IAM を使用してリソースへのアクセスを制御する
このドキュメントでは、BigQuery データセットと、データセット内のリソース(テーブル、ビュー、ルーティン)のアクセス制御を表示、付与、取り消す方法について説明します。モデルもデータセット レベルのリソースですが、IAM ロールを使用して個々のモデルへのアクセス権を付与することはできません。
Google Cloud リソースへのアクセスを許可するには、Identity and Access Management(IAM)ポリシー(許可ポリシー)を使用します。これはリソースに適用されます。各リソースに適用できる許可ポリシーは 1 つだけです。許可ポリシーは、リソース自体だけでなく、そのリソースの許可ポリシーを継承する子孫へのアクセスも制御します。
許可ポリシーの詳細については、IAM ドキュメントのポリシー構造をご覧ください。
このドキュメントは、 Google Cloudの Identity and Access Management(IAM)に関する知識があることを前提としています。
制限事項
- ルーティン アクセス制御リスト(ACL)は、複製されたルーティンに含まれません。
- 外部データセットまたはリンクされたデータセット内のルーティンは、アクセス制御をサポートしていません。
- 外部データセットまたはリンクされたデータセット内のテーブルは、アクセス制御をサポートしていません。
- ルーティン アクセス制御は、Terraform を使用して設定することはできません。
- ルーティン アクセス制御は、Google Cloud SDK を使用して設定することはできません。
- ルーティン アクセス制御は、BigQuery データ制御言語(DCL)を使用して設定することはできません。
- Data Catalog は、ルーティン アクセス制御をサポートしていません。ユーザーが条件付きでルーティンレベルのアクセス権を付与した場合、BigQuery のサイドパネルにルーティンは表示されません。回避策として、データセット レベルのアクセス権を付与します。
INFORMATION_SCHEMA.OBJECT_PRIVILEGESビューには、ルーティンのアクセス制御は表示されません。
始める前に
このドキュメントの各タスクを実行するために必要な権限をユーザーに与える Identity and Access Management(IAM)のロールを付与します。
必要なロール
リソースの IAM ポリシーを変更するために必要な権限を取得するには、プロジェクトに対する BigQuery データオーナー(roles/bigquery.dataOwner)IAM ロールを付与するよう管理者に依頼してください。ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。
この事前定義ロールには、リソースの IAM ポリシーを変更するために必要な権限が含まれています。必要とされる正確な権限については、「必要な権限」セクションを開いてご確認ください。
必要な権限
リソースの IAM ポリシーを変更するには、次の権限が必要です。
-
データセットのアクセス ポリシーを取得するには:
bigquery.datasets.get -
データセットのアクセス ポリシーを設定するには:
bigquery.datasets.update -
データセットのアクセス ポリシーを取得するには(Google Cloud コンソールのみ):
bigquery.datasets.getIamPolicy -
データセットのアクセス ポリシーを設定するには(コンソールのみ):
bigquery.datasets.setIamPolicy -
テーブルまたはビューのポリシーを取得するには:
bigquery.tables.getIamPolicy -
テーブルまたはビューのポリシーを設定するには:
bigquery.tables.setIamPolicy -
ルーティンのアクセス ポリシーを取得するには:
bigquery.routines.getIamPolicy -
ルーティンのアクセス ポリシーを設定するには:
bigquery.routines.setIamPolicy -
bq ツールまたは SQL BigQuery ジョブ(省略可)を作成するには:
bigquery.jobs.create
カスタムロールや他の事前定義ロールを使用して、これらの権限を取得することもできます。
データセットのアクセス制御を操作する
データセットへのアクセス権を付与するには、プリンシパルがデータセットに対して実行できる操作を決定する事前定義ロールまたはカスタムロールを IAM プリンシパルに付与します。この操作は、リソースに許可ポリシーを適用するとも呼ばれます。アクセス権を付与すると、データセットのアクセス制御を表示したり、データセットへのアクセス権を取り消すことができます。
データセットへのアクセス権を付与する
BigQuery ウェブ UI または bq コマンドライン ツールを使用してデータセットを作成するときに、データセットへのアクセス権を付与することはできません。まずデータセットを作成してから、データセットへのアクセス権を付与する必要があります。この API では、定義済みのデータセット リソースを使用して datasets.insert メソッドを呼び出すことで、データセットの作成時にアクセス権を付与できます。
プロジェクトはデータセットの親リソースであり、データセットはテーブル、ビュー、ルーティン、モデルの親リソースです。プロジェクト レベルでロールを付与すると、そのロールとその権限はデータセットとデータセットのリソースに継承されます。同様に、データセット レベルでロールを付与すると、ロールとその権限はデータセット内のリソースに継承されます。
データセットへのアクセス権を付与するには、IAM ロールにデータセットへのアクセス権を付与するか、IAM 条件を使用して条件付きでアクセス権を付与します。条件付きアクセス権の付与の詳細については、IAM Conditions によるアクセス制御をご覧ください。
条件を使用せずに IAM ロールにデータセットへのアクセス権を付与するには、次のいずれかのオプションを選択します。
コンソール
[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。

左側のペインが表示されていない場合は、 左側のペインを開くをクリックしてペインを開きます。
[エクスプローラ] ペインでプロジェクトを開き、[データセット] をクリックして、データセットを選択します。
[共有] > [権限] の順にクリックします。
[ プリンシパルを追加] をクリックします。
[新しいプリンシパル] フィールドに、プリンシパルを入力します。
[ロールを選択] リストで、事前定義ロールまたはカスタムロールを選択します。
[保存] をクリックします。
データセット情報に戻るには、[閉じる] をクリックします。
SQL
プリンシパルにデータセットへのアクセス権を付与するには、GRANT DCL ステートメントを使用します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
GRANT `ROLE_LIST` ON SCHEMA RESOURCE_NAME TO "USER_LIST"
次のように置き換えます。
ROLE_LIST: 付与するロールまたはカンマ区切りのロールのリストRESOURCE_NAME: アクセス権を付与するデータセットの名前USER_LIST: ロールが付与されているユーザーのカンマ区切りのリスト有効な形式の一覧については、
user_listをご覧ください。
[実行] をクリックします。
クエリの実行方法については、インタラクティブ クエリを実行するをご覧ください。
次の例では、myDataset に BigQuery データ閲覧者のロールを付与します。
GRANT `roles/bigquery.dataViewer`
ON SCHEMA `myProject`.myDataset
TO "user:user@example.com", "user:user2@example.com"
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
既存のデータセット情報(アクセス制御を含む)を JSON ファイルに書き込むには、
bq showコマンドを使用します。bq show \ --format=prettyjson \ PROJECT_ID:DATASET > PATH_TO_FILE
次のように置き換えます。
- PROJECT_ID: プロジェクト ID
- DATASET: データセットの名前
- PATH_TO_FILE: ローカルマシン上の JSON ファイルへのパス
JSON ファイルの
accessセクションに変更を加えます。specialGroupエントリ(projectOwners、projectWriters、projectReaders、allAuthenticatedUsers)はどれも追加できます。また、userByEmail、groupByEmail、domainも追加できます。たとえば、データセットの JSON ファイルの
accessセクションは次のようになります。{ "access": [ { "role": "READER", "specialGroup": "projectReaders" }, { "role": "WRITER", "specialGroup": "projectWriters" }, { "role": "OWNER", "specialGroup": "projectOwners" }, { "role": "READER", "specialGroup": "allAuthenticatedUsers" }, { "role": "READER", "domain": "domain_name" }, { "role": "WRITER", "userByEmail": "user_email" }, { "role": "READER", "groupByEmail": "group_email" } ], ... }
編集が完了したら、
bq updateコマンドを実行します。その際、--sourceフラグを使用して JSON ファイルを指定します。データセットがデフォルト プロジェクト以外のプロジェクトにある場合は、PROJECT_ID:DATASETの形式でプロジェクト ID をデータセット名に追加します。bq update
--source PATH_TO_FILE
PROJECT_ID:DATASETアクセス制御の変更を確認するには、
bq showコマンドをもう一度使用します。ただし、今回は情報をファイルに書き込む指定を省略します。bq show --format=prettyjson PROJECT_ID:DATASET
- Cloud Shell を起動します。
-
Terraform 構成を適用するデフォルトの Google Cloud プロジェクトを設定します。
このコマンドは、プロジェクトごとに 1 回だけ実行する必要があります。これは任意のディレクトリで実行できます。
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Terraform 構成ファイルに明示的な値を設定すると、環境変数がオーバーライドされます。
-
Cloud Shell で、ディレクトリを作成し、そのディレクトリ内に新しいファイルを作成します。ファイルの拡張子は
.tfにする必要があります(例:main.tf)。このチュートリアルでは、このファイルをmain.tfとします。mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
チュートリアルを使用している場合は、各セクションまたはステップのサンプルコードをコピーできます。
新しく作成した
main.tfにサンプルコードをコピーします。必要に応じて、GitHub からコードをコピーします。Terraform スニペットがエンドツーエンドのソリューションの一部である場合は、この方法をおすすめします。
- 環境に適用するサンプル パラメータを確認し、変更します。
- 変更を保存します。
-
Terraform を初期化します。これは、ディレクトリごとに 1 回だけ行います。
terraform init
最新バージョンの Google プロバイダを使用する場合は、
-upgradeオプションを使用します。terraform init -upgrade
-
構成を確認して、Terraform が作成または更新するリソースが想定どおりであることを確認します。
terraform plan
必要に応じて構成を修正します。
-
次のコマンドを実行します。プロンプトで「
yes」と入力して、Terraform 構成を適用します。terraform apply
Terraform に「Apply complete!」というメッセージが表示されるまで待ちます。
- Google Cloud プロジェクトを開いて結果を表示します。 Google Cloud コンソールの UI でリソースに移動して、Terraform によって作成または更新されたことを確認します。
Terraform
google_bigquery_dataset_iam リソースを使用して、データセットへのアクセス権を更新します。
データセットのアクセス制御ポリシーを設定する
次の例では、google_bigquery_dataset_iam_policy リソースを使用して、mydataset データセットの IAM ポリシーを設定する方法を示します。これにより、データセットにすでにアタッチされている既存のポリシーが置き換えられます。
# This file sets the IAM policy for the dataset created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_dataset/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" dataset resource with a dataset_id of "mydataset". data "google_iam_policy" "iam_policy" { binding { role = "roles/bigquery.admin" members = [ "user:user@example.com", ] } binding { role = "roles/bigquery.dataOwner" members = [ "group:data.admin@example.com", ] } binding { role = "roles/bigquery.dataEditor" members = [ "serviceAccount:bqcx-1234567891011-12a3@gcp-sa-bigquery-condel.iam.gserviceaccount.com", ] } } resource "google_bigquery_dataset_iam_policy" "dataset_iam_policy" { dataset_id = google_bigquery_dataset.default.dataset_id policy_data = data.google_iam_policy.iam_policy.policy_data }
データセットのロール メンバーシップを設定する
次の例では、google_bigquery_dataset_iam_binding リソースを使用して、mydataset データセットの特定のロールのメンバーシップを設定する方法を示します。これにより、そのロールの既存のメンバーシップがすべて置き換えられます。データセットの IAM ポリシー内の他のロールは保持されます。
# This file sets membership in an IAM role for the dataset created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_dataset/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" dataset resource with a dataset_id of "mydataset". resource "google_bigquery_dataset_iam_binding" "dataset_iam_binding" { dataset_id = google_bigquery_dataset.default.dataset_id role = "roles/bigquery.jobUser" members = [ "user:user@example.com", "group:group@example.com" ] }
単一のプリンシパルのロール メンバーシップを設定する
次の例は、単一のプリンシパルにロールを付与するために、google_bigquery_dataset_iam_member リソースを使用して mydataset データセットの IAM ポリシーを更新する方法を示しています。この IAM ポリシーを更新しても、データセットに対してそのロールが付与されている他のプリンシパルのアクセス権には影響しません。
# This file adds a member to an IAM role for the dataset created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_dataset/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" dataset resource with a dataset_id of "mydataset". resource "google_bigquery_dataset_iam_member" "dataset_iam_member" { dataset_id = google_bigquery_dataset.default.dataset_id role = "roles/bigquery.user" member = "user:user@example.com" }
Google Cloud プロジェクトで Terraform 構成を適用するには、次のセクションの手順を完了します。
Cloud Shell を準備する
ディレクトリを準備する
Terraform 構成ファイルには独自のディレクトリ(ルート モジュールとも呼ばれます)が必要です。
変更を適用する
API
データセットの作成時にアクセス制御を適用するには、定義済みのデータセット リソースを使用して datasets.insert メソッドを呼び出します。アクセス制御を更新するには、datasets.patch メソッドを呼び出して、Dataset リソースの access プロパティを使用します。
datasets.update メソッドは、データセット リソース全体を置き換えるため、アクセス制御の更新には datasets.patch メソッドのほうが適切です。
Go
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Go の設定手順を完了してください。詳細については、BigQuery Go API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
DatasetMetadataToUpdate タイプの新しいエントリを既存のリストに追加して、新しいアクセスリストを設定します。次に、dataset.Update() 関数を呼び出してプロパティを更新します。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Node.js
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Node.js の設定手順を完了してください。詳細については、BigQuery Node.js API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Dataset#metadata メソッドを使用して、新しいエントリを既存のリストに追加し、新しいアクセスリストを設定します。次に、Dataset#setMetadata() 関数を呼び出してプロパティを更新します。Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
dataset.access_entries プロパティに、データセットのアクセス制御を設定します。次に、client.update_dataset() 関数を呼び出してプロパティを更新します。
データセットへのアクセス権を付与する事前定義ロール
次の IAM 事前定義ロールにデータセットへのアクセス権を付与できます。
| ロール | 説明 |
|---|---|
BigQuery データオーナー(roles/bigquery.dataOwner) |
このロールをデータセットに関して付与すると、次の権限が与えられます。
|
BigQuery データ編集者(roles/bigquery.dataEditor) |
このロールをデータセットに関して付与すると、次の権限が与えられます。
|
BigQuery データ閲覧者(roles/bigquery.dataViewer) |
このロールをデータセットに関して付与すると、次の権限が与えられます。
|
BigQuery メタデータ閲覧者(roles/bigquery.metadataViewer) |
このロールをデータセットに関して付与すると、次の権限が与えられます。
|
データセットの権限
bigquery.datasets で始まるほとんどの権限は、データセット レベルで適用されます。ただし、bigquery.datasets.create は異なります。データセットを作成するには、親コンテナ(プロジェクト)のロールに bigquery.datasets.create 権限が付与されている必要があります。
次の表に、データセットのすべての権限と、権限を適用できる最下位のリソースを示します。
| 権限 | リソース | アクション |
|---|---|---|
bigquery.datasets.create |
プロジェクト | プロジェクトに新しいデータセットを作成する。 |
bigquery.datasets.get |
データセット | データセットのメタデータとアクセス制御を取得する。コンソールで権限を表示するには、bigquery.datasets.getIamPolicy 権限も必要です。 |
bigquery.datasets.getIamPolicy |
データセット | コンソールで、データセットのアクセス制御を取得する権限をユーザーに付与するために必要です。フェール オープン。コンソールでデータセットを表示するには、bigquery.datasets.get 権限も必要です。 |
bigquery.datasets.update |
データセット | データセットのメタデータとアクセス制御を更新する。コンソールでアクセス制御を更新するには、bigquery.datasets.setIamPolicy 権限も必要です。 |
bigquery.datasets.setIamPolicy |
データセット | コンソールで、データセットのアクセス制御を設定する権限をユーザーに付与するために必要です。フェール オープン。コンソールでデータセットを更新するには、bigquery.datasets.update 権限も必要です。 |
bigquery.datasets.delete |
データセット | データセットを削除する。 |
bigquery.datasets.createTagBinding |
データセット | データセットにタグを適用する。 |
bigquery.datasets.deleteTagBinding |
データセット | データセットからタグの適用を解除する。 |
bigquery.datasets.listTagBindings |
データセット | データセットのタグを一覧表示する。 |
bigquery.datasets.listEffectiveTags |
データセット | データセットの有効なタグ(適用済みと継承済み)を一覧表示する。 |
bigquery.datasets.link |
データセット | リンクされたデータセットを作成します。 |
bigquery.datasets.listSharedDatasetUsage |
プロジェクト | プロジェクト内でアクセス権のあるデータセットについて、共有データセットの使用統計情報を一覧表示する。この権限は、INFORMATION_SCHEMA.SHARED_DATASET_USAGE ビューにクエリを実行するために必要です。 |
データセットのアクセス制御を表示する
データセットに明示的に設定されたアクセス制御を表示するには、次のいずれかのオプションを選択します。データセットで継承されたロールを確認するには、BigQuery ウェブ UI を使用します。
コンソール
[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。
[エクスプローラ] ペインでプロジェクトを開き、[データセット] をクリックして、データセットを選択します。
[共有] > [権限] の順にクリックします。
データセットのアクセス制御が [データセットの権限] ペインに表示されます。
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
既存のポリシーを取得して JSON でローカル ファイルに出力するには、Cloud Shell で
bq showコマンドを使用します。bq show \ --format=prettyjson \ PROJECT_ID:DATASET > PATH_TO_FILE
次のように置き換えます。
- PROJECT_ID: プロジェクト ID
- DATASET: データセットの名前
- PATH_TO_FILE: ローカルマシン上の JSON ファイルのパス
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
SELECT COLUMN_LIST FROM PROJECT_ID.`region-REGION`.INFORMATION_SCHEMA.OBJECT_PRIVILEGES WHERE object_name = "DATASET";
次のように置き換えます。
- COLUMN_LIST:
INFORMATION_SCHEMA.OBJECT_PRIVILEGESビューの列のカンマ区切りリスト - PROJECT_ID: プロジェクト ID
- REGION: リージョン修飾子
- DATASET: プロジェクト内のデータセットの名前
- COLUMN_LIST:
[実行] をクリックします。
SQL
INFORMATION_SCHEMA.OBJECT_PRIVILEGES ビューをクエリします。データセットのアクセス制御を取得するクエリでは、object_name を指定する必要があります。
クエリの実行方法については、インタラクティブ クエリを実行するをご覧ください。
例:
このクエリは、mydataset のアクセス制御を取得します。
SELECT object_name, privilege_type, grantee FROM my_project.`region-us`.INFORMATION_SCHEMA.OBJECT_PRIVILEGES WHERE object_name = "mydataset";
出力は次のようになります。
+------------------+-----------------------------+-------------------------+
| object_name | privilege_type | grantee |
+------------------+-----------------------------+-------------------------+
| mydataset | roles/bigquery.dataOwner | projectOwner:myproject |
| mydataset | roles/bigquery.dataViwer | user:user@example.com |
+------------------+-----------------------------+-------------------------+
API
データセットのアクセス制御を表示するには、定義済みの dataset リソースを使用して、datasets.get メソッドを呼び出します。
アクセス制御は、dataset リソースの access プロパティに表示されます。
Go
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Go の設定手順を完了してください。詳細については、BigQuery Go API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
client.Dataset().Metadata() 関数を呼び出します。アクセス ポリシーは Access プロパティで使用できます。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Node.js
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Node.js の設定手順を完了してください。詳細については、BigQuery Node.js API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Dataset#getMetadata() 関数を使用して、データセットのメタデータを取得します。アクセス ポリシーは、生成されたメタデータ オブジェクトのアクセス プロパティで使用できます。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
client.get_dataset() 関数を呼び出します。アクセス ポリシーは dataset.access_entries プロパティで使用できます。
データセットに対するアクセス権を取り消す
データセットに対するアクセスを取り消すには、次のいずれかのオプションを選択します。
コンソール
[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。
[エクスプローラ] ペインでプロジェクトを開き、[データセット] をクリックして、データセットを選択します。
詳細パネルで、[共有 > 権限] をクリックします。
[データセットの権限] ダイアログで、アクセス権を取り消すプリンシパルを開きます。
[ プリンシパルを削除] をクリックします。
[プリンシパルからロールを削除しますか?] ダイアログで、[削除] をクリックします。
データセットの詳細に戻るには、[閉じる] をクリックします。
SQL
プリンシパルからデータセットへのアクセス権を削除するには、REVOKE DCL ステートメントを使用します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
REVOKE `ROLE_LIST` ON SCHEMA RESOURCE_NAME FROM "USER_LIST"
次のように置き換えます。
ROLE_LIST: 取り消すロールまたはカンマ区切りのロールのリストRESOURCE_NAME: 権限を取り消すリソースの名前USER_LIST: ロールが取り消されるユーザーのカンマ区切りのリスト有効な形式の一覧については、
user_listをご覧ください。
[実行] をクリックします。
クエリの実行方法については、インタラクティブ クエリを実行するをご覧ください。
次の例では、myDataset から BigQuery データオーナーのロールを取り消します。
REVOKE `roles/bigquery.dataOwner`
ON SCHEMA `myProject`.myDataset
FROM "group:group@example.com", "serviceAccount:user@test-project.iam.gserviceaccount.com"
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
既存のデータセット情報(アクセス制御を含む)を JSON ファイルに書き込むには、
bq showコマンドを使用します。bq show \ --format=prettyjson \ PROJECT_ID:DATASET > PATH_TO_FILE
次のように置き換えます。
- PROJECT_ID: プロジェクト ID
- DATASET: データセットの名前
- PATH_TO_FILE: ローカルマシン上の JSON ファイルへのパス
JSON ファイルの
accessセクションに変更を加えます。specialGroupのエントリ(projectOwners、projectWriters、projectReaders、allAuthenticatedUsers)は削除できます。さらに、userByEmail、groupByEmail、domainの削除もできます。たとえば、データセットの JSON ファイルの
accessセクションは次のようになります。{ "access": [ { "role": "READER", "specialGroup": "projectReaders" }, { "role": "WRITER", "specialGroup": "projectWriters" }, { "role": "OWNER", "specialGroup": "projectOwners" }, { "role": "READER", "specialGroup": "allAuthenticatedUsers" }, { "role": "READER", "domain": "domain_name" }, { "role": "WRITER", "userByEmail": "user_email" }, { "role": "READER", "groupByEmail": "group_email" } ], ... }
編集が完了したら、
bq updateコマンドを実行します。その際、--sourceフラグを使用して JSON ファイルを指定します。データセットがデフォルト プロジェクト以外のプロジェクトにある場合は、PROJECT_ID:DATASETの形式でプロジェクト ID をデータセット名に追加します。bq update
--source PATH_TO_FILE
PROJECT_ID:DATASETアクセス制御の変更を確認するには、
showコマンドを使用します。ただし、今回は情報をファイルに書き込む指定を省略します。bq show --format=prettyjson PROJECT_ID:DATASET
API
アクセス制御を更新するには、datasets.patch メソッドを呼び出し、Dataset リソースの access プロパティを使用します。
datasets.update メソッドは、データセット リソース全体を置き換えるため、アクセス制御の更新には datasets.patch メソッドのほうが適切です。
Go
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Go の設定手順を完了してください。詳細については、BigQuery Go API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
DatasetMetadataToUpdate タイプの既存のリストからエントリを削除して、新しいアクセスリストを設定します。次に、dataset.Update() 関数を呼び出してプロパティを更新します。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Node.js
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Node.js の設定手順を完了してください。詳細については、BigQuery Node.js API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Dataset#get() メソッドを使用して既存のリストから指定されたエントリを削除し、現在のメタデータを取得して、データセット アクセスリストを更新します。目的のエンティティを除外するようにアクセス プロパティを変更し、Dataset#setMetadata() 関数を呼び出して更新されたアクセスリストを適用します。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
dataset.access_entries プロパティに、データセットのアクセス制御を設定します。次に、client.update_dataset() 関数を呼び出してプロパティを更新します。
テーブルとビューのアクセス制御を操作する
BigQuery では、ビューはテーブル リソースとして扱われます。テーブルまたはビューへのアクセス権を付与するには、プリンシパルがテーブルまたはビューに対して実行できる操作を決定する事前定義ロールまたはカスタムロールを IAM プリンシパルに付与します。この操作は、リソースに許可ポリシーを適用するとも呼ばれます。アクセス権を付与すると、テーブルまたはビューのアクセス制御を表示して、テーブルまたはビューへのアクセス権を取り消すことができます。
テーブルまたはビューへのアクセス権を付与する
きめ細かいアクセス制御では、特定のテーブルまたはビューに対する IAM 事前定義ロールまたはカスタムロールを付与できます。テーブルまたはビューは、データセット レベル以上で指定されたアクセス制御も継承します。たとえば、プリンシパルにデータセットに対する BigQuery データオーナーのロールを付与すると、そのプリンシパルはデータセット内のテーブルとビューに対する BigQuery データオーナーの権限も持ちます。
テーブルまたはビューへのアクセス権を付与するには、次のいずれかのオプションを選択します。
コンソール
[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。
[エクスプローラ] ペインでプロジェクトを開き、[データセット] をクリックして、データセットを選択します。
[概要 > テーブル] をクリックし、テーブルまたはビューをクリックします。
[共有] > [権限の管理] の順にクリックします。
[ プリンシパルを追加] をクリックします。
[新しいプリンシパル] フィールドに、プリンシパルを入力します。
[ロールを選択] リストで、事前定義ロールまたはカスタムロールを選択します。
[保存] をクリックします。
テーブルまたはビューの詳細に戻るには、[閉じる] をクリックします。
SQL
プリンシパルにテーブルまたはビューへのアクセス権を付与するには、GRANT DCL ステートメントを使用します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
GRANT `ROLE_LIST` ON RESOURCE_TYPE RESOURCE_NAME TO "USER_LIST"
次のように置き換えます。
ROLE_LIST: 付与するロールまたはカンマ区切りのロールのリストRESOURCE_TYPE: ロールが適用されるリソースのタイプ。サポートされている値には、
TABLE、VIEW、MATERIALIZED VIEW、EXTERNAL TABLEがあります。RESOURCE_NAME: 権限を付与するリソースの名前USER_LIST: ロールが付与されているユーザーのカンマ区切りのリスト有効な形式の一覧については、
user_listをご覧ください。
[実行] をクリックします。
クエリの実行方法については、インタラクティブ クエリを実行するをご覧ください。
次の例では、myTable に対する BigQuery データ閲覧者のロールを付与します。
GRANT `roles/bigquery.dataViewer`
ON TABLE `myProject`.myDataset.myTable
TO "user:user@example.com", "user:user2@example.com"
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
テーブルまたはビューへのアクセス権を付与するには、
bq add-iam-policy-bindingコマンドを使用します。bq add-iam-policy-binding --member=MEMBER_TYPE:MEMBER --role=ROLE --table=true RESOURCE
次のように置き換えます。
- MEMBER_TYPE: メンバーのタイプ(
user、group、serviceAccount、domainなど)。 - MEMBER: メンバーのメールアドレスまたはドメイン名。
- ROLE: メンバーに付与するロール。
- RESOURCE: ポリシーを更新するテーブルまたはビューの名前。
- MEMBER_TYPE: メンバーのタイプ(
- Cloud Shell を起動します。
-
Terraform 構成を適用するデフォルトの Google Cloud プロジェクトを設定します。
このコマンドは、プロジェクトごとに 1 回だけ実行する必要があります。これは任意のディレクトリで実行できます。
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Terraform 構成ファイルに明示的な値を設定すると、環境変数がオーバーライドされます。
-
Cloud Shell で、ディレクトリを作成し、そのディレクトリ内に新しいファイルを作成します。ファイルの拡張子は
.tfにする必要があります(例:main.tf)。このチュートリアルでは、このファイルをmain.tfとします。mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
チュートリアルを使用している場合は、各セクションまたはステップのサンプルコードをコピーできます。
新しく作成した
main.tfにサンプルコードをコピーします。必要に応じて、GitHub からコードをコピーします。Terraform スニペットがエンドツーエンドのソリューションの一部である場合は、この方法をおすすめします。
- 環境に適用するサンプル パラメータを確認し、変更します。
- 変更を保存します。
-
Terraform を初期化します。これは、ディレクトリごとに 1 回だけ行います。
terraform init
最新バージョンの Google プロバイダを使用する場合は、
-upgradeオプションを使用します。terraform init -upgrade
-
構成を確認して、Terraform が作成または更新するリソースが想定どおりであることを確認します。
terraform plan
必要に応じて構成を修正します。
-
次のコマンドを実行します。プロンプトで「
yes」と入力して、Terraform 構成を適用します。terraform apply
Terraform に「Apply complete!」というメッセージが表示されるまで待ちます。
- Google Cloud プロジェクトを開いて結果を表示します。 Google Cloud コンソールの UI でリソースに移動して、Terraform によって作成または更新されたことを確認します。
現在のポリシーを取得するには、
tables.getIamPolicyメソッドを呼び出します。ポリシーを編集して、メンバーまたはアクセス制御、あるいはその両方を追加します。ポリシーに必要な形式については、リファレンスのポリシーのトピックをご覧ください。
tables.setIamPolicyを呼び出して、更新されたポリシーを書き込みます。
Terraform
google_bigquery_table_iam リソースを使用して、テーブルへのアクセス権を更新します。
テーブルのアクセス制御ポリシーを設定する
次の例では、google_bigquery_table_iam_policy リソースを使用して、mytable テーブルの IAM ポリシーを設定する方法を示します。これにより、テーブルにすでにアタッチされている既存のポリシーが置き換えられます。
# This file sets the IAM policy for the table created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_table/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" table resource with a table_id of "mytable". data "google_iam_policy" "iam_policy" { binding { role = "roles/bigquery.dataOwner" members = [ "user:user@example.com", ] } } resource "google_bigquery_table_iam_policy" "table_iam_policy" { dataset_id = google_bigquery_table.default.dataset_id table_id = google_bigquery_table.default.table_id policy_data = data.google_iam_policy.iam_policy.policy_data }
テーブルのロール メンバーシップを設定する
次の例では、google_bigquery_table_iam_binding リソースを使用して、mytable テーブルの特定のロールのメンバーシップを設定する方法を示します。これにより、そのロールの既存のメンバーシップがすべて置き換えられます。テーブルの IAM ポリシー内の他のロールは保持されます。
# This file sets membership in an IAM role for the table created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_table/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" table resource with a table_id of "mytable". resource "google_bigquery_table_iam_binding" "table_iam_binding" { dataset_id = google_bigquery_table.default.dataset_id table_id = google_bigquery_table.default.table_id role = "roles/bigquery.dataOwner" members = [ "group:group@example.com", ] }
単一のプリンシパルのロール メンバーシップを設定する
次の例は、mytable テーブルの IAM ポリシーを更新し、1 つのプリンシパルにロールを付与するための、google_bigquery_table_iam_member リソースの使用方法を示しています。この IAM ポリシーを更新しても、データセットに対してそのロールが付与されている他のプリンシパルのアクセス権には影響しません。
# This file adds a member to an IAM role for the table created by # https://github.com/terraform-google-modules/terraform-docs-samples/blob/main/bigquery/bigquery_create_table/main.tf. # You must place it in the same local directory as that main.tf file, # and you must have already applied that main.tf file to create # the "default" table resource with a table_id of "mytable". resource "google_bigquery_table_iam_member" "table_iam_member" { dataset_id = google_bigquery_table.default.dataset_id table_id = google_bigquery_table.default.table_id role = "roles/bigquery.dataEditor" member = "serviceAccount:bqcx-1234567891011-12a3@gcp-sa-bigquery-condel.iam.gserviceaccount.com" }
Google Cloud プロジェクトで Terraform 構成を適用するには、次のセクションの手順を完了します。
Cloud Shell を準備する
ディレクトリを準備する
Terraform 構成ファイルには独自のディレクトリ(ルート モジュールとも呼ばれます)が必要です。
変更を適用する
API
Go
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Go の設定手順を完了してください。詳細については、BigQuery Go API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
リソースのIAM().SetPolicy() 関数を呼び出して、テーブルまたはビューのアクセス ポリシーの変更を保存します。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Node.js
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Node.js の設定手順を完了してください。詳細については、BigQuery Node.js API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Table#getIamPolicy() 関数を呼び出して、テーブルまたはビューの現在の IAM ポリシーを取得し、新しいバインディングを追加してポリシーを変更します。次に、Table#setIamPolicy() 関数を使用して、アクセス ポリシーの変更を保存します。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
client.set_iam_policy() 関数を呼び出して、テーブルまたはビューのアクセス ポリシーの変更を保存します。
テーブルとビューへのアクセス権を付与する事前定義ロール
BigQuery では、ビューはテーブル リソースとして扱われます。きめ細かいアクセス制御では、特定のテーブルまたはビューに対する IAM 事前定義ロールまたはカスタムロールを付与できます。テーブルまたはビューは、データセット レベル以上で指定されたアクセス制御も継承します。たとえば、プリンシパルにデータセットに対する BigQuery データオーナーのロールを付与すると、そのプリンシパルはデータセット内のテーブルとビューに対するデータオーナーの権限も持ちます。
次の IAM 事前定義ロールには、テーブルまたはビューに対する権限があります。
| ロール | 説明 |
|---|---|
BigQuery データオーナー(roles/bigquery.dataOwner) |
このロールをテーブルまたはビューに関して付与すると、次の権限が与えられます。
|
BigQuery データ編集者(roles/bigquery.dataEditor) |
このロールをテーブルまたはビューに関して付与すると、次の権限が与えられます。
|
BigQuery データ閲覧者(roles/bigquery.dataViewer) |
このロールをテーブルまたはビューに関して付与すると、次の権限が与えられます。
|
BigQuery メタデータ閲覧者(roles/bigquery.metadataViewer) |
このロールをテーブルまたはビューに関して付与すると、次の権限が与えられます。
|
テーブルとビューの権限
BigQuery では、ビューはテーブル リソースとして扱われます。テーブルレベルの権限はすべてビューに適用されます。
bigquery.tables で始まる権限のほとんどは、テーブルレベルで適用されます。ただし、bigquery.tables.create と bigquery.tables.list は異なります。テーブルまたはビューを作成して一覧表示するには、親コンテナ(データセットまたはプロジェクト)のロールに bigquery.tables.create 権限と bigquery.tables.list 権限が付与されている必要があります。
次の表に、テーブルとビューのすべての権限と、付与できる最下位レベルのリソースを示します。
| 権限 | リソース | アクション |
|---|---|---|
bigquery.tables.create |
データセット | データセットに新しいテーブルを作成する。 |
bigquery.tables.createIndex |
テーブル | テーブルに検索インデックスを作成する。 |
bigquery.tables.deleteIndex |
テーブル | テーブルの検索インデックスを削除する。 |
bigquery.tables.createSnapshot |
テーブル | テーブルのスナップショットを作成する。スナップショットを作成するには、テーブルとデータセットのレベルでいくつかの追加の権限が必要です。詳細については、テーブル スナップショットの作成に関する権限とロールをご覧ください。 |
bigquery.tables.deleteSnapshot |
テーブル | テーブルのスナップショットを削除する。 |
bigquery.tables.delete |
テーブル | テーブルを削除する。 |
bigquery.tables.createTagBinding |
テーブル | テーブルにリソースタグ バインディングを作成する。 |
bigquery.tables.deleteTagBinding |
テーブル | テーブルのリソースタグ バインディングを削除します。 |
bigquery.tables.listTagBindings |
テーブル | テーブルのリソースタグ バインディングの一覧を取得します。 |
bigquery.tables.listEffectiveTags |
テーブル | テーブルの有効なタグ(適用済みと継承済み)を一覧表示する。 |
bigquery.tables.export |
テーブル | テーブルのデータをエクスポートする。抽出ジョブを実行するには、bigquery.jobs.create 権限も必要です。 |
bigquery.tables.get |
テーブル | テーブルのメタデータを取得する。 |
bigquery.tables.getData |
テーブル | テーブルのデータをクエリする。クエリジョブを実行するには、bigquery.jobs.create 権限も必要です。 |
bigquery.tables.getIamPolicy |
テーブル | テーブルのアクセス制御を取得する。 |
bigquery.tables.list |
データセット | データセット内のすべてのテーブルとテーブル メタデータを一覧表示する。 |
bigquery.tables.replicateData |
テーブル | テーブルデータを複製する。この権限は、レプリカのマテリアライズド ビューを作成するために必要です。 |
bigquery.tables.restoreSnapshot |
テーブル | テーブル スナップショットを復元する。 |
bigquery.tables.setCategory |
テーブル | テーブルのスキーマにポリシータグを設定する。 |
bigquery.tables.setColumnDataPolicy |
テーブル | テーブルに列レベルのアクセス ポリシーを設定する。 |
bigquery.tables.setIamPolicy |
テーブル | テーブルのアクセス制御を設定する。 |
bigquery.tables.update |
テーブル | テーブルを更新する。コンソールでテーブル メタデータを更新する場合にも metadata. bigquery.tables.get が必要です。 |
bigquery.tables.updateData |
テーブル | テーブルのデータを更新する。 |
bigquery.tables.updateIndex |
テーブル | テーブルの検索インデックスを更新する。 |
テーブルまたはビューのアクセス制御を表示する
テーブルまたはビューのアクセス制御を表示するには、次のいずれかのオプションを選択します。
コンソール
[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。
[エクスプローラ] ペインでプロジェクトを開き、[データセット] をクリックして、データセットを選択します。
[概要 > テーブル] をクリックし、テーブルまたはビューをクリックします。
[共有] をクリックします。
テーブルまたはビューのアクセス制御が [共有] ペインに表示されます。
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
既存のアクセス ポリシーを取得して JSON でローカル ファイルに出力するには、Cloud Shell で
bq get-iam-policyコマンドを使用します。bq get-iam-policy \ --table=true \ PROJECT_ID:DATASET.RESOURCE > PATH_TO_FILE
次のように置き換えます。
- PROJECT_ID: プロジェクト ID
- DATASET: データセットの名前
- RESOURCE: ポリシーを表示するテーブルまたはビューの名前
- PATH_TO_FILE: ローカルマシン上の JSON ファイルのパス
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
SELECT COLUMN_LIST FROM PROJECT_ID.`region-REGION`.INFORMATION_SCHEMA.OBJECT_PRIVILEGES WHERE object_schema = "DATASET" AND object_name = "TABLE";
次のように置き換えます。
- COLUMN_LIST:
INFORMATION_SCHEMA.OBJECT_PRIVILEGESビューの列のカンマ区切りリスト - PROJECT_ID: プロジェクト ID
- REGION: リージョン修飾子
- DATASET: テーブルまたはビューを含むデータセットの名前
- TABLE: テーブルまたはビューの名前。
- COLUMN_LIST:
[実行] をクリックします。
SQL
INFORMATION_SCHEMA.OBJECT_PRIVILEGES ビューをクエリします。テーブルまたはビューのアクセス制御を取得するクエリでは、object_schema と object_name を指定する必要があります。
クエリの実行方法については、インタラクティブ クエリを実行するをご覧ください。
例:
SELECT object_name, privilege_type, grantee FROM my_project.`region-us`.INFORMATION_SCHEMA.OBJECT_PRIVILEGES WHERE object_schema = "mydataset" AND object_name = "mytable";
+------------------+-----------------------------+--------------------------+
| object_name | privilege_type | grantee |
+------------------+-----------------------------+--------------------------+
| mytable | roles/bigquery.dataEditor | group:group@example.com|
| mytable | roles/bigquery.dataOwner | user:user@example.com|
+------------------+-----------------------------+--------------------------+
API
現在のポリシーを取得するには、tables.getIamPolicy メソッドを呼び出します。
Go
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Go の設定手順を完了してください。詳細については、BigQuery Go API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
リソースのIAM().Policy() 関数を呼び出します。次に、Roles() 関数を呼び出して、テーブルまたはビューのアクセス ポリシーを取得します。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Node.js
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Node.js の設定手順を完了してください。詳細については、BigQuery Node.js API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Table#getIamPolicy() 関数を使用して、テーブルまたはビューの IAM ポリシーを取得します。アクセス ポリシーの詳細は、返されたポリシー オブジェクトで確認できます。
テーブルまたはビューに対するアクセス権を取り消す
テーブルまたはビューへのアクセス権を取り消すには、次のいずれかのオプションを選択します。
コンソール
[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。
[エクスプローラ] ペインでプロジェクトを開き、[データセット] をクリックして、データセットを選択します。
[概要 > テーブル] をクリックし、テーブルまたはビューをクリックします。
詳細ペインで、[共有] > [権限の管理] をクリックします。
[共有] ダイアログで、アクセス権を取り消すプリンシパルを開きます。
[削除] をクリックします。
[プリンシパルからロールを削除しますか?] ダイアログで、[削除] をクリックします。
テーブルまたはビューの詳細に戻るには、[閉じる] をクリックします。
SQL
プリンシパルからテーブルまたはビューへのアクセス権を削除するには、REVOKE DCL ステートメントを使用します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
REVOKE `ROLE_LIST` ON RESOURCE_TYPE RESOURCE_NAME FROM "USER_LIST"
次のように置き換えます。
ROLE_LIST: 取り消すロールまたはカンマ区切りのロールのリストRESOURCE_TYPE: ロールが取り消されるリソースの種類サポートされている値には、
TABLE、VIEW、MATERIALIZED VIEW、EXTERNAL TABLEがあります。RESOURCE_NAME: 権限を取り消すリソースの名前USER_LIST: ロールが取り消されるユーザーのカンマ区切りのリスト有効な形式の一覧については、
user_listをご覧ください。
[実行] をクリックします。
クエリの実行方法については、インタラクティブ クエリを実行するをご覧ください。
次の例では、myTable に対する BigQuery データオーナーのロールを取り消します。
REVOKE `roles/bigquery.dataOwner`
ON TABLE `myProject`.myDataset.myTable
FROM "group:group@example.com", "serviceAccount:user@myproject.iam.gserviceaccount.com"
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
テーブルまたはビューへのアクセス権を取り消すには、
bq remove-iam-policy-bindingコマンドを使用します。bq remove-iam-policy-binding --member=MEMBER_TYPE:MEMBER --role=ROLE --table=true RESOURCE
次のように置き換えます。
- MEMBER_TYPE: メンバーのタイプ(
user、group、serviceAccount、domainなど) - MEMBER: メンバーのメールアドレスまたはドメイン名
- ROLE: メンバーから取り消すロール
- RESOURCE: ポリシーを更新するテーブルまたはビューの名前
- MEMBER_TYPE: メンバーのタイプ(
現在のポリシーを取得するには、
tables.getIamPolicyメソッドを呼び出します。ポリシーを編集して、メンバーまたはバインディング、あるいはその両方を削除します。ポリシーに必要な形式については、リファレンスのポリシーのトピックをご覧ください。
tables.setIamPolicyを呼び出して、更新されたポリシーを書き込みます。
API
Go
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Go の設定手順を完了してください。詳細については、BigQuery Go API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
policy.Remove() 関数を呼び出してアクセス権を削除します。次に、IAM().SetPolicy() 関数を呼び出して、テーブルまたはビューのアクセス ポリシーの変更を保存します。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Node.js
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Node.js の設定手順を完了してください。詳細については、BigQuery Node.js API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Table#getIamPolicy() メソッドを使用して、テーブルまたはビューの現在の IAM ポリシーを取得します。目的のロールまたはプリンシパルを削除するようにポリシーを変更し、Table#setIamPolicy() メソッドを使用して更新したポリシーを適用します。
ルーティンのアクセス制御を操作する
この機能に関するフィードバックやサポートのリクエストは、bq-govsec-eng@google.com 宛てにメールでお送りください。
ルーティンへのアクセス権を付与するには、プリンシパルがルーティンに対して実行できる操作を決定する事前定義ロールまたはカスタムロールを IAM プリンシパルに付与します。この操作は、リソースに許可ポリシーを適用するとも呼ばれます。アクセス権を付与すると、ルーティンのアクセス制御を表示したり、ルーティンへのアクセス権を取り消すことができます。
ルーティンへのアクセス権を付与する
きめ細かいアクセス制御を行うには、特定のルーティンに対する IAM 事前定義ロールまたはカスタムロールを付与します。ルーティンは、データセット レベル以上で指定されたアクセス制御も継承します。たとえば、プリンシパルにデータセットに対する BigQuery データオーナーのロールを付与すると、そのプリンシパルはデータセット内のルーティンに対するデータオーナーの権限も持ちます。
次のオプションのいずれかを選択します。
コンソール
[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。
[エクスプローラ] ペインでプロジェクトを開き、[データセット] をクリックして、データセットを選択します。
[ルーティン] タブに移動して、ルーティンをクリックします。
[共有] をクリックします。
[メンバーを追加] をクリックします。
[新しいメンバー] フィールドに、プリンシパルを入力します。
[ロールを選択] リストで、事前定義ロールまたはカスタムロールを選択します。
[保存] をクリックします。
ルーティン情報に戻るには、[完了] をクリックします。
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
既存のルーティン情報(アクセス制御を含む)を JSON ファイルに書き込むには、
bq get-iam-policyコマンドを使用します。bq get-iam-policy \ PROJECT_ID:DATASET.ROUTINE \ > PATH_TO_FILE
次のように置き換えます。
- PROJECT_ID: プロジェクト ID
- DATASET: 更新するルーティンを含むデータセットの名前
- ROUTINE: 更新するリソースの名前
- PATH_TO_FILE: ローカルマシン上の JSON ファイルへのパス
JSON ファイルの
bindingsセクションに変更を加えます。バインディングは、1 つ以上のプリンシパルを 1 つのroleにバインドします。プリンシパルは、ユーザー アカウント、サービス アカウント、Google グループ、ドメインです。たとえば、ルーティンの JSON ファイルのbindingsセクションは次のようになります。{ "bindings": [ { "role": "roles/bigquery.dataViewer", "members": [ "user:user@example.com", "group:group@example.com", "domain:example.com", ] }, ], "etag": "BwWWja0YfJA=", "version": 1 }
アクセス ポリシーを更新するには、
bq set-iam-policyコマンドを使用します。bq set-iam-policy PROJECT_ID:DATASET.ROUTINE PATH_TO_FILE
アクセス制御の変更を確認するには、
bq get-iam-policyコマンドをもう一度使用します。ただし、今回は情報をファイルに書き込む指定を省略します。bq get-iam-policy --format=prettyjson \\ PROJECT_ID:DATASET.ROUTINE
現在のポリシーを取得するには、
routines.getIamPolicyメソッドを呼び出します。ポリシーを編集して、プリンシパルまたはバインディング、あるいはその両方を追加します。ポリシーに必要な形式については、リファレンスのポリシーのトピックをご覧ください。
routines.setIamPolicyを呼び出して、更新されたポリシーを書き込みます。
API
ルーティンへのアクセス権を付与する事前定義ロール
きめ細かいアクセス制御を行うには、特定のルーティンに対する IAM 事前定義ロールまたはカスタムロールを付与します。ルーティンは、データセット レベル以上で指定されたアクセス制御も継承します。たとえば、データセットに対するデータオーナーのロールをプリンシパルに付与すると、継承により、そのプリンシパルはデータセット内のルーティンに対するデータオーナーの権限も持ちます。
次の IAM 事前定義ロールには、ルーティンに対する権限があります。
| ロール | 説明 |
|---|---|
BigQuery データオーナー(roles/bigquery.dataOwner) |
このロールをルーティンに関して付与すると、次の権限が与えられます。
データオーナーのロールをルーティン レベルで付与しないでください。データ編集者ロールも、ルーティンに関するすべての権限を付与しますが、こちらのロールのほうが権限は少なくなります。 |
BigQuery データ編集者(roles/bigquery.dataEditor) |
このロールをルーティンに関して付与すると、次の権限が与えられます。
|
BigQuery データ閲覧者(roles/bigquery.dataViewer) |
このロールをルーティンに関して付与すると、次の権限が与えられます。
|
BigQuery メタデータ閲覧者(roles/bigquery.metadataViewer) |
このロールをルーティンに関して付与すると、次の権限が与えられます。
|
ルーティンの権限
bigquery.routines で始まる権限のほとんどは、ルーティン レベルで適用されます。ただし、bigquery.routines.create と bigquery.routines.list は異なります。ルーティンを作成して一覧表示するには、親コンテナ(データセット)のロールに bigquery.routines.create 権限と bigquery.routines.list 権限が付与されている必要があります。
次の表に、ルーティンのすべての権限と、それらの権限を付与できる最下位レベルのリソースを示します。
| 権限 | リソース | 説明 |
|---|---|---|
bigquery.routines.create |
データセット | データセットにルーティンを作成する。この権限には、CREATE FUNCTION ステートメントを含むクエリジョブを実行するための bigquery.jobs.create も必要です。 |
bigquery.routines.delete |
ルーティン | ルーティンを削除する。 |
bigquery.routines.get |
ルーティン | 他のユーザーが作成したルーティンを参照する。この権限には、ルーティンを参照するクエリジョブを実行するための bigquery.jobs.create も必要です。また、ルーティンが参照するリソース(テーブルやビューなど)にアクセスするための権限も必要です。 |
bigquery.routines.list |
データセット | データセット内のルーティンを一覧表示し、ルーティンのメタデータを表示する。 |
bigquery.routines.update |
ルーティン | ルーティンの定義とメタデータを更新する。 |
bigquery.routines.getIamPolicy |
ルーティン | ルーティンのアクセス制御を取得する。 |
bigquery.routines.setIamPolicy |
ルーティン | ルーティンのアクセス制御を設定する。 |
ルーティンのアクセス制御を表示する
ルーティンのアクセス制御を表示するには、次のいずれかのオプションを選択します。
コンソール
[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。
[エクスプローラ] ペインでプロジェクトを開き、[データセット] をクリックして、データセットを選択します。
[ルーティン] タブに移動して、ルーティンをクリックします。
[共有] をクリックします。
ルーティンのアクセス制御が [共有] ペインに表示されます。
bq
bq get-iam-policy コマンドは、ルーティンに対するアクセス制御の表示をサポートしていません。
SQL
INFORMATION_SCHEMA.OBJECT_PRIVILEGES ビューには、ルーティンのアクセス制御は表示されません。
API
現在のポリシーを取得するには、routines.getIamPolicy メソッドを呼び出します。
ルーティンへのアクセス権を取り消す
ルーティンへのアクセス権を取り消すには、次のいずれかのオプションを選択します。
コンソール
[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。
[エクスプローラ] ペインでプロジェクトを開き、[データセット] をクリックして、データセットを選択します。
[ルーティン] タブに移動して、ルーティンをクリックします。
詳細ペインで、[共有 > 権限] をクリックします。
[ルーティンの権限] ダイアログで、アクセス権を取り消すプリンシパルを開きます。
[ プリンシパルを削除] をクリックします。
[プリンシパルからロールを削除しますか?] ダイアログで、[削除] をクリックします。
[閉じる] をクリックします。
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
既存のルーティン情報(アクセス制御を含む)を JSON ファイルに書き込むには、
bq get-iam-policyコマンドを使用します。bq get-iam-policy --routine PROJECT_ID:DATASET.ROUTINE > PATH_TO_FILE
次のように置き換えます。
- PROJECT_ID: プロジェクト ID
- DATASET: 更新するルーティンを含むデータセットの名前
- ROUTINE: 更新するリソースの名前
- PATH_TO_FILE: ローカルマシン上の JSON ファイルへのパス
ポリシー ファイルでは、
versionの値は1のままです。この番号は、ポリシーのバージョンではなく、IAM ポリシーのスキーマ バージョンを表します。etagの値はポリシーのバージョン番号です。JSON ファイルの
accessセクションに変更を加えます。specialGroupのエントリ(projectOwners、projectWriters、projectReaders、allAuthenticatedUsers)は削除できます。さらに、userByEmail、groupByEmail、domainも削除できます。たとえば、ルーティンの JSON ファイルの
accessセクションは次のようになります。{ "bindings": [ { "role": "roles/bigquery.dataViewer", "members": [ "user:user@example.com", "group:group@example.com", "domain:google.com", ] }, ], "etag": "BwWWja0YfJA=", "version": 1 }
アクセス ポリシーを更新するには、
bq set-iam-policyコマンドを使用します。bq set-iam-policy --routine PROJECT_ID:DATASET.ROUTINE PATH_TO_FILE
アクセス制御の変更を確認するには、
get-iam-policyコマンドをもう一度使用します。ただし、今回は情報をファイルに書き込む指定を省略します。bq get-iam-policy --routine --format=prettyjson PROJECT_ID:DATASET.ROUTINE
現在のポリシーを取得するには、
routines.getIamPolicyメソッドを呼び出します。ポリシーを編集して、プリンシパルまたはバインディング、あるいはその両方を追加します。ポリシーに必要な形式については、リファレンスのポリシーのトピックをご覧ください。
API
リソースで継承されたアクセス制御を表示する
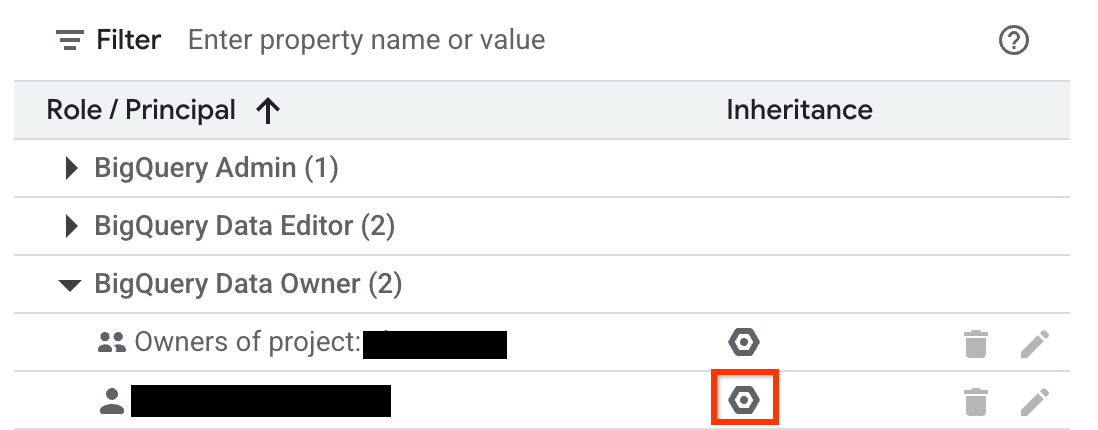
リソースで継承された IAM ロールは、BigQuery ウェブ UI を使用して確認できます。コンソールで継承を表示するには、適切な権限が必要です。データセット、テーブル、ビュー、ルーティンの継承を調べるには:
Google Cloud コンソールで、[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。
[エクスプローラ] ペインで、プロジェクトを開き、[データセット] をクリックして、データセットを選択するか、データセット内のテーブル、ビュー、またはルーティンを選択します。
[共有>権限の管理] をクリックします。
[継承されたロールをテーブルに表示] オプションが有効になっていることを確認します。
![コンソールの [継承されたロールをテーブルに表示] オプション](https://cloud.google.com/bigquery/images/inheritance-toggle.png?authuser=0000&hl=ja)
テーブル内のロールを開きます。
[継承] 列の六角形のアイコンは、ロールが親リソースから継承されたかどうかを示します。
リソースへのアクセスを拒否する
IAM 拒否ポリシーを使用すると、BigQuery リソースへのアクセスにガードレールを設定できます。付与されるロールに関係なく、選択したプリンシパルが特定の権限を使用できないようにする拒否ルールを定義できます。
拒否ポリシーの作成、更新、削除方法については、リソースへのアクセスを拒否するをご覧ください。
特殊なケース
いくつかの BigQuery 権限に IAM 拒否ポリシーを作成する場合は、次のシナリオを検討してください。
承認済みリソース(ビュー、ルーティン、データセット、ストアド プロシージャ)にアクセスすると、オペレーションを実行する直接的な権限がない場合でも、テーブルの作成、削除、操作、テーブルデータの読み取りや変更を行えます。また、基盤となるテーブルでモデルデータまたはメタデータを取得し、他のストアド プロシージャを呼び出すこともできます。この機能は、承認済みリソースに次の権限があることを意味します。
bigquery.tables.getbigquery.tables.listbigquery.tables.getDatabigquery.tables.updateDatabigquery.tables.createbigquery.tables.deletebigquery.routines.getbigquery.routines.listbigquery.datasets.getbigquery.models.getDatabigquery.models.getMetadata
これらの承認済みリソースへのアクセスを拒否するには、拒否ポリシーを作成するとき
deniedPrincipalフィールドに次のいずれかの値を追加します。値 ユースケース principalSet://goog/public:all承認済みリソースを含むすべてのプリンシパルをブロックします。 principalSet://bigquery.googleapis.com/projects/PROJECT_NUMBER/*指定されたプロジェクト内のすべての BigQuery 承認済みリソースをブロックします。 PROJECT_NUMBERは、INT64タイプのプロジェクトに対して自動的に生成される固有識別子です。特定のプリンシパルを拒否ポリシーから除外するには、拒否ポリシーの
exceptionPrincipalsフィールドでそのプリンシパルを指定します。例:exceptionPrincipals: "principalSet://bigquery.googleapis.com/projects/1234/*"BigQuery はジョブオーナーのクエリ結果を 24 時間キャッシュに保存します。ジョブオーナーは、データを含むテーブルに対する
bigquery.tables.getData権限を必要とせずに、キャッシュに保存されたクエリ結果にアクセスできます。したがって、bigquery.tables.getData権限に IAM 拒否ポリシーを追加しても、キャッシュの有効期限が切れるまで、ジョブオーナーのキャッシュに保存された結果へのアクセスはブロックされません。キャッシュに保存された結果へのジョブオーナーのアクセスをブロックするには、bigquery.jobs.create権限に対して別の拒否ポリシーを作成します。拒否ポリシーを使用してデータ読み取りオペレーションをブロックする際に、データへの意図しないアクセスを防ぐため、データセットの既存のサブスクリプションも確認して取り消すことをおすすめします。
データセットのアクセス制御を表示する IAM 拒否ポリシーを作成するには、次の権限を拒否します。
bigquery.datasets.getbigquery.datasets.getIamPolicy
データセットのアクセス制御を更新する IAM 拒否ポリシーを作成するには、次の権限を拒否します。
bigquery.datasets.updatebigquery.datasets.setIamPolicy
次のステップ
projects.testIamPermissions メソッドを使用して、リソースへのユーザー アクセスをテストする方法について学習する。