Replica dei set di dati tra regioni
Con la replica dei set di dati BigQuery, puoi configurare la replica automatica di un set di dati tra due regioni o multiregioni diverse.
Panoramica
Quando crei un set di dati in BigQuery, selezioni la regione o la multiregione in cui vengono archiviati i dati. Una regione è un insieme di data center all'interno di un'area geografica, mentre una multi-region è una grande area geografica che contiene due o più regioni geografiche. I tuoi dati vengono archiviati in una delle regioni contenute e non vengono replicati all'interno della multiregione. Per saperne di più su regioni e multiregioni, consulta Località BigQuery.
BigQuery archivia sempre copie dei dati in dueGoogle Cloud zone diverse all'interno della località del set di dati. Una zona è un'area di deployment per le risorse Google Cloud all'interno di una regione. In tutte le regioni, la replica tra le zone utilizza la doppia scrittura sincrona. La selezione di una località multiregionale non fornisce la replica tra regioni o la ridondanza regionale, pertanto non si verifica un aumento della disponibilità del set di dati in caso di interruzione del servizio a livello di regione. I dati vengono archiviati in una singola regione all'interno della posizione geografica.
Per una maggiore ridondanza geografica, puoi replicare qualsiasi set di dati. BigQuery crea una replica secondaria del set di dati, che si trova in un'altra regione specificata. Questa replica viene poi replicata in modo asincrono tra due zone con l'altra regione, per un totale di quattro copie zonali.
Replica del set di dati
Se replichi un set di dati, BigQuery archivia i dati nella regione che specifichi.
Regione principale. Quando crei un set di dati per la prima volta, BigQuery lo inserisce nella regione principale.
Regione secondaria. Quando aggiungi una replica del set di dati, BigQuery la inserisce nella regione secondaria.
Inizialmente, la replica nella regione principale è la replica primaria e la replica nella regione secondaria è la replica secondaria.
La replica primaria è scrivibile, mentre la replica secondaria è di sola lettura. Le scritture nella replica principale vengono replicate in modo asincrono nella replica secondaria. All'interno di ogni regione, i dati vengono archiviati in modo ridondante in due zone. Il traffico di rete non esce mai dalla rete Google Cloud .
Il seguente diagramma mostra la replica che si verifica quando un set di dati viene replicato:
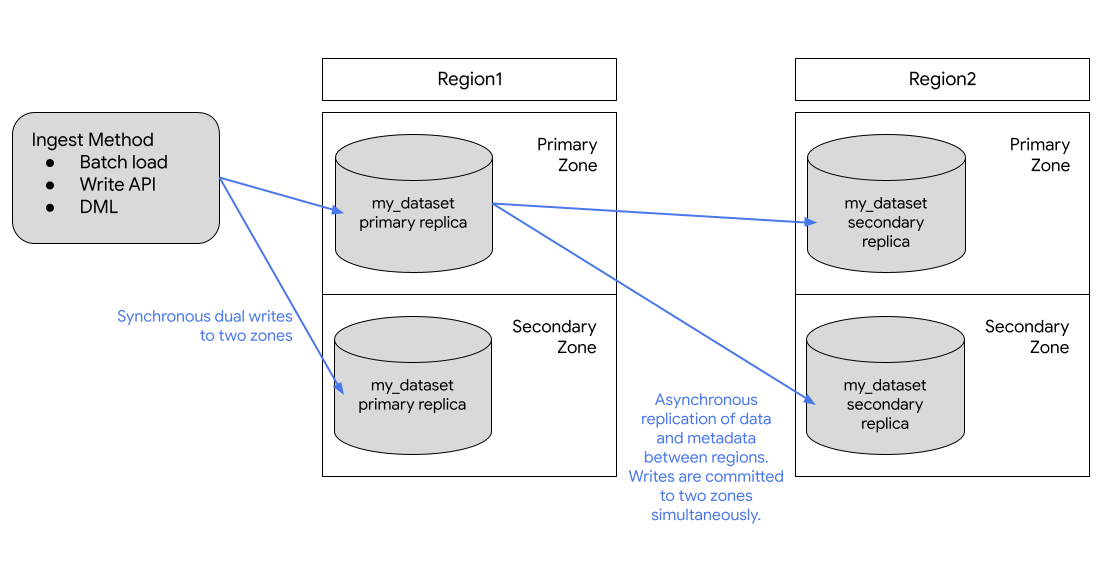
Se la regione principale è online, puoi passare manualmente alla replica secondaria. Per ulteriori informazioni, consulta Promuovere la replica secondaria.
Prezzi
Per i set di dati replicati, ti vengono addebitati i seguenti costi:
- Spazio di archiviazione. I byte di spazio di archiviazione nella regione secondaria vengono fatturati come una copia separata nella regione secondaria. Consulta i prezzi dello spazio di archiviazione BigQuery.
- Replica dei dati. Per ulteriori informazioni su come viene fatturata la replica dei dati, consulta Prezzi della replica dei dati.
La replica dei dati è gestita da BigQuery e non utilizza le tue risorse slot. La fatturazione della replica dei dati avviene separatamente.
Capacità di calcolo nella regione secondaria
Per eseguire job e query sulla replica nella regione secondaria, devi acquistare slot all'interno della regione secondaria o eseguire una query on demand.
Puoi utilizzare gli slot per eseguire query di sola lettura dalla replica secondaria. Se promuovi la replica secondaria a primaria, puoi utilizzare questi slot anche per scrivere nella replica.
Puoi acquistare lo stesso numero di slot della regione principale o un numero diverso. Se acquisti meno slot, le prestazioni delle query potrebbero risentirne.
Considerazioni sulla posizione
Prima di aggiungere una replica del set di dati, devi creare il set di dati iniziale da replicare in BigQuery, se non esiste già. La posizione della replica aggiunta è impostata sulla posizione specificata durante l'aggiunta della replica. La posizione della replica aggiunta deve essere diversa da quella del set di dati iniziale. Ciò significa che i dati nel set di dati vengono replicati continuamente tra la località in cui è stato creato il set di dati e la località della replica. Per le repliche che richiedono la collocazione, come viste, viste materializzate o tabelle esterne non BigLake, l'aggiunta di una replica in una località diversa o non compatibile con la località dei dati di origine potrebbe causare errori del job.
Quando i clienti replicano un set di dati in più regioni, BigQuery garantisce che i dati si trovino solo nelle località in cui sono state create le repliche.
Requisiti di colocation
L'utilizzo della replica dei set di dati dipende dai seguenti requisiti di colocation.
Cloud Storage
L'esecuzione di query sui dati in Cloud Storage richiede che il bucket Cloud Storage sia collocato insieme alla replica. Quando decidi dove posizionare la replica, tieni conto delle considerazioni sulla posizione delle tabelle esterne.
Limitazioni
La replica del set di dati BigQuery è soggetta alle limitazioni riportate di seguito:
- I dati di streaming scritti nella replica primaria dall'API BigQuery Storage Write o dal metodo
tabledata.insertAll, che vengono poi replicati nella replica secondaria, sono di tipo best-effort e potrebbero subire un ritardo di replica elevato. - Gli upsert in streaming scritti nella replica primaria da
Datastream o
BigQuery Change Data Capture,
che viene poi replicata nella replica secondaria, sono di tipo best-effort e potrebbero
presentare un ritardo di replica elevato. Una volta replicate, le operazioni di upsert nella replica secondaria vengono unite alla baseline della tabella della replica secondaria in base al valore
max_stalenessconfigurato della tabella. - Non puoi attivare DML granulare� in una tabella di un set di dati replicato e non puoi replicare un set di dati che contiene una tabella con DML granulare abilitata.
- La replica e il failover vengono gestiti tramite istruzioni Data Definition Language (DDL) di SQL.
- Puoi creare una sola replica di ogni set di dati per ogni regione o multiregione. Non puoi creare due repliche secondarie dello stesso set di dati nella stessa regione di destinazione.
- Le risorse all'interno delle repliche sono soggette alle limitazioni descritte in Comportamento delle risorse.
- I tag di criterio e i criteri relativi ai dati associati non vengono replicati nella replica secondaria. Qualsiasi query che fa riferimento a colonne con tag di criteri in regioni diverse da quella originale non va a buon fine, anche se la replica viene promossa.
- Time-Travel è disponibile solo nella replica secondaria dopo il completamento della creazione della replica secondaria.
- Il limite di dimensioni della regione di destinazione per l'attivazione della replica tra regioni
in un set di dati è 10 PB per le multiregioni
useeue 500 TB per le altre regioni per impostazione predefinita. Questi limiti sono configurabili. Per ulteriori informazioni, contatta l'assistenza diGoogle Cloud . - La quota si applica alle risorse logiche.
- Puoi replicare solo un set di dati con meno di 100.000 tabelle.
- Puoi aggiungere (e poi eliminare) un massimo di 4 repliche alla stessa regione per set di dati al giorno.
- La larghezza di banda è limitata.
- Le tabelle a cui sono state applicate le chiavi di crittografia gestite dal cliente (CMEK) non sono interrogabili nella regione secondaria se il valore
replica_kms_keynon è configurato. - Le tabelle BigLake non sono supportate.
- Non puoi replicare set di dati esterni o federati.
- Le posizioni BigQuery Omni non sono supportate.
- Non puoi configurare le seguenti coppie di regioni se stai configurando la replica dei dati per il recupero di emergenza:
us-central1-usmultiregionaleus-west1-usmultiregionaleeu-west1-eumultiregionaleeu-west4-eumultiregionale
- I controlli dell'accesso a livello di routine non possono essere replicati, ma puoi replicare i controlli dell'accesso a livello di set di dati per le routine.
Comportamento delle risorse
Le seguenti operazioni non sono supportate sulle risorse all'interno della replica secondaria:
La replica secondaria è di sola lettura. Se devi creare una copia di una risorsa in una replica secondaria, devi copiare la risorsa o eseguirne una query e poi materializzare i risultati al di fuori della replica secondaria. Ad esempio, utilizza CREATE TABLE AS SELECT per creare una nuova risorsa dalla risorsa di replica secondaria.
Le repliche primaria e secondaria sono soggette alle seguenti differenze:
| Replica primaria della regione 1 | Replica secondaria della regione 2 | Note |
|---|---|---|
| Tabella BigLake | Tabella BigLake | Non supportati. |
| Tabella esterna | Tabella esterna | Viene replicata solo la definizione della tabella esterna. La query non va a buon fine quando il bucket Cloud Storage non si trova nella stessa località di una replica. |
| Vista logica | Vista logica | Le viste logiche che fanno riferimento a un set di dati o a una risorsa che non si trova nella stessa posizione della vista logica non vanno a buon fine quando vengono eseguite query. |
| Tabella gestita | Tabella gestita | Nessuna differenza. |
| Vista materializzata | Vista materializzata | Se una tabella a cui viene fatto riferimento non si trova nella stessa regione della vista materializzata, la query non va a buon fine. Le viste materializzate replicate potrebbero presentare un'inattività superiore all'inattività massima della vista. |
| Modello | Modello | Archiviati come tabelle gestite. |
| Funzione remota | Funzione remota | Le connessioni sono regionali. Le funzioni remote che fanno riferimento a un set di dati o a una risorsa (connessione) che non si trova nella stessa località della funzione remota non vengono eseguite. |
| Routine | Funzione definita dall'utente o stored procedure | Le routine che fanno riferimento a un set di dati o a una risorsa che non si trova nella stessa posizione della routine non vengono eseguite. Qualsiasi routine che faccia riferimento a una connessione, ad esempio funzioni remote, non funziona al di fuori della regione di origine. |
| Criterio di accesso alle righe | Criterio di accesso alle righe | Nessuna differenza. |
| Indice di ricerca | Indice di ricerca | Non replicato. |
| Stored procedure | Stored procedure | Le stored procedure che fanno riferimento a un set di dati o a una risorsa che non si trova nella stessa posizione della stored procedure non vengono eseguite. |
| Clonazione della tabella | Tabella gestita | Fatturata come copia completa nella replica secondaria. |
| Snapshot tabella | Snapshot tabella | Fatturata come copia completa nella replica secondaria. |
| Funzione con valori di tabella (TVF) | TVF | Le TVF che fanno riferimento a un set di dati o a una risorsa che non si trova nella stessa posizione della TVF non vengono eseguite. |
| Funzioni definite dall'utente | Funzioni definite dall'utente | Le UDF che fanno riferimento a un set di dati o a una risorsa che non si trova nella stessa posizione della UDF non vengono eseguite. |
Scenari di interruzione del servizio
La replica tra regioni non è pensata per essere utilizzata come piano di ripristino di emergenza durante un'interruzione totale a livello di regione. In caso di interruzione totale della regione in cui si trova la replica primaria, non puoi promuovere la replica secondaria. Poiché le repliche secondarie sono di sola lettura, non puoi eseguire job di scrittura sulla replica secondaria e non puoi promuovere la regione secondaria finché non viene ripristinata la regione della replica principale. Per saperne di più sulla preparazione al ripristino di emergenza, vedi Disaster recovery gestito.
La tabella seguente spiega l'impatto delle interruzioni totali della regione sui dati replicati:
| Regione 1 | Regione 2 | Regione di interruzione | Impatto |
|---|---|---|---|
| Replica primaria | Replica secondaria | Regione 2 | I job di sola lettura eseguiti nella regione 2 sulla replica secondaria non vanno a buon fine. |
| Replica primaria | Replica secondaria | Regione 1 | Tutti i job in esecuzione nella regione 1 non vanno a buon fine. I job di sola lettura continuano a essere eseguiti nella regione 2 in cui si trova la replica secondaria. I contenuti della regione 2 non sono aggiornati finché non vengono sincronizzati correttamente con la regione 1. |
Utilizzare la replica del set di dati
Questa sezione descrive come replicare un set di dati, promuovere la replica secondaria ed eseguire job di lettura BigQuery nella regione secondaria.
Autorizzazioni obbligatorie
Per ottenere le autorizzazioni necessarie per gestire le repliche, chiedi all'amministratore
di concederti l'autorizzazione bigquery.datasets.update.
Replicare un set di dati
Per replicare un set di dati, utilizza l'istruzione DDL ALTER SCHEMA ADD REPLICA.
Puoi aggiungere una replica a qualsiasi set di dati che si trova in una regione o in più regioni che non è già replicato in quella regione o in più regioni. Dopo aver aggiunto una replica, è necessario del tempo per completare l'operazione di copia iniziale. Puoi comunque eseguire query che fanno riferimento alla replica primaria durante la replica dei dati, senza ridurre la capacità di elaborazione delle query. Non puoi replicare i dati all'interno delle posizioni geografiche in una regione multipla.
Il seguente esempio crea un set di dati denominato my_dataset nella regione us-central1 e poi aggiunge una replica nella regione us-east4:
-- Create the primary replica in the us-central1 region. CREATE SCHEMA my_dataset OPTIONS(location='us-central1'); -- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `my_replica` OPTIONS(location='us-east4');
Per verificare quando la replica secondaria è stata creata correttamente, puoi
interrogare la colonna creation_complete nella
visualizzazione INFORMATION_SCHEMA.SCHEMATA_REPLICAS.
Dopo aver creato la replica secondaria, puoi eseguirvi query impostando esplicitamente la località della query sulla regione secondaria. Se una località non è impostata in modo esplicito, BigQuery utilizza la regione della replica principale del set di dati.
Promuovere la replica secondaria
Se la regione principale è online, puoi promuovere la replica secondaria. La promozione fa sì che la replica secondaria diventi la principale scrivibile. Questa operazione viene completata in pochi secondi se la replica secondaria è sincronizzata con la replica principale. Se la replica secondaria non è aggiornata, la promozione non può essere completata finché non viene aggiornata. La replica secondaria non può essere promossa a principale se la regione contenente la principale ha un'interruzione.
Tieni presente quanto segue:
- Tutte le scritture nelle tabelle restituiscono errori durante l'elaborazione della promozione. La vecchia replica primaria diventa non scrivibile immediatamente all'inizio della promozione.
- Le tabelle che non sono completamente replicate al momento dell'avvio della promozione restituiscono letture non aggiornate.
Per promuovere una replica a replica primaria, utilizza l'istruzione DDL ALTER SCHEMA SET
OPTIONS e imposta l'opzione primary_replica.
Tieni presente quanto segue: - Devi impostare esplicitamente la posizione del lavoro sulla regione secondaria nelle impostazioni della query. Consulta Specifica delle località BigQuery.
L'esempio seguente promuove la replica us-east4 a principale:
ALTER SCHEMA my_dataset SET OPTIONS(primary_replica = 'us-east4')
Per verificare quando la replica secondaria è stata promossa correttamente, puoi
interrogare la colonna replica_primary_assignment_complete nella
visualizzazione INFORMATION_SCHEMA.SCHEMATA_REPLICAS.
Rimuovere una replica del set di dati
Per rimuovere una replica e interrompere la replica del set di dati, utilizza l'istruzione DDL ALTER SCHEMA DROP REPLICA.
L'esempio seguente rimuove la replica us:
ALTER SCHEMA my_dataset DROP REPLICA IF EXISTS `us`;
Per eliminare l'intero set di dati, devi prima eliminare tutte le repliche secondarie. Se elimini l'intero set di dati, ad esempio utilizzando l'istruzione DROP
SCHEMA, senza eliminare tutte le repliche secondarie, viene visualizzato il seguente errore:
The dataset replica of the cross region dataset 'project_id:dataset_id' in region 'REGION' is not yet writable because the primary assignment is not yet complete.
Per saperne di più, consulta Promuovere la replica secondaria.
Elenca repliche del set di dati
Per elencare le repliche del set di dati in un progetto, esegui una query sulla visualizzazione
INFORMATION_SCHEMA.SCHEMATA_REPLICAS.
Eseguire la migrazione dei set di dati
Puoi utilizzare la replica dei set di dati tra regioni per eseguire la migrazione dei set di dati da una regione all'altra. Il seguente esempio mostra il processo di migrazione
del set di dati my_migration esistente dalla regione multiregionale US alla regione multiregionale EU
utilizzando la replica tra regioni.
Replica il set di dati
Per iniziare il processo di migrazione, replica prima il set di dati nella regione in cui
vuoi eseguire la migrazione dei dati. In questo scenario, viene eseguita la migrazione del
set di dati my_migration nella multiregione EU.
-- Create a replica in the secondary region. ALTER SCHEMA my_migration ADD REPLICA `eu` OPTIONS(location='eu');
Viene creata una replica secondaria denominata eu nella multi-regione EU.
La replica principale è il set di dati my_migration nella regione multiregionale US.
Promuovere la replica secondaria
Per continuare la migrazione del set di dati nella regione multiregionale EU, promuovi la replica secondaria:
ALTER SCHEMA my_migration SET OPTIONS(primary_replica = 'eu')
Al termine della promozione, eu è la replica primaria. È una replica
modificabile.
Completare la migrazione
Per completare la migrazione dalla multiregione US alla multiregione EU,
elimina la replica us. Questo passaggio non è obbligatorio, ma è utile se non hai bisogno di una replica del set di dati oltre alle tue esigenze di migrazione.
ALTER SCHEMA my_migration DROP REPLICA IF EXISTS us;
Il tuo set di dati si trova nella multiregione EU e non esistono repliche del set di dati my_migration. Hai eseguito la migrazione del set di dati alla
multiregione EU. L'elenco completo delle risorse di cui viene eseguita la migrazione è disponibile
in Comportamento delle risorse.
Chiavi di crittografia gestite dal cliente (CMEK)
Le chiavi di Cloud Key Management Service gestite dal cliente
non vengono replicate automaticamente quando crei una replica secondaria. Per mantenere la crittografia nel set di dati replicato, devi impostare replica_kms_key per la posizione della replica aggiunta. Puoi impostare
replica_kms_key utilizzando l'istruzione
ALTER SCHEMA ADD REPLICA DDL.
La replica dei set di dati con CMEK si comporta come descritto negli scenari seguenti:
Se il set di dati di origine ha un
default_kms_key, devi fornire unreplica_kms_keycreato nella regione del set di dati di replica quando utilizzi l'istruzione DDLALTER SCHEMA ADD REPLICA.Se il set di dati di origine non ha un valore impostato per
default_kms_key, non puoi impostarereplica_kms_key.Se utilizzi la rotazione delle chiavi Cloud KMS su uno o entrambi i
default_kms_keyoreplica_kms_key, il set di dati replicato è ancora interrogabile dopo la rotazione della chiavevi.- La rotazione della chiave nella regione primaria aggiorna la versione della chiave solo nelle tabelle create dopo la rotazione. Le tabelle esistenti prima della rotazione della chiave continuano a utilizzare la versione della chiave impostata prima della rotazione.
- La rotazione delle chiavi nella regione secondaria aggiorna tutte le tabelle nella replica secondaria alla nuova versione della chiave.
- Il passaggio dalla replica primaria alla replica secondaria aggiorna tutte le tabelle nella replica secondaria (precedentemente la replica primaria) alla nuova versione della chiave.
- Se la versione della chiave impostata nelle tabelle nella replica primaria prima della rotazione della chiave viene eliminata, non è possibile eseguire query sulle tabelle che utilizzano ancora la versione della chiave impostata prima della rotazione della chiave finché la versione della chiave non viene aggiornata. Per aggiornare la versione della chiave, la versione precedente deve essere attiva (non disattivata o eliminata).
Se il set di dati di origine non ha un valore impostato per
default_kms_key, ma nel set di dati di origine sono presenti singole tabelle a cui è stata applicata la CMEK, queste tabelle non sono interrogabili nel set di dati replicato. Per eseguire query sulle tabelle:- Aggiungi un valore
default_kms_keyper il set di dati di origine. - Quando crei una
nuova replica utilizzando l'istruzione DDL
ALTER SCHEMA ADD REPLICA, imposta un valore per l'opzionereplica_kms_key. Le tabelle CMEK sono interrogabili nella regione di destinazione.
Tutte le tabelle CMEK nella regione di destinazione utilizzano lo stesso
replica_kms_key, indipendentemente dalla chiave utilizzata nella regione di origine.- Aggiungi un valore
Crea una replica con CMEK
L'esempio seguente crea una replica nella regione us-west1 con un valore replica_kms_key impostato. Per la chiave CMEK, concedi
all'account di servizio BigQuery
l'autorizzazione a criptare e decriptare.
-- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `us-west1` OPTIONS(location='us-west1', replica_kms_key='my_us_west1_kms_key_name');
Limitazioni di CMEK
La replica dei set di dati a cui è stata applicata CMEK è soggetta alle seguenti limitazioni:
Non puoi aggiornare la chiave Cloud KMS replicata dopo la creazione della replica.
Non puoi aggiornare il valore
default_kms_keynel set di dati di origine dopo la creazione delle repliche del set di dati.Se il
replica_kms_keyfornito non è valido nella regione di destinazione, il set di dati non verrà replicato.
Passaggi successivi
- Scopri come utilizzare le prenotazioni BigQuery.
- Scopri di più sulle funzionalità di affidabilità di BigQuery.