Exportar modelos
En esta página, se muestra cómo exportar modelos de BigQuery ML. Puedes exportar modelos de BigQuery ML a Cloud Storage y usarlos para la predicción en línea o editarlos en Python. Puedes exportar un modelo de BigQuery ML mediante lo siguiente:
- Usa la consola deGoogle Cloud .
- Mediante la sentencia
EXPORT MODEL. - Usa el comando
bq extracten la herramienta de línea de comandos de bq. - Usa el envío de un trabajo
extracta través de la API o las bibliotecas cliente
Puedes exportar los siguientes tipos de modelos:
AUTOENCODERAUTOML_CLASSIFIERAUTOML_REGRESSORBOOSTED_TREE_CLASSIFIERBOOSTED_TREE_REGRESSORDNN_CLASSIFIERDNN_REGRESSORDNN_LINEAR_COMBINED_CLASSIFIERDNN_LINEAR_COMBINED_REGRESSORKMEANSLINEAR_REGLOGISTIC_REGMATRIX_FACTORIZATIONRANDOM_FOREST_CLASSIFIERRANDOM_FOREST_REGRESSORTENSORFLOW(modelos importados de TensorFlow)PCATRANSFORM_ONLY
Exporta muestras y formatos de modelos
En la siguiente tabla, se muestran los formatos de destino de exportación de cada tipo de modelo de BigQuery ML y se proporciona una muestra de archivos que se escriben en el bucket de Cloud Storage.
| Tipo de modelo | Formato del modelo de exportación | Archivos exportados de muestra |
|---|---|---|
| AUTOML_CLASSIFIER | Modelo guardado de TensorFlow (TF 2.1.0) | gcs_bucket/
|
| AUTOML_REGRESSOR | ||
| CODIFICADOR AUTOMÁTICO | Modelo guardado de TensorFlow (TF 1.15 o posterior) | |
| DNN_CLASSIFIER | ||
| DNN_REGRESSOR | ||
| DNN_LINEAR_COMBINED_CLASSIFIER | ||
| DNN_LINEAR_COMBINED_REGRESSOR | ||
| KMEANS | ||
| LINEAR_REGRESSOR | ||
| LOGISTIC_REG | ||
| MATRIX_FACTORIZATION | ||
| PCA | ||
| TRANSFORM_ONLY | ||
| BOOSTED_TREE_CLASSIFIER | Booster (XGBoost 0.82) | gcs_bucket/
main.py es para la ejecución local. Consulta Implementación de modelos para obtener más detalles.
|
| BOOSTED_TREE_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| TENSORFLOW (importado) | Modelo guardado de TensorFlow | Los mismos archivos que estaban presentes cuando se importó el modelo |
Exporta modelo entrenado con TRANSFORM
Si el modelo está entrenado con la
cláusula TRANSFORM,
un modelo de procesamiento previo adicional ejecuta la misma lógica en la
cláusula TRANSFORM y se guarda en
formato de modelo guardado de TensorFlow en el subdirectorio transform.
Puedes implementar un modelo entrenado con la cláusula TRANSFORM en Vertex AI y de forma local. Para obtener más información, consulta
Implementación de modelos.
| Formato del modelo de exportación | Archivos exportados de muestra |
|---|---|
|
Modelo de predicción: Modelo guardado de TensorFlow o Booster (XGBoost 0.82).
Modelo de procesamiento previo para la cláusula TRANSFORM: modelo guardado de TensorFlow (TF 2.5 o versiones posteriores) |
gcs_bucket/
|
El modelo no contiene la información sobre la ingeniería de funciones
realizada fuera de la cláusula TRANSFORM
durante el entrenamiento. Por ejemplo, cualquier elemento de la declaración SELECT. Por lo tanto,
deberás convertir manualmente los datos de entrada antes de que lo haga el feed al modelo de procesamiento
previo.
Tipos de datos admitidos
Cuando se exportan modelos entrenados con la cláusula TRANSFORM, se admiten los siguientes tipos de datos para realizar el feed en la cláusula TRANSFORM.
| Tipo de entrada TRANSFORM | Muestras de entrada de TRANSFORM | Muestras de entrada del modelo de procesamiento previo exportado |
|---|---|---|
| INT64 |
10,
|
tf.constant(
|
| NUMERIC |
NUMERIC 10,
|
tf.constant(
|
| BIGNUMERIC |
BIGNUMERIC 10,
|
tf.constant(
|
| FLOAT64 |
10.0,
|
tf.constant(
|
| BOOL |
TRUE,
|
tf.constant(
|
| STRING |
'abc',
|
tf.constant(
|
| BYTES |
b'abc',
|
tf.constant(
|
| DATE |
DATE '2020-09-27',
|
tf.constant(
|
| DATETIME |
DATETIME '2023-02-02 02:02:01.152903',
|
tf.constant(
|
| TIME |
TIME '16:32:36.152903',
|
tf.constant(
|
| TIMESTAMP |
TIMESTAMP '2017-02-28 12:30:30.45-08',
|
tf.constant(
|
| ARRAY |
['a', 'b'],
|
tf.constant(
|
| ARRAY< STRUCT< INT64, FLOAT64>> |
[(1, 1.0), (2, 1.0)],
|
tf.sparse.from_dense(
|
| NULL |
NULL,
|
tf.constant(
|
Funciones de SQL compatibles
Cuando exportas modelos entrenados con la cláusula TRANSFORM, puedes usar las siguientes funciones de SQL dentro de la cláusula TRANSFORM.
- Operadores
+,-,*,/,=,<,>,<=,>=,!=,<>,[NOT] BETWEEN,[NOT] IN,IS [NOT] NULL,IS [NOT] TRUE,IS [NOT] FALSE,NOT,AND,OR.
- Expresiones condicionales
CASE expr,CASE,COALESCE,IF,IFNULL,NULLIF.
- Funciones matemáticas
ABS,ACOS,ACOSH,ASINH,ATAN,ATAN2,ATANH,CBRT,CEIL,CEILING,COS,COSH,COT,COTH,CSC,CSCH,EXP,FLOOR,IS_INF,IS_NAN,LN,LOG,LOG10,MOD,POW,POWER,SEC,SECH,SIGN,SIN,SINH,SQRT,TAN,TANH.
- Funciones de conversión
CAST AS INT64,CAST AS FLOAT64,CAST AS NUMERIC,CAST AS BIGNUMERIC,CAST AS STRING,SAFE_CAST AS INT64,SAFE_CAST AS FLOAT64
- Funciones de string
CONCAT,LEFT,LENGTH,LOWER,REGEXP_REPLACE,RIGHT,SPLIT,SUBSTR,SUBSTRING,TRIM,UPPER.
- Funciones de fecha
Date,DATE_ADD,DATE_SUB,DATE_DIFF,DATE_TRUNC,EXTRACT,FORMAT_DATE,PARSE_DATE,SAFE.PARSE_DATE.
- Funciones de fecha y hora
DATETIME,DATETIME_ADD,DATETIME_SUB,DATETIME_DIFF,DATETIME_TRUNC,EXTRACT,PARSE_DATETIME,SAFE.PARSE_DATETIME.
- Funciones de tiempo
TIME,TIME_ADD,TIME_SUB,TIME_DIFF,TIME_TRUNC,EXTRACT,FORMAT_TIME,PARSE_TIME,SAFE.PARSE_TIME.
- Funciones de marca de tiempo
TIMESTAMP,TIMESTAMP_ADD,TIMESTAMP_SUB,TIMESTAMP_DIFF,TIMESTAMP_TRUNC,FORMAT_TIMESTAMP,PARSE_TIMESTAMP,SAFE.PARSE_TIMESTAMP,TIMESTAMP_MICROS,TIMESTAMP_MILLIS,TIMESTAMP_SECONDS,EXTRACT,STRING,UNIX_MICROS,UNIX_MILLIS,UNIX_SECONDS.
- Funciones de procesamiento previo manual
ML.IMPUTER,ML.HASH_BUCKETIZE,ML.LABEL_ENCODER,ML.MULTI_HOT_ENCODER,ML.NGRAMS,ML.ONE_HOT_ENCODER,ML.BUCKETIZE,ML.MAX_ABS_SCALER,ML.MIN_MAX_SCALER,ML.NORMALIZER,ML.QUANTILE_BUCKETIZE,ML.ROBUST_SCALER,ML.STANDARD_SCALER.
Limitaciones
Cuando se exportan modelos, se aplican las siguientes limitaciones:
La exportación de modelos no se admite si se usó alguno de los siguientes atributos durante el entrenamiento:
- Los tipos de funciones
ARRAY,TIMESTAMPoGEOGRAPHYestaban presentes en los datos de entrada.
- Los tipos de funciones
Los modelos exportados para los tipos de modelos
AUTOML_REGRESSORyAUTOML_CLASSIFIERno admiten la implementación de Vertex AI para la predicción en línea.El límite de tamaño del modelo es de 1 GB para la exportación de modelos de factorización de matrices. El tamaño del modelo es aproximadamente proporcional a
num_factors, por lo que puedes reducirnum_factorsdurante el entrenamiento para disminuir el tamaño del modelo si alcanzas el límite.Para modelos entrenados con la cláusula
TRANSFORMde BigQuery ML para el procesamiento previo de los atributos manuales, consulta Tipos de datos y las funciones admitidas para la exportación.Los modelos entrenados con la cláusula
TRANSFORMde BigQuery ML antes del 18 de septiembre de 2023, se deben volver a entrenar antes de que se puedan implementar a través de Model Registry para la predicción en línea.Durante la exportación del modelo,
ARRAY<STRUCT<INT64, FLOAT64>>,ARRAYyTIMESTAMPson compatibles como datos transformados previamente, pero no son compatibles como datos postransformados.
Exporta modelos de BigQuery ML
Para exportar un modelo, haz lo siguiente:
Console
Abre la página de BigQuery en la Google Cloud consola.
En el panel de navegación, en la sección Recursos (Resources), expande tu proyecto y haz clic en un conjunto de datos para expandirlo. Busca el modelo que deseas exportar y haz clic en él.
En el lado derecho de la ventana, haz clic en Export Model (Exportar modelo).
En el diálogo Exportar modelo a Cloud Storage, haz lo siguiente:
- En Elegir ubicación de Cloud Storage, busca la ubicación de la carpeta o el depósito al que deseas exportar el modelo.
- Para exportar el modelo, haz clic en Exportar.
Para verificar el progreso del trabajo, busca en la parte superior de la página el Historial de trabajo para un trabajo de exportación.
SQL
La sentencia EXPORT MODEL te permite exportar modelos de BigQuery ML a Cloud Storage con la sintaxis de consulta de GoogleSQL.
Para exportar un modelo de BigQuery ML en la consola de Google Cloud con la instrucción EXPORT MODEL, sigue estos pasos:
En la consola de Google Cloud , abre la página de BigQuery.
Haz clic en Redactar consulta nueva.
En el campo Editor de consultas, escribe la sentencia
EXPORT MODEL.En la siguiente consulta, se exporta un modelo llamado
myproject.mydataset.mymodela un bucket de Cloud Storage con el URIgs://bucket/path/to/saved_model/.EXPORT MODEL `myproject.mydataset.mymodel` OPTIONS(URI = 'gs://bucket/path/to/saved_model/')
Haz clic en Ejecutar. Cuando se completa la consulta, aparece lo siguiente en el panel Resultados de la consulta:
Successfully exported model.
bq
Usa el comando bq extract con la marca --model.
Proporciona la marca --destination_format y elige el formato del modelo exportado (opcional).
Proporciona la marca --location y establece el valor según la ubicación (opcional).
bq --location=location extract \ --destination_format format \ --model project_id:dataset.model \ gs://bucket/model_folder
Donde:
- location es el nombre de tu ubicación. La marca
--locationes opcional. Por ejemplo, si usas BigQuery en la región de Tokio, puedes establecer el valor de la marca enasia-northeast1. Puedes configurar un valor predeterminado para la ubicación mediante el archivo .bigqueryrc. - destination_format es el formato para el modelo exportado:
ML_TF_SAVED_MODEL(predeterminado) oML_XGBOOST_BOOSTER. - project_id es el ID del proyecto.
- dataset es el nombre del conjunto de datos de origen.
- model es el modelo que exportas.
- bucket es el nombre del depósito de Cloud Storage al que deseas exportar los datos. El conjunto de datos de BigQuery y el depósito de Cloud Storage deben estar en la misma ubicación.
- model_folder es el nombre de la carpeta en la que se escribirán los archivos del modelo que se exportó.
Ejemplos:
Por ejemplo, mediante el siguiente comando, se exporta mydataset.mymodel en formato de modelo guardado de TensorFlow a un depósito de Cloud Storage llamado mymodel_folder.
bq extract --model \ 'mydataset.mymodel' \ gs://example-bucket/mymodel_folder
El valor predeterminado de destination_format es ML_TF_SAVED_MODEL.
El siguiente comando exporta mydataset.mymodel en formato booster de XGBoost a un depósito de Cloud Storage llamado mymodel_folder.
bq extract --model \ --destination_format ML_XGBOOST_BOOSTER \ 'mydataset.mytable' \ gs://example-bucket/mymodel_folder
API
Para exportar el modelo, crea un trabajo extract y propaga la configuración del trabajo.
Especifica tu ubicación en la propiedad location de la sección jobReference del recurso de trabajo (opcional).
Crea un trabajo de extracción que apunte al modelo de BigQuery ML y al destino de Cloud Storage.
Especifica el modelo de origen mediante el objeto de configuración
sourceModelque contiene el ID del proyecto, el ID del conjunto de datos y el ID del modelo.La propiedad
destination URI(s)debe estar completamente calificada en el formato gs://bucket/model_folder.Configura la propiedad
configuration.extract.destinationFormatpara especificar el formato de destino. Por ejemplo, para exportar un modelo de árbol mejorado, establece esta propiedad en el valorML_XGBOOST_BOOSTER.Para verificar el estado del trabajo, llama a jobs.get(job_id) con el ID del trabajo que se muestra en la solicitud inicial.
- Si se muestra
status.state = DONE, el trabajo se completó de forma correcta. - Si la propiedad
status.errorResultestá presente, la solicitud falló y ese objeto incluirá información que describa qué salió mal. - Si
status.errorResultestá ausente, el trabajo finalizó de forma correcta, aunque puede que haya habido algunos errores recuperables. Los errores recuperables se enumeran en la propiedadstatus.errorsdel objeto de trabajo que se muestra.
- Si se muestra
Notas sobre la API:
Se recomienda que generes un ID único y lo pases como
jobReference.jobIdcuando llames ajobs.insertpara crear un trabajo. Este enfoque es más resistente a las fallas de la red porque el cliente puede sondear o reintentar con el ID de trabajo conocido.Llamar a
jobs.insertcon un ID de trabajo determinado es idempotente. En otras palabras, puedes volver a intentarlo tantas veces como desees con el mismo ID de trabajo y, como máximo, solo una de esas operaciones funcionará.
Java
Antes de probar este ejemplo, sigue las instrucciones de configuración para Java incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Java.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Implementación del modelo
Puedes implementar el modelo exportado en Vertex AI y de forma local. Si la
cláusula TRANSFORM del modelo contiene funciones
de fecha, funciones de fecha y hora, funciones de hora o funciones de marca de tiempo, debes
usar la biblioteca bigquery-ml-utils
en el contenedor. La excepción es si implementas a través de Model Registry,
que no necesita modelos exportados ni contenedores de entrega.
Implementación de Vertex AI
| Formato del modelo de exportación | Implementación |
|---|---|
| Modelo guardado de Tensorflow (modelos que no son de AutoML) | Implementa un modelo guardado de TensorFlow. Debes crear el archivo del modelo guardado con una versión compatible de TensorFlow. |
| Modelo guardado de Tensorflow (modelos de AutoML) | No compatible. |
| Booster de XGBoost |
Usa una rutina de predicción personalizada. En el caso de los modelos de XGBoost Booster, la información de procesamiento previo y posterior se guarda en los archivos exportados, y una rutina de predicción personalizada te permite implementar el modelo con los archivos exportados adicionales.
Debes crear los archivos del modelo con una versión compatible de XGBoost. |
Implementación local
| Formato del modelo de exportación | Implementación |
|---|---|
| Modelo guardado de Tensorflow (modelos que no son de AutoML) | El modelo guardado es un formato estándar y puedes implementarlo en el contenedor de Docker de Tensorflow Serving. También puedes aprovechar la ejecución local de la predicción en línea de Vertex AI. |
| Modelo guardado de Tensorflow (modelos de AutoML) | Organiza el modelo en contenedores y ejecútalo. |
| Booster de XGBoost | Para ejecutar modelos booster de XGBoost de manera local, puedes usar el archivo main.py exportado:
|
Formato del resultado de la predicción
En esta sección, se proporciona el formato del resultado de la predicción de los modelos exportados para cada tipo de modelo. Todos los modelos exportados admiten la predicción por lotes, ya que pueden administrar varias filas de entrada a la vez. Por ejemplo, hay dos filas de entrada en cada uno de los siguientes ejemplos de formato de resultados.
CODIFICADOR AUTOMÁTICO
| Formato del resultado de la predicción | Ejemplo de resultado |
|---|---|
+------------------------+------------------------+------------------------+
| LATENT_COL_1 | LATENT_COL_2 | ... |
+------------------------+------------------------+------------------------+
| [FLOAT] | [FLOAT] | ... |
+------------------------+------------------------+------------------------+
|
+------------------+------------------+------------------+------------------+
| LATENT_COL_1 | LATENT_COL_2 | LATENT_COL_3 | LATENT_COL_4 |
+------------------------+------------+------------------+------------------+
| 0.21384512 | 0.93457112 | 0.64978097 | 0.00480489 |
+------------------+------------------+------------------+------------------+
|
AUTOML_CLASSIFIER
| Formato del resultado de la predicción | Ejemplo de resultado |
|---|---|
+------------------------------------------+
| predictions |
+------------------------------------------+
| [{"scores":[FLOAT], "classes":[STRING]}] |
+------------------------------------------+
|
+---------------------------------------------+
| predictions |
+---------------------------------------------+
| [{"scores":[1, 2], "classes":['a', 'b']}, |
| {"scores":[3, 0.2], "classes":['a', 'b']}] |
+---------------------------------------------+
|
AUTOML_REGRESSOR
| Formato del resultado de la predicción | Ejemplo de resultado |
|---|---|
+-----------------+
| predictions |
+-----------------+
| [FLOAT] |
+-----------------+
|
+-----------------+
| predictions |
+-----------------+
| [1.8, 2.46] |
+-----------------+
|
BOOSTED_TREE_CLASSIFIER y RANDOM_FOREST_CLASSIFIER
| Formato del resultado de la predicción | Ejemplo de resultado |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
BOOSTED_TREE_REGRESSOR Y RANDOM_FOREST_REGRESSOR
| Formato del resultado de la predicción | Ejemplo de resultado |
|---|---|
+-----------------+
| predicted_label |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| predicted_label |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_CLASSIFIER
| Formato del resultado de la predicción | Ejemplo de resultado |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_REGRESSOR
| Formato del resultado de la predicción | Ejemplo de resultado |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_LINEAR_COMBINED_CLASSIFIER
| Formato del resultado de la predicción | Ejemplo de resultado |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_LINEAR_COMBINED_REGRESSOR
| Formato del resultado de la predicción | Ejemplo de resultado |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
KMEANS
| Formato del resultado de la predicción | Ejemplo de resultado |
|---|---|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [FLOAT] | [INT64] | INT64 |
+--------------------+--------------+---------------------+
|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [1.2, 1.3] | [1, 2] | [1] |
+--------------------+--------------+---------------------+
| [0.4, 0.1] | [1, 2] | [2] |
+--------------------+--------------+---------------------+
|
LINEAR_REG
| Formato del resultado de la predicción | Ejemplo de resultado |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
LOGISTIC_REG
| Formato del resultado de la predicción | Ejemplo de resultado |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
MATRIX_FACTORIZATION
Nota: Por el momento, solo admitimos un usuario de entrada y los primeros 50 pares de resultado (predicted_rating, predicted_item) ordenados por predicted_rating de forma descendente.
| Formato del resultado de la predicción | Ejemplo de resultado |
|---|---|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [FLOAT] | [STRING] |
+------------------+----------------+
|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [5.5, 1.7] | ['A', 'B'] |
+------------------+----------------+
| [7.2, 2.7] | ['B', 'A'] |
+------------------+----------------+
|
TENSORFLOW (importado)
| Formato del resultado de la predicción |
|---|
| El mismo que el del modelo importado |
PCA
| Formato del resultado de la predicción | Ejemplo de resultado |
|---|---|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [INT64] | [FLOAT] |
+-------------------------+---------------------------------+
|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [1, 2] | [1.2, 5.0] |
+-------------------------+---------------------------------+
|
TRANSFORM_ONLY
| Formato del resultado de la predicción |
|---|
Igual que las columnas especificadas en la cláusula TRANSFORM del modelo
|
Visualización del modelo XGBoost
Puedes visualizar los árboles mejorados mediante la API de Python plot_tree después de la exportación del modelo. Por ejemplo, puedes aprovechar Colab sin instalar las dependencias:
- Exporta el modelo de árbol mejorado a un bucket de Cloud Storage.
- Descarga el archivo
model.bstdel depósito de Cloud Storage. - En un notebook de Colab, sube el archivo
model.bstaFiles. Ejecuta el siguiente código en el notebook:
import xgboost as xgb import matplotlib.pyplot as plt model = xgb.Booster(model_file="model.bst") num_iterations = <iteration_number> for tree_num in range(num_iterations): xgb.plot_tree(model, num_trees=tree_num) plt.show
En este ejemplo, se trazan varios árboles (un árbol por iteración):
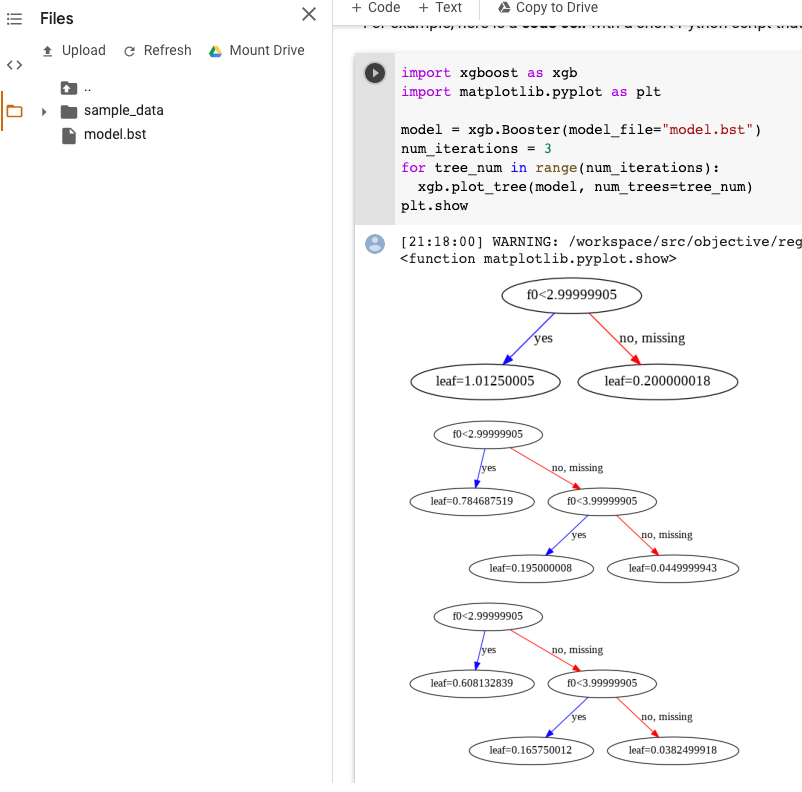
En la actualidad, no guardamos nombres de atributos en el modelo, por lo que verás nombres como “f0”, “f1”, etcétera. Puedes encontrar los nombres de los atributos correspondientes en el archivo exportado assets/model_metadata.json con estos nombres (como “f0”) como índices.
Permisos necesarios
Para exportar un modelo de BigQuery ML a Cloud Storage, necesitas permisos para acceder al modelo de BigQuery ML, ejecutar un trabajo de exportación y escribir los datos en el bucket de Cloud Storage.
Permisos de BigQuery
Para exportar el modelo, debes tener permisos
bigquery.models.exportcomo mínimo. Los siguientes roles predefinidos de Identity and Access Management (IAM) tienen permisosbigquery.models.export:bigquery.dataViewerbigquery.dataOwnerbigquery.dataEditorbigquery.admin
Como mínimo, para ejecutar un trabajo de exportación, debes tener permisos
bigquery.jobs.create. Las siguientes funciones predefinidas de IAM tienen permisosbigquery.jobs.create:bigquery.userbigquery.jobUserbigquery.admin
Permisos de Cloud Storage
Para escribir los datos en un depósito de Cloud Storage existente, debes tener permisos
storage.objects.create. Las siguientes funciones predefinidas de IAM tienen permisosstorage.objects.create:storage.objectCreatorstorage.objectAdminstorage.admin
Para obtener más información sobre los permisos y las funciones de IAM en BigQuery ML, consulta Control de acceso.
Traslada los datos de BigQuery entre ubicaciones
No puedes cambiar la ubicación de un conjunto de datos después de crearlo, pero puedes crear una copia del conjunto de datos.
Política de cuotas
Para obtener información sobre las cuotas de los trabajos de exportación, consulta Trabajos de exportación en la página Cuotas y límites.
Precios
No se aplican cargos por exportar modelos de BigQuery ML, pero las exportaciones están sujetas a las cuotas y los límites de BigQuery. Para obtener más información sobre los precios de BigQuery, consulta la página Precios.
Una vez que se exportan los datos, se te cobra por almacenarlos en Cloud Storage. Para obtener más información, consulta la página Precios de Cloud Storage.
¿Qué sigue?
- Consulta el instructivo Exporta un modelo de BigQuery ML para la predicción en línea.