Introdução às consultas contínuas
Este documento descreve as consultas contínuas do BigQuery.
As consultas contínuas do BigQuery são declarações SQL executadas continuamente. As consultas contínuas permitem-lhe analisar os dados recebidos no BigQuery em tempo real. Pode inserir as linhas de saída produzidas por uma consulta contínua numa tabela do BigQuery ou exportá-las para o Pub/Sub, o Bigtable ou o Spanner. As consultas contínuas podem processar dados que foram escritos em tabelas padrão do BigQuery através de um dos seguintes métodos:
- A API BigQuery Storage Write
- O
tabledata.insertAllmétodo - Carregamento em lote
- A
INSERTinstrução DML
Pode usar consultas contínuas para realizar tarefas sensíveis ao tempo, como criar e agir imediatamente com base em estatísticas, aplicar inferência de aprendizagem automática (AA) em tempo real e replicar dados noutras plataformas. Isto permite-lhe usar o BigQuery como um motor de processamento de dados orientado por eventos para a lógica de decisão da sua aplicação.
O diagrama seguinte mostra fluxos de trabalho de consultas contínuas comuns:
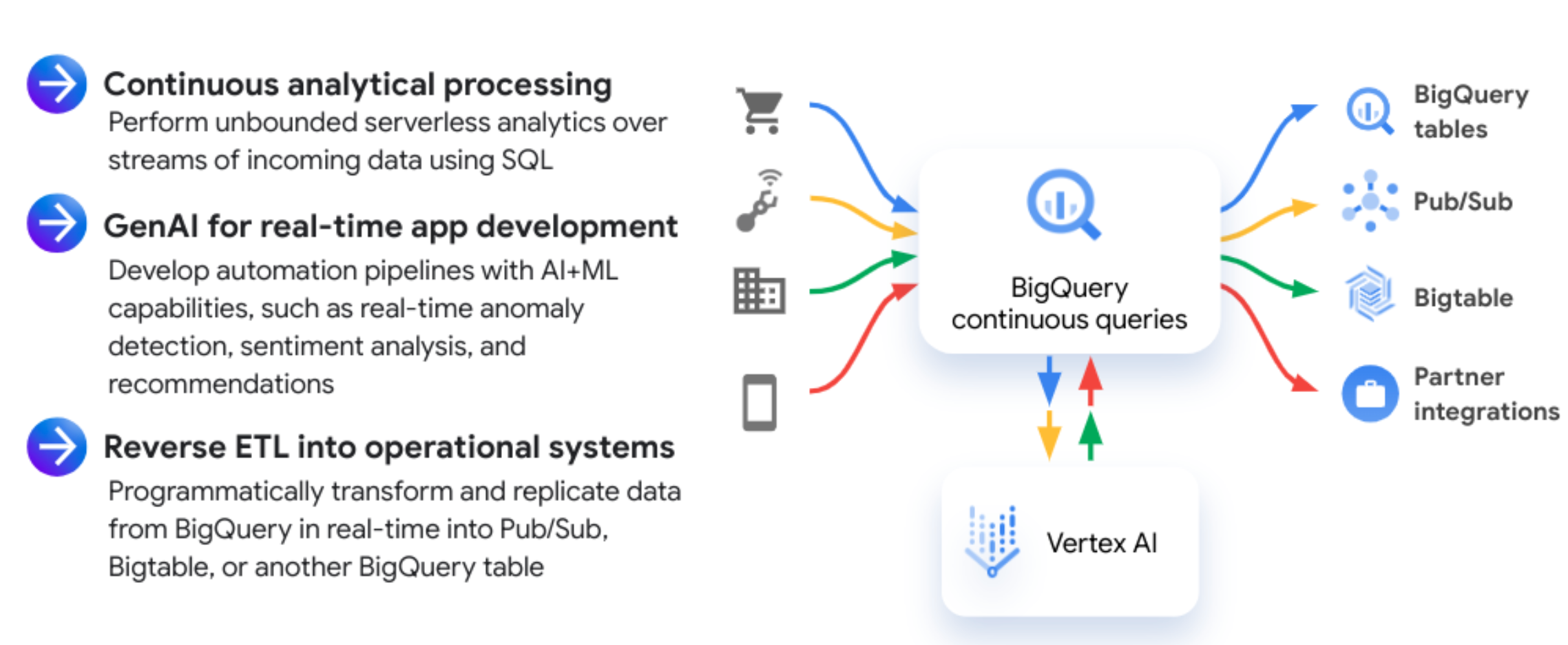
Exemplos de utilização
Seguem-se alguns exemplos de utilização comuns em que pode querer usar consultas contínuas:
- Serviços de interação com o cliente personalizados: use a IA generativa para criar mensagens personalizadas para cada interação com o cliente.
- Deteção de anomalias: crie soluções que lhe permitam realizar a deteção de anomalias e ameaças em dados complexos em tempo real, para que possa reagir aos problemas mais rapidamente.
- Pipelines orientados por eventos personalizáveis: use a integração de consultas contínuas com o Pub/Sub para acionar aplicações a jusante com base nos dados recebidos.
- Enriquecimento de dados e extração de entidades: use consultas contínuas para realizar o enriquecimento e a transformação de dados em tempo real através de funções SQL e modelos de AA.
- Extração, transformação e carregamento (ETL) inversos: execute ETL inversos em tempo real noutros sistemas de armazenamento mais adequados para o fornecimento de aplicações de baixa latência. Por exemplo, analisar ou melhorar os dados de eventos que são escritos no BigQuery e, em seguida, transmiti-los para o Bigtable ou o Spanner para publicação de aplicações.
Operações compatíveis
As seguintes operações são suportadas em consultas contínuas:
- Executar declarações
INSERTpara escrever dados de uma consulta contínua numa tabela do BigQuery. Executar declarações
EXPORT DATApara publicar a saída de consultas contínuas em tópicos do Pub/Sub. Para mais informações, consulte o artigo Exporte dados para o Pub/Sub.A partir de um tópico do Pub/Sub, pode usar os dados com outros serviços, como realizar estatísticas de streaming com o Dataflow ou usar os dados num fluxo de trabalho de integração de aplicações.
Executar declarações
EXPORT DATApara exportar dados do BigQuery para tabelas do Bigtable. Para mais informações, consulte o artigo Exporte dados para o Bigtable.Executar declarações
EXPORT DATApara exportar dados do BigQuery para tabelas do Spanner. Para mais informações, consulte o artigo Exporte dados para o Spanner (ETL inverso).Chamar a seguinte função de IA generativa:
Esta função requer que tenha um modelo remoto do BigQuery ML sobre um modelo do Vertex AI.
Chamar as seguintes funções de IA:
Estas funções requerem que tenha um modelo remoto do BigQuery ML através de uma API Cloud AI.
Normalizar dados numéricos através da função
ML.NORMALIZER.Usar funções GoogleSQL sem estado, por exemplo, funções de conversão. Nas funções sem estado, cada linha é processada independentemente das outras linhas na tabela.
Usando a função
APPENDSHistórico de alterações para iniciar o processamento contínuo de consultas a partir de um ponto específico no tempo.
Autorização
Os Google Cloud tokens de acesso usados quando são executados trabalhos de consulta contínuos têm um tempo de vida (TTL) de dois dias quando são gerados por uma conta de utilizador. Por conseguinte, estas tarefas deixam de ser executadas após dois dias. Os tokens de acesso gerados pelas contas de serviço podem ser executados durante mais tempo, mas continuam a ter de cumprir o tempo de execução máximo da consulta. Para mais informações, consulte o artigo Execute uma consulta contínua através de uma conta de serviço.
Localizações
As consultas contínuas são suportadas nas seguintes localizações:
| Descrição da região | Nome da região | Detalhes | |
|---|---|---|---|
| Americas | |||
| Multirregião dos EUA | us |
||
| Dallas | us-south1 |
|
|
| Iowa | us-central1 |
|
|
| Los Angeles | us-west2 |
||
| México | northamerica-south1 |
||
| Montréal | northamerica-northeast1 |
|
|
| Virgínia do Norte | us-east4 |
||
| Oregon | us-west1 |
|
|
| Salt Lake City | us-west3 |
||
| São Paulo | southamerica-east1 |
|
|
| Carolina do Sul | us-east1 |
||
| Toronto | northamerica-northeast2 |
|
|
| Ásia-Pacífico | |||
| Deli | asia-south2 |
||
| Hong Kong | asia-east2 |
||
| Jacarta | asia-southeast2 |
||
| Melbourne | australia-southeast2 |
||
| Mumbai | asia-south1 |
||
| Osaca | asia-northeast2 |
||
| Seul | asia-northeast3 |
||
| Singapura | asia-southeast1 |
||
| Sydney | australia-southeast1 |
||
| Taiwan | asia-east1 |
||
| Tóquio | asia-northeast1 |
||
| Europa | |||
| Multirregional da UE | eu |
||
| Bélgica | europe-west1 |
|
|
| Berlim | europe-west10 |
||
| Finlândia | europe-north1 |
|
|
| Frankfurt | europe-west3 |
||
| Londres | europe-west2 |
|
|
| Madrid | europe-southwest1 |
|
|
| Milão | europe-west8 |
||
| Países Baixos | europe-west4 |
|
|
| Paris | europe-west9 |
|
|
| Estocolmo | europe-north2 |
|
|
| Turim | europe-west12 |
||
| Varsóvia | europe-central2 |
||
| Zurique | europe-west6 |
|
|
| Médio Oriente | |||
| Doha | me-central1 |
||
| Damã | me-central2 |
||
| Telavive | me-west1 |
||
| África | |||
| Joanesburgo | africa-south1 |
||
Limitações
As consultas contínuas estão sujeitas às seguintes limitações:
- As consultas contínuas do BigQuery não mantêm o estado dos dados carregados. As operações comuns que dependem do estado, como uma
JOINfunção de agregação ou uma função de janela, não são suportadas. Não pode usar as seguintes capacidades de SQL numa consulta contínua:
JOINoperações- Funções de agregação
- Funções de agregação aproximadas
As seguintes cláusulas de consulta:
Os seguintes operadores de consulta:
Consultar operadores definidos
Funções do BigQuery ML que não sejam as indicadas em Operações suportadas
Declarações de linguagem de manipulação de dados (DML) exceto
INSERT.EXPORT DATAdeclarações que não segmentam o Bigtable, o Pub/Sub nem o Spanner.
As consultas contínuas não suportam o processamento de dados de inserção/atualização de captura de dados de alterações (CDC).
As consultas contínuas não suportam tabelas com carateres universais como origem de dados.
As consultas contínuas não suportam tabelas externas como origem de dados.
As consultas contínuas não suportam as vistas INFORMATION_SCHEMA como origem de dados.
As consultas contínuas não suportam tabelas do BigLake para o Apache Iceberg no BigQuery.
As consultas contínuas não suportam as seguintes funcionalidades de segurança do BigQuery:
Quando exporta dados para o Bigtable, só pode segmentar instâncias do Bigtable que se encontram no mesmo Google Cloud limite regional que o conjunto de dados do BigQuery que contém a tabela que está a consultar. Para mais informações, consulte o artigo Considerações sobre a localização. Esta restrição não se aplica à exportação de dados para o Pub/Sub, porque o Pub/Sub é um recurso global.
Quando exporta dados para o Bigtable, o Spanner ou os endpoints de localização do Pub/Sub só pode segmentar recursos do Bigtable, do Spanner ou do Pub/Sub que se encontrem dentro do mesmo Google Cloud limite regional que o conjunto de dados do BigQuery que contém a tabela que está a consultar. Esta restrição não se aplica quando exporta dados para pontos finais globais do Pub/Sub.
Não pode executar uma consulta contínua a partir de uma tela de dados.
Não pode modificar o SQL usado numa consulta contínua enquanto a tarefa de consulta contínua estiver em execução. Para mais informações, consulte o artigo Modifique o SQL de uma consulta contínua.
Se uma tarefa de consulta contínua ficar atrasada no processamento de dados recebidos e tiver um atraso da marca cronológica de saída de mais de 48 horas, falha. Pode executar a consulta novamente e usar a função
APPENDShistórico de alterações para retomar o processamento a partir do momento em que parou a tarefa de consulta contínua anterior. Para mais informações, consulte o artigo Inicie uma consulta contínua a partir de um ponto específico no tempo.Uma consulta contínua configurada com uma conta de utilizador pode ser executada durante um máximo de dois dias. Uma consulta contínua configurada com uma conta de serviço pode ser executada durante um período máximo de 150 dias. Quando o tempo de execução máximo da consulta é atingido, a consulta falha e deixa de processar os dados recebidos.
Embora as consultas contínuas sejam criadas com as funcionalidades de fiabilidade do BigQuery, podem ocorrer problemas temporários ocasionais. Os problemas podem levar a algum reprocessamento automático da sua consulta contínua, o que pode resultar em dados duplicados no resultado da consulta contínua. Crie os seus sistemas a jusante para lidar com esses cenários.
Limitações de reservas
- Tem de criar reservas da edição Enterprise ou Enterprise Plus para executar consultas contínuas. As consultas contínuas não suportam o modelo de faturação de computação a pedido.
- Quando cria uma
CONTINUOUSatribuição de reserva, a reserva associada está limitada a, no máximo, 500 vagas. Pode pedir um aumento deste limite contactando bq-continuous-queries-feedback@google.com. - Não pode criar uma atribuição de reserva que use um tipo de trabalho diferente na mesma reserva que uma atribuição de reserva de consulta contínua.
- Não pode configurar a simultaneidade de consultas contínuas. O BigQuery determina automaticamente o número de consultas contínuas que podem ser executadas em simultâneo, com base nas atribuições de reservas disponíveis que usam o tipo de tarefa
CONTINUOUS. - Quando executa várias consultas contínuas com a mesma reserva, os trabalhos individuais podem não dividir os recursos disponíveis de forma justa, conforme definido pela equidade do BigQuery.
Escala automática de slots
As consultas contínuas podem usar a escalabilidade automática de ranhuras para dimensionar dinamicamente a capacidade atribuída de forma a acomodar a sua carga de trabalho. À medida que a carga de trabalho das suas consultas contínuas aumenta ou diminui, o BigQuery ajusta dinamicamente os seus slots.
Depois de uma consulta contínua começar a ser executada, esta ouve ativamente os dados recebidos, o que consome recursos de slots. Embora uma reserva com uma consulta contínua em execução não seja reduzida para zero espaços, espera-se que uma consulta contínua inativa que esteja principalmente a ouvir dados recebidos consuma uma quantidade mínima de espaços, normalmente cerca de 1 espaço.
Partilha de horários disponíveis inativos
As consultas contínuas podem usar a partilha de espaços inativos para partilhar recursos de espaços não usados com outras reservas e tipos de tarefas.
- A
CONTINUOUSatribuição de reserva continua a ser necessária para executar uma consulta contínua e não pode depender apenas de espaços livres de outras reservas. Assim, uma atribuição de reservaCONTINUOUSrequer uma base de horário diferente de zero ou uma configuração de dimensionamento automático de horário diferente de zero. - Só é possível partilhar espaços de base inativos ou espaços comprometidos de uma atribuição de reserva
CONTINUOUS. Os horários com ajuste automático de escala não são partilháveis como horários disponíveis para outras reservas.
Preços
As consultas contínuas usam os preços de computação de capacidade do BigQuery, que são medidos em slots.
Para executar consultas contínuas, tem de ter uma reserva que use a edição Enterprise ou Enterprise Plus e uma atribuição de reserva que use o tipo de tarefa CONTINUOUS.
A utilização de outros recursos do BigQuery, como o carregamento e o armazenamento de dados, é cobrada às taxas apresentadas nos preços do BigQuery.
A utilização de outros serviços que recebem resultados de consultas contínuas ou que são chamados durante o processamento de consultas contínuas é cobrada às taxas publicadas para esses serviços. Para os preços de outros Google Cloud serviços usados por consultas contínuas, consulte os seguintes tópicos:
O que se segue?
Experimente criar uma consulta contínua.