跨区域数据集复制
BigQuery 数据集复制功能可让您在两个不同的区域或多区域之间设置数据集的自动复制。
概览
在 BigQuery 中创建数据集时,您需要选择存储数据的区域或多区域。区域是一个地理区域内的数据中心集合,多区域是包含两个或更多地理区域的大型地理区域。您的数据存储在其中一个包含区域中,不会在多区域内复制。如需详细了解单区域和多区域,请参阅 BigQuery 位置。
BigQuery 始终将您的数据副本存储在数据集位置内的两个不同Google Cloud 可用区中。可用区是区域内 Google Cloud 资源的部署范围。在所有区域中,可用区之间的复制使用同步双重写入。选择多区域位置不会提供跨区域复制或区域冗余功能,因此在发生区域中断时数据集可用性不会提高。数据存储在地理位置内的单个区域中。
如需获得额外的地理位置冗余,您可以复制任何数据集。BigQuery 会创建数据集的次要副本,该副本位于您指定的其他区域。然后,此副本在另一个区域的两个可用区之间异步复制,总共有四个可用区级副本。
数据集复制
如果您复制数据集,BigQuery 会将数据存储在您指定的区域中。
主要区域。在您首次创建数据集时,BigQuery 会将该数据集放在主要区域。
次要区域。当您添加数据集副本时,BigQuery 会将副本放在次要区域。
最初,主要区域中的副本是主要副本,次要区域中的副本是次要副本。
主要副本为可写副本,次要副本为只读副本。对主要副本的写入会异步复制到次要副本。在每个区域内,数据以冗余方式存储在两个可用区中。网络流量绝不会离开 Google Cloud 网络。
下图展示了复制数据集时发生的复制:
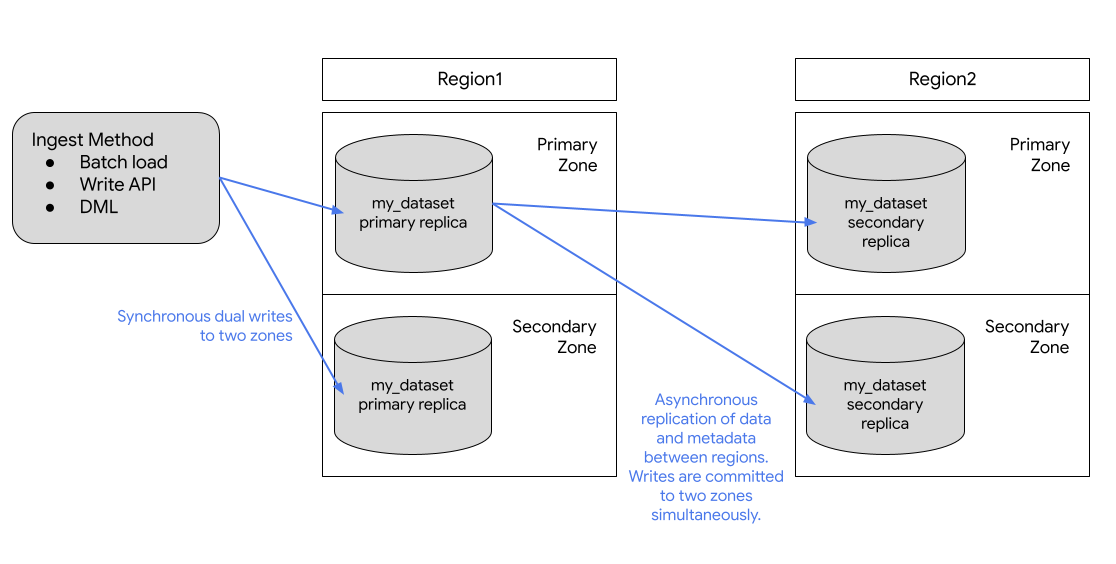
如果主要区域在线,您可以手动切换到次要副本。如需了解详情,请参阅提升次要副本。
价格
对于复制的数据集,您需要支付以下费用:
- 存储空间。次要区域中的存储字节数按次要区域中的单独副本进行计费。请参阅 BigQuery 存储价格。
- 数据复制。如需详细了解数据复制的结算方式,请参阅数据复制价格。
数据复制由 BigQuery 管理,不会使用您的槽资源。数据复制费用将单独结算。
次要区域中的计算容量
要对次要区域中的副本运行作业和查询,您必须在次要区域内购买槽或者运行按需查询。
您可以使用槽从次要副本执行只读查询。如果将次要副本提升为主要副本,您还可以使用这些槽来写入副本。
您可以购买与主要区域数量相同的槽,也可以购买不同数量的槽。如果购买较少的槽,查询性能可能会受影响。
位置注意事项
在添加数据集副本之前,您需要先在 BigQuery 中创建需要复制的初始数据集(如果此数据集尚不存在)。添加的副本的位置设置为您在添加副本时指定的位置。添加副本的位置必须与初始数据集的位置不同。这意味着,数据集中的数据会在数据集的创建位置和副本位置之间持续复制。对于需要保存在相同位置的副本(例如视图、具体化视图、非 BigLake 外部表),在与来源数据的位置不同或不兼容的位置添加副本可能会导致作业错误。
当客户跨区域复制数据集时,BigQuery 可确保数据仅位于副本的创建位置。
共置要求
使用数据集复制功能依赖于以下共置要求。
Cloud Storage
如需查询 Cloud Storage 中的数据,Cloud Storage 存储桶必须与副本位于同一位置。在决定副本的存放位置时,请考虑外部表位置注意事项。
限制
BigQuery 数据集复制需遵循以下限制:
- 通过 BigQuery Storage Write API 或
tabledata.insertAll方法写入主副本的流式数据随后会复制到次要副本,但这种复制是尽力而为的,并且复制延迟时间可能会很长。 - 从 Datastream 或 BigQuery 变更数据捕获写入主副本的流式更新/插入操作随后会复制到次要副本,但这种复制是尽力而为的,并且可能会出现较长的复制延迟。复制完成后,次要副本中的增量更新会根据表的配置
max_staleness值合并到次要副本的表基准中。 - 您不能在复制的数据集中的表上启用细粒度 DML,也不能复制包含已启用细粒度 DML 的表的数据集。
- 复制和切换通过 SQL 数据定义语言 (DDL) 语句进行管理。
- 每个区域或多区域只能有每个数据集的一个副本。您不能在同一目标区域中创建同一数据集的两个次要副本。
- 副本内的资源需遵循资源行为中所述的限制。
- 政策标记和关联的数据政策不会复制到次要副本。任何引用具有非原始区域中的政策标记的列的查询都将失败,即使该副本被提升也是如此。
- 只有在次要副本创建完成后,时间旅行才在次要副本中可用。
- 默认情况下,为数据集启用跨区域复制功能的目标区域大小限制为:
us和eu多区域为 10 PB,其他区域为 500 TB。这些限制可配置。如需了解详情,请联系Google Cloud 支持团队。 - 此配额适用于逻辑资源。
- 只能复制少于 10 万个表的数据集。
- 每个数据集每天最多只能向同一区域添加 4 个副本(然后丢弃)。
- 您受到带宽的限制。
- 如果未配置
replica_kms_key值,则在次要区域中无法查询已应用客户管理的加密密钥 (CMEK) 的表。 - 不支持 BigLake 表。
- 您不能复制外部数据集或联合数据集。
- 不支持 BigQuery Omni 位置。
- 如果您要为灾难恢复配置数据复制,则无法配置以下区域对:
us-central1-us多区域us-west1-us多区域eu-west1-eu多区域eu-west4-eu多区域
- 例程级访问权限控制无法复制,但您可以复制例程的数据集级访问权限控制。
资源行为
次要副本中的资源不支持以下操作:
次要副本为只读副本。如果您需要在次要副本中创建资源的副本,则必须先复制资源或查询资源,然后在次要副本之外具体化结果。例如,使用 CREATE TABLE AS SELECT 根据次要副本资源创建新资源。
主要副本和次要副本存在以下差异:
| 区域 1 主要副本 | 区域 2 次要副本 | 备注 |
|---|---|---|
| BigLake 表 | BigLake 表 | 不受支持。 |
| 外部表 | 外部表 | 仅复制外部表定义。如果 Cloud Storage 存储桶与副本位于不同位置,则查询会失败。 |
| 逻辑视图 | 逻辑视图 | 如果逻辑视图引用的数据集或资源与逻辑视图位于不同位置,则查询会失败。 |
| 代管表 | 代管表 | 没有区别。 |
| 物化视图 | 物化视图 | 如果引用的表与具体化视图不在同一区域,则查询会失败。复制的具体化视图的过时时间可能会超过视图的最大过时期限。 |
| 型号 | 型号 | 存储为代管表。 |
| 远程函数 | 远程函数 | 连接是区域级的。引用与远程函数位于不同位置的数据集或资源(连接)的远程函数在运行时会失败。 |
| 例程 | 用户定义的函数 (UDF) 或存储过程 | 引用与例程位于不同位置的数据集或资源的例程在运行时会失败。任何引用连接的例程(例如远程函数)都无法在源区域外部运行。 |
| 行访问权限政策 | 行访问权限政策 | 没有区别。 |
| 搜索索引 | 搜索索引 | 不复制。 |
| 存储过程 | 存储过程 | 引用与存储过程位于不同位置的数据集或资源的存储过程在运行时会失败。 |
| 表克隆 | 代管表 | 作为次要副本中的深度副本计费。 |
| 表快照 | 表快照 | 作为次要副本中的深度副本计费。 |
| 表值函数 (TVF) | TVF | 引用与 TVF 位于不同位置的数据集或资源的 TVF 在运行时会失败。 |
| UDF | UDF | 引用与 UDF 位于不同位置的数据集或资源的 UDF 在运行时会失败。 |
服务中断场景
跨区域复制不可用作发生全区域服务中断时的灾难恢复计划。如果主要副本的区域发生全区域服务中断,你将无法提升次要副本。由于次要副本是只读的,因此您无法在次要副本上运行任何写入作业,并且在主要副本的区域恢复之前也无法提升次要区域。 如需详细了解如何为灾难恢复做好准备,请参阅托管式灾难恢复。
下表说明了全区域服务中断对复制数据的影响:
| 区域 1 | 区域 2 | 服务中断区域 | 影响 |
|---|---|---|---|
| 主要副本 | 次要副本 | 区域 2 | 在区域 2 中对次要副本运行的只读作业会失败。 |
| 主要副本 | 次要副本 | 区域 1 | 在区域 1 中运行的所有作业都会失败。只读作业将继续在次要副本所在的区域 2 中运行。在区域 2 与区域 1 成功同步之前,区域 2 的内容为过时状态。 |
使用数据集复制功能
本部分介绍如何复制数据集、提升次要副本以及在次要区域中运行 BigQuery 读取作业。
所需权限
如需获得管理副本所需的权限,请让管理员向您授予 bigquery.datasets.update 权限。
复制数据集
如需复制数据集,请使用 ALTER SCHEMA ADD REPLICA DDL 语句。
您可以将副本添加到位于尚未复制的区域或多区域中的任何数据集。添加副本后,初始复制操作需要一些时间才能完成。当数据正在复制时,您仍然可以运行引用主要副本的查询,并且查询处理容量不会降低。您无法复制多区域内地理位置的数据。
以下示例在 us-central1 区域中创建名为 my_dataset 的数据集,然后在 us-east4 区域中添加副本:
-- Create the primary replica in the us-central1 region. CREATE SCHEMA my_dataset OPTIONS(location='us-central1'); -- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `my_replica` OPTIONS(location='us-east4');
如需确认次要副本已成功创建,您可以在 INFORMATION_SCHEMA.SCHEMATA_REPLICAS 视图中查询 creation_complete 列。
创建次要副本后,您可以明确将查询的位置设置为次要区域,从而查询该副本。如果未明确设置位置,BigQuery 会使用数据集主副本的区域。
提升次要副本
如果主要区域在线,您可以提升次要副本。提升操作会将次要副本切换为可写的主要副本。如果次要副本与主要副本同步,此操作几秒钟即可完成。如果次要副本与主要副本不同步,则在同步之前,提升操作无法完成。如果包含主要副本的区域发生服务中断,则次要副本无法提升为主要副本。
请注意以下几点:
- 当提升正在进行时,所有表写入操作都会返回错误。提升开始后,旧的主要副本会立即变得无法写入。
- 提升启动时未完全复制的表会返回过时读取。
如需将副本提升为主要副本,请使用 ALTER SCHEMA SET
OPTIONS DDL 语句并设置 primary_replica 选项。
请注意,您必须在查询设置中将作业位置明确设置为次要区域。请参阅 BigQuery 指定位置。
以下示例将 us-east4 副本提升为主要副本:
ALTER SCHEMA my_dataset SET OPTIONS(primary_replica = 'us-east4')
如需确认次要副本成功提升,您可以在 INFORMATION_SCHEMA.SCHEMATA_REPLICAS 视图中查询 replica_primary_assignment_complete 列。
移除数据集副本
如需移除副本并停止复制数据集,请使用 ALTER SCHEMA DROP REPLICA DDL 语句。
以下示例移除 us 副本:
ALTER SCHEMA my_dataset DROP REPLICA IF EXISTS `us`;
您必须先删除所有次要副本,然后才能删除整个数据集。如果您删除整个数据集(例如,使用 DROP
SCHEMA 语句),但不删除所有次要副本,则会收到以下错误:
The dataset replica of the cross region dataset 'project_id:dataset_id' in region 'REGION' is not yet writable because the primary assignment is not yet complete.
如需了解详情,请参阅提升次要副本。
列出数据集副本
如需列出项目中的数据集副本,请查询 INFORMATION_SCHEMA.SCHEMATA_REPLICAS 视图。
迁移数据集
您可以使用跨区域复制功能将数据集从一个区域迁移到另一个区域。以下示例演示了使用跨区域复制功能将现有 my_migration 数据集从 US 多区域迁移到 EU 多区域的过程。
复制数据集
如需开始迁移过程,请先在数据迁移的目标区域中复制数据集。在此场景中,您要将 my_migration 数据集迁移到 EU 多区域。
-- Create a replica in the secondary region. ALTER SCHEMA my_migration ADD REPLICA `eu` OPTIONS(location='eu');
这会在 EU 多区域中创建一个名为 eu 的次要副本。主要副本是 US 多区域中的 my_migration 数据集。
提升次要副本
如需继续将数据集迁移到 EU 多区域,请提升次要副本:
ALTER SCHEMA my_migration SET OPTIONS(primary_replica = 'eu')
提升完成后,eu 是主要副本。它是可写的副本。
完成迁移
如需完成从 US 多区域到 EU 多区域的迁移,请删除 us 副本。此步骤不是必需的,但如果您在迁移后不需要数据集副本,则此步骤很有用。
ALTER SCHEMA my_migration DROP REPLICA IF EXISTS us;
您的数据集位于 EU 多区域,并且 my_migration 数据集没有副本。您已成功将数据集迁移到 EU 多区域。如需查看已迁移资源的完整列表,请参阅资源行为。
客户管理的加密密钥 (CMEK)
当您创建次要副本时,客户管理的 Cloud Key Management Service 密钥不会自动复制。为了保持对复制的数据集的加密,您必须为添加副本的位置设置 replica_kms_key。您可以使用 ALTER SCHEMA ADD REPLICA DDL 语句设置 replica_kms_key。
复制具有 CMEK 的数据集的行为如以下场景所述:
如果源数据集有
default_kms_key,则您必须在使用ALTER SCHEMA ADD REPLICADDL 语句时提供在副本数据集的区域中创建的replica_kms_key。如果源数据集没有为
default_kms_key设置值,您无法设置replica_kms_key。如果您对
default_kms_key或replica_kms_key中的一个(或两者)使用 Cloud KMS 密钥轮替,则在密钥轮替后,复制的数据集仍可查询。- 主要区域中的密钥轮替仅在轮替后创建的表中更新密钥版本,密钥轮替之前存在的表仍然使用轮替之前设置的密钥版本。
- 次要区域中的密钥轮替会将次要副本中的所有表更新为新的密钥版本。
- 将主要副本切换到次要副本会将次要副本(以前称为主要副本)中的所有表更新为新的密钥版本。
- 如果在密钥轮替之前在主要副本中的表上设置的密钥版本被删除,则在密钥版本更新之前,无法查询仍在使用密钥轮替之前设置的密钥版本的任何表。如需更新密钥版本,旧密钥版本必须处于活跃状态(而非停用或删除)。
如果源数据集没有为
default_kms_key设置值,但源数据集中有个别表应用了 CMEK,则这些表无法在复制的数据集中查询。如需查询表,请执行以下操作:- 为源数据集添加
default_kms_key值。 - 使用
ALTER SCHEMA ADD REPLICADDL 语句创建新副本时,为replica_kms_key选项设置一个值。CMEK 表可以在目标区域中查询。
无论源区域使用什么密钥,目标区域中的所有 CMEK 表都使用相同的
replica_kms_key。- 为源数据集添加
创建具有 CMEK 的副本
以下示例在 us-west1 区域中创建一个副本,并设置 replica_kms_key 值。 对于 CMEK 密钥,请授予 BigQuery 服务账号权限以进行加密和解密。
-- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `us-west1` OPTIONS(location='us-west1', replica_kms_key='my_us_west1_kms_key_name');
CMEK 限制
复制应用了 CMEK 的数据集须遵循以下限制:
创建副本后,您无法更新复制的 Cloud KMS 密钥。
创建数据集副本后,您无法更新源数据集的
default_kms_key值。如果提供的
replica_kms_key在目标区域中无效,则数据集将不会复制。
后续步骤
- 了解如何使用 BigQuery 预留。
- 了解 BigQuery 可靠性功能。