Exporter des modèles
Cette page explique comment exporter des modèles BigQuery ML. Vous pouvez exporter des modèles BigQuery ML vers Cloud Storage et les utiliser pour la prédiction en ligne, ou les modifier en langage Python. Vous pouvez exporter un modèle BigQuery ML à l'aide des méthodes suivantes :
- Utiliser la consoleGoogle Cloud .
- Utiliser l'instruction
EXPORT MODEL. - En utilisant la commande
bq extractde l'outil de ligne de commande bq. - En envoyant une tâche
extractvia l'API ou les bibliothèques clientes
Vous pouvez exporter les types de modèles suivants :
AUTOENCODERAUTOML_CLASSIFIERAUTOML_REGRESSORBOOSTED_TREE_CLASSIFIERBOOSTED_TREE_REGRESSORDNN_CLASSIFIERDNN_REGRESSORDNN_LINEAR_COMBINED_CLASSIFIERDNN_LINEAR_COMBINED_REGRESSORKMEANSLINEAR_REGLOGISTIC_REGMATRIX_FACTORIZATIONRANDOM_FOREST_CLASSIFIERRANDOM_FOREST_REGRESSORTENSORFLOW(modèles TensorFlow importés)PCATRANSFORM_ONLY
Formats et exemples de modèles d'exportation
Le tableau suivant présente les formats de destination des exportations pour chaque type de modèle BigQuery ML et fournit un exemple des fichiers écrits dans le bucket Cloud Storage.
| Type de modèle | Format du modèle d'exportation | Exemple de fichiers exportés |
|---|---|---|
| AUTOML_CLASSIFIER | TensorFlow SavedModel (version 2.1.0) | gcs_bucket/
|
| AUTOML_REGRESSOR | ||
| AUTOENCODER | TensorFlow SavedModel (version TF 1.15 ou ultérieure) | |
| DNN_CLASSIFIER | ||
| DNN_REGRESSOR | ||
| DNN_LINEAR_COMBINED_CLASSIFIER | ||
| DNN_LINEAR_COMBINED_REGRESSOR | ||
| KMEANS | ||
| LINEAR_REGRESSOR | ||
| LOGISTIC_REG | ||
| MATRIX_FACTORIZATION | ||
| ACP | ||
| TRANSFORM_ONLY | ||
| BOOSTED_TREE_CLASSIFIER | Booster (XGBoost 0,82) | gcs_bucket/
main.py est destiné à une exécution locale. Pour en savoir plus, consultez la section Déploiement du modèle.
|
| BOOSTED_TREE_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| TENSORFLOW (importé) | Modèle SavedModel TensorFlow | Exactement les mêmes fichiers que lors de l'importation du modèle |
Exporter un modèle entraîné avec TRANSFORM
Si le modèle est entraîné avec la clause TRANSFORM, un modèle de prétraitement supplémentaire utilise la même logique dans la clause TRANSFORM et est enregistré au format TensorFlow SavedModel dans le sous-répertoire transform.
Vous pouvez déployer un modèle entraîné avec la clause TRANSFORM sur Vertex AI ainsi qu'en local. Pour en savoir plus, consultez la section Déploiement de modèle.
| Format du modèle d'exportation | Exemple de fichiers exportés |
|---|---|
|
Modèle de prédiction : TensorFlow SavedModel ou Booster (XGBoost 0.82).
Modèle de prétraitement pour la clause TRANSFORM : TensorFlow SavedModel (version TF 2.5 ou ultérieure) |
gcs_bucket/
|
Le modèle ne contient pas d'informations sur l'ingénierie des caractéristiques mise en œuvre en dehors de la clause TRANSFORM pendant l'entraînement. Par exemple, tout ce qui est dans l'instruction SELECT. Vous devez donc convertir manuellement les données d'entrée avant de les utiliser dans le modèle de prétraitement.
Types de données acceptés
Lors de l'exportation de modèles entraînés avec la clause TRANSFORM, les types de données suivants sont compatibles pour alimenter la clause TRANSFORM.
| Type d'entrée TRANSFORM | Exemples d'entrées TRANSFORM | Échantillons d'entrée de modèle de prétraitement exportés |
|---|---|---|
| INT64 |
10,
|
tf.constant(
|
| NUMERIC |
NUMERIC 10,
|
tf.constant(
|
| BIGNUMERIC |
BIGNUMERIC 10,
|
tf.constant(
|
| FLOAT64 |
10.0,
|
tf.constant(
|
| BOOL |
TRUE,
|
tf.constant(
|
| STRING |
'abc',
|
tf.constant(
|
| BYTES |
b'abc',
|
tf.constant(
|
| DATE |
DATE '2020-09-27',
|
tf.constant(
|
| DATETIME |
DATETIME '2023-02-02 02:02:01.152903',
|
tf.constant(
|
| TIME |
TIME '16:32:36.152903',
|
tf.constant(
|
| TIMESTAMP |
TIMESTAMP '2017-02-28 12:30:30.45-08',
|
tf.constant(
|
| ARRAY |
['a', 'b'],
|
tf.constant(
|
| ARRAY< STRUCT< INT64, FLOAT64>> |
[(1, 1.0), (2, 1.0)],
|
tf.sparse.from_dense(
|
| NULL |
NULL,
|
tf.constant(
|
Fonctions SQL compatibles
Lorsque vous exportez des modèles entraînés avec la clause TRANSFORM, vous pouvez utiliser les fonctions SQL suivantes dans la clause TRANSFORM.
- Opérateurs
+,-,*,/,=,<,>,<=,>=,!=,<>,[NOT] BETWEEN,[NOT] IN,IS [NOT] NULL,IS [NOT] TRUE,IS [NOT] FALSE,NOT,AND,OR.
- Expressions conditionnelles
CASE expr,CASE,COALESCE,IF,IFNULL,NULLIF.
- Fonctions mathématiques
ABS,ACOS,ACOSH,ASINH,ATAN,ATAN2,ATANH,CBRT,CEIL,CEILING,COS,COSH,COT,COTH,CSC,CSCH,EXP,FLOOR,IS_INF,IS_NAN,LN,LOG,LOG10,MOD,POW,POWER,SEC,SECH,SIGN,SIN,SINH,SQRT,TAN,TANH.
- Fonctions de conversion
CAST AS INT64,CAST AS FLOAT64,CAST AS NUMERIC,CAST AS BIGNUMERIC,CAST AS STRING,SAFE_CAST AS INT64,SAFE_CAST AS FLOAT64
- Fonctions de chaîne
CONCAT,LEFT,LENGTH,LOWER,REGEXP_REPLACE,RIGHT,SPLIT,SUBSTR,SUBSTRING,TRIM,UPPER.
- Fonctions de date
Date,DATE_ADD,DATE_SUB,DATE_DIFF,DATE_TRUNC,EXTRACT,FORMAT_DATE,PARSE_DATE,SAFE.PARSE_DATE.
- Fonctions DATETIME
DATETIME,DATETIME_ADD,DATETIME_SUB,DATETIME_DIFF,DATETIME_TRUNC,EXTRACT,PARSE_DATETIME,SAFE.PARSE_DATETIME.
- Fonctions TIME
TIME,TIME_ADD,TIME_SUB,TIME_DIFF,TIME_TRUNC,EXTRACT,FORMAT_TIME,PARSE_TIME,SAFE.PARSE_TIME.
- Fonctions TIMESTAMP
TIMESTAMP,TIMESTAMP_ADD,TIMESTAMP_SUB,TIMESTAMP_DIFF,TIMESTAMP_TRUNC,FORMAT_TIMESTAMP,PARSE_TIMESTAMP,SAFE.PARSE_TIMESTAMP,TIMESTAMP_MICROS,TIMESTAMP_MILLIS,TIMESTAMP_SECONDS,EXTRACT,STRING,UNIX_MICROS,UNIX_MILLIS,UNIX_SECONDS.
- Fonctions de prétraitement manuel
ML.IMPUTER,ML.HASH_BUCKETIZE,ML.LABEL_ENCODER,ML.MULTI_HOT_ENCODER,ML.NGRAMS,ML.ONE_HOT_ENCODER,ML.BUCKETIZE,ML.MAX_ABS_SCALER,ML.MIN_MAX_SCALER,ML.NORMALIZER,ML.QUANTILE_BUCKETIZE,ML.ROBUST_SCALER,ML.STANDARD_SCALER.
Limites
Les limites suivantes s'appliquent lors de l'exportation de modèles :
L'exportation du modèle n'est pas possible si l'une des caractéristiques suivantes a été utilisée pendant l'entraînement :
- Les types caractéristiques
ARRAY,TIMESTAMPouGEOGRAPHYétaient présents dans les données d'entrée.
- Les types caractéristiques
Les modèles exportés pour les types de modèle
AUTOML_REGRESSORetAUTOML_CLASSIFIERne sont pas compatibles avec le déploiement de Vertex AI pour la prédiction en ligne.Pour l'exportation du modèle de factorisation matricielle, la taille du modèle est limitée à 1 Go. La taille du modèle est approximativement proportionnelle à
num_factors. Si la limite est atteinte, vous pouvez donc réduire la valeur denum_factorspendant l'entraînement de façon à réduire la taille du modèle.Pour les modèles entraînés avec la clause
TRANSFORMBigQuery ML pour le prétraitement manuel des caractéristiques, consultez les types de données et fonctions compatibles avec l'exportation.Les modèles entraînés avec la clause BigQuery ML
TRANSFORMavant le 18 septembre 2023 doivent être réentraînés pour pouvoir être déployés via Model Registry pour la prédiction en ligne.Lors de l'exportation du modèle,
ARRAY<STRUCT<INT64, FLOAT64>>,ARRAYetTIMESTAMPsont acceptés en tant que données prétransformées, mais pas en tant que données post-transformées.
Exporter des modèles BigQuery ML
Pour exporter un modèle, procédez comme suit :
Console
Ouvrez la page BigQuery dans la console Google Cloud .
Dans la section Ressources du panneau de navigation, développez votre projet et cliquez sur un ensemble de données pour le développer. Recherchez et cliquez sur le modèle que vous exportez.
Dans la fenêtre, à droite, cliquez sur Export Model (Exporter le modèle).
Dans la boîte de dialogue Exporter le modèle vers Cloud Storage, procédez comme suit :
- Dans le champ Sélectionner l'emplacement Cloud Storage, recherchez l'emplacement du bucket ou du dossier dans lequel vous souhaitez exporter le modèle.
- Cliquez sur Exporter pour exporter le modèle.
Pour vérifier la progression de la tâche, consultez en haut de la fenêtre de navigation l'historique de la tâche pour une tâche d'exportation.
SQL
L'instruction EXPORT MODEL vous permet d'exporter des modèles BigQuery ML vers Cloud Storage à l'aide de la syntaxe de requête GoogleSQL.
Pour exporter un modèle BigQuery ML dans la console Google Cloud à l'aide de l'instruction EXPORT MODEL, procédez comme suit :
Dans la console Google Cloud , ouvrez la page "BigQuery".
Cliquez sur Saisir une nouvelle requête.
Dans le champ Éditeur de requête, saisissez votre instruction
EXPORT MODEL.La requête suivante permet d'exporter un modèle nommé
myproject.mydataset.mymodelvers un bucket Cloud Storage avec l'URI URIgs://bucket/path/to/saved_model/.EXPORT MODEL `myproject.mydataset.mymodel` OPTIONS(URI = 'gs://bucket/path/to/saved_model/')
Cliquez sur Run (Exécuter). Lorsque la requête est terminée, la ligne suivante apparaît dans le volet Résultats de la requête :
Successfully exported model.
bq
Exécutez la commande bq extract avec l'option --model.
(Facultatif) Spécifiez l'option --destination_format et choisissez le format du modèle exporté.
(Facultatif) Spécifiez l'option --location et définissez la valeur correspondant à votre emplacement.
bq --location=location extract \ --destination_format format \ --model project_id:dataset.model \ gs://bucket/model_folder
Où :
- location est le nom du site. L'option
--locationest facultative. Par exemple, si vous utilisez BigQuery dans la région de Tokyo, vous pouvez définir la valeur de l'option surasia-northeast1. Vous pouvez définir une valeur par défaut correspondant à l'emplacement en utilisant le fichier .bigqueryrc. - destination_format est le format du modèle exporté :
ML_TF_SAVED_MODEL(par défaut) ouML_XGBOOST_BOOSTER. - project_id est l'ID de votre projet.
- dataset est le nom de l'ensemble de données source.
- model est le modèle que vous exportez.
- bucket est le nom du bucket Cloud Storage vers lequel vous exportez les données. L'ensemble de données BigQuery et le bucket Cloud Storage doivent se trouver dans le même emplacement.
- model_folder est le nom du dossier dans lequel les fichiers de modèle exportés seront écrits.
Exemples :
Par exemple, la commande suivante exporte mydataset.mymodel au format TensorFlow SavedModel vers un bucket Cloud Storage nommé mymodel_folder.
bq extract --model \ 'mydataset.mymodel' \ gs://example-bucket/mymodel_folder
La valeur par défaut de destination_format est ML_TF_SAVED_MODEL.
La commande suivante exporte mydataset.mymodel au format Booster XGBoost vers un bucket Cloud Storage nommé mymodel_folder.
bq extract --model \ --destination_format ML_XGBOOST_BOOSTER \ 'mydataset.mytable' \ gs://example-bucket/mymodel_folder
API
Pour exporter le modèle, créez une tâche extract et renseignez la configuration de la tâche.
(Facultatif) Spécifiez votre emplacement dans la propriété location de la section jobReference de la ressource de tâche.
Créez une tâche d'extraction qui pointe vers le modèle BigQuery ML et la destination Cloud Storage.
Spécifiez le modèle source à l'aide de l'objet de configuration
sourceModelqui contient l'ID du projet, l'ID de l'ensemble de données et l'ID du modèle.La propriété
destination URI(s)doit être complète, au format gs://bucket/model_folder.Spécifiez le format de destination en définissant la propriété
configuration.extract.destinationFormat. Par exemple, pour exporter un modèle en arbre de décision à boosting, définissez cette propriété sur la valeurML_XGBOOST_BOOSTER.Pour vérifier l'état de la tâche, appelez jobs.get(job_id) avec l'ID de la tâche renvoyée par la requête initiale.
- Si la réponse est
status.state = DONE, la tâche a bien été exécutée. - Si la propriété
status.errorResultest présente, la requête a échoué. Cet objet inclura des informations décrivant le problème rencontré. - Si la propriété
status.errorResultest absente, la tâche a bien été exécutée. Toutefois, des erreurs non fatales ont pu se produire. La propriétéstatus.errorsde l'objet de la tâche répertorie ces erreurs.
- Si la réponse est
Remarques concernant l'API :
Nous vous recommandons de générer un ID unique et de le transmettre en tant que
jobReference.jobIdlorsque vous appelezjobs.insertpour créer une tâche. Cette approche offre une protection plus robuste contre les pannes réseau, car le client peut lancer une requête ou effectuer de nouvelles tentatives en utilisant l'ID de job connu.L'appel de
jobs.insertavec un ID de tâche donné est idempotent. En d'autres termes, vous pouvez effectuer autant de tentatives que vous le souhaitez avec le même ID de tâche. L'une de ces opérations tout au plus aboutira.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Déploiement du modèle
Vous pouvez déployer le modèle exporté sur Vertex AI ainsi que localement. Si la clause TRANSFORM du modèle contient des fonctions de date, des fonctions de date et heure, des fonctions d'heure ou des fonctions temporelles, vous devez utiliser la bibliothèque bigquery-ml-utils dans le conteneur. La seule exception est si vous effectuez un déploiement via Model Registry, qui ne nécessite pas de modèles exportés ni de conteneurs de diffusion.
Déploiement sur Vertex AI
| Format du modèle d'exportation | Déploiement |
|---|---|
| TensorFlow SavedModel (modèles autres qu'AutoML) | Déployer un modèle SavedModel TensorFlow Vous devez créer le fichier SavedModel à l'aide d'une version compatible de TensorFlow. |
| TensorFlow SavedModel (modèles AutoML) | Non compatible. |
| Booster XGBoost |
Utilisez une routine de prédiction personnalisée. Pour les modèles Booster XGBoost, les informations de prétraitement et de post-traitement sont enregistrées dans les fichiers exportés, et une routine de prédiction personnalisée vous permet de déployer le modèle avec les fichiers exportés supplémentaires.
Vous devez créer les fichiers du modèle à l'aide d'une version compatible de XGBoost. |
Déploiement local
| Format du modèle d'exportation | Déploiement |
|---|---|
| TensorFlow SavedModel (modèles autres qu'AutoML) | Le modèle SavedModel est un format standard que vous pouvez déployer dans le conteneur Docker de Tensorflow Serving. Vous pouvez également exploiter l'exécution locale de la prédiction en ligne Vertex AI. |
| TensorFlow SavedModel (modèles AutoML) | Exécuter le modèle dans des conteneurs |
| Booster XGBoost | Pour exécuter des modèles Booster XGBoost localement, vous pouvez utiliser le fichier main.py exporté :
|
Format de sortie de la prédiction
Cette section fournit le format de sortie de la prédiction pour les modèles exportés et pour chaque type de modèle. Tous les modèles exportés sont compatibles avec la prédiction par lot. Ils peuvent gérer plusieurs lignes d'entrée à la fois. Par exemple, chacun des exemples de formats de sortie suivants contient deux lignes d'entrée.
AUTOENCODER
| Format de sortie de la prédiction | Exemple de sortie |
|---|---|
+------------------------+------------------------+------------------------+
| LATENT_COL_1 | LATENT_COL_2 | ... |
+------------------------+------------------------+------------------------+
| [FLOAT] | [FLOAT] | ... |
+------------------------+------------------------+------------------------+
|
+------------------+------------------+------------------+------------------+
| LATENT_COL_1 | LATENT_COL_2 | LATENT_COL_3 | LATENT_COL_4 |
+------------------------+------------+------------------+------------------+
| 0.21384512 | 0.93457112 | 0.64978097 | 0.00480489 |
+------------------+------------------+------------------+------------------+
|
AUTOML_CLASSIFIER
| Format de sortie de la prédiction | Exemple de sortie |
|---|---|
+------------------------------------------+
| predictions |
+------------------------------------------+
| [{"scores":[FLOAT], "classes":[STRING]}] |
+------------------------------------------+
|
+---------------------------------------------+
| predictions |
+---------------------------------------------+
| [{"scores":[1, 2], "classes":['a', 'b']}, |
| {"scores":[3, 0.2], "classes":['a', 'b']}] |
+---------------------------------------------+
|
AUTOML_REGRESSOR
| Format de sortie de la prédiction | Exemple de sortie |
|---|---|
+-----------------+
| predictions |
+-----------------+
| [FLOAT] |
+-----------------+
|
+-----------------+
| predictions |
+-----------------+
| [1.8, 2.46] |
+-----------------+
|
BOOSTED_TREE_CLASSIFIER et RANDOM_FOREST_CLASSIFIER
| Format de sortie de la prédiction | Exemple de sortie |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
BOOSTED_TREE_REGRESSOR et RANDOM_FOREST_REGRESSOR
| Format de sortie de la prédiction | Exemple de sortie |
|---|---|
+-----------------+
| predicted_label |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| predicted_label |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_CLASSIFIER
| Format de sortie de la prédiction | Exemple de sortie |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_REGRESSOR
| Format de sortie de la prédiction | Exemple de sortie |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_LINEAR_COMBINED_CLASSIFIER
| Format de sortie de la prédiction | Exemple de sortie |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_LINEAR_COMBINED_REGRESSOR
| Format de sortie de la prédiction | Exemple de sortie |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
KMEANS
| Format de sortie de la prédiction | Exemple de sortie |
|---|---|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [FLOAT] | [INT64] | INT64 |
+--------------------+--------------+---------------------+
|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [1.2, 1.3] | [1, 2] | [1] |
+--------------------+--------------+---------------------+
| [0.4, 0.1] | [1, 2] | [2] |
+--------------------+--------------+---------------------+
|
LINEAR_REG
| Format de sortie de la prédiction | Exemple de sortie |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
LOGISTIC_REG
| Format de sortie de la prédiction | Exemple de sortie |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
MATRIX_FACTORIZATION
Remarque : Pour le moment, nous n'acceptons que le type utilisateur en entrée et affichons les 50 meilleures paires en sortie (predicted_rating, predicted_item) triées dans l'ordre décroissant de predicted_rating.
| Format de sortie de la prédiction | Exemple de sortie |
|---|---|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [FLOAT] | [STRING] |
+------------------+----------------+
|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [5.5, 1.7] | ['A', 'B'] |
+------------------+----------------+
| [7.2, 2.7] | ['B', 'A'] |
+------------------+----------------+
|
TENSORFLOW (importé)
| Format de sortie de la prédiction |
|---|
| Identique au modèle importé |
ACP
| Format de sortie de la prédiction | Exemple de sortie |
|---|---|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [INT64] | [FLOAT] |
+-------------------------+---------------------------------+
|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [1, 2] | [1.2, 5.0] |
+-------------------------+---------------------------------+
|
TRANSFORM_ONLY
| Format de sortie de la prédiction |
|---|
Identique aux colonnes spécifiées dans la clause TRANSFORM du modèle
|
Visualiser le modèle XGBoost
Vous pouvez visualiser les arbres de décision à boosting à l'aide de l'API Python plot_tree après l'exportation du modèle. Par exemple, vous pouvez exploiter Colab sans installer les dépendances :
- Exportez le modèle d'arbre de décision à boosting vers un bucket Cloud Storage.
- Téléchargez le fichier
model.bstà partir du bucket Cloud Storage. - Dans un notebook Colab, importez le fichier
model.bstdansFiles. Exécutez le code suivant dans le notebook :
import xgboost as xgb import matplotlib.pyplot as plt model = xgb.Booster(model_file="model.bst") num_iterations = <iteration_number> for tree_num in range(num_iterations): xgb.plot_tree(model, num_trees=tree_num) plt.show
Cet exemple représente plusieurs arbres (un par itération) :
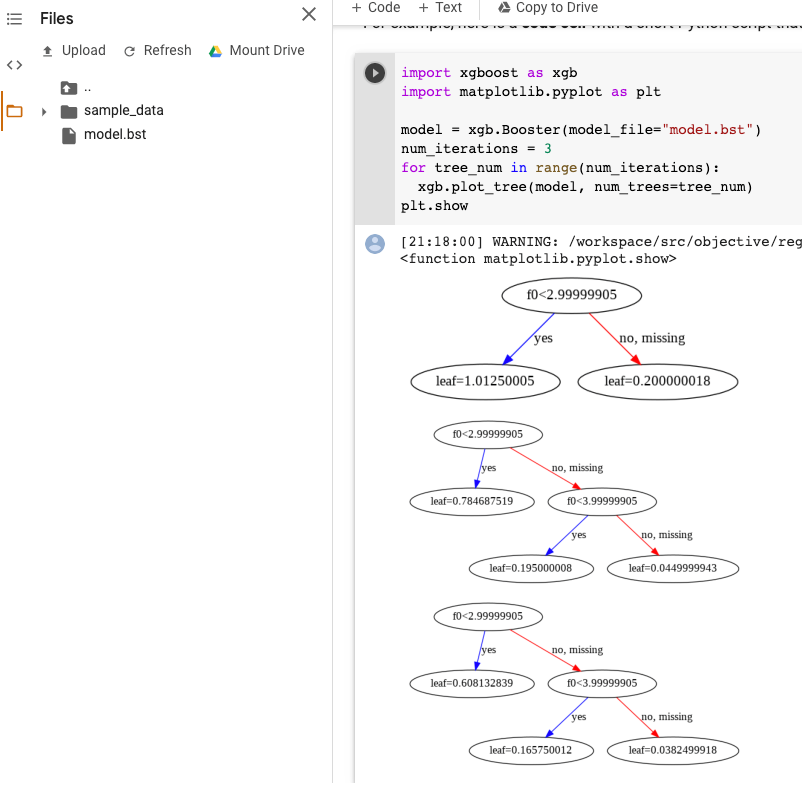
Actuellement, nous n'enregistrons pas les noms de caractéristiques dans le modèle. Vous verrez donc des noms tels que "f0", "f1", etc. Vous pouvez trouver les noms de caractéristiques correspondants dans le fichier exporté assets/model_metadata.json en utilisant ces noms (tels que "f0") comme index.
Autorisations requises
Pour exporter un modèle BigQuery ML vers Cloud Storage, vous devez disposer des autorisations d'accès au modèle BigQuery ML, des autorisations d'exécution d'une tâche d'exportation et des autorisations d'écriture des données dans le bucket Cloud Storage.
Autorisations BigQuery
Pour exporter le modèle, vous devez au minimum disposer des autorisations
bigquery.models.export. Les rôles IAM (Identity and Access Management) prédéfinis suivants disposent des autorisationsbigquery.models.export:bigquery.dataViewerbigquery.dataOwnerbigquery.dataEditorbigquery.admin
Pour exécuter une tâche d'exportation, vous devez au moins disposer des autorisations
bigquery.jobs.create. Les rôles IAM prédéfinis suivants disposent des autorisationsbigquery.jobs.create:bigquery.userbigquery.jobUserbigquery.admin
Autorisations Cloud Storage
Pour écrire les données dans un bucket Cloud Storage existant, vous devez disposer des autorisations
storage.objects.create. Les rôles IAM prédéfinis suivants disposent des autorisationsstorage.objects.create:storage.objectCreatorstorage.objectAdminstorage.admin
Pour en savoir plus sur les rôles et les autorisations IAM dans BigQuery ML, consultez la page Contrôle des accès.
Déplacer des données BigQuery entre des emplacements
Il n'est pas possible de modifier l'emplacement d'un ensemble de données après sa création. Toutefois, vous pouvez effectuer une copie de l'ensemble de données.
Règles de quotas
Pour en savoir plus sur les quotas appliqués aux tâches d'exportation, consultez la section Tâches d'exportation de la page "Quotas et limites".
Tarifs
L'exportation de modèles BigQuery ML est gratuite, mais les exportations sont soumises aux quotas et limites de BigQuery. Pour en savoir plus sur les tarifs de BigQuery, consultez la page Tarifs.
Une fois les données exportées, leur stockage dans Cloud Storage vous est facturé. Pour en savoir plus sur les tarifs de Cloud Storage, reportez-vous à la page Tarifs.
Étapes suivantes
- Suivez le tutoriel Exporter un modèle BigQuery ML pour la prédiction en ligne.