Carregue dados do Cloud Storage para o BigQuery
Pode carregar dados do Cloud Storage para o BigQuery através do conetor do Serviço de transferência de dados do BigQuery para o Cloud Storage. Com o Serviço de transferência de dados do BigQuery, pode agendar tarefas de transferência recorrentes que adicionam os dados mais recentes do Cloud Storage ao BigQuery.
Antes de começar
Antes de criar uma transferência de dados do Cloud Storage, faça o seguinte:
- Verifique se concluiu todas as ações necessárias em Ativar o Serviço de transferência de dados do BigQuery.
- Obtenha o seu URI do Cloud Storage.
- Crie um conjunto de dados do BigQuery para armazenar os seus dados.
- Crie a tabela de destino para a transferência de dados e especifique a definição do esquema.
- Se planeia especificar uma chave de encriptação gerida pelo cliente (CMEK), certifique-se de que a sua conta de serviço tem autorizações para encriptar e desencriptar e que tem o ID de recurso da chave do Cloud KMS necessário para usar a CMEK. Para obter informações sobre como a CMEK funciona com o Serviço de transferência de dados do BigQuery, consulte o artigo Especifique a chave de encriptação com transferências.
Limitações
As transferências de dados recorrentes do Cloud Storage para o BigQuery estão sujeitas às seguintes limitações:
- Todos os ficheiros que correspondam aos padrões definidos por um caráter universal ou por parâmetros de tempo de execução para a sua transferência de dados têm de partilhar o mesmo esquema que definiu para a tabela de destino, ou a transferência falha. As alterações ao esquema da tabela entre execuções também fazem com que a transferência falhe.
- Uma vez que os objetos do Cloud Storage podem ter várias versões, é importante ter em atenção que os objetos do Cloud Storage arquivados não são suportados para transferências de dados do BigQuery. Os objetos têm de estar ativos para serem transferidos.
- Ao contrário dos carregamentos individuais de dados do Cloud Storage para o BigQuery, para transferências de dados contínuas, tem de criar a tabela de destino antes de configurar a transferência. Para ficheiros CSV e JSON, também tem de definir o esquema de tabela antecipadamente. O BigQuery não consegue criar a tabela como parte do processo de transferência de dados recorrente.
- As transferências de dados do Cloud Storage definem o parâmetro Write preference como
APPENDpor predefinição. Neste modo, só é possível carregar um ficheiro não modificado para o BigQuery uma vez. Se a propriedadelast modification timedo ficheiro for atualizada, o ficheiro é recarregado. O Serviço de transferência de dados do BigQuery não garante que todos os ficheiros sejam transferidos ou transferidos apenas uma vez se os ficheiros do Cloud Storage forem modificados durante uma transferência de dados. Está sujeito às seguintes limitações quando carrega dados para o BigQuery a partir de um contentor do Cloud Storage:
O BigQuery não garante a consistência dos dados para origens de dados externas. As alterações aos dados subjacentes durante a execução de uma consulta podem resultar num comportamento inesperado.
O BigQuery não suporta o controlo de versões de objetos do Cloud Storage. Se incluir um número de geração no URI do Cloud Storage, a tarefa de carregamento falha.
Consoante o formato dos dados de origem do Cloud Storage, podem existir limitações adicionais. Para mais informações, consulte:
O contentor do Cloud Storage tem de estar numa localização compatível com a região ou a multirregião do conjunto de dados de destino no BigQuery. Isto é conhecido como colocação. Consulte o artigo Localizações de dados de transferência do Cloud Storage para ver detalhes.
Intervalos mínimos
- Os ficheiros de origem são recolhidos para transferência de dados imediatamente, sem idade mínima do ficheiro.
- O intervalo de tempo mínimo entre transferências de dados recorrentes é de 15 minutos. O intervalo predefinido para uma transferência de dados recorrente é de 24 horas.
- Pode configurar uma transferência orientada por eventos para agendar automaticamente transferências de dados a intervalos mais baixos.
Autorizações necessárias
Quando carrega dados para o BigQuery, precisa de autorizações que lhe permitam carregar dados para partições e tabelas do BigQuery novas ou existentes. Se estiver a carregar dados do Cloud Storage, também precisa de ter acesso ao contentor que contém os seus dados. Certifique-se de que tem as seguintes autorizações necessárias:
BigQuery: certifique-se de que a pessoa ou a conta de serviço que está a criar a transferência de dados tem as seguintes autorizações no BigQuery:
- Autorizações
bigquery.transfers.updatepara criar a Transferência de dados - Autorizações de
bigquery.datasets.getebigquery.datasets.updateno conjunto de dados de destino
A
bigquery.adminfunção de IAM predefinida inclui as autorizaçõesbigquery.transfers.update,bigquery.datasets.updateebigquery.datasets.get. Para mais informações sobre as funções do IAM no Serviço de transferência de dados do BigQuery, consulte o artigo Controlo de acesso.- Autorizações
Cloud Storage: são necessárias
storage.objects.getautorizações no contentor individual ou superior. Se estiver a usar um caráter universal de URI, também tem de ter autorizaçõesstorage.objects.list. Se quiser eliminar os ficheiros de origem após cada transferência bem-sucedida, também precisa de autorizaçõesstorage.objects.delete. Astorage.objectAdminfunção de IAM predefinida inclui todas estas autorizações.
Configure uma transferência do Cloud Storage
Para criar uma transferência de dados do Cloud Storage no Serviço de transferência de dados do BigQuery:
Consola
Aceda à página Transferências de dados na Google Cloud consola.
Clique em Criar transferência.
Na secção Tipo de origem, para Origem, escolha Google Cloud Storage.
Na secção Nome da configuração de transferência, em Nome a apresentar, introduza um nome para a transferência de dados, como
My Transfer. O nome da transferência pode ser qualquer valor que lhe permita identificar a transferência se precisar de a modificar mais tarde.
Na secção Opções de programação, selecione uma Frequência de repetição:
Se selecionar Horas, Dias, Semanas ou Meses, também tem de especificar uma frequência. Também pode selecionar Personalizado para especificar uma frequência de repetição personalizada. Pode selecionar Começar agora ou Começar a uma hora definida e indicar uma data de início e um tempo de execução.
Se selecionar A pedido, esta transferência de dados é executada quando aciona manualmente a transferência.
Se selecionar Acionado por eventos, também tem de especificar uma subscrição do Pub/Sub. Escolha o nome da subscrição ou clique em Criar uma subscrição. Esta opção ativa uma transferência orientada por eventos que aciona execuções de transferências quando os eventos chegam à subscrição do Pub/Sub.
Na secção Definições de destino, para Conjunto de dados de destino, escolha o conjunto de dados que criou para armazenar os seus dados.
Na secção Detalhes da origem de dados:
- Em Tabela de destino, introduza o nome da tabela de destino. A tabela de destino tem de seguir as regras de nomenclatura de tabelas. Os nomes das tabelas de destino também suportam parâmetros.
- Para o URI do Cloud Storage, introduza o URI do Cloud Storage. Os carateres universais e os parâmetros são compatíveis. Se o URI não corresponder a nenhum ficheiro, não são substituídos dados na tabela de destino.
Para Escrever preferência, escolha:
- APPEND para acrescentar incrementalmente novos dados à tabela de destino existente. APPEND é o valor predefinido para Preferência de escrita.
- MIRROR para substituir os dados na tabela de destino durante cada execução da transferência de dados.
Para mais informações sobre como o Serviço de transferência de dados do BigQuery carrega dados usando APPEND ou MIRROR, consulte o artigo Carregamento de dados para transferências do Cloud Storage. Para mais informações sobre o campo
writeDisposition, consulteJobConfigurationLoad.Para Eliminar ficheiros de origem após a transferência, selecione a caixa se quiser eliminar os ficheiros de origem após cada transferência de dados bem-sucedida. A eliminação de trabalhos é feita com base no melhor esforço. As tarefas de eliminação não são repetidas se a primeira tentativa de eliminar os ficheiros de origem falhar.
Na secção Opções de transferência:
- Em Todos os formatos:
- Para Número de erros permitidos, introduza o número máximo de registos inválidos que o BigQuery pode ignorar quando executa a tarefa. Se o número de registos inválidos exceder este valor, é devolvido um erro
invalidno resultado da tarefa e a tarefa falha. O valor predefinido é0. - (Opcional) Para Tipos de destino decimal, introduza uma lista separada por vírgulas dos possíveis tipos de dados SQL para os quais os valores decimais de origem podem ser convertidos. O tipo de dados SQL selecionado para a conversão depende das seguintes condições:
- O tipo de dados selecionado para a conversão vai ser o primeiro tipo de dados na seguinte lista que suporta a precisão e a escala dos dados de origem, por esta ordem:
NUMERIC,BIGNUMERICeSTRING. - Se nenhum dos tipos de dados indicados suportar a precisão e a escala, é selecionado o tipo de dados que suporta o intervalo mais amplo na lista especificada. Se um valor exceder o intervalo suportado ao ler os dados de origem, é gerado um erro.
- O tipo de dados
STRINGsuporta todos os valores de precisão e escala. - Se este campo for deixado em branco, o tipo de dados é predefinido como
NUMERIC,STRINGpara ORC eNUMERICpara os outros formatos de ficheiros. - Este campo não pode conter tipos de dados duplicados.
- A ordem dos tipos de dados que indica neste campo é ignorada.
- O tipo de dados selecionado para a conversão vai ser o primeiro tipo de dados na seguinte lista que suporta a precisão e a escala dos dados de origem, por esta ordem:
- Para Número de erros permitidos, introduza o número máximo de registos inválidos que o BigQuery pode ignorar quando executa a tarefa. Se o número de registos inválidos exceder este valor, é devolvido um erro
- Em JSON, CSV, para Ignorar valores desconhecidos, selecione a caixa se quiser que a transferência de dados elimine dados que não se enquadram no esquema da tabela de destino.
- Em AVRO, para Usar tipos lógicos Avro, selecione a caixa se quiser que a transferência de dados converta os tipos lógicos Avro nos respetivos tipos de dados do BigQuery. O comportamento predefinido é ignorar o atributo
logicalTypepara a maioria dos tipos e usar o tipo Avro subjacente. Em CSV:
- Em Delimitador de campo, introduza o caráter que separa os campos. O valor predefinido é uma vírgula.
- Para Carater de aspas, introduza o carater usado para
colocar entre aspas secções de dados num ficheiro CSV. O valor predefinido é uma aspa dupla (
"). - Em Linhas de cabeçalho a ignorar, introduza o número de linhas de cabeçalho nos ficheiros de origem se não quiser importá-las. O valor predefinido é
0. - Para Permitir novas linhas entre aspas, selecione a caixa se quiser permitir novas linhas em campos entre aspas.
- Para Permitir linhas irregulares, selecione a caixa se quiser permitir a transferência de dados de linhas com colunas em falta.
NULLABLE
Consulte as opções apenas de CSV para mais informações.
- Em Todos os formatos:
No menu Conta de serviço, selecione uma conta de serviço das contas de serviço associadas ao seu Google Cloud projeto. Pode associar uma conta de serviço à transferência de dados em vez de usar as suas credenciais de utilizador. Para mais informações sobre a utilização de contas de serviço com transferências de dados, consulte o artigo Use contas de serviço.
- Se iniciou sessão com uma identidade federada, é necessária uma conta de serviço para criar uma transferência de dados. Se iniciou sessão com uma Conta Google, uma conta de serviço para a transferência de dados é opcional.
- A conta de serviço tem de ter as autorizações necessárias para o BigQuery e o Cloud Storage.
Opcional: na secção Opções de notificação:
- Clique no botão para ativar as notificações por email. Quando ativa esta opção, o proprietário da configuração da Transferência de dados recebe uma notificação por email quando uma execução da transferência falha.
- Em Selecionar um tópico do Pub/Sub, escolha o nome do tópico ou clique em Criar um tópico. Esta opção configura notificações executadas pelo Pub/Sub para a transferência.
Opcional: na secção Opções avançadas, se usar CMEKs, selecione Chave gerida pelo cliente. É apresentada uma lista das suas CMEKs disponíveis para que possa escolher. Para obter informações sobre como as CMEKs funcionam com o Serviço de transferência de dados do BigQuery, consulte o artigo Especifique a chave de encriptação com transferências.
Clique em Guardar.
bq
Introduza o comando bq mk e forneça a flag de criação de transferência —
--transfer_config. Os seguintes indicadores também são obrigatórios:
--data_source--display_name--target_dataset--params
Sinalizadores opcionais:
--destination_kms_key: especifica o ID de recurso da chave para a chave do Cloud KMS se usar uma chave de encriptação gerida pelo cliente (CMEK) para esta transferência de dados. Para obter informações sobre como as CMEKs funcionam com o Serviço de transferência de dados do BigQuery, consulte o artigo Especifique a chave de encriptação com transferências.--service_account_name: especifica uma conta de serviço a usar para a autenticação de transferência do Cloud Storage em vez da sua conta de utilizador.
bq mk \ --transfer_config \ --project_id=PROJECT_ID \ --data_source=DATA_SOURCE \ --display_name=NAME \ --target_dataset=DATASET \ --destination_kms_key="DESTINATION_KEY" \ --params='PARAMETERS' \ --service_account_name=SERVICE_ACCOUNT_NAME
Onde:
- PROJECT_ID é o ID do seu projeto. Se não for fornecido
--project_idpara especificar um projeto em particular, é usado o projeto predefinido. - DATA_SOURCE é a origem de dados, por exemplo,
google_cloud_storage. - NAME é o nome a apresentar da configuração de transferência de dados. O nome da transferência pode ser qualquer valor que lhe permita identificar a transferência se precisar de a modificar mais tarde.
- DATASET é o conjunto de dados de destino para a configuração de transferência.
- DESTINATION_KEY: o ID do recurso da chave do Cloud KMS, por exemplo,
projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name. - PARAMETERS contém os parâmetros da configuração de transferência criada no formato JSON. Por exemplo:
--params='{"param":"param_value"}'.destination_table_name_template: o nome da tabela do BigQuery de destino.data_path_template: o URI do Cloud Storage que contém os seus ficheiros a transferir. Os carateres universais e os parâmetros são compatíveis.write_disposition: determina se os ficheiros correspondentes são anexados à tabela de destino ou espelhados na totalidade. Os valores suportados sãoAPPENDouMIRROR. Para obter informações sobre como o Serviço de transferência de dados do BigQuery anexa ou reflete dados em transferências do Cloud Storage, consulte o artigo Carregamento de dados para transferências do Cloud Storage.file_format: o formato dos ficheiros que quer transferir. O formato pode serCSV,JSON,AVRO,PARQUETouORC. O valor predefinido éCSV.max_bad_records: para qualquer valor defile_format, o número máximo de registos inválidos que podem ser ignorados. O valor predefinido é0.decimal_target_types: para qualquer valorfile_format, uma lista separada por vírgulas dos possíveis tipos de dados SQL para os quais os valores decimais de origem podem ser convertidos. Se este campo não for fornecido, o tipo de dados é predefinido como"NUMERIC,STRING"paraORCe"NUMERIC"para os outros formatos de ficheiros.ignore_unknown_values: para qualquer valor defile_format, defina comoTRUEpara aceitar linhas que contenham valores que não correspondam ao esquema. Para mais informações, consulte os detalhes do campoignoreUnknownvaluesnaJobConfigurationLoadtabela de referência.use_avro_logical_types: para valores deAVROfile_format, defina comoTRUEpara interpretar os tipos lógicos nos respetivos tipos (por exemplo,TIMESTAMP), em vez de usar apenas os respetivos tipos não processados (por exemplo,INTEGER).parquet_enum_as_string: para valoresPARQUETfile_format, defina comoTRUEpara inferir o tipo lógicoPARQUETENUMcomoSTRINGem vez do predefinidoBYTES.parquet_enable_list_inference: para valores dePARQUETfile_format, defina comoTRUEpara usar a inferência de esquemas especificamente para o tipo lógicoPARQUETLIST.reference_file_schema_uri: um caminho do URI para um ficheiro de referência com o esquema do leitor.field_delimiter: para valoresCSVfile_format, um caráter que separa os campos. O valor predefinido é uma vírgula.quote: para valoresCSVfile_format, um caráter usado para colocar entre aspas secções de dados num ficheiro CSV. O valor predefinido é uma aspa dupla (").skip_leading_rows: para valoresCSVfile_format, indique o número de linhas de cabeçalho iniciais que não quer importar. O valor predefinido é 0.allow_quoted_newlines: para valoresCSVfile_format, defina comoTRUEpara permitir novas linhas em campos entre aspas.allow_jagged_rows: para valoresCSVfile_format, defina comoTRUEpara aceitar linhas que não tenham colunas opcionais finais. Os valores em falta são preenchidos comNULL.preserve_ascii_control_characters: para valoresCSVfile_format, defina comoTRUEpara preservar quaisquer carateres de controlo ASCII incorporados.encoding: especifique o tipo de codificaçãoCSV. Os valores suportados sãoUTF8,ISO_8859_1,UTF16BE,UTF16LE,UTF32BEeUTF32LE.delete_source_files: definido comoTRUEpara eliminar os ficheiros de origem após cada transferência bem-sucedida. As tarefas de eliminação não são executadas novamente se a primeira tentativa de eliminar o ficheiro de origem falhar. O valor predefinido éFALSE.
- SERVICE_ACCOUNT_NAME é o nome da conta de serviço usado para autenticar a sua transferência. A conta de serviço deve ser propriedade do mesmo
project_idusado para criar a transferência e deve ter todas as autorizações necessárias.
Por exemplo, o seguinte comando cria uma transferência de dados do Cloud Storage
denominada My Transfer com um valor de data_path_template de
gs://mybucket/myfile/*.csv, o conjunto de dados de destino mydataset e file_format
CSV. Este exemplo inclui valores não predefinidos para os parâmetros opcionais associados ao CSV file_format.
A transferência de dados é criada no projeto predefinido:
bq mk --transfer_config \
--target_dataset=mydataset \
--project_id=myProject \
--display_name='My Transfer' \
--destination_kms_key=projects/myproject/locations/mylocation/keyRings/myRing/cryptoKeys/myKey \
--params='{"data_path_template":"gs://mybucket/myfile/*.csv",
"destination_table_name_template":"MyTable",
"file_format":"CSV",
"max_bad_records":"1",
"ignore_unknown_values":"true",
"field_delimiter":"|",
"quote":";",
"skip_leading_rows":"1",
"allow_quoted_newlines":"true",
"allow_jagged_rows":"false",
"delete_source_files":"true"}' \
--data_source=google_cloud_storage \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com projects/862514376110/locations/us/transferConfigs/ 5dd12f26-0000-262f-bc38-089e0820fe38
Depois de executar o comando, recebe uma mensagem semelhante à seguinte:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Siga as instruções e cole o código de autenticação na linha de comandos.
API
Use o método projects.locations.transferConfigs.create
e forneça uma instância do recurso TransferConfig.
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Especifique a chave de encriptação com transferências
Pode especificar chaves de encriptação geridas pelo cliente (CMEKs) para encriptar dados para uma execução de transferência. Pode usar uma CMEK para suportar transferências a partir do Cloud Storage.Quando especifica uma CMEK com uma transferência, o Serviço de transferência de dados do BigQuery aplica a CMEK a qualquer cache intermédia no disco dos dados carregados, para que todo o fluxo de trabalho de transferência de dados esteja em conformidade com a CMEK.
Não é possível atualizar uma transferência existente para adicionar uma CMEK se a transferência não tiver sido criada originalmente com uma CMEK. Por exemplo, não pode alterar uma tabela de destino que foi originalmente encriptada por predefinição para ser encriptada com CMEK. Por outro lado, também não pode alterar uma tabela de destino encriptada com CMEK para ter um tipo de encriptação diferente.
Pode atualizar uma CMEK para uma transferência se a configuração de transferência tiver sido criada originalmente com uma encriptação CMEK. Quando atualiza uma CMEK para uma configuração de transferência, o Serviço de transferência de dados do BigQuery propaga a CMEK para as tabelas de destino na execução seguinte da transferência, em que o Serviço de transferência de dados do BigQuery substitui todas as CMEKs desatualizadas pela nova CMEK durante a execução da transferência. Para mais informações, consulte o artigo Atualize uma transferência.
Também pode usar as chaves predefinidas do projeto. Quando especifica uma chave predefinida do projeto com uma transferência, o Serviço de transferência de dados do BigQuery usa a chave predefinida do projeto como a chave predefinida para quaisquer novas configurações de transferência.
Acione manualmente uma transferência
Além das transferências de dados agendadas automaticamente a partir do Cloud Storage, pode acionar manualmente uma transferência para carregar ficheiros de dados adicionais.
Se a configuração de transferência for parametrizada em tempo de execução, tem de especificar um intervalo de datas para o qual serão iniciadas transferências adicionais.
Para acionar uma transferência de dados:
Consola
Aceda à página do BigQuery na Google Cloud consola.
Clique em Transferências de dados.
Selecione a transferência de dados na lista.
Clique em Executar transferência agora ou Agendar preenchimento (para configurações de transferência parametrizadas em tempo de execução).
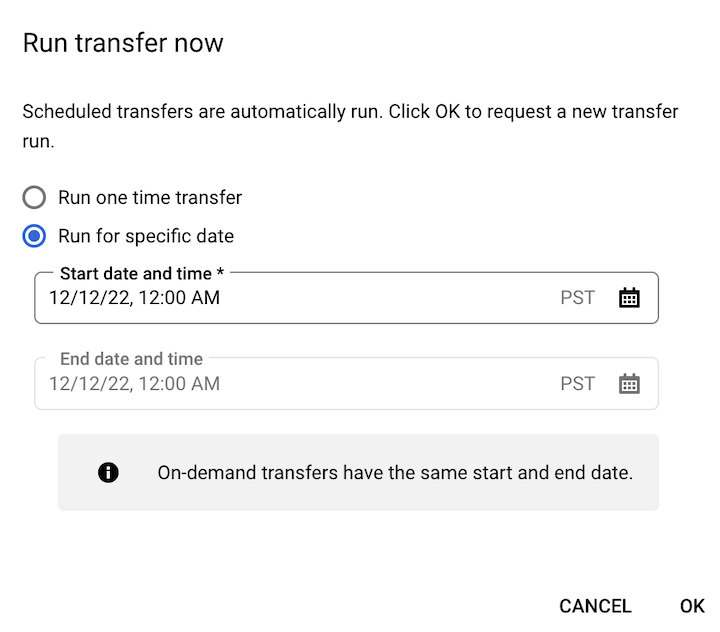
Se clicou em Executar transferência agora, selecione Executar transferência única ou Executar para uma data específica, conforme aplicável. Se selecionou a opção Executar para uma data específica, selecione uma data e uma hora específicas:
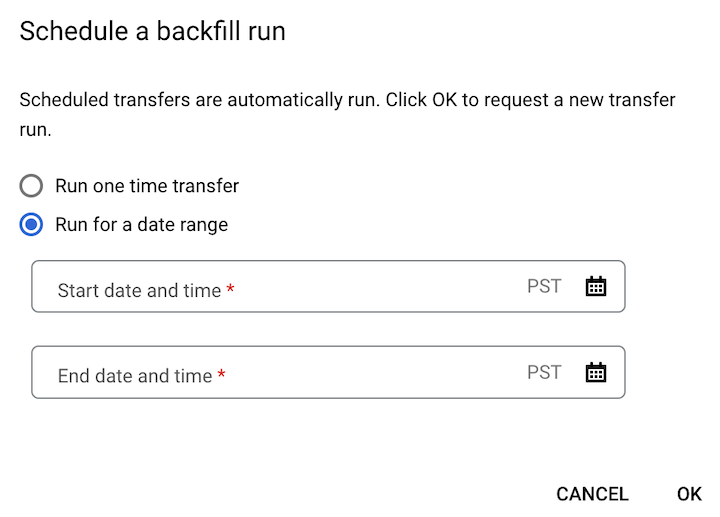
Se clicou em Agendar preenchimento, selecione Executar transferência única ou Executar para um intervalo de datas, conforme aplicável. Se selecionou a opção Executar durante um intervalo de datas, selecione uma data e uma hora de início e de fim:
Clique em OK.
bq
Introduza o comando bq mk
e forneça a flag --transfer_run. Pode usar a flag --run_time
ou as flags --start_time e --end_time.
bq mk \ --transfer_run \ --start_time='START_TIME' \ --end_time='END_TIME' \ RESOURCE_NAME
bq mk \ --transfer_run \ --run_time='RUN_TIME' \ RESOURCE_NAME
Onde:
START_TIME e END_TIME são indicações de tempo que terminam em
Zou contêm uma compensação de fuso horário válida. Por exemplo:2017-08-19T12:11:35.00Z2017-05-25T00:00:00+00:00
RUN_TIME é uma data/hora que especifica a hora para agendar a execução da transferência de dados. Se quiser executar uma transferência única para a hora atual, pode usar a flag
--run_time.RESOURCE_NAME é o nome do recurso da transferência (também denominado configuração de transferência), por exemplo,
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7. Se não souber o nome do recurso da transferência, execute o comandobq ls --transfer_config --transfer_location=LOCATIONpara encontrar o nome do recurso.
API
Use o método projects.locations.transferConfigs.startManualRuns
e forneça o recurso de configuração de transferência através do parâmetro parent.
O que se segue?
- Saiba mais sobre os parâmetros de tempo de execução nas transferências do Cloud Storage.
- Saiba mais acerca do Serviço de transferência de dados do BigQuery.