Réplica de conjuntos de datos entre regiones
Con la replicación de conjuntos de datos de BigQuery, puedes configurar la replicación automática de un conjunto de datos entre dos regiones o multirregiones diferentes.
Información general
Cuando creas un conjunto de datos en BigQuery, seleccionas la región o la multirregión en la que se almacenan los datos. Una región es un conjunto de centros de datos que se encuentran en una zona geográfica, mientras que una multirregión es una zona geográfica amplia que contiene dos o más regiones geográficas. Tus datos se almacenan en una de las regiones incluidas y no se replican en la multirregión. Para obtener más información sobre las regiones y las multirregiones, consulta Ubicaciones de BigQuery.
BigQuery siempre almacena copias de tus datos en dosGoogle Cloud zonas diferentes dentro de la ubicación del conjunto de datos. Una zona es un área de implementación de recursos Google Cloud dentro de una región. En todas las regiones, la replicación entre zonas usa escrituras duales síncronas. Si seleccionas una ubicación multirregional, no se proporciona replicación entre regiones ni redundancia regional, por lo que no aumenta la disponibilidad del conjunto de datos en caso de que se produzca una interrupción regional. Los datos se almacenan en una sola región dentro de la ubicación geográfica.
Para disfrutar de una redundancia geográfica adicional, puedes replicar cualquier conjunto de datos. BigQuery crea una réplica secundaria del conjunto de datos, ubicada en otra región que especifiques. Esta réplica se replica de forma asíncrona entre dos zonas de la otra región, lo que da un total de cuatro copias zonales.
Replicación de conjuntos de datos
Si replicas un conjunto de datos, BigQuery almacenará los datos en la región que especifiques.
Región principal. Cuando creas un conjunto de datos por primera vez, BigQuery lo coloca en la región principal.
Región secundaria. Cuando añade una réplica de un conjunto de datos, BigQuery la coloca en la región secundaria.
Inicialmente, la réplica de la región principal es la réplica principal y la réplica de la región secundaria es la réplica secundaria.
La réplica principal es de escritura y la secundaria es de solo lectura. Las escrituras en la réplica principal se replican de forma asíncrona en la réplica secundaria. En cada región, los datos se almacenan de forma redundante en dos zonas. El tráfico de red nunca sale de la red Google Cloud .
En el siguiente diagrama se muestra la replicación que se produce cuando se replica un conjunto de datos:
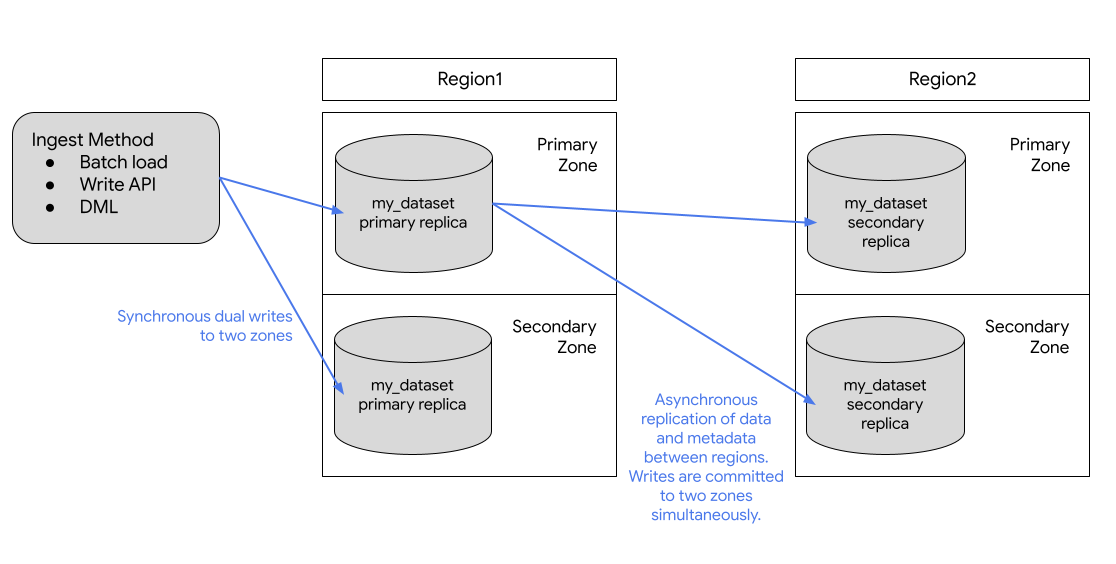
Si la región principal está online, puedes cambiar manualmente a la réplica secundaria. Para obtener más información, consulta Promover la réplica secundaria.
Precios
Se te factura lo siguiente por los conjuntos de datos replicados:
- Almacenamiento Los bytes de almacenamiento de la región secundaria se facturan como una copia independiente en la región secundaria. Consulta los precios del almacenamiento de BigQuery.
- Replicación de datos. Para obtener más información sobre cómo se te factura la replicación de datos, consulta los precios de replicación de datos.
BigQuery gestiona la réplica de datos y no utiliza tus recursos de ranura. La replicación de datos se factura por separado.
Capacidad de computación en la región secundaria
Para ejecutar trabajos y consultas en la réplica de la región secundaria, debes comprar ranuras en la región secundaria o ejecutar una consulta bajo demanda.
Puedes usar las ranuras para realizar consultas de solo lectura desde la réplica secundaria. Si asciendes la réplica secundaria a primaria, también puedes usar esas ranuras para escribir en la réplica.
Puedes comprar el mismo número de ranuras que tienes en la región principal o un número diferente. Si compras menos ranuras, puede que se vea afectado el rendimiento de las consultas.
Consideraciones de ubicación
Antes de añadir una réplica de un conjunto de datos, debes crear el conjunto de datos inicial que quieras replicar en BigQuery si aún no existe. La ubicación de la réplica añadida se define como la ubicación que especifiques al añadir la réplica. La ubicación de la réplica añadida debe ser diferente a la del conjunto de datos inicial. Esto significa que los datos de tu conjunto de datos se replican continuamente entre la ubicación en la que se creó el conjunto de datos y la ubicación de la réplica. En el caso de las réplicas que requieren colocación, como las vistas, las vistas materializadas o las tablas externas que no son de BigLake, si se añade una réplica en una ubicación que sea diferente o no compatible con la ubicación de los datos de origen, se pueden producir errores en los trabajos.
Cuando los clientes replican un conjunto de datos en varias regiones, BigQuery se asegura de que los datos solo se encuentren en las ubicaciones en las que se crearon las réplicas.
Requisitos de colocación
Para usar la replicación de conjuntos de datos, debes cumplir los siguientes requisitos de colocación.
Cloud Storage
Para consultar datos en Cloud Storage, el segmento de Cloud Storage debe estar ubicado en el mismo lugar que la réplica. Ten en cuenta las consideraciones sobre la ubicación de las tablas externas cuando decidas dónde colocar tu réplica.
Limitaciones
La replicación de conjuntos de datos de BigQuery está sujeta a las siguientes limitaciones:
- Los datos de streaming escritos en la réplica principal desde la API Storage Write de BigQuery o el método
tabledata.insertAll, que luego se replican en la réplica secundaria, se replican de la mejor forma posible y pueden experimentar un retraso de replicación elevado. - Las inserciones y actualizaciones de flujos escritas en la réplica principal desde Datastream o la captura de datos de cambios de BigQuery, que luego se replica en la réplica secundaria, se realizan con el mejor esfuerzo posible y pueden experimentar un retraso de replicación elevado. Una vez replicadas, las inserciones y actualizaciones de la réplica secundaria se combinan con la base de la tabla de la réplica secundaria según el valor
max_stalenessconfigurado de la tabla. - No puedes habilitar DML detallado en una tabla de un conjunto de datos replicado, ni replicar un conjunto de datos que contenga una tabla con DML detallado habilitado.
- La replicación y el cambio se gestionan mediante instrucciones del lenguaje de definición de datos (DDL) de SQL.
- Solo puedes tener una réplica de cada conjunto de datos por región o multirregión. No puedes crear dos réplicas secundarias del mismo conjunto de datos en la misma región de destino.
- Los recursos de las réplicas están sujetos a las limitaciones descritas en la sección Comportamiento de los recursos.
- Las etiquetas de política y las políticas de datos asociadas no se replican en la réplica secundaria. Las consultas que hagan referencia a columnas con etiquetas de política en regiones distintas de la región original fallarán, aunque se promueva esa réplica.
- La función de viaje en el tiempo solo está disponible en la réplica secundaria una vez que se haya completado su creación.
- El límite de tamaño de la región de destino para habilitar la replicación entre regiones en un conjunto de datos es de 10 PB para las
usyeumultirregiones y de 500 TB para otras regiones de forma predeterminada. Estos límites se pueden configurar. Para obtener más información, ponte en contacto con el equipo de Google Cloud Asistencia. - La cuota se aplica a los recursos lógicos.
- Solo puedes replicar un conjunto de datos que tenga menos de 100.000 tablas.
- Puedes añadir (y luego eliminar) un máximo de 4 réplicas a la misma región por conjunto de datos al día.
- Estás limitado por el ancho de banda.
- Las tablas a las que se les ha aplicado cifrado gestionado por el cliente (CMEK) no se pueden consultar en la región secundaria si no se ha configurado el valor
replica_kms_key. - No se admiten tablas BigLake.
- No puedes replicar conjuntos de datos externos o federados.
- No se admiten las ubicaciones de BigQuery Omni.
- No puedes configurar los siguientes pares de regiones si estás configurando la replicación de datos para la recuperación tras desastres:
us-central1-usmultirregiónus-west1-usmultirregióneu-west1-eumultirregióneu-west4-eumultirregión
- Los controles de acceso a nivel de rutina no se pueden replicar, pero sí los controles de acceso a nivel de conjunto de datos de las rutinas.
Comportamiento de los recursos
No se admiten las siguientes operaciones en los recursos de la réplica secundaria:
La réplica secundaria es de solo lectura. Si necesitas crear una copia de un recurso en una réplica secundaria, debes copiar el recurso o consultar el recurso primero y, a continuación, materializar los resultados fuera de la réplica secundaria. Por ejemplo, usa CREATE TABLE AS SELECT para crear un recurso a partir del recurso de réplica secundaria.
Las réplicas principales y secundarias están sujetas a las siguientes diferencias:
| Réplica principal de la región 1 | Réplica secundaria de la región 2 | Notas |
|---|---|---|
| Tabla de BigLake | Tabla de BigLake | No es compatible. |
| Tabla externa | Tabla externa | Solo se replica la definición de la tabla externa. La consulta falla cuando el segmento de Cloud Storage no está en la misma ubicación que una réplica. |
| Vista lógica | Vista lógica | Las vistas lógicas que hacen referencia a un conjunto de datos o a un recurso que no se encuentra en la misma ubicación que la vista lógica fallan cuando se consultan. |
| Tabla gestionada | Tabla gestionada | No hay ninguna diferencia. |
| Vista materializada | Vista materializada | Si una tabla a la que se hace referencia no está en la misma región que la vista materializada, la consulta falla. Las vistas materializadas replicadas pueden tener una antigüedad superior a la antigüedad máxima de la vista. |
| Modelo | Modelo | Se almacenan como tablas gestionadas. |
| Función remota | Función remota | Las conexiones son regionales. Las funciones remotas que hacen referencia a un conjunto de datos o a un recurso (conexión) que no se encuentra en la misma ubicación que la función remota fallan al ejecutarse. |
| Rutinas | Función definida por el usuario (UDF) o procedimiento almacenado | Las rutinas que hacen referencia a un conjunto de datos o a un recurso que no se encuentra en la misma ubicación que la rutina fallan al ejecutarse. Las rutinas que hacen referencia a una conexión, como las funciones remotas, no funcionan fuera de la región de origen. |
| Política de acceso a filas | Política de acceso a filas | No hay ninguna diferencia. |
| Índice de búsqueda | Índice de búsqueda | No se ha replicado. |
| Procedimiento almacenado | Procedimiento almacenado | Los procedimientos almacenados que hacen referencia a un conjunto de datos o a un recurso que no se encuentra en la misma ubicación que el procedimiento almacenado fallan al ejecutarse. |
| Clon de tabla | Tabla gestionada | Se factura como una copia profunda en la réplica secundaria. |
| Captura de tabla | Captura de tabla | Se factura como una copia profunda en la réplica secundaria. |
| Función con valores de tabla (TVF) | TVF | Las funciones con valores de tabla que hacen referencia a un conjunto de datos o a un recurso que no se encuentra en la misma ubicación que la función con valores de tabla fallan al ejecutarse. |
| FDU | FDU | Las FDU que hacen referencia a un conjunto de datos o a un recurso que no se encuentra en la misma ubicación que la FDU fallan al ejecutarse. |
Situaciones de interrupción del servicio
La replicación entre regiones no está pensada para utilizarse como plan de recuperación tras fallos durante una interrupción total del servicio en una región. En caso de que se produzca una interrupción total en la región de la réplica principal, no podrás promover la réplica secundaria. Como las réplicas secundarias son de solo lectura, no puedes ejecutar ningún trabajo de escritura en la réplica secundaria ni promover la región secundaria hasta que se restaure la región de la réplica principal. Para obtener más información sobre cómo prepararse para la recuperación tras fallos, consulte Recuperación tras fallos gestionada.
En la siguiente tabla se explica el impacto de las interrupciones en toda la región en los datos replicados:
| Región 1 | Región 2 | Región de interrupción del servicio | Impacto |
|---|---|---|---|
| Réplica principal | Réplica secundaria | Región 2 | Las tareas de solo lectura que se ejecutan en la región 2 en la réplica secundaria fallan. |
| Réplica principal | Réplica secundaria | Región 1 | Todos los trabajos que se ejecutan en la región 1 fallan. Los trabajos de solo lectura siguen ejecutándose en la región 2, donde se encuentra la réplica secundaria. El contenido de la región 2 no estará actualizado hasta que se sincronice correctamente con la región 1. |
Usar la replicación de conjuntos de datos
En esta sección se describe cómo replicar un conjunto de datos, promover la réplica secundaria y ejecutar tareas de lectura de BigQuery en la región secundaria.
Permisos obligatorios
Para obtener los permisos que necesitas para gestionar réplicas, pide a tu administrador que te conceda el permiso bigquery.datasets.update.
Replicar un conjunto de datos
Para replicar un conjunto de datos, usa la ALTER SCHEMA ADD REPLICAdeclaración de DDL.
Puedes añadir una réplica a cualquier conjunto de datos que se encuentre en una región o multirregión que no esté replicado en esa región o multirregión. Después de añadir una réplica, la operación de copia inicial tarda un tiempo en completarse. Puedes seguir ejecutando consultas que hagan referencia a la réplica principal mientras se replican los datos, sin que se reduzca la capacidad de procesamiento de las consultas. No puedes replicar datos en las ubicaciones geográficas de una multirregión.
En el siguiente ejemplo se crea un conjunto de datos llamado my_dataset en la región us-central1 y, a continuación, se añade una réplica en la región us-east4:
-- Create the primary replica in the us-central1 region. CREATE SCHEMA my_dataset OPTIONS(location='us-central1'); -- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `my_replica` OPTIONS(location='us-east4');
Para confirmar cuándo se ha creado correctamente la réplica secundaria, puedes consultar la columna creation_complete en la vista INFORMATION_SCHEMA.SCHEMATA_REPLICAS.
Una vez que se haya creado la réplica secundaria, podrá consultarla definiendo explícitamente la ubicación de la consulta en la región secundaria. Si no se define una ubicación de forma explícita, BigQuery usa la región de la réplica principal del conjunto de datos.
Promocionar la réplica secundaria
Si la región principal está online, puedes promover la réplica secundaria. La promoción cambia la réplica secundaria para que sea la principal con permisos de escritura. Esta operación se completa en unos segundos si la réplica secundaria está al día con la réplica principal. Si la réplica secundaria no está actualizada, la promoción no se puede completar hasta que lo esté. La réplica secundaria no se puede convertir en principal si la región que contiene la principal sufre una interrupción.
Ten en cuenta lo siguiente:
- Todas las escrituras en tablas devuelven errores mientras se está procesando la promoción. La réplica principal antigua deja de ser grabable inmediatamente cuando empieza la promoción.
- Las tablas que no se hayan replicado por completo en el momento en que se inicie la promoción devolverán lecturas obsoletas.
Para promover una réplica a réplica principal, usa la ALTER SCHEMA SET
OPTIONS instrucción DDL
y define la opción primary_replica.
Ten en cuenta lo siguiente: - Debes definir explícitamente la ubicación del trabajo en la región secundaria en los ajustes de la consulta. Consulta Especificar ubicaciones de BigQuery.
En el siguiente ejemplo se asciende la réplica us-east4 a principal:
ALTER SCHEMA my_dataset SET OPTIONS(primary_replica = 'us-east4')
Para confirmar cuándo se ha ascendido correctamente la réplica secundaria, puedes consultar la columna replica_primary_assignment_complete de la vista INFORMATION_SCHEMA.SCHEMATA_REPLICAS.
Eliminar una réplica de un conjunto de datos
Para quitar una réplica y dejar de replicar el conjunto de datos, usa la ALTER SCHEMA DROP REPLICA instrucción DDL.
En el siguiente ejemplo se elimina la réplica us:
ALTER SCHEMA my_dataset DROP REPLICA IF EXISTS `us`;
Primero debes eliminar todas las réplicas secundarias para eliminar todo el conjunto de datos. Si elimina todo el conjunto de datos (por ejemplo, mediante la instrucción DROP
SCHEMA) sin eliminar todas las réplicas secundarias, recibirá el siguiente error:
The dataset replica of the cross region dataset 'project_id:dataset_id' in region 'REGION' is not yet writable because the primary assignment is not yet complete.
Para obtener más información, consulta Promover la réplica secundaria.
Mostrar réplicas de conjuntos de datos
Para ver una lista de las réplicas de conjuntos de datos de un proyecto, consulta la vista INFORMATION_SCHEMA.SCHEMATA_REPLICAS.
Migrar conjuntos de datos
Puede usar la réplica de conjuntos de datos entre regiones para migrar sus conjuntos de datos de una región a otra. En el siguiente ejemplo se muestra el proceso de migración del conjunto de datos my_migration de la multirregión US a la multirregión EU mediante la réplica entre regiones.
Replicar el conjunto de datos
Para iniciar el proceso de migración, primero replica el conjunto de datos en la región a la que quieras migrar los datos. En este caso, vas a migrar el conjunto de datos my_migration a la multirregión EU.
-- Create a replica in the secondary region. ALTER SCHEMA my_migration ADD REPLICA `eu` OPTIONS(location='eu');
De esta forma, se crea una réplica secundaria llamada eu en la multirregión EU.
La réplica principal es el conjunto de datos my_migration de la multirregión US.
Promocionar la réplica secundaria
Para seguir migrando el conjunto de datos a la EU multirregión, promueve la réplica secundaria:
ALTER SCHEMA my_migration SET OPTIONS(primary_replica = 'eu')
Una vez que se haya completado la promoción, eu será la réplica principal. Es una réplica
en la que se puede escribir.
Completar la migración
Para completar la migración de la US multirregión a la EU multirregión, elimina la réplica us. Este paso no es obligatorio, pero es útil si no necesitas una réplica del conjunto de datos más allá de tus necesidades de migración.
ALTER SCHEMA my_migration DROP REPLICA IF EXISTS us;
Tu conjunto de datos se encuentra en la multirregión EU y no hay réplicas del conjunto de datos my_migration. Has migrado correctamente tu conjunto de datos a la multirregión EU. Puedes consultar la lista completa de recursos que se migran en Comportamiento de los recursos.
Claves de encriptado gestionadas por el cliente (CMEK)
Las claves de Cloud Key Management Service gestionadas por el cliente no se replican automáticamente cuando creas una réplica secundaria. Para mantener el cifrado en el conjunto de datos replicado, debes definir la replica_kms_key de la ubicación de la réplica añadida. Puedes definir el
replica_kms_key con la ALTER SCHEMA ADD REPLICA instrucción DDL.
La replicación de conjuntos de datos con CMEK se comporta como se describe en los siguientes casos:
Si el conjunto de datos de origen tiene un
default_kms_key, debes proporcionar unreplica_kms_keyque se haya creado en la región del conjunto de datos de réplica al usar la instrucción DDLALTER SCHEMA ADD REPLICA.Si el conjunto de datos de origen no tiene ningún valor asignado a
default_kms_key, no puedes definirreplica_kms_key.Si usas la rotación de claves de Cloud KMS en cualquiera de los dos (o en ambos)
default_kms_keyoreplica_kms_key, se podrá seguir consultando el conjunto de datos replicado después de la rotación de claves.- La rotación de claves en la región principal actualiza la versión de la clave solo en las tablas creadas después de la rotación. Las tablas que ya existían antes de la rotación de claves siguen usando la versión de la clave que se había definido antes de la rotación.
- La rotación de claves en la región secundaria actualiza todas las tablas de la réplica secundaria a la nueva versión de la clave.
- Al cambiar la réplica principal a secundaria, se actualizan todas las tablas de la réplica secundaria (antes la réplica principal) a la nueva versión de la clave.
- Si se elimina la versión de clave definida en las tablas de la réplica principal antes de la rotación de claves, no se podrán consultar las tablas que sigan usando la versión de clave definida antes de la rotación hasta que se actualice la versión de clave. Para actualizar la versión de la clave, la versión antigua debe estar activa (no inhabilitada ni eliminada).
Si el conjunto de datos de origen no tiene ningún valor asignado a
default_kms_key, pero hay tablas individuales en el conjunto de datos de origen con CMEK aplicada, no se pueden consultar esas tablas en el conjunto de datos replicado. Para consultar las tablas, haz lo siguiente:- Añada un valor
default_kms_keyal conjunto de datos de origen. - Cuando crees una réplica con la instrucción
ALTER SCHEMA ADD REPLICADDL, asigna un valor a la opciónreplica_kms_key. Las tablas de CMEK se pueden consultar en la región de destino.
Todas las tablas CMEK de la región de destino usan el mismo
replica_kms_key, independientemente de la clave utilizada en la región de origen.- Añada un valor
Crear una réplica con CMEK
En el siguiente ejemplo se crea una réplica en la región us-west1 con un valor replica_kms_key definido. En el caso de la clave CMEK, concede permiso a la cuenta de servicio de BigQuery para cifrar y descifrar.
-- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `us-west1` OPTIONS(location='us-west1', replica_kms_key='my_us_west1_kms_key_name');
Limitaciones de CMEK
La replicación de conjuntos de datos con CMEK aplicada está sujeta a las siguientes limitaciones:
No puedes actualizar la clave de Cloud KMS replicada después de crear la réplica.
No puede actualizar el valor
default_kms_keydel conjunto de datos de origen después de que se hayan creado las réplicas del conjunto de datos.Si el
replica_kms_keyproporcionado no es válido en la región de destino, el conjunto de datos no se replicará.
Siguientes pasos
- Consulta cómo trabajar con las reservas de BigQuery.
- Consulta las funciones de fiabilidad de BigQuery.