavedModel (Nicht-AutoML-Modelle) | TensorFlow SavedModel bereitstellen. Sie müssen die SavedModel-Datei mit einer unterstützten Version von TensorFlow erstellen. |
| TensorFlow SavedModel (AutoML-Modelle) | Nicht unterstützt. |
| XGBoost-Booster |
Verwenden Sie eine benutzerdefinierte Vorhersageroutine. Bei XGBoost-Booster-Modellen werden Informationen zur Vor- und Nachverarbeitung in den exportierten Dateien gespeichert. Mit einer benutzerdefinierten Vorhersageroutine können Sie das Modell mit den zusätzlichen exportierten Dateien bereitstellen.
Sie müssen die Modelldateien mit einer unterstützten Version von XGBoost erstellen. |
Lokale Bereitstellung
| Exportmodellformat | Bereitstellung |
|---|---|
| TensorFlow SavedModel (Nicht-AutoML-Modelle) | "SavedModel" ist ein Standardformat, das sich in Tensorflow Serving-Docker-Containern bereitstellen lässt. Sie können auch die lokale Ausführung von Vertex AI-Onlinevorhersagen nutzen. |
| TensorFlow SavedModel (AutoML-Modelle) | Modell containerisieren und ausführen. |
| XGBoost-Booster | Zum lokalen Ausführen von XGBoost-Booster-Modellen können Sie die exportierte main.py-Datei verwenden:
|
Ausgabeformat der Vorhersage
In diesem Abschnitt wird das Ausgabeformat für die Vorhersage der exportierten Modelle für jeden Modelltyp dargestellt. Alle exportierten Modelle unterstützen Batchvorhersagen und können mehrere Eingabezeilen gleichzeitig verarbeiten. Beispielsweise gibt es in jedem der folgenden Beispiele für die Ausgabeformate zwei Eingabezeilen.
AUTOENCODER
| Ausgabeformat der Vorhersage | Ausgabebeispiel |
|---|---|
+------------------------+------------------------+------------------------+
| LATENT_COL_1 | LATENT_COL_2 | ... |
+------------------------+------------------------+------------------------+
| [FLOAT] | [FLOAT] | ... |
+------------------------+------------------------+------------------------+
|
+------------------+------------------+------------------+------------------+
| LATENT_COL_1 | LATENT_COL_2 | LATENT_COL_3 | LATENT_COL_4 |
+------------------------+------------+------------------+------------------+
| 0.21384512 | 0.93457112 | 0.64978097 | 0.00480489 |
+------------------+------------------+------------------+------------------+
|
AUTOML_CLASSIFIER
| Ausgabeformat der Vorhersage | Ausgabebeispiel |
|---|---|
+------------------------------------------+
| predictions |
+------------------------------------------+
| [{"scores":[FLOAT], "classes":[STRING]}] |
+------------------------------------------+
|
+---------------------------------------------+
| predictions |
+---------------------------------------------+
| [{"scores":[1, 2], "classes":['a', 'b']}, |
| {"scores":[3, 0.2], "classes":['a', 'b']}] |
+---------------------------------------------+
|
AUTOML_REGRESSOR
| Ausgabeformat der Vorhersage | Ausgabebeispiel |
|---|---|
+-----------------+
| predictions |
+-----------------+
| [FLOAT] |
+-----------------+
|
+-----------------+
| predictions |
+-----------------+
| [1.8, 2.46] |
+-----------------+
|
BOOSTED_TREE_CLASSIFIER und RANDOM_FOREST_CLASSIFIER
| Ausgabeformat der Vorhersage | Ausgabebeispiel |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
BOOSTED_TREE_REGRESSOR UND RANDOM_FOREST_REGRESSOR
| Ausgabeformat der Vorhersage | Ausgabebeispiel |
|---|---|
+-----------------+
| predicted_label |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| predicted_label |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_CLASSIFIER
| Ausgabeformat der Vorhersage | Ausgabebeispiel |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_REGRESSOR
| Ausgabeformat der Vorhersage | Ausgabebeispiel |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_LINEAR_COMBINED_CLASSIFIER
| Ausgabeformat der Vorhersage | Ausgabebeispiel |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_LINEAR_COMBINED_REGRESSOR
| Ausgabeformat der Vorhersage | Ausgabebeispiel |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
KMEANS
| Ausgabeformat der Vorhersage | Ausgabebeispiel |
|---|---|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [FLOAT] | [INT64] | INT64 |
+--------------------+--------------+---------------------+
|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [1.2, 1.3] | [1, 2] | [1] |
+--------------------+--------------+---------------------+
| [0.4, 0.1] | [1, 2] | [2] |
+--------------------+--------------+---------------------+
|
LINEAR_REG
| Ausgabeformat der Vorhersage | Ausgabebeispiel |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
LOGISTIC_REG
| Ausgabeformat der Vorhersage | Ausgabebeispiel |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
MATRIX_FACTORIZATION
Hinweis: Derzeit wird nur ein Eingabenutzer unterstützt und die 50 besten Paare (predicted_rating, predicted_item) werden nach predicted_rating in absteigender Reihenfolge sortiert ausgegeben.
| Ausgabeformat der Vorhersage | Ausgabebeispiel |
|---|---|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [FLOAT] | [STRING] |
+------------------+----------------+
|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [5.5, 1.7] | ['A', 'B'] |
+------------------+----------------+
| [7.2, 2.7] | ['B', 'A'] |
+------------------+----------------+
|
TENSORFLOW (importiert)
| Ausgabeformat der Vorhersage |
|---|
| Entspricht dem importierten Modell |
PCA
| Ausgabeformat der Vorhersage | Ausgabebeispiel |
|---|---|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [INT64] | [FLOAT] |
+-------------------------+---------------------------------+
|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [1, 2] | [1.2, 5.0] |
+-------------------------+---------------------------------+
|
TRANSFORM_ONLY
| Ausgabeformat der Vorhersage |
|---|
Entspricht den Spalten, die in der TRANSFORM-Anweisung des Modells angegeben sind
|
XGBoost-Modellvisualisierung
Sie können die hochgeladenen Boosted Trees nach dem Modellexport mit der Python API plot_tree visualisieren. Beispielsweise können Sie Colab nutzen, ohne die Abhängigkeiten zu installieren:
- Exportieren Sie das Boosted Tree-Modell in einen Cloud Storage-Bucket.
- Laden Sie die Datei
model.bstaus dem Cloud Storage-Bucket herunter. - Laden Sie die Datei
model.bstin ein Colab-Notebook inFileshoch. Führen Sie den folgenden Code im Notebook aus:
import xgboost as xgb import matplotlib.pyplot as plt model = xgb.Booster(model_file="model.bst") num_iterations = <iteration_number> for tree_num in range(num_iterations): xgb.plot_tree(model, num_trees=tree_num) plt.show
In diesem Beispiel werden mehrere Bäume dargestellt (ein Baum pro Iteration):
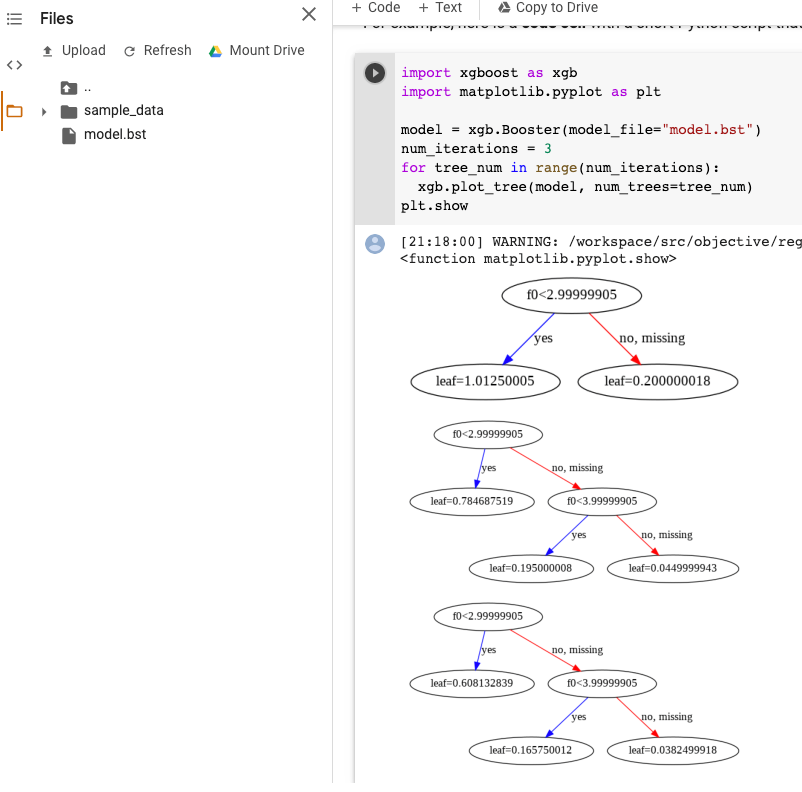
Derzeit speichern wir keine Featurenamen im Modell, sodass Sie Namen wie "f0", "f1" usw. sehen. Die entsprechenden Featurenamen finden Sie in der exportierten Datei assets/model_metadata.json mithilfe dieser Namen (z. B. "f0") als Indexe.
Erforderliche Berechtigungen
Zum Exportieren eines BigQuery ML-Modells nach Cloud Storage benötigen Sie Berechtigungen für den Zugriff auf das BigQuery ML-Modell, für das Ausführen eines Exportjobs und für das Schreiben der Daten in den Cloud Storage-Bucket.
BigQuery-Berechtigungen
Zum Exportieren des Modells sind mindestens Berechtigungen vom Typ
bigquery.models.exporterforderlich. Die folgenden vordefinierten IAM-Rollen (Identity and Access Management) enthalten Berechtigungen vom Typbigquery.models.export:bigquery.dataViewerbigquery.dataOwnerbigquery.dataEditorbigquery.admin
Zum Ausführen eines Exportjobs benötigen Sie Berechtigungen vom Typ
bigquery.jobs.create. Die folgenden vordefinierten IAM-Rollen enthalten Berechtigungen vom Typbigquery.jobs.create:bigquery.userbigquery.jobUserbigquery.admin
Cloud Storage-Berechtigungen
Zum Schreiben von Daten in einen vorhandenen Cloud Storage-Bucket benötigen Sie Berechtigungen vom Typ
storage.objects.create. Die folgenden vordefinierten IAM-Rollen enthalten Berechtigungen vom Typstorage.objects.create:storage.objectCreatorstorage.objectAdminstorage.admin
Unter Zugriffssteuerung erfahren Sie mehr über IAM-Rollen und -Berechtigungen in BigQuery ML.
BigQuery-Daten zwischen Standorten verschieben
Der Standort eines Datasets lässt sich nach seiner Erstellung nicht mehr ändern. Sie können aber eine Kopie des Datasets anlegen.
Kontingentrichtlinie
Weitere Informationen zum Exportieren von Jobkontingenten finden Sie auf der Seite "Kontingente und Limits" unter Exportjobs.
Preise
Für das Exportieren von BigQuery ML-Modellen fallen keine Kosten an. Exporte unterliegen aber den Kontingenten und Limits von BigQuery. Weitere Informationen zu den Preisen von BigQuery finden Sie auf der Seite BigQuery-Preise.
Nachdem die Daten exportiert wurden, wird das Speichern der Daten in Cloud Storage in Rechnung gestellt. Weitere Informationen zu den Preisen von Cloud Storage erhalten Sie auf der Seite Cloud Storage – Preise.