Replicación de conjuntos de datos entre regiones
Con la replicación de conjuntos de datos de BigQuery, puedes configurar la replicación automática de un conjunto de datos entre dos regiones diferentes o multirregiones.
Descripción general
Cuando creas un conjunto de datos en BigQuery, debes seleccionar la región o multirregión en la que se almacenan los datos. Una región es una colección de centros de datos dentro de un área geográfica, y una multirregión es un área geográfica grande que contiene dos o más regiones geográficas. Tus datos se almacenan en una de las regiones contenidas y no se replican dentro de la multirregión. Para obtener más información sobre regiones y multirregiones, consulta Ubicaciones de BigQuery.
BigQuery siempre almacena copias de tus datos en dosGoogle Cloud zonas diferentes dentro de la ubicación del conjunto de datos. Una zona es un área de implementación para los recursos de Google Cloud dentro de una región. En todas las regiones, la replicación entre zonas usa escrituras dobles síncronas. Seleccionar una ubicación multirregional no proporciona replicación entre regiones ni redundancia regional, por lo que no hay un aumento en la disponibilidad del conjunto de datos en el caso de una interrupción regional. Los datos se almacenan en una sola región dentro de la ubicación geográfica.
Para obtener redundancia geográfica adicional, puedes replicar cualquier conjunto de datos. BigQuery crea una réplica secundaria del conjunto de datos, ubicada en otra región que especifiques. Luego, esta réplica se replica de forma asíncrona entre dos zonas con la otra región para producir un total de cuatro copias zonales.
Replicación de conjuntos de datos
Si replicas un conjunto de datos, BigQuery almacena los datos en la región que especifiques.
Región principal. Cuando creas un conjunto de datos por primera vez, BigQuery lo coloca en la región principal.
Región secundaria. Cuando agregas una réplica del conjunto de datos, BigQuery la coloca en la región secundaria.
En un principio, la réplica en la región principal es la réplica principal, y la réplica en la región secundaria es la réplica secundaria.
La réplica principal admite operaciones de escritura y la réplica secundaria es de solo lectura. Las operaciones de escritura en la réplica principal se replican de forma asíncrona en la réplica secundaria. Dentro de cada región, los datos se almacenan de manera redundante en dos zonas. El tráfico de red nunca sale de la red Google Cloud .
En el siguiente diagrama, se muestra la replicación que ocurre cuando se replica un conjunto de datos:
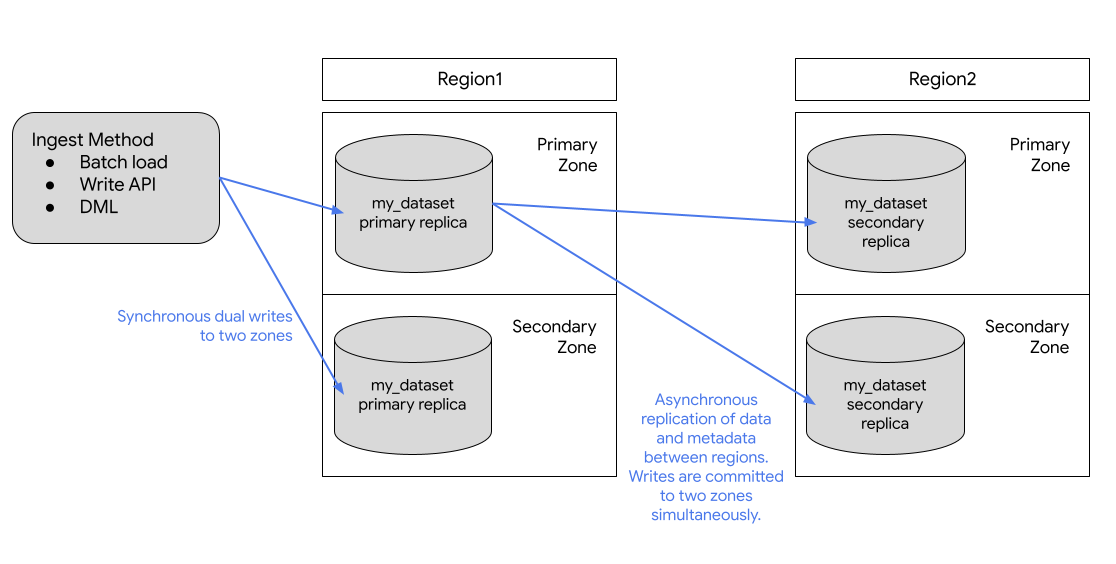
Si la región principal está en línea, puedes cambiar de forma manual a la réplica secundaria. Para obtener más información, consulta Asciende la réplica secundaria.
Precios
Se te factura lo siguiente en el caso de los conjuntos de datos replicados:
- Almacenamiento. Los bytes de almacenamiento en la región secundaria se facturan como una copia independiente en la región secundaria. Consulta los precios de almacenamiento de BigQuery.
- Replicación de datos. Para obtener más información sobre cómo se te factura por la replicación de datos, consulta Precios de la replicación de datos.
BigQuery administra la replicación de datos y no usa tus recursos de ranuras. La replicación de datos se factura por separado.
Capacidad de procesamiento en la región secundaria
Para ejecutar trabajos y consultas en la réplica en la región secundaria, debes comprar ranuras dentro de la región secundaria o ejecutar una consulta según demanda.
Puedes usar las ranuras para realizar consultas de solo lectura desde la réplica secundaria. Si asciendes la réplica secundaria para que sea la principal, también puedes usar esas ranuras a fin de escribir en la réplica.
Puedes comprar la misma cantidad de ranuras que tienes en la región principal o una cantidad diferente de ranuras. Si compras menos ranuras, esto podría afectar el rendimiento de las consultas.
Consideraciones de ubicación
Antes de agregar una réplica del conjunto de datos, debes crear el conjunto de datos inicial que deseas replicar en BigQuery si aún no existe. La ubicación de la réplica agregada se establece en la ubicación que especificas cuando agregas la réplica. La ubicación de la réplica agregada debe ser diferente de la ubicación del conjunto de datos inicial. Esto significa que los datos en tu conjunto de datos se replican de forma continua entre la ubicación en la que se creó el conjunto de datos y la ubicación de la réplica. En el caso de las réplicas que requieren colocación, como vistas, vistas materializadas o tablas externas que no sean de BigLake, agregar una réplica en una ubicación diferente de la ubicación de tus datos de origen o que no sea compatible con ella puede generar errores en el trabajo.
Cuando los clientes replican un conjunto de datos en varias regiones, BigQuery se asegura de que los datos se encuentren solo en las ubicaciones en las que se crearon las réplicas.
Requisitos de colocación
El uso de la replicación de conjuntos de datos depende de los siguientes requisitos de colocación.
Cloud Storage
Para consultar datos en Cloud Storage, el bucket de Cloud Storage se ubica en la réplica. Usa las consideraciones de ubicación de tablas externas para decidir en qué lugar ubicar la réplica.
Limitaciones
La replicación de conjuntos de datos de BigQuery está sujeta a las siguientes limitaciones:
- La transmisión de datos escritos en la réplica principal desde la API de BigQuery Storage Write o el método
tabledata.insertAll, que luego se replica en la réplica secundaria, se basa en el mejor esfuerzo y puede experimentar un retraso de replicación alto. - Las operaciones upsert de transmisión escritas en la réplica principal desde Datastream o la captura de datos modificados de BigQuery, que luego se replican en la réplica secundaria, se basan en el mejor esfuerzo y pueden experimentar un retraso de replicación alto. Una vez replicadas, las inserciones y actualizaciones de la réplica secundaria se combinan en la línea base de la tabla de la réplica secundaria según el valor de
max_stalenessconfigurado de la tabla. - No puedes habilitar el DML detallado en una tabla de un conjunto de datos replicado, ni puedes replicar un conjunto de datos que contenga una tabla con el DML detallado habilitado.
- Las replicaciones y los cambios se administran mediante las declaraciones de lenguaje de definición de datos (DDL) de SQL.
- Tienes un límite de una réplica de cada conjunto de datos para cada región o multirregión. No puedes crear dos réplicas secundarias del mismo conjunto de datos en la misma región de destino.
- Los recursos dentro de las réplicas están sujetos a las limitaciones, como se describe en Comportamiento de los recursos.
- Las etiquetas de política y las políticas de datos asociadas no se replican en la réplica secundaria. Cualquier consulta que haga referencia a columnas con etiquetas de política en regiones distintas de la región original fallarán, incluso si se asciende esa réplica.
- El viaje en el tiempo solo está disponible en la réplica secundaria una vez que se completa la creación de la réplica secundaria.
- El límite de tamaño de la región de destino para habilitar la replicación entre regiones en un conjunto de datos es de 10 PB para las multirregiones
usyeu, y de 500 TB para otras regiones de forma predeterminada. Estos límites se pueden configurar. Para obtener más información, comunícate con el Google Cloud equipo de asistencia. - La cuota se aplica a los recursos lógicos.
- Solo puedes replicar un conjunto de datos con menos de 100,000 tablas.
- Tienes un límite de 4 réplicas para agregar (y que luego se descartan) a una misma región por conjunto de datos por día.
- Estás limitado por el ancho de banda.
- Las tablas con claves de encriptación administradas por el cliente (CMEK) aplicadas no se pueden consultar en la región secundaria si el valor
replica_kms_keyno está configurado. - Las tablas de BigLake no son compatibles.
- No puedes replicar conjuntos de datos externos o federados.
- No se admiten las ubicaciones de BigQuery Omni.
- No puedes configurar los siguientes pares de regiones si configuras la replicación de datos para la recuperación ante desastres:
us-central1-usmultirregionalus-west1-usmultirregionaleu-west1-eumultirregionaleu-west4-eumultirregional
- Los controles de acceso a nivel de la rutina no se pueden replicar, pero sí se pueden replicar los controles de acceso a nivel del conjunto de datos para las rutinas.
Comportamiento de los recursos
Las siguientes operaciones no son compatibles con los recursos dentro de la réplica secundaria:
La réplica secundaria es de solo lectura. Si necesitas crear una copia de un recurso en una réplica secundaria, primero debes copiar el recurso o consultarlo y, luego, materializar los resultados fuera de la réplica secundaria. Por ejemplo, usa CREATE TABLE AS SELECT para crear un recurso nuevo a partir del recurso de réplica secundario.
Las réplicas principales y secundarias están sujetas a las siguientes diferencias:
| Réplica principal de la región 1 | Réplica secundaria de la región 2 | Notas |
|---|---|---|
| Tabla de BigLake | Tabla de BigLake | No compatible. |
| Tabla externa | Tabla externa | Solo se replica la definición de la tabla externa. La consulta falla cuando el bucket de Cloud Storage no se encuentra en la misma ubicación que una réplica. |
| Vista lógica | Vista lógica | Las vistas lógicas que hacen referencia a un conjunto de datos o a un recurso que no se encuentran en la misma ubicación que ellas fallan cuando se consultan. |
| Tabla administrada | Tabla administrada | Ninguna diferencia |
| Vista materializada | Vista materializada | Si una tabla a la que se hace referencia no está en la misma región que la vista materializada, la consulta falla. Es posible que las vistas materializadas replicadas tengan una inactividad superior a la inactividad máxima de la vista. |
| Modelo | Modelo | Se almacenan como tablas administradas. |
| Función remota | Función remota | Las conexiones son regionales. Las funciones remotas que hacen referencia a un conjunto de datos o a un recurso (conexión) que no se encuentra en la misma ubicación que ellas fallan cuando se ejecutan. |
| Rutinas | Función definida por el usuario (UDF) o procedimiento almacenado | Las rutinas que hacen referencia a un conjunto de datos o a un recurso que no se encuentra en la misma ubicación que ellas fallan cuando se ejecutan. Cualquier rutina que haga referencia a una conexión, como las funciones remotas, no funciona fuera de la región de origen. |
| Política de acceso a las filas | Política de acceso a las filas | Ninguna diferencia |
| Índice de la Búsqueda | Índice de la Búsqueda | No replicado. |
| Procedimiento almacenado | Procedimiento almacenado | Los procedimientos almacenados que hacen referencia a un conjunto de datos o a un recurso que no se encuentran en la misma ubicación que estos fallan cuando se ejecutan. |
| Clonación de tabla | Tabla administrada | Se factura como una copia profunda en la réplica secundaria. |
| Resumen de la tabla | Resumen de la tabla | Se factura como una copia profunda en la réplica secundaria. |
| Función con valor de tabla (TVF) | TVF | Las TVF que hacen referencia a un conjunto de datos o a un recurso que no se encuentra en la misma ubicación que ellas fallan cuando se ejecutan. |
| UDF | UDF | Las UDF que hacen referencia a un conjunto de datos o un recurso que no se encuentra en la misma ubicación que ellas fallan cuando se ejecutan. |
Situaciones de interrupción
La replicación entre regiones no está diseñada para usarse como un plan de recuperación ante desastres durante una interrupción regional total. En el caso de una interrupción regional total en la región de la réplica principal, no puedes ascender la réplica secundaria. Debido a que las réplicas secundarias son de solo lectura, no puedes ejecutar ningún trabajo de escritura en la réplica secundaria ni puedes ascender la región secundaria hasta que se restablezca la región de la réplica principal. Si deseas obtener más información sobre cómo prepararte para la recuperación ante desastres, consulta Recuperación ante desastres administrada.
En la siguiente tabla, se explica el impacto de las interrupciones regionales en los datos replicados:
| Región 1 | Región 2 | Región de la interrupción | Impacto |
|---|---|---|---|
| Réplica principal | Réplica secundaria | Región 2 | Los trabajos de solo lectura que se ejecutan en la región 2 en la réplica secundaria fallan. |
| Réplica principal | Réplica secundaria | Región 1 | Todos los trabajos que se ejecutan en la región 1 fallan. Los trabajos de solo lectura continúan ejecutándose en la región 2, donde se encuentra la réplica secundaria. El contenido de la región 2 permanecerá inactivo hasta que se sincronice de forma correcta con la región 1. |
Usa la replicación de conjuntos de datos
En esta sección, se describe cómo replicar un conjunto de datos, promover la réplica secundaria y ejecutar trabajos de lectura de BigQuery en la región secundaria.
Permisos necesarios
Si deseas obtener los permisos que necesitas para administrar réplicas, pídele a tu administrador que te otorgue el permiso bigquery.datasets.update.
Replica un conjunto de datos
Para replicar un conjunto de datos, usa el ALTER SCHEMA ADD REPLICA de la declaración DDL.
Puedes agregar una réplica a cualquier conjunto de datos que aún no esté replicado en la región o multirregión en la que se encuentra. Cuando agregas una réplica, la operación de copia inicial tarda un tiempo en completarse. Puedes ejecutar consultas que hagan referencia a la réplica principal mientras se replican los datos, sin reducción en la capacidad de procesamiento de consultas. No puedes replicar datos dentro de las ubicaciones geográficas dentro de una multirregión.
En el siguiente ejemplo, se crea un conjunto de datos llamado my_dataset en la región us-central1 y, luego, se agrega una réplica en la región us-east4:
-- Create the primary replica in the us-central1 region. CREATE SCHEMA my_dataset OPTIONS(location='us-central1'); -- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `my_replica` OPTIONS(location='us-east4');
Para confirmar cuándo se creó la réplica secundaria de forma correcta, puedes consultar la columna creation_complete en la vista INFORMATION_SCHEMA.SCHEMATA_REPLICAS.
Después de crear la réplica secundaria, puedes consultarla configurando explícitamente la ubicación de la consulta en la región secundaria. Si no se establece una ubicación de forma explícita, BigQuery usa la región de la réplica principal del conjunto de datos.
Asciende la réplica secundaria
Si la región principal está en línea, puedes ascender la réplica secundaria. La promoción cambia la réplica secundaria para que sea la principal que admite escritura. Esta operación se completa en unos segundos si la réplica secundaria se sincronizó con la réplica principal. Si la réplica secundaria no se actualiza, la promoción no se podrá completar hasta que esté al día. La réplica secundaria no se puede ascender a la instancia principal si la región que contiene la instancia principal tiene una interrupción.
Ten en cuenta lo siguiente:
- Todas las operaciones de escritura en tablas muestran errores mientras la promoción está en proceso. Se bloquean inmediatamente las operaciones de escritura en réplica principal antigua cuando comienza la promoción.
- Las tablas que no se replican por completo en el momento en que se inicia la promoción muestran operaciones de lectura inactiva.
Para ascender una réplica a fin de que sea la réplica principal, usa la declaración DDL ALTER SCHEMA SET
OPTIONS y configura la opción primary_replica.
Ten en cuenta lo siguiente: Debes establecer de manera explícita la ubicación del trabajo como la región secundaria en la configuración de la consulta. Lee Especifica ubicaciones de BigQuery.
En el siguiente ejemplo, se asciende la réplica us-east4 para que sea la principal:
ALTER SCHEMA my_dataset SET OPTIONS(primary_replica = 'us-east4')
Para confirmar cuándo la réplica secundaria se asciende de forma correcta, puedes consultar la columna replica_primary_assignment_complete en la vista INFORMATION_SCHEMA.SCHEMATA_REPLICAS.
Quita una réplica de conjunto de datos
Para quitar una réplica y dejar de replicar el conjunto de datos, usa la sentencia DDL ALTER SCHEMA DROP REPLICA.
En el siguiente ejemplo, se quita la réplica us:
ALTER SCHEMA my_dataset DROP REPLICA IF EXISTS `us`;
Primero debes descartar cualquier réplica secundaria para borrar todo el conjunto de datos. Si borras todo el conjunto de datos, por ejemplo, mediante la sentencia DROP
SCHEMA, sin descartar todas las réplicas secundarias, recibirás el siguiente error:
The dataset replica of the cross region dataset 'project_id:dataset_id' in region 'REGION' is not yet writable because the primary assignment is not yet complete.
Para obtener más información, consulta Asciende la réplica secundaria.
Enumera réplicas de conjuntos de datos
Para enumerar las réplicas de conjuntos de datos en un proyecto, consulta la vista INFORMATION_SCHEMA.SCHEMATA_REPLICAS.
Migrar conjuntos de datos
Puedes usar la replicación de conjuntos de datos entre regiones para migrar tus conjuntos de datos de una región a otra. En el siguiente ejemplo, se muestra el proceso de migración del conjunto de datos my_migration existente de la multirregión US a la multirregión EU mediante la replicación entre regiones.
Replica el conjunto de datos
Para comenzar el proceso de migración, primero replica el conjunto de datos en la región a la que deseas migrar los datos. En este caso, debes migrar el conjunto de datos my_migration a la multirregión EU.
-- Create a replica in the secondary region. ALTER SCHEMA my_migration ADD REPLICA `eu` OPTIONS(location='eu');
Esto crea una réplica secundaria llamada eu en la multirregión EU.
La réplica principal es el conjunto de datos my_migration en la multirregión US.
Asciende la réplica secundaria
Para continuar con la migración del conjunto de datos a la multirregión EU, promueve la réplica secundaria:
ALTER SCHEMA my_migration SET OPTIONS(primary_replica = 'eu')
Una vez que se completa la promoción, eu es la réplica principal. Es una réplica que admite escritura.
Completa la migración
Para completar la migración de la multirregión US a la multirregión EU, borra la réplica us. Este paso no es obligatorio, pero es útil si no necesitas una réplica del conjunto de datos más allá de tus necesidades de migración.
ALTER SCHEMA my_migration DROP REPLICA IF EXISTS us;
Tu conjunto de datos se encuentra en la multirregión EU y no hay réplicas del conjunto de datos my_migration. Migraste correctamente tu conjunto de datos a la multirregión EU. La lista completa de los recursos que se migran se puede encontrar en Comportamiento de los recursos.
Claves de encriptación administradas por el cliente (CMEK)
Las claves de Cloud Key Management Service administradas por el cliente no se replican de forma automática cuando creas una réplica secundaria. Para mantener la encriptación en tu conjunto de datos replicados, debes configurar replica_kms_key para la ubicación de la réplica agregada. Puedes configurar replica_kms_key mediante la declaración DDL ALTER SCHEMA ADD REPLICA.
La replicación de conjuntos de datos con CMEK se comporta como se describe en las siguientes situaciones:
Si el conjunto de datos de origen tiene un
default_kms_key, debes proporcionar unreplica_kms_keyque se creó en la región del conjunto de datos de réplica cuando se usó la declaración DDLALTER SCHEMA ADD REPLICA.Si el conjunto de datos de origen no tiene un valor establecido para
default_kms_key, no puedes establecerreplica_kms_key.Si usas la rotación de claves de Cloud KMS en
default_kms_keyoreplica_kms_key, o ambas, el conjunto de datos replicado aún se puede consultar después de la rotación de claves.- La rotación de claves en la región principal actualiza la versión de clave solo en las tablas creadas después de la rotación. Las tablas que existían antes de la rotación de claves aún usan la versión de clave que se configuró antes de la rotación.
- La rotación de claves en la región secundaria actualiza todas las tablas en la réplica secundaria a la versión de clave nueva.
- Cuando cambias la réplica principal a la réplica secundaria, se actualizan todas las tablas en la réplica secundaria (antes conocida como la réplica principal) a la versión de clave nueva.
- Si se borra la versión de clave configurada en las tablas de la réplica principal antes de la rotación de claves, las tablas que aún usan la versión de clave establecida antes de la rotación de claves no se pueden consultar hasta que se actualice la versión de clave. Para actualizar la versión de clave, la versión anterior debe estar activa (no inhabilitada ni borrada).
Si el conjunto de datos de origen no tiene un valor establecido para
default_kms_key, pero hay tablas individuales en el conjunto de datos de origen con CMEK aplicadas, esas tablas no se pueden consultar en el conjunto de datos replicados. Para consultar las tablas, haz lo siguiente:- Agrega un valor
default_kms_keypara el conjunto de datos de origen. - Cuando crees una réplica nueva con la declaración DDL
ALTER SCHEMA ADD REPLICA, establece un valor para la opciónreplica_kms_key. Las tablas de CMEK se pueden consultar en la región de destino.
Todas las tablas de CMEK en la región de destino usan el mismo
replica_kms_key, sin importar la clave que se usa en la región de origen.- Agrega un valor
Crea una réplica con CMEK
En el siguiente ejemplo, se crea una réplica en la región us-west1 con un valor replica_kms_key configurado. En el caso de la clave CMEK, otorga el permiso de la cuenta de servicio de BigQuery para encriptar y desencriptar.
-- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `us-west1` OPTIONS(location='us-west1', replica_kms_key='my_us_west1_kms_key_name');
Limitaciones de CMEK
La replicación de conjuntos de datos con clave CMEK aplicada está sujeta a las siguientes limitaciones:
No puedes actualizar la clave replicada de Cloud KMS después de crear la réplica.
No puedes actualizar el valor
default_kms_keyen el conjunto de datos de origen después de crear las réplicas del conjunto de datos.Si el
replica_kms_keyproporcionado no es válido en la región de destino, el conjunto de datos no se replicará.
¿Qué sigue?
- Obtén información sobre cómo trabajar con reservas de BigQuery.
- Obtén más información sobre las funciones de confiabilidad de BigQuery.