Créer des ensembles de données
Ce document explique comment créer des ensembles de données dans BigQuery.
Vous pouvez créer des ensembles de données de différentes manières :
- Utiliser la console Google Cloud .
- Utiliser une requête SQL
- Exécuter la commande
bq mkdans l'outil de ligne de commande bq - Appeler la méthode API
datasets.insert - Utiliser les bibliothèques clientes
- Copier un ensemble de données existant
Pour connaître la procédure à suivre pour copier un ensemble de données, y compris entre plusieurs régions, consultez la page Copier des ensembles de données.
Ce document explique comment utiliser les ensembles de données standards qui stockent des données dans BigQuery. Pour savoir comment utiliser les ensembles de données externes Spanner, consultez Créer des ensembles de données externes Spanner. Pour savoir comment utiliser les ensembles de données fédérés AWS Glue, consultez Créer des ensembles de données fédérés AWS Glue.
Pour savoir comment interroger des tables dans un ensemble de données public, consultez Interroger un ensemble de données public avec la console Google Cloud .
Limites des ensembles de données
Les ensembles de données BigQuery sont soumis aux limitations suivantes :
- L'emplacement de l'ensemble de données ne peut être défini qu'au moment de la création. Une fois l'ensemble de données créé, l'emplacement ne peut plus être modifié.
- Toutes les tables référencées dans une requête doivent être stockées dans des ensembles de données situés au même emplacement.
Les ensembles de données externes ne sont pas compatibles avec l'expiration des tables, les répliques, les fonctionnalités temporelles, le classement par défaut, le mode d'arrondi par défaut ni l'option permettant d'activer ou de désactiver les noms de tables insensibles à la casse.
Lorsque vous copiez une table, les ensembles de données contenant la table source et la table de destination doivent se trouver au même emplacement.
Les noms d'ensembles de données doivent être uniques pour chaque projet.
Une fois que vous avez modifié le modèle de facturation du stockage d'un ensemble de données, vous devez attendre 14 jours avant de pouvoir le modifier à nouveau.
Vous ne pouvez pas enregistrer un ensemble de données à la facturation du stockage physique si vous avez d'anciens engagements d'emplacements à tarifs forfaitaires situés dans la même région que cet ensemble de données.
Avant de commencer
Attribuez aux utilisateurs des rôles IAM (Identity and Access Management) incluant les autorisations nécessaires pour effectuer l'ensemble des tâches du présent document.
Autorisations requises
Pour créer un ensemble de données, vous avez besoin de l'autorisation IAM bigquery.datasets.create.
Chacun des rôles IAM prédéfinis suivants inclut les autorisations dont vous avez besoin pour créer un ensemble de données :
roles/bigquery.dataEditorroles/bigquery.dataOwnerroles/bigquery.userroles/bigquery.admin
Pour en savoir plus sur les rôles IAM dans BigQuery, consultez la page Rôles prédéfinis et autorisations.
Créer des ensembles de données
Pour créer un ensemble de données, procédez comme suit :
Console
- Ouvrez la page BigQuery dans la console Google Cloud . Accéder à la page "BigQuery"
- Dans le panneau de gauche, cliquez sur Explorer.
- Sélectionnez le projet dans lequel vous souhaitez créer l'ensemble de données.
- Cliquez sur Afficher les actions, puis sur Créer un ensemble de données.
- Sur la page Créer un ensemble de données, procédez comme suit :
- Pour ID de l'ensemble de données, indiquez le nom d'un ensemble de données unique.
- Dans Type d'emplacement, sélectionnez un emplacement géographique pour l'ensemble de données. Une fois l'ensemble de données créé, l'emplacement ne peut plus être modifié.
- Facultatif : Sélectionnez Associer à un ensemble de données externe si vous créez un ensemble de données externe.
- Si vous n'avez pas besoin de configurer d'autres options, telles que les tags et les dates d'expiration des tables, cliquez sur Créer un ensemble de données. Sinon, développez la section suivante pour configurer les options supplémentaires de l'ensemble de données.
- Facultatif : Développez la section Tags pour ajouter des tags à votre ensemble de données.
- Pour appliquer un tag existant, procédez comme suit :
- Cliquez sur la flèche du menu déroulant à côté de Sélectionner le champ d'application, puis sélectionnez Champ d'application actuel > Sélectionner l'organisation actuelle ou Sélectionner le projet actuel.
- Pour Clé 1 et Valeur 1, choisissez les valeurs appropriées dans les listes.
- Pour saisir manuellement un tag, procédez comme suit :
- Cliquez sur la flèche du menu déroulant à côté de Sélectionner un champ d'application, puis sélectionnez Saisir manuellement les ID > Organisation, Projet ou Tags.
- Si vous créez un tag pour votre projet ou votre organisation, saisissez
PROJECT_IDouORGANIZATION_IDdans la boîte de dialogue, puis cliquez sur Enregistrer. - Pour Clé 1 et Valeur 1, choisissez les valeurs appropriées dans les listes.
- Pour ajouter d'autres tags au tableau, cliquez sur Ajouter un tag et suivez les étapes précédentes.
- Facultatif : Développez la section Options avancées pour configurer une ou plusieurs des options suivantes.
- Pour modifier l'option Chiffrement afin d'utiliser votre propre clé cryptographique avec Cloud Key Management Service, sélectionnez Clé Cloud KMS.
- Pour utiliser des noms de tables non sensibles à la casse, sélectionnez Rendre les noms de tables non sensibles à la casse.
- Pour modifier la spécification de classement par défaut, choisissez le type de classement dans la liste.
- Pour définir une date d'expiration pour les tables de l'ensemble de données, sélectionnez Activer l'expiration de la table, puis spécifiez l'âge maximal par défaut de la table en jours.
- Pour définir un mode d'arrondi par défaut, sélectionnez-le dans la liste.
- Pour activer le modèle de facturation du stockage physique, sélectionnez-le dans la liste.
- Pour définir la fenêtre temporelle de l'ensemble de données, sélectionnez la taille de la fenêtre dans la liste.
- Cliquez sur Créer un ensemble de données.
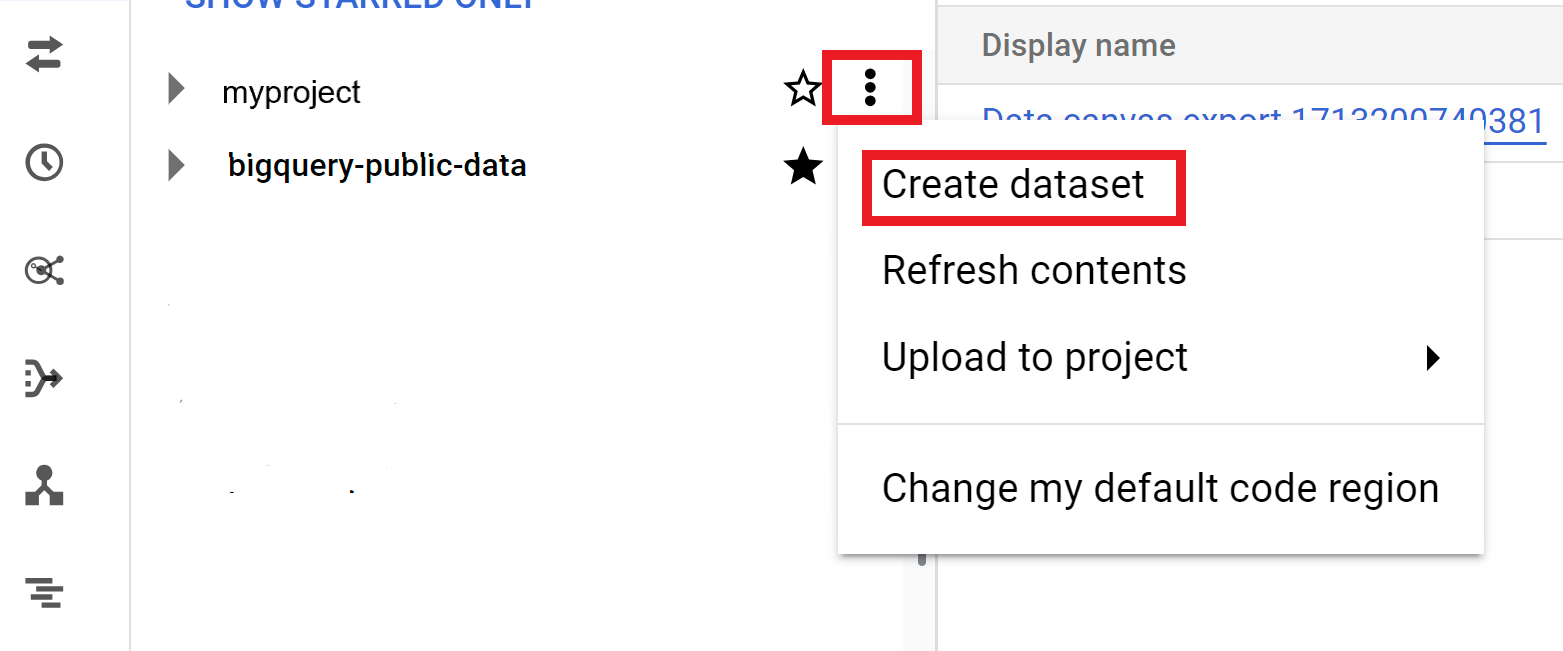
Options supplémentaires pour les ensembles de données
Vous pouvez également cliquer sur Sélectionner le champ d'application pour rechercher une ressource ou afficher la liste des ressources actuelles.
Lorsque vous modifiez le modèle de facturation d'un ensemble de données, la prise en compte de la modification prend 24 heures.
Une fois que vous avez modifié le modèle de facturation du stockage d'un ensemble de données, vous devez attendre 14 jours avant de pouvoir modifier à nouveau le modèle de facturation du stockage.
SQL
Utilisez l'instruction CREATE SCHEMA.
Pour créer un ensemble de données dans un projet autre que votre projet par défaut, ajoutez l'ID du projet à l'ID de l'ensemble de données de la manière suivante : PROJECT_ID.DATASET_ID.
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
CREATE SCHEMA PROJECT_ID.DATASET_ID OPTIONS ( default_kms_key_name = 'KMS_KEY_NAME', default_partition_expiration_days = PARTITION_EXPIRATION, default_table_expiration_days = TABLE_EXPIRATION, description = 'DESCRIPTION', labels = [('KEY_1','VALUE_1'),('KEY_2','VALUE_2')], location = 'LOCATION', max_time_travel_hours = HOURS, storage_billing_model = BILLING_MODEL);
Remplacez les éléments suivants :
PROJECT_ID: ID de votre projet.DATASET_ID: ID de l'ensemble de données que vous créez.KMS_KEY_NAME: nom de la clé Cloud Key Management Service utilisée par défaut pour protéger les tables nouvellement créées dans cet ensemble de données, à moins qu'une clé différente ne soit fournie au moment de la création. Vous ne pouvez pas créer de table chiffrée par Google dans un ensemble de données avec ces paramètres.PARTITION_EXPIRATION: durée de vie par défaut (en jours) des partitions des tables partitionnées nouvellement créées. Aucune valeur minimale n'est imposée pour le délai d'expiration par défaut des partitions. Le délai d'expiration correspond à la date de la partition plus la valeur entière. Toute partition créée dans une table partitionnée de l'ensemble de données est suppriméePARTITION_EXPIRATIONjours après sa partition. Si vous spécifiez l'optiontime_partitioning_expirationlors de la création ou de la mise à jour d'une table partitionnée, le délai d'expiration des partitions défini au niveau de la table est prioritaire sur le délai d'expiration des partitions défini par défaut au niveau de l'ensemble de données.TABLE_EXPIRATION: durée de vie par défaut (en jours) des tables nouvellement créées. La valeur minimale est de 0,042 jour (une heure). Le délai d'expiration correspond à l'heure actuelle plus la valeur entière. Toutes les tables créées dans l'ensemble de données sont suppriméesTABLE_EXPIRATIONjours après leur création. Cette valeur est appliquée si vous ne définissez pas de délai d'expiration lors de la création de la table.DESCRIPTION: description de l'ensemble de donnéesKEY_1:VALUE_1: paire clé-valeur que vous souhaitez définir comme première étiquette sur cet ensemble de donnéesKEY_2:VALUE_2: paire clé-valeur que vous souhaitez définir comme deuxième étiquetteLOCATION: emplacement de l'ensemble de données. Une fois l'ensemble de données créé, l'emplacement ne peut plus être modifié.HOURS: durée en heures de la fenêtre temporelle du nouvel ensemble de données. La valeurHOURSdoit être un entier exprimé par des multiples de 24 (48, 72, 96, 120, 144, 168) entre 48 (2 jours) et 168 (7 jours). 168 heures est la valeur par défaut si cette option n'est pas spécifiée.BILLING_MODEL: définit le modèle de facturation du stockage pour l'ensemble de données. Définissez la valeurBILLING_MODELsurPHYSICALpour utiliser des octets physiques lors du calcul des frais de stockage, ou surLOGICALpour utiliser des octets logiques.LOGICALest la valeur par défaut.Lorsque vous modifiez le modèle de facturation d'un ensemble de données, la prise en compte de la modification prend 24 heures.
Une fois que vous avez modifié le modèle de facturation du stockage d'un ensemble de données, vous devez attendre 14 jours avant de pouvoir modifier à nouveau le modèle de facturation du stockage.
Cliquez sur Exécuter.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
bq
Pour créer un ensemble de données, exécutez la commande bq mk en spécifiant l'option --location. Pour obtenir la liste complète des paramètres possibles, consultez la documentation de référence sur la commande bq mk --dataset.
Pour créer un ensemble de données dans un projet autre que votre projet par défaut, ajoutez l'ID du projet au nom de l'ensemble de données de la manière suivante : PROJECT_ID:DATASET_ID.
bq --location=LOCATION mk \ --dataset \ --default_kms_key=KMS_KEY_NAME \ --default_partition_expiration=PARTITION_EXPIRATION \ --default_table_expiration=TABLE_EXPIRATION \ --description="DESCRIPTION" \ --label=KEY_1:VALUE_1 \ --label=KEY_2:VALUE_2 \ --add_tags=KEY_3:VALUE_3[,...] \ --max_time_travel_hours=HOURS \ --storage_billing_model=BILLING_MODEL \ PROJECT_ID:DATASET_ID
Remplacez les éléments suivants :
LOCATION: emplacement de l'ensemble de données. Une fois l'ensemble de données créé, l'emplacement ne peut plus être modifié. Vous pouvez spécifier une valeur par défaut pour l'emplacement à l'aide du fichier.bigqueryrc.KMS_KEY_NAME: nom de la clé Cloud Key Management Service utilisée par défaut pour protéger les tables nouvellement créées dans cet ensemble de données, à moins qu'une clé différente ne soit fournie au moment de la création. Vous ne pouvez pas créer de table chiffrée par Google dans un ensemble de données avec ces paramètres.PARTITION_EXPIRATION: durée de vie par défaut (en secondes) des partitions des tables partitionnées nouvellement créées. Aucune valeur minimale n'est imposée pour le délai d'expiration par défaut des partitions. Le délai d'expiration correspond à la date de la partition plus la valeur entière. Toute partition créée dans une table partitionnée de l'ensemble de données est suppriméePARTITION_EXPIRATIONsecondes après sa partition. Si vous spécifiez l'option--time_partitioning_expirationlors de la création ou de la mise à jour d'une table partitionnée, le délai d'expiration des partitions défini au niveau de la table est prioritaire sur le délai d'expiration des partitions défini par défaut au niveau de l'ensemble de données.TABLE_EXPIRATION: durée de vie par défaut (en secondes) des tables nouvellement créées. La valeur minimale est de 3 600 secondes (une heure). Le délai d'expiration correspond à l'heure actuelle plus la valeur entière. Toutes les tables créées dans l'ensemble de données sont suppriméesTABLE_EXPIRATIONsecondes après leur création. Cette valeur est appliquée si vous ne définissez pas de délai d'expiration pour la table lors de sa création.DESCRIPTION: description de l'ensemble de donnéesKEY_1:VALUE_1est la paire clé-valeur que vous souhaitez définir en tant que premier libellé de cet ensemble de données, etKEY_2:VALUE_2est la paire clé-valeur que vous souhaitez définir en tant que deuxième libellé.KEY_3:VALUE_3: paire clé-valeur que vous souhaitez définir en tant que tag sur l'ensemble de données. Ajoutez plusieurs tags sous la même option en séparant les paires clé/valeur par des virgules.HOURS: durée en heures de la fenêtre temporelle du nouvel ensemble de données. La valeurHOURSdoit être un entier exprimé par des multiples de 24 (48, 72, 96, 120, 144, 168) entre 48 (2 jours) et 168 (7 jours). 168 heures est la valeur par défaut si cette option n'est pas spécifiée.BILLING_MODEL: définit le modèle de facturation du stockage pour l'ensemble de données. Définissez la valeurBILLING_MODELsurPHYSICALpour utiliser des octets physiques lors du calcul des frais de stockage, ou surLOGICALpour utiliser des octets logiques.LOGICALest la valeur par défaut.Lorsque vous modifiez le modèle de facturation d'un ensemble de données, la prise en compte de la modification prend 24 heures.
Une fois que vous avez modifié le modèle de facturation du stockage d'un ensemble de données, vous devez attendre 14 jours avant de pouvoir modifier à nouveau le modèle de facturation du stockage.
PROJECT_ID: ID de votre projet.DATASET_IDest l'ID de l'ensemble de données que vous créez.
Par exemple, la commande suivante crée un ensemble de données nommé mydataset avec l'emplacement des données défini sur US, une valeur de 3 600 secondes (une heure) pour le délai d'expiration par défaut des tables et la description This is my dataset. Au lieu d'utiliser l'option --dataset, la commande utilise le raccourci -d. Si vous omettez -d et --dataset, la commande crée un ensemble de données par défaut.
bq --location=US mk -d \ --default_table_expiration 3600 \ --description "This is my dataset." \ mydataset
Pour vérifier que l'ensemble de données a bien été créé, saisissez la commande bq ls. Vous pouvez également créer une table lorsque vous créez un ensemble de données. Pour cela, exécutez la commande suivante : bq mk -t dataset.table.
Pour en savoir plus sur la création des tables, consultez la section Créer une table.
Terraform
Utilisez la ressource google_bigquery_dataset.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Créer un ensemble de données
L'exemple suivant crée un ensemble de données nommé mydataset :
Lorsque vous créez un ensemble de données en utilisant la ressource google_bigquery_dataset, l'accès à l'ensemble de données est automatiquement accordé à tous les comptes affiliés aux rôles de base au niveau du projet.
Si vous exécutez la commande terraform show après avoir créé l'ensemble de données, le bloc access pour l'ensemble de données ressemble à l'exemple suivant :
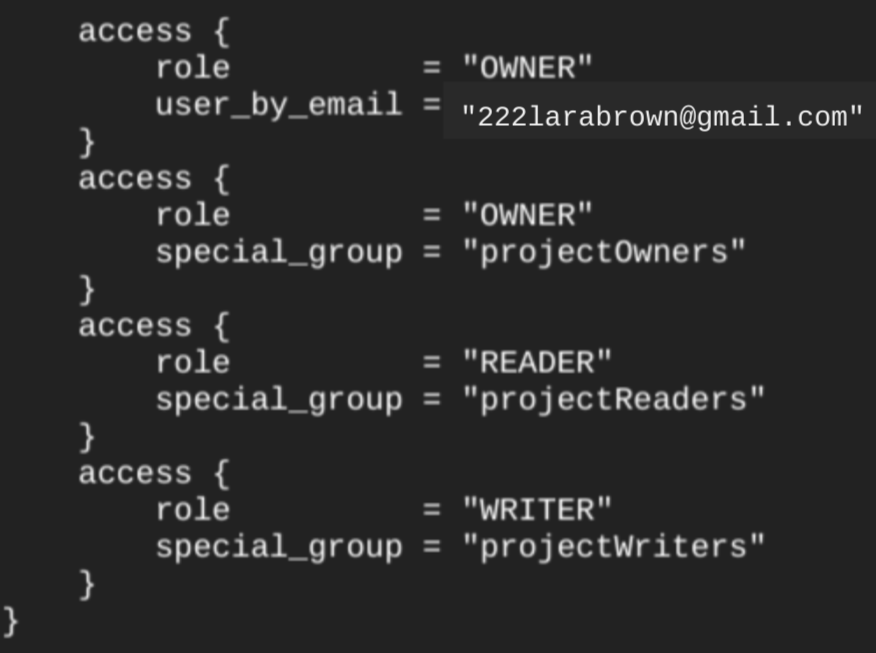
Pour accorder l'accès à l'ensemble de données, nous vous recommandons d'utiliser l'une des ressources google_bigquery_iam, comme indiqué dans l'exemple suivant, sauf si vous prévoyez de créer des objets autorisés, tels que des vues autorisées, dans l'ensemble de données.
Dans ce cas, utilisez la ressource google_bigquery_dataset_access. Consultez la documentation pour obtenir des exemples.
Créer un ensemble de données et accorder l'accès à cet ensemble
L'exemple suivant crée un ensemble de données nommé mydataset et utilise ensuite la ressource google_bigquery_dataset_iam_policy pour accorder l'accès à cet ensemble de données.
Créer un ensemble de données avec une clé de chiffrement gérée par le client
L'exemple suivant crée un ensemble de données nommé mydataset et utilise également les ressources google_kms_crypto_key et google_kms_key_ring pour spécifier une clé Cloud Key Management Service pour l'ensemble de données. Vous devez activer l'API Cloud Key Management Service avant d'exécuter cet exemple.
Pour appliquer votre configuration Terraform dans un projet Google Cloud , suivez les procédures des sections suivantes.
Préparer Cloud Shell
- Lancez Cloud Shell.
-
Définissez le projet Google Cloud par défaut dans lequel vous souhaitez appliquer vos configurations Terraform.
Vous n'avez besoin d'exécuter cette commande qu'une seule fois par projet et vous pouvez l'exécuter dans n'importe quel répertoire.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Les variables d'environnement sont remplacées si vous définissez des valeurs explicites dans le fichier de configuration Terraform.
Préparer le répertoire
Chaque fichier de configuration Terraform doit avoir son propre répertoire (également appelé module racine).
-
Dans Cloud Shell, créez un répertoire et un nouveau fichier dans ce répertoire. Le nom du fichier doit comporter l'extension
.tf, par exemplemain.tf. Dans ce tutoriel, le fichier est appelémain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Si vous suivez un tutoriel, vous pouvez copier l'exemple de code dans chaque section ou étape.
Copiez l'exemple de code dans le fichier
main.tfque vous venez de créer.Vous pouvez également copier le code depuis GitHub. Cela est recommandé lorsque l'extrait Terraform fait partie d'une solution de bout en bout.
- Examinez et modifiez les exemples de paramètres à appliquer à votre environnement.
- Enregistrez les modifications.
-
Initialisez Terraform. Cette opération n'est à effectuer qu'une seule fois par répertoire.
terraform init
Vous pouvez également utiliser la dernière version du fournisseur Google en incluant l'option
-upgrade:terraform init -upgrade
Appliquer les modifications
-
Examinez la configuration et vérifiez que les ressources que Terraform va créer ou mettre à jour correspondent à vos attentes :
terraform plan
Corrigez les modifications de la configuration si nécessaire.
-
Appliquez la configuration Terraform en exécutant la commande suivante et en saisissant
yeslorsque vous y êtes invité :terraform apply
Attendez que Terraform affiche le message "Apply completed!" (Application terminée).
- Ouvrez votre projet Google Cloud pour afficher les résultats. Dans la console Google Cloud , accédez à vos ressources dans l'interface utilisateur pour vous assurer que Terraform les a créées ou mises à jour.
API
Appelez la méthode datasets.insert avec une ressource d'ensemble de données définie.
C#
Avant d'essayer cet exemple, suivez les instructions de configuration pour C# du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour C#.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Go
Avant d'essayer cet exemple, suivez les instructions de configuration pour Go du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Go.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Node.js
Avant d'essayer cet exemple, suivez les instructions de configuration pour Node.js du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Node.js.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
PHP
Avant d'essayer cet exemple, suivez les instructions de configuration pour PHP du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour PHP.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Ruby
Avant d'essayer cet exemple, suivez les instructions de configuration pour Ruby du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Ruby.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Nommer des ensembles de données
Lorsque vous créez un ensemble de données dans BigQuery, son nom doit être unique pour chaque projet. Le nom de l'ensemble de données peut contenir les éléments suivants :
- Jusqu'à 1 024 caractères
- Lettres (majuscules ou minuscules), chiffres et traits de soulignement
Les noms des ensembles de données sont sensibles à la casse par défaut. mydataset et MyDataset peuvent coexister dans le même projet, sauf si la sensibilité à la casse est désactivée pour l'un d'entre eux. Pour obtenir des exemples, consultez Créer un ensemble de données non sensible à la casse et Ressource : Ensemble de données.
Les noms d'ensembles de données ne peuvent pas contenir d'espaces ni de caractères spéciaux tels que -, &, @ ou %.
Ensembles de données masqués
Un ensemble de données masqué est un ensemble de données dont le nom commence par un trait de soulignement. Vous pouvez interroger les tables et les vues des ensembles de données masqués de la même manière que dans n'importe quel autre ensemble de données. Les ensembles de données masqués sont soumis aux restrictions suivantes :
- Ils sont masqués dans le panneau Explorateur de la console Google Cloud .
- Ils n'apparaissent pas dans les vues
INFORMATION_SCHEMA. - Ils ne peuvent pas être utilisés avec des ensembles de données associés.
- Ils ne peuvent pas être utilisés comme ensemble de données source avec les ressources autorisées suivantes :
- Ils n'apparaissent pas dans Data Catalog (obsolète) ni dans Dataplex Universal Catalog.
Sécurité des ensembles de données
Pour savoir comment contrôler l'accès aux ensembles de données dans BigQuery, consultez la page Contrôler l'accès aux ensembles de données. Pour en savoir plus sur le chiffrement des données, consultez la page Chiffrement au repos.
Étapes suivantes
- Pour savoir comment répertorier les ensembles de données d'un projet, consultez la page Répertorier des ensembles de données.
- Pour en savoir plus sur les métadonnées d'ensemble de données, consultez la page Obtenir des informations sur les ensembles de données.
- Pour savoir comment modifier les propriétés d'un ensemble de données, consultez la page Mettre à jour des ensembles de données.
- Pour en savoir plus sur la création et la gestion des libellés, consultez la page Créer et gérer des libellés.
Faites l'essai
Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de BigQuery en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits offerts pour exécuter, tester et déployer des charges de travail.
Profiter d'un essai gratuit de BigQuery