Replicação de conjuntos de dados entre regiões
Com a replicação de conjuntos de dados do BigQuery, pode configurar a replicação automática de um conjunto de dados entre duas regiões ou multirregiões diferentes.
Vista geral
Quando cria um conjunto de dados no BigQuery, seleciona a região ou a multirregião onde os dados são armazenados. Uma região é uma coleção de centros de dados numa área geográfica, e uma multirregião é uma grande área geográfica que contém duas ou mais regiões geográficas. Os seus dados são armazenados numa das regiões contidas e não são replicados na região múltipla. Para mais informações sobre regiões e multirregiões, consulte o artigo Localizações do BigQuery.
O BigQuery armazena sempre cópias dos seus dados em duas Google Cloud zonas diferentes na localização do conjunto de dados. Uma zona é uma área de implementação para Google Cloud recursos numa região. Em todas as regiões, a replicação entre zonas usa escritas duplas síncronas. A seleção de uma localização multirregional não oferece replicação entre regiões nem redundância regional, pelo que não há aumento na disponibilidade do conjunto de dados em caso de interrupção regional. Os dados são armazenados numa única região na localização geográfica.
Para redundância geográfica adicional, pode replicar qualquer conjunto de dados. O BigQuery cria uma réplica secundária do conjunto de dados, localizada noutra região que especificar. Esta réplica é replicada de forma assíncrona entre duas zonas com a outra região, para um total de quatro cópias zonais.
Replicação do conjunto de dados
Se replicar um conjunto de dados, o BigQuery armazena os dados na região que especificar.
Região principal. Quando cria um conjunto de dados pela primeira vez, o BigQuery coloca-o na região principal.
Região secundária. Quando adiciona uma réplica de um conjunto de dados, o BigQuery coloca a réplica na região secundária.
Inicialmente, a réplica na região principal é a réplica principal e a réplica na região secundária é a réplica secundária.
A réplica principal é gravável e a réplica secundária é só de leitura. As escritas na réplica principal são replicadas de forma assíncrona para a réplica secundária. Em cada região, os dados são armazenados de forma redundante em duas zonas. O tráfego de rede nunca sai da rede Google Cloud .
O diagrama seguinte mostra a replicação que ocorre quando um conjunto de dados é replicado:
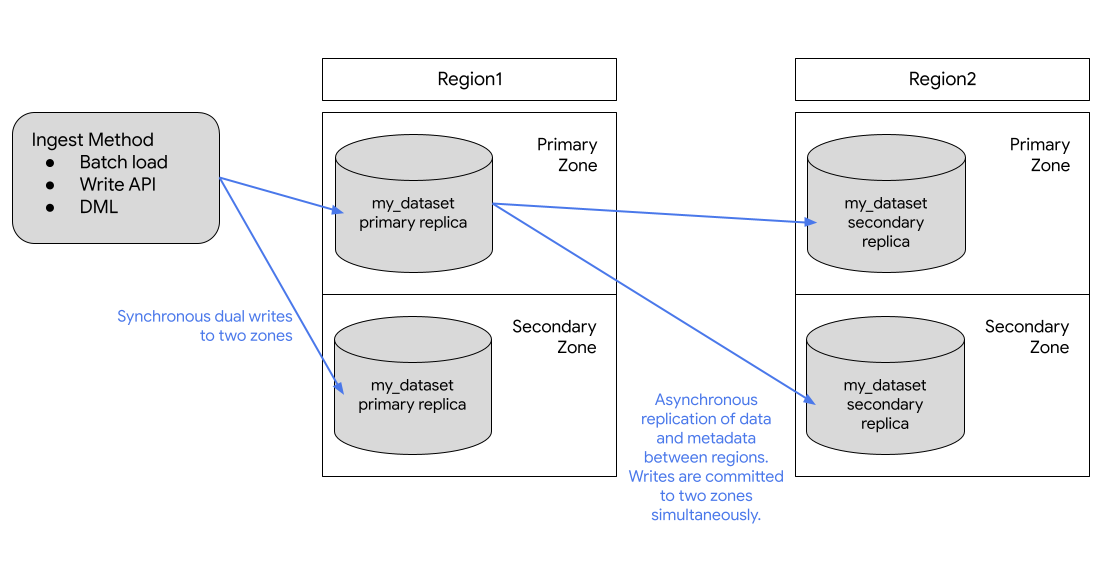
Se a região principal estiver online, pode mudar manualmente para a réplica secundária. Para mais informações, consulte o artigo Promova a réplica secundária.
Preços
A faturação dos conjuntos de dados replicados é feita com base no seguinte:
- Armazenamento. Os bytes de armazenamento na região secundária são faturados como uma cópia separada na região secundária. Consulte os preços do armazenamento do BigQuery.
- Replicação de dados. Para mais informações sobre a faturação da replicação de dados, consulte os preços da replicação de dados.
A replicação de dados é gerida pelo BigQuery e não usa os seus recursos de slots. A replicação de dados é faturada separadamente.
Calcule a capacidade na região secundária
Para executar tarefas e consultas na réplica na região secundária, tem de comprar slots na região secundária ou executar uma consulta a pedido.
Pode usar as ranhuras para executar consultas de leitura apenas a partir da réplica secundária. Se promover a réplica secundária para principal, também pode usar essas posições para escrever na réplica.
Pode comprar o mesmo número de espaços que tem na região principal ou um número diferente de espaços. Se comprar menos espaços, pode afetar o desempenho das consultas.
Considerações sobre a localização
Antes de adicionar uma réplica do conjunto de dados, tem de criar o conjunto de dados inicial que quer replicar no BigQuery, se ainda não existir. A localização da réplica adicionada é definida para a localização que especificar quando adicionar a réplica. A localização da réplica adicionada tem de ser diferente da localização do conjunto de dados inicial. Isto significa que os dados no seu conjunto de dados são replicados continuamente entre a localização em que o conjunto de dados foi criado e a localização da réplica. Para réplicas que requerem colocação conjunta, como vistas, vistas materializadas ou tabelas externas não BigLake, adicionar uma réplica numa localização diferente ou não compatível com a localização dos dados de origem pode resultar em erros de tarefas.
Quando os clientes replicam um conjunto de dados em várias regiões, o BigQuery garante que os dados estão localizados apenas nas localizações onde as réplicas foram criadas.
Requisitos de colocação
A utilização da replicação de conjuntos de dados depende dos seguintes requisitos de colocação.
Cloud Storage
A consulta de dados no Cloud Storage requer que o contentor do Cloud Storage esteja localizado juntamente com a réplica. Use as considerações sobre a localização das tabelas externas quando decidir onde colocar a réplica.
Limitações
A replicação do conjunto de dados do BigQuery está sujeita às seguintes limitações:
- Os dados de streaming escritos na réplica principal a partir da
API BigQuery Storage Write ou do método
tabledata.insertAll, que são replicados na réplica secundária, são de melhor esforço e podem ter um elevado atraso na replicação. - As inserções/atualizações por streaming escritas na réplica principal a partir do
Datastream ou da
captura de dados de alterações do BigQuery,
que são replicadas na réplica secundária, são de melhor esforço e podem
apresentar um elevado atraso na replicação. Após a replicação, as inserções/atualizações na réplica secundária são unidas na base de referência da tabela da réplica secundária de acordo com o valor
max_stalenessconfigurado da tabela. - Não pode ativar o DML detalhado numa tabela num conjunto de dados replicado, e não pode replicar um conjunto de dados que contenha uma tabela com o DML detalhado ativado.
- A replicação e a comutação são geridas através de declarações de linguagem de definição de dados (LDD) SQL.
- Está limitado a uma réplica de cada conjunto de dados para cada região ou multirregião. Não pode criar duas réplicas secundárias do mesmo conjunto de dados na mesma região de destino.
- Os recursos nas réplicas estão sujeitos às limitações descritas em Comportamento dos recursos.
- As etiquetas de políticas e as políticas de dados associadas não são replicadas para a réplica secundária. Todas as consultas que referenciam colunas com etiquetas de políticas em regiões que não sejam a região original falham, mesmo que essa réplica seja promovida.
- A viagem no tempo só está disponível na réplica secundária após a conclusão da criação da réplica secundária.
- O limite de tamanho da região de destino para ativar a replicação entre regiões num conjunto de dados é de 10 PB para
useeuvárias regiões e 500 TB para outras regiões por predefinição. Estes limites são configuráveis. Para mais informações, contacte o Google Cloud apoio técnico. - A quota aplica-se a recursos lógicos.
- Só pode replicar um conjunto de dados com menos de 100 000 tabelas.
- Tem um limite máximo de 4 réplicas adicionadas (e, em seguida, eliminadas) à mesma região por conjunto de dados por dia.
- Está limitado pela largura de banda.
- As tabelas com chaves de encriptação geridas pelo cliente (CMEK) aplicadas não são consultáveis na região secundária se o valor
replica_kms_keynão estiver configurado. - As tabelas do BigLake não são suportadas.
- Não pode replicar conjuntos de dados externos ou federados.
- As localizações do BigQuery Omni não são suportadas.
- Não pode configurar os seguintes pares de regiões se estiver a configurar a replicação de dados para recuperação de desastres:
us-central1-usmultirregiãous-west1-usmultirregiãoeu-west1-eumultirregiãoeu-west4-eumultirregião
- Não é possível replicar os controlos de acesso ao nível da rotina, mas pode replicar os controlos de acesso ao nível do conjunto de dados para rotinas.
Comportamento dos recursos
As seguintes operações não são suportadas em recursos na réplica secundária:
A réplica secundária é só de leitura. Se precisar de criar uma cópia de um recurso numa réplica secundária, tem de copiar o recurso ou consultar o recurso primeiro e, em seguida, materializar os resultados fora da réplica secundária. Por exemplo, use CREATE TABLE AS SELECT para criar um novo recurso a partir do recurso de réplica secundária.
As réplicas principais e secundárias estão sujeitas às seguintes diferenças:
| Réplica principal da região 1 | Réplica secundária da região 2 | Notas |
|---|---|---|
| Tabela do BigLake | Tabela do BigLake | Não suportado. |
| Tabela externa | Tabela externa | Apenas a definição da tabela externa é replicada. A consulta falha quando o contentor do Cloud Storage não está localizado na mesma localização que uma réplica. |
| Vista lógica | Vista lógica | As vistas lógicas que fazem referência a um conjunto de dados ou a um recurso que não se encontra na mesma localização que a vista lógica falham quando são consultadas. |
| Tabela gerida | Tabela gerida | Não existe qualquer diferença. |
| Vista materializada | Vista materializada | Se uma tabela referenciada não estiver na mesma região que a vista materializada, a consulta falha. As vistas materializadas replicadas podem apresentar desatualização acima da desatualização máxima da vista. |
| Modelo | Modelo | Armazenados como tabelas geridas. |
| Função remota | Função remota | As ligações são regionais. As funções remotas que fazem referência a um conjunto de dados ou a um recurso (ligação) que não se encontra na mesma localização que a função remota falham quando são executadas. |
| Rotinas | Função definida pelo utilizador (FDU) ou procedimento armazenado | As rotinas que fazem referência a um conjunto de dados ou a um recurso que não se encontra na mesma localização que a rotina falham quando são executadas. Qualquer rotina que faça referência a uma ligação, como funções remotas, não funciona fora da região de origem. |
| Política de acesso ao nível da linha | Política de acesso ao nível da linha | Não existe qualquer diferença. |
| Índice de pesquisa | Índice de pesquisa | Não replicado. |
| Procedimento armazenado | Procedimento armazenado | Os procedimentos armazenados que fazem referência a um conjunto de dados ou a um recurso que não se encontra na mesma localização que o procedimento armazenado falham quando são executados. |
| Clonagem de tabelas | Tabela gerida | Faturado como uma cópia detalhada na réplica secundária. |
| Instantâneo da tabela | Instantâneo da tabela | Faturado como uma cópia detalhada na réplica secundária. |
| Função de valor de tabela (TVF) | TVF | As FTVs que fazem referência a um conjunto de dados ou a um recurso que não se encontra na mesma localização que a FTV falham quando são executadas. |
| FDU | FDU | As FDU que fazem referência a um conjunto de dados ou a um recurso que não se encontra na mesma localização que a FDU falham quando são executadas. |
Cenários de indisponibilidade
A replicação entre regiões não se destina a ser usada como um plano de recuperação de desastres durante uma indisponibilidade total da região. No caso de uma indisponibilidade total da região na região da réplica principal, não pode promover a réplica secundária. Uma vez que as réplicas secundárias são só de leitura, não pode executar tarefas de escrita na réplica secundária e não pode promover a região secundária até que a região da réplica principal seja restaurada. Para mais informações sobre a preparação para a recuperação de desastres, consulte o artigo Recuperação de desastres gerida.
A tabela seguinte explica o impacto das indisponibilidades totais da região nos seus dados replicados:
| Região 1 | Região 2 | Região de indisponibilidade | Impacto |
|---|---|---|---|
| Réplica principal | Réplica secundária | Região 2 | As tarefas de leitura executadas na região 2 em relação à réplica secundária falham. |
| Réplica principal | Réplica secundária | Região 1 | Todas as tarefas executadas na região 1 falham. As tarefas de leitura continuam a ser executadas na região 2, onde se encontra a réplica secundária. O conteúdo da região 2 está desatualizado até ser sincronizado com êxito com a região 1. |
Use a replicação de conjuntos de dados
Esta secção descreve como replicar um conjunto de dados, promover a réplica secundária e executar tarefas de leitura do BigQuery na região secundária.
Autorizações necessárias
Para receber as autorizações necessárias para gerir réplicas, peça ao seu administrador
para lhe conceder a autorização bigquery.datasets.update.
Replique um conjunto de dados
Para replicar um conjunto de dados, use a declaração DDL ALTER SCHEMA ADD REPLICA.
Pode adicionar uma réplica a qualquer conjunto de dados localizado numa região ou multirregião que ainda não tenha sido replicado nessa região ou multirregião. Depois de adicionar uma réplica, a operação de cópia inicial demora algum tempo a ser concluída. Ainda pode executar consultas que referenciam a réplica principal enquanto os dados estão a ser replicados, sem redução na capacidade de processamento de consultas. Não pode replicar dados nas geolocalizações numa região múltipla.
O exemplo seguinte cria um conjunto de dados denominado my_dataset na região us-central1
e, em seguida, adiciona uma réplica na região us-east4:
-- Create the primary replica in the us-central1 region. CREATE SCHEMA my_dataset OPTIONS(location='us-central1'); -- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `my_replica` OPTIONS(location='us-east4');
Para confirmar quando a réplica secundária foi criada com êxito, pode consultar a coluna creation_complete na vista INFORMATION_SCHEMA.SCHEMATA_REPLICAS.
Depois de criar a réplica secundária, pode consultá-la definindo explicitamente a localização da consulta para a região secundária. Se uma localização não for definida explicitamente, o BigQuery usa a região da réplica principal do conjunto de dados.
Promova a réplica secundária
Se a região principal estiver online, pode promover a réplica secundária. A promoção muda a réplica secundária para a principal gravável. Esta operação é concluída em poucos segundos se a réplica secundária estiver atualizada com a réplica principal. Se a réplica secundária não estiver atualizada, a promoção não pode ser concluída até estar atualizada. Não é possível promover a réplica secundária a principal se a região que contém a principal tiver uma indisponibilidade.
Tenha em conta o seguinte:
- Todas as escritas em tabelas devolvem erros enquanto a promoção está em processamento. A réplica principal antiga deixa de ser gravável imediatamente quando a promoção começa.
- As tabelas que não são totalmente replicadas no momento em que a promoção é iniciada devolvem leituras desatualizadas.
Para promover uma réplica para ser a réplica principal, use a declaração DDL ALTER SCHEMA SET
OPTIONS e defina a opção primary_replica.
Tenha em atenção o seguinte: - Tem de definir explicitamente a localização do trabalho para a região secundária nas definições da consulta. Consulte o artigo Especificar localizações do BigQuery.
O exemplo seguinte promove a réplica us-east4 para ser a principal:
ALTER SCHEMA my_dataset SET OPTIONS(primary_replica = 'us-east4')
Para confirmar quando a réplica secundária foi promovida com êxito, pode consultar a coluna replica_primary_assignment_complete na vista INFORMATION_SCHEMA.SCHEMATA_REPLICAS.
Remova uma réplica do conjunto de dados
Para remover uma réplica e parar de replicar o conjunto de dados, use a declaração DDL ALTER SCHEMA DROP REPLICA.
O exemplo seguinte remove a réplica us:
ALTER SCHEMA my_dataset DROP REPLICA IF EXISTS `us`;
Primeiro, tem de eliminar todas as réplicas secundárias para eliminar o conjunto de dados completo. Se eliminar o conjunto de dados completo, por exemplo, através da declaração DROP
SCHEMA, sem eliminar todas as réplicas secundárias, recebe o seguinte erro:
The dataset replica of the cross region dataset 'project_id:dataset_id' in region 'REGION' is not yet writable because the primary assignment is not yet complete.
Para mais informações, consulte o artigo Promova a réplica secundária.
Apresente réplicas do conjunto de dados
Para listar as réplicas do conjunto de dados num projeto, consulte a vista
INFORMATION_SCHEMA.SCHEMATA_REPLICAS.
Migre conjuntos de dados
Pode usar a replicação de conjuntos de dados entre regiões para migrar os seus conjuntos de dados de uma região para outra. O exemplo seguinte demonstra o processo de migração do conjunto de dados my_migration existente da região US multirregional para a região EU multirregional através da replicação entre regiões.
Replique o conjunto de dados
Para iniciar o processo de migração, primeiro, replique o conjunto de dados na região para a qual quer migrar os dados. Neste cenário, está a migrar o conjunto de dados my_migration para a região múltipla EU.
-- Create a replica in the secondary region. ALTER SCHEMA my_migration ADD REPLICA `eu` OPTIONS(location='eu');
Esta ação cria uma réplica secundária denominada eu na multirregião EU.
A réplica principal é o conjunto de dados my_migration na multirregião US.
Promova a réplica secundária
Para continuar a migrar o conjunto de dados para a EU multirregião, promova a réplica secundária:
ALTER SCHEMA my_migration SET OPTIONS(primary_replica = 'eu')
Após a conclusão da promoção, eu é a réplica principal. É uma réplica
gravável.
Conclua a migração
Para concluir a migração da US multirregião para a EU multirregião,
elimine a réplica us. Este passo não é obrigatório, mas é útil se não
precisar de uma réplica do conjunto de dados além das suas necessidades de migração.
ALTER SCHEMA my_migration DROP REPLICA IF EXISTS us;
O seu conjunto de dados está localizado na multirregião EU e não existem réplicas do conjunto de dados my_migration. Migrou com êxito o seu conjunto de dados para a
EU multirregião. Pode encontrar a lista completa de recursos migrados em Comportamento dos recursos.
Chaves de encriptação geridas pelo cliente (CMEK)
As chaves do Cloud Key Management Service geridas pelo cliente
não são replicadas automaticamente quando cria uma réplica secundária. Para manter a encriptação no conjunto de dados replicado, tem de definir o
replica_kms_key para a localização da réplica adicionada. Pode definir o
replica_kms_key através da declaração DDL ALTER SCHEMA ADD REPLICA.
A replicação de conjuntos de dados com CMEK comporta-se conforme descrito nos seguintes cenários:
Se o conjunto de dados de origem tiver um
default_kms_key, tem de fornecer umreplica_kms_keyque tenha sido criado na região do conjunto de dados da réplica quando usar a declaração DDLALTER SCHEMA ADD REPLICA.Se o conjunto de dados de origem não tiver um valor definido para
default_kms_key, não pode definir o valor dereplica_kms_key.Se estiver a usar a rotação de chaves do Cloud KMS no
default_kms_keyou noreplica_kms_key(ou em ambos), o conjunto de dados replicado continua a ser consultável após a rotação de chaves.- A rotação de chaves na região principal atualiza a versão da chave apenas nas tabelas criadas após a rotação. As tabelas existentes antes da rotação de chaves continuam a usar a versão da chave definida antes da rotação.
- A alteração da chave na região secundária atualiza todas as tabelas na réplica secundária para a nova versão da chave.
- A mudança da réplica principal para a réplica secundária atualiza todas as tabelas na réplica secundária (anteriormente a réplica principal) para a nova versão da chave.
- Se a versão da chave definida nas tabelas na réplica principal antes da rotação de chaves for eliminada, não é possível consultar as tabelas que ainda usam a versão da chave definida antes da rotação de chaves até que a versão da chave seja atualizada. Para atualizar a versão da chave, a versão antiga da chave tem de estar ativa (não desativada nem eliminada).
Se o conjunto de dados de origem não tiver um valor definido para
default_kms_key, mas existirem tabelas individuais no conjunto de dados de origem com a CMEK aplicada, essas tabelas não podem ser consultadas no conjunto de dados replicado. Para consultar as tabelas, faça o seguinte:- Adicione um valor de
default_kms_keypara o conjunto de dados de origem. - Quando cria uma nova réplica através da declaração DDL, defina um valor para a opção
replica_kms_key.ALTER SCHEMA ADD REPLICAAs tabelas CMEK são consultáveis na região de destino.
Todas as tabelas de CMEK na região de destino usam o mesmo
replica_kms_key, independentemente da chave usada na região de origem.- Adicione um valor de
Crie uma réplica com CMEK
O exemplo seguinte cria uma réplica na região us-west1 com um valor replica_kms_key definido. Para a chave CMEK, conceda autorização à conta de serviço do BigQuery para encriptar e desencriptar.
-- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `us-west1` OPTIONS(location='us-west1', replica_kms_key='my_us_west1_kms_key_name');
Limitações da CMEK
A replicação de conjuntos de dados com a CMEK aplicada está sujeita às seguintes limitações:
Não pode atualizar a chave do Cloud KMS replicada depois de criar a réplica.
Não pode atualizar o valor
default_kms_keyno conjunto de dados de origem após a criação das réplicas do conjunto de dados.Se o
replica_kms_keyfornecido não for válido na região de destino, o conjunto de dados não é replicado.
O que se segue?
- Saiba como trabalhar com reservas do BigQuery.
- Saiba mais acerca das funcionalidades de fiabilidade do BigQuery.