Transmite actualizaciones de tablas con captura de datos modificados
La captura de datos modificados (CDC) de BigQuery actualiza las tablas de BigQuery mediante el procesamiento y la aplicación de cambios transmitidos a los datos existentes. Esta sincronización se realiza a través de las operaciones de inserción y actualización y de eliminación de filas que se transmiten en tiempo real a través de la API de BigQuery Storage Write, con la que debes estar familiarizado antes de continuar.
Antes de comenzar
Otorga roles de Identity and Access Management (IAM) que les den a los usuarios los permisos necesarios para realizar cada tarea de este documento y asegúrate de que tu flujo de trabajo cumpla con cada requisito.
Permisos necesarios
Para obtener el permiso que
necesitas para usar la API de Storage Write,
pídele a tu administrador que te otorgue el
rol de IAM de editor de datos de BigQuery (roles/bigquery.dataEditor).
Para obtener más información sobre cómo otorgar roles, consulta Administra el acceso a proyectos, carpetas y organizaciones.
Este rol predefinido contiene el permiso bigquery.tables.updateData, que se requiere para usar la API de Storage Write.
También puedes obtener este permiso con roles personalizados o con otros roles predefinidos.
Para obtener más información sobre los roles y permisos de IAM en BigQuery, consulta Introducción a IAM.
Requisitos previos
Para usar la CDC de BigQuery, tu flujo de trabajo debe cumplir con las siguientes condiciones:
- Debes usar la API de Storage Write en la transmisión predeterminada.
- Debes usar el formato protobuf como formato de transferencia. No se admite el formato Apache Arrow.
- Debes declarar claves primarias para la tabla de destino en BigQuery. Se admiten claves primarias compuestas que contengan hasta 16 columnas.
- Los recursos de procesamiento de BigQuery suficientes deben estar disponibles para realizar las operaciones de fila de la CDC. Ten en cuenta que, si las operaciones de modificación de filas de la CDC fallan, podrías retener de forma involuntaria los datos que deseas borrar. Para obtener más información, consulta Consideraciones sobre datos borrados.
Especificar cambios en los registros existentes
En la CDC de BigQuery, la seudocolumna _CHANGE_TYPE indica el tipo de cambio que se procesará para cada fila. Para usar la CDC, configura _CHANGE_TYPE cuando transmitas modificaciones de filas mediante la API de Storage Write. La seudocolumna _CHANGE_TYPE solo acepta los valores UPSERT y DELETE.
Una tabla se considera habilitada por los CDC mientras la API de Storage Write son transmisiones de modificaciones de las filas de la tabla de esta manera.
Ejemplo con valores UPSERT y DELETE
Considera la siguiente tabla en BigQuery:
| ID | Nombre | Salario |
|---|---|---|
| 100 | Charlie | 2000 |
| 101 | Tal | 3000 |
| 102 | Lee | 5000 |
La API de Storage Write transmite las siguientes modificaciones de filas:
| ID | Nombre | Salario | _CHANGE_TYPE |
|---|---|---|---|
| 100 | BORRAR | ||
| 101 | Tal | 8000 | UPSERT |
| 105 | Izumi | 6000 | UPSERT |
La tabla actualizada ahora es la siguiente:
| ID | Nombre | Salario |
|---|---|---|
| 101 | Tal | 8000 |
| 102 | Lee | 5000 |
| 105 | Izumi | 6000 |
Administra la obsolescencia de la tabla
De forma predeterminada, cada vez que ejecutas una consulta, BigQuery muestra los resultados más actualizados. A fin de proporcionar los resultados más recientes cuando se consulta una tabla habilitada para la CDC, BigQuery debe aplicar cada modificación de fila transmitida hasta la hora de inicio de la consulta, de modo que se consulte la versión más reciente de la tabla. Aplicar estas modificaciones de filas al momento de ejecutar la consulta aumenta la latencia y el costo de la consulta. Sin embargo, si no necesitas resultados de consulta completamente actualizados, puedes reducir el costo y la latencia en tus consultas mediante la configuración de la opción max_staleness en la tabla. Cuando se configura esta opción, BigQuery aplica modificaciones de fila al menos una vez dentro del intervalo que define el valor max_staleness, lo que te permite ejecutar consultas sin esperar a que se apliquen las actualizaciones y esto genera cierta obsolescencia de los datos.
Este comportamiento es especialmente útil para los paneles y los informes en los que la actualidad de los datos no es esencial. También es útil para la administración de costos, ya que te brinda más control sobre la frecuencia con la que BigQuery aplica modificaciones de fila.
Consultar tablas con la opción max_staleness configurada
Cuando consultas una tabla con la opción max_staleness establecida, BigQuery muestra el resultado según el valor de max_staleness y la hora en que se produjo el último trabajo de aplicación, que se representa mediante la marca de tiempo upsert_stream_apply_watermark de la tabla.
Considera el siguiente ejemplo, en el que una tabla tiene la opción max_staleness establecida en 10 minutos y el trabajo de aplicación más reciente ocurrió en T20:
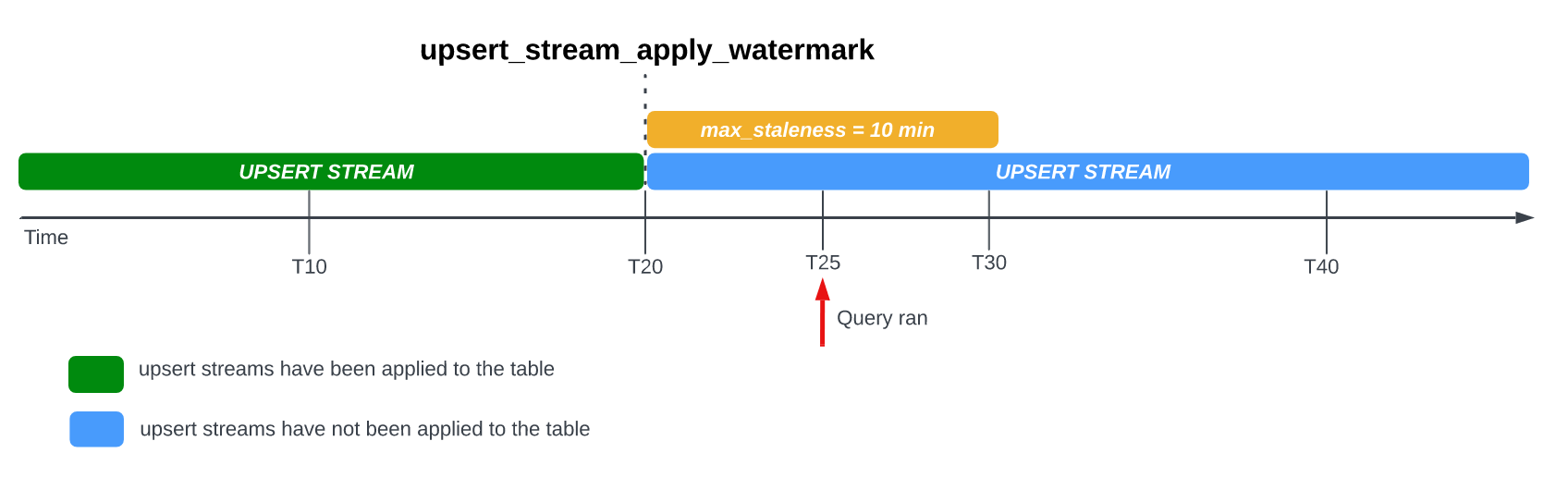
Si consultas la tabla en T25, la versión actual de la tabla está obsoleta por 5 minutos, lo que es menor que el intervalo de max_staleness de 10 minutos. En este caso, BigQuery muestra la versión de la tabla en T20, lo que significa que los datos que se muestran también están obsoletos 5 minutos.
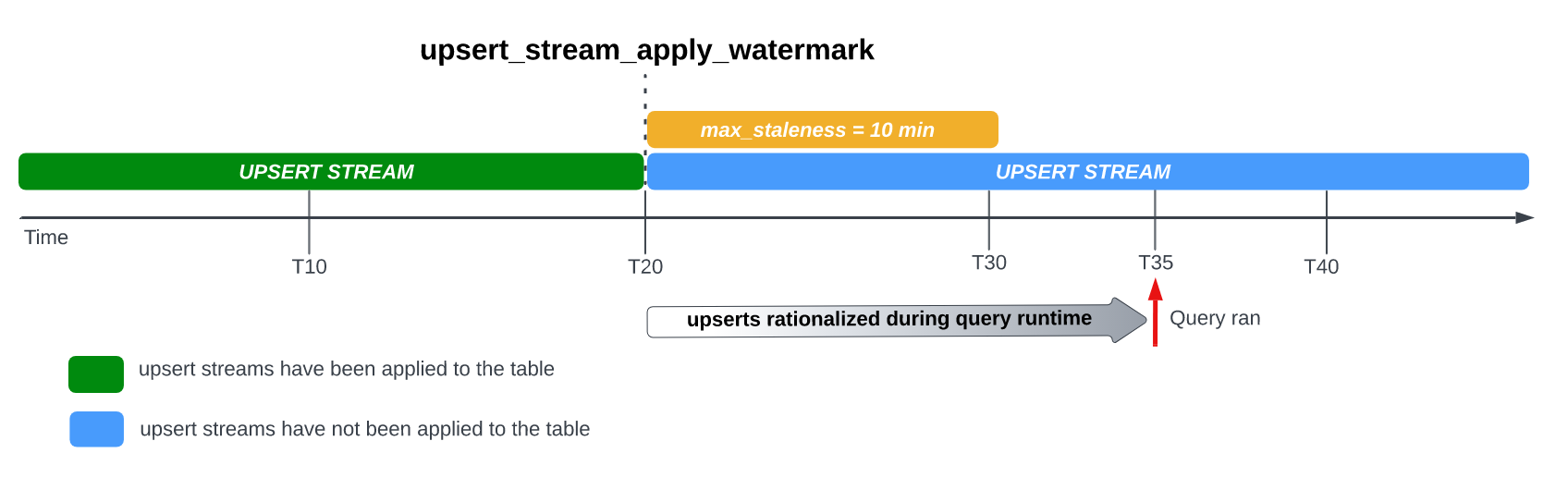
Cuando configuras la opción max_staleness en tu tabla, BigQuery aplica las modificaciones de filas pendientes al menos una vez dentro del intervalo max_staleness. Sin embargo, en algunos casos, es posible que BigQuery no complete el proceso de aplicación de estas modificaciones de filas pendientes dentro del intervalo.
Por ejemplo, si consultas la tabla en T35 y el proceso de aplicación de modificaciones de filas pendientes no se completó, la versión actual de la tabla estará obsoleta 15 minutos, lo que supera el intervalo de max_staleness de 10 minutos
En este caso, en el momento de la ejecución de la consulta, BigQuery aplica todas las
modificaciones de filas entre T20 y T35 para la consulta actual, lo que significa que los datos
consultados están completamente actualizados, a costa de una latencia adicional en la consulta.
Esto se considera un trabajo de combinación del entorno de ejecución.
Valor recomendado de max_staleness de tabla
Por lo general, el valor max_staleness de una tabla debe ser el más alto de los dos valores siguientes:
- La obsolescencia máxima tolerable de los datos para tu flujo de trabajo.
- El doble de tiempo que lleva aplicar cambios actualizados en tu tabla, más algún búfer adicional.
Para calcular el tiempo que lleva aplicar cambios actualizados a una tabla existente, usa la siguiente consulta de SQL a fin de determinar la duración del percentil 95 de los trabajos de aplicación en segundo plano, más un búfer de siete minutos para permitir la conversión de almacenamiento optimizado para escritura de BigQuery (búfer de transmisión)
SELECT project_id, destination_table.dataset_id, destination_table.table_id, APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)] AS p95_background_apply_duration_in_seconds, CEILING(APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)]*2/60)+7 AS recommended_max_staleness_with_buffer_in_minutes FROM `region-REGION`.INFORMATION_SCHEMA.JOBS AS job WHERE project_id = 'PROJECT_ID' AND DATE(creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE "%cdc_background%" GROUP BY 1,2,3;
Reemplaza lo siguiente:
REGION: Es el nombre de la región en la que se encuentra tu proyecto. Por ejemplo,us.PROJECT_ID: Es el ID del proyecto que contiene las tablas de BigQuery que modifica la CDC de BigQuery.
La duración de los trabajos de aplicación en segundo plano se ve afectada por varios factores, como la cantidad y la complejidad de las operaciones de CDC emitidas dentro del intervalo de inactividad, el tamaño de la tabla y la disponibilidad de recursos de BigQuery. Para obtener más información sobre la disponibilidad de los recursos, consulta Ajusta el tamaño y supervisa las reservas de BACKGROUND.
Crea una tabla con la opción max_staleness
Para crear una tabla con la opción max_staleness, usa la declaración CREATE TABLE.
En el siguiente ejemplo, se crea la tabla employees con un límite de max_staleness de 10 minutos:
CREATE TABLE employees ( id INT64 PRIMARY KEY NOT ENFORCED, name STRING) CLUSTER BY id OPTIONS ( max_staleness = INTERVAL 10 MINUTE);
Modifica la opción max_staleness para una tabla existente
Para agregar o modificar un límite max_staleness en una tabla existente, usa la declaración ALTER TABLE.
En el siguiente ejemplo, se cambia el límite max_staleness de la tabla employees a 15 minutos:
ALTER TABLE employees SET OPTIONS ( max_staleness = INTERVAL 15 MINUTE);
Determina el valor actual de max_staleness de una tabla
Para determinar el valor actual de max_staleness de una tabla, consulta la vista INFORMATION_SCHEMA.TABLE_OPTIONS.
En el siguiente ejemplo, se verifica el valor actual de max_staleness de la tabla mytable:
SELECT option_name, option_value FROM DATASET_NAME.INFORMATION_SCHEMA.TABLE_OPTIONS WHERE option_name = 'max_staleness' AND table_name = 'TABLE_NAME';
Reemplaza lo siguiente:
DATASET_NAME: el nombre del conjunto de datos en el que reside la tabla habilitada para la CDC.TABLE_NAME: el nombre de la tabla habilitada para la CDC.
Los resultados muestran que el valor de max_staleness es de 10 minutos:
+---------------------+--------------+ | Row | option_name | option_value | +---------------------+--------------+ | 1 | max_staleness | 0-0 0 0:10:0 | +---------------------+--------------+
Supervisa el progreso de la operación de inserción y actualización de tablas
Para supervisar el estado de una tabla y verificar cuándo se aplicaron las modificaciones más recientes, consulta la vista INFORMATION_SCHEMA.TABLES a fin de obtener la marca de tiempo upsert_stream_apply_watermark.
En el siguiente ejemplo, se verifica el valor upsert_stream_apply_watermark de la tabla mytable:
SELECT upsert_stream_apply_watermark FROM DATASET_NAME.INFORMATION_SCHEMA.TABLES WHERE table_name = 'TABLE_NAME';
Reemplaza lo siguiente:
DATASET_NAME: el nombre del conjunto de datos en el que reside la tabla habilitada para la CDC.TABLE_NAME: el nombre de la tabla habilitada para la CDC.
El resultado es similar al siguiente:
[{
"upsert_stream_apply_watermark": "2022-09-15T04:17:19.909Z"
}]
La cuenta de servicio bigquery-adminbot@system.gserviceaccount.com realiza operaciones de
inserción y actualización y aparecen en el historial de trabajos del proyecto que contiene la
tabla habilitada para la CDC.
Administrar pedidos personalizados
Cuando se transmiten inserciones y actualizaciones a BigQuery, el comportamiento predeterminado de ordenar los registros con claves primarias idénticas se determina según la hora del sistema de BigQuery en la que se transfirió el registro a BigQuery. En otras palabras, el registro que se transfirió más recientemente con la marca de tiempo más reciente tiene prioridad sobre el registro que se transfirió anteriormente con una marca de tiempo más antigua. En algunos casos de uso, como aquellos en los que se pueden realizar inserciones y actualizaciones muy frecuentes en la misma clave principal en un período muy corto o en los que no se garantiza el orden de inserción o actualización, es posible que esto no sea suficiente. En estos casos, es posible que se necesite una clave de ordenamiento proporcionada por el usuario.
Para configurar los claves de orden que proporciona el usuario, se usa la pseudocolumna _CHANGE_SEQUENCE_NUMBER para indicar el orden en el que BigQuery debe aplicar los registros, según el _CHANGE_SEQUENCE_NUMBER más grande entre dos registros coincidentes con la misma clave principal. La pseudocolumna _CHANGE_SEQUENCE_NUMBER es opcional y solo acepta valores en un formato fijo STRING.
Formato _CHANGE_SEQUENCE_NUMBER
La seudocolumna _CHANGE_SEQUENCE_NUMBER solo acepta valores STRING, escritos en un formato fijo. Este formato fijo usa valores STRING escritos en hexadecimal, separados en secciones por una barra diagonal /. Cada sección se puede expresar en un máximo de 16 caracteres hexadecimales y se permiten hasta cuatro secciones por _CHANGE_SEQUENCE_NUMBER. El rango permitido de _CHANGE_SEQUENCE_NUMBER admite valores entre 0/0/0/0 y FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF.
Los valores _CHANGE_SEQUENCE_NUMBER admiten caracteres en mayúsculas y minúsculas.
Para expresar claves de ordenamiento básicas, puedes usar una sola sección. Por ejemplo, para ordenar claves solo en función de la marca de tiempo de procesamiento de un registro desde un servidor de aplicaciones, puedes usar una sección: '2024-04-30 11:19:44 UTC', que se expresa como hexadecimal convirtiendo la marca de tiempo en milisegundos desde la época, en este caso, '18F2EBB6480'. La lógica para convertir datos en hexadecimales es responsabilidad del cliente que emite la operación de escritura en BigQuery con la API de Storage Write.
La compatibilidad con varias secciones te permite combinar varios valores de lógica de procesamiento en una clave para casos de uso más complejos. Por ejemplo, para ordenar claves en función de la marca de tiempo de procesamiento de un registro desde un servidor de aplicaciones, un número de secuencia de registro y el estado del registro, puedes usar tres secciones: '2024-04-30 11:19:44 UTC' / '123' / 'complete', cada una expresada como hexadecimal.
El orden de las secciones es una consideración importante para clasificar tu lógica de procesamiento. BigQuery compara los valores de _CHANGE_SEQUENCE_NUMBER comparando la primera sección y, luego, la siguiente solo si las secciones anteriores fueron iguales.
BigQuery usa _CHANGE_SEQUENCE_NUMBER para ordenar comparando dos o más campos _CHANGE_SEQUENCE_NUMBER como valores numéricos sin firmar.
Considera los siguientes ejemplos de comparación de _CHANGE_SEQUENCE_NUMBER y sus resultados de precedencia:
Ejemplo 1:
- Registro #1:
_CHANGE_SEQUENCE_NUMBER= "77" - Registro #2:
_CHANGE_SEQUENCE_NUMBER= "7B"
Resultado: El registro #2 se considera el más reciente porque "7B" > "77" (es decir, "123" > "119").
- Registro #1:
Ejemplo 2:
- Registro #1:
_CHANGE_SEQUENCE_NUMBER= "FFF/B" - Registro #2:
_CHANGE_SEQUENCE_NUMBER= "FFF/ABC"
Resultado: El registro #2 se considera el más reciente porque "FFF/ABC" > "FFF/B" (es decir, "4095/2748" > "4095/11").
- Registro #1:
Ejemplo 3:
- Registro #1:
_CHANGE_SEQUENCE_NUMBER= "BA/FFFFFFFF" - Registro #2:
_CHANGE_SEQUENCE_NUMBER= "ABC"
Resultado: El registro #2 se considera el más reciente porque "ABC" > "BA/FFFFFFFF" (es decir, "2748" > "186/4294967295").
- Registro #1:
Ejemplo 4:
- Registro #1:
_CHANGE_SEQUENCE_NUMBER= "FFF/ABC" - Registro #2:
_CHANGE_SEQUENCE_NUMBER= "ABC"
Resultado: El registro #1 se considera el más reciente porque "FFF/ABC" > "ABC" (es decir, "4095/2748" > "2748").
- Registro #1:
Si dos valores de _CHANGE_SEQUENCE_NUMBER son idénticos, el registro con el tiempo de transferencia más reciente del sistema de BigQuery tiene prioridad sobre los registros transferidos anteriormente.
Cuando se usa el orden personalizado para una tabla, siempre se debe proporcionar el valor de _CHANGE_SEQUENCE_NUMBER. Las solicitudes de escritura que no especifican el valor _CHANGE_SEQUENCE_NUMBER, lo que genera una combinación de filas con y sin valores _CHANGE_SEQUENCE_NUMBER, dan como resultado un orden impredecible.
Configura una reserva de BigQuery para usarla con la CDC
Puedes usar reservas de BigQuery a fin de asignar recursos de procesamiento dedicados de BigQuery para las operaciones de modificación de filas de la CDC. Las reservas te permiten establecer un límite para el costo de realizar estas operaciones. Este enfoque es particularmente útil para flujos de trabajo con operaciones frecuentes de CDC en tablas grandes, que, de lo contrario, tendrían costos de demanda altos debido a la gran cantidad de bytes procesados cuando se realiza cada operación.
Los trabajos de CDC de BigQuery que aplican modificaciones de filas pendientes dentro del intervalo max_staleness se consideran trabajos en segundo plano y usan el tipo de asignación BACKGROUND, en lugar del tipo de asignación QUERY.
Por otro lado, las consultas fuera del intervalo max_staleness que requieren que se apliquen modificaciones de filas en el momento de la ejecución de la consulta usan el tipo de asignación QUERY. Las tablas sin un parámetro de configuración max_staleness o las tablas con max_staleness establecido en 0 también usan el tipo de asignación QUERY.
Los trabajos en segundo plano de la CDC de BigQuery que se realizan sin una asignación
BACKGROUND usan los precios a pedido.
Esta consideración es importante cuando diseñas tu estrategia de administración de
cargas de trabajo para la CDC de BigQuery.
Si deseas configurar una reserva de BigQuery para usarla con la CDC, primero debes configurar una reserva en la región en la que se encuentran tus tablas de BigQuery. Para obtener información sobre el tamaño de tu reserva, consulta Cambia el tamaño y supervisa las reservas de BACKGROUND.
Una vez que hayas creado una reserva, asigna el proyecto de BigQuery en la reserva y configura la opción job_type como BACKGROUND mediante la ejecución de la siguiente sentencia CREATE ASSIGNMENT:
CREATE ASSIGNMENT `ADMIN_PROJECT_ID.region-REGION.RESERVATION_NAME.ASSIGNMENT_ID` OPTIONS ( assignee = 'projects/PROJECT_ID', job_type = 'BACKGROUND');
Reemplaza lo siguiente:
ADMIN_PROJECT_IDpor el ID del proyecto de administración que posee la reserva.REGION: Es el nombre de la región en la que se encuentra tu proyecto. Por ejemplo,us.RESERVATION_NAMEpor el nombre de la reserva.ASSIGNMENT_IDpor el ID de la asignación. El ID debe ser único para el proyecto y la ubicación, debe comenzar y terminar con una letra minúscula o un número, y contener solo letras en minúscula, números y guiones.PROJECT_IDpor el ID del proyecto que contiene las tablas de BigQuery que modifica la CDC de BigQuery. Este proyecto está asignado a la reserva.
Ajusta el tamaño y supervisa las reservas de BACKGROUND
Las reservas determinan la cantidad de recursos de procesamiento disponibles para realizar operaciones de procesamiento de BigQuery. Reducir el tamaño de una reserva puede aumentar el tiempo de procesamiento de las operaciones de modificación de filas de la CDC. Para dimensionar con precisión una reserva, supervisa el consumo histórico de ranuras del proyecto que realiza las operaciones de CDC mediante la consulta de la vista INFORMATION_SCHEMA.JOBS_TIMELINE:
SELECT period_start, SUM(period_slot_ms) / (1000 * 60) AS slots_used FROM region-REGION.INFORMATION_SCHEMA.JOBS_TIMELINE_BY_PROJECT WHERE DATE(job_creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE '%cdc_background%' GROUP BY period_start ORDER BY period_start DESC;
Reemplaza REGION por el nombre de la región en la que se encuentra tu proyecto. Por ejemplo, us.
Consideraciones de datos borrados
- Las operaciones de CDC de BigQuery usan recursos de procesamiento de BigQuery. Si las operaciones de CDC se configuran para usar la facturación on demand, las operaciones de CDC se realizan de forma periódica mediante recursos internos de BigQuery. Si las operaciones de CDC se configuran con una reserva
BACKGROUND, las operaciones de CDC están sujetas a la disponibilidad de recursos de la reserva configurada. Si no hay suficientes recursos disponibles dentro de la reserva configurada, el procesamiento de las operaciones de CDC, incluida la eliminación, puede tardar más de lo previsto. - Se considera que una operación
DELETEde CDC solo se aplica cuando la marca de tiempoupsert_stream_apply_watermarkpasó la marca de tiempo en la que la API de Storage Write transmitió la operación. Para obtener más información sobre la marca de tiempoupsert_stream_apply_watermark, consulta Supervisa el progreso de la operación de inserción y actualización de tablas. - Para aplicar operaciones
DELETEde la CDC que llegan fuera de orden, BigQuery mantiene un período de retención de eliminación de dos días. Las operaciones de la tablaDELETEse almacenan durante este período antes de que comience el Google Cloud proceso de eliminación de datos estándar. Las operaciones deDELETEdentro del período de retención de eliminación usan los precios de almacenamiento estándar de BigQuery.
Limitaciones
- La CDC de BigQuery no realiza la aplicación de claves, por lo que es esencial que tus claves primarias sean únicas.
- Las claves primarias no pueden superar las 16 columnas.
- Las tablas habilitadas para CDC no pueden tener más de 2,000 columnas de nivel superior definidas por el esquema de la tabla.
- Las tablas habilitadas para CDC no admiten lo siguiente:
- Sentencias de lenguaje de manipulación de datos (DML), como
DELETE,UPDATEyMERGE - Consulta tablas comodín
- Índices de búsqueda
- Sentencias de lenguaje de manipulación de datos (DML), como
- Las tablas habilitadas para la CDC que realizan trabajos de combinación en el entorno de ejecución porque el valor
max_stalenessde la tabla es demasiado bajo no pueden admitir lo siguiente: - Las operaciones de exportación de BigQuery en las tablas habilitadas para la CDC no exportan las modificaciones de filas transmitidas recientemente que aún no se aplicaron mediante un trabajo en segundo plano. Para exportar la tabla completa, usa una sentencia
EXPORT DATA. - Si tu consulta activa una combinación de entorno de ejecución en una tabla particionada, toda la tabla se analiza sin importar si la consulta está restringida a un subconjunto de las particiones o no.
- Si usas la Edición estándar,
BACKGROUNDlas reservas no estarán disponibles, por lo que aplicar modificaciones de filas pendientes usa el modelo de precios según demanda. Sin embargo, puedes consultar tablas habilitadas para CDC, sin importar la edición. - Las seudocolumnas
_CHANGE_TYPEy_CHANGE_SEQUENCE_NUMBERno son columnas consultables cuando se realiza una operación de lectura de tabla. - No se admite mezclar filas que tengan valores
UPSERToDELETEpara_CHANGE_TYPEcon filas que tenganINSERTo valores no especificados para_CHANGE_TYPEen la misma conexión, lo que genera el siguiente error de validación:The given value is not a valid CHANGE_TYPE.
Precios de la CDC de BigQuery
La CDC de BigQuery usa la API de Storage Write para la transferencia de datos, el almacenamiento de BigQuery para el almacenamiento de datos y el procesamiento de BigQuery para las operaciones de modificación de filas, todos los cuales generan costos. Para obtener información sobre los precios, consulta Precios de BigQuery.
Estima los costos de los CDC de BigQuery
Además de las prácticas recomendadas generales de estimación de costos de BigQuery, estimar los costos de los CDC de BigQuery puede ser importante para los flujos de trabajo que tienen grandes cantidades de datos, una configuración de max_staleness baja o datos que cambian con frecuencia.
Los precios de la transferencia de datos de BigQuery y los precios de almacenamiento de BigQuery se calculan directamente según la cantidad de datos que transfieres y almacenas, incluidas las seudocolumnas. Sin embargo, los precios de procesamiento de BigQuery pueden ser más difíciles de estimar, ya que se relacionan con el consumo de recursos de procesamiento que se usan para ejecutar trabajos de CDC de BigQuery.
Los trabajos de CDC de BigQuery se dividen en tres categorías:
- Trabajos de aplicación en segundo plano: trabajos que se ejecutan en segundo plano en intervalos regulares que se definen mediante el valor
max_stalenessde la tabla. Estos trabajos aplican modificaciones de filas transmitidas recientemente a la tabla habilitada para los CDC. - Trabajos de consulta: Consultas de Google SQL que se ejecutan dentro de la ventana
max_stalenessy solo leen desde la tabla de referencia de los CDC. - Trabajos de combinación en entorno de ejecución: trabajos que se activan mediante consultas Google SQL ad hoc que se ejecutan fuera de la ventana
max_staleness. Estos trabajos deben realizar una combinación sobre la marcha de la tabla de referencia de CDC y las modificaciones de filas transmitidas recientemente en el entorno de ejecución de la consulta.
Solo los trabajos de consulta aprovechan la partición de BigQuery. Los trabajos de aplicación en segundo plano y los trabajos de combinación del entorno de ejecución no se pueden particionar porque, cuando se aplican modificaciones de filas transmitidas recientemente, no hay garantía de a qué partición de tabla se aplican las inserciones y actualizaciones recientemente transmitidas. En otras palabras, la tabla de modelo de referencia completa se lee durante los trabajos de aplicación en segundo plano y los trabajos de combinación del entorno de ejecución. Por el mismo motivo, solo los trabajos de consulta pueden beneficiarse de los filtros en las columnas de agrupamiento en clústeres de BigQuery. Comprender la cantidad de datos que se leen para realizar operaciones de los CDC es útil a la hora de estimar el costo total.
Si la cantidad de datos que se leen en el modelo de referencia de la tabla es alta, considera usar el modelo de precios de capacidad de BigQuery, que no se basa en la cantidad de datos procesados.
Prácticas recomendadas para los costos de los CDC de BigQuery
Además de las prácticas recomendadas generales sobre los costos de BigQuery, usa las siguientes técnicas para optimizar los costos de las operaciones de CDC de BigQuery:
- A menos que sea necesario, evita configurar la opción
max_stalenessde una tabla con un valor muy bajo. El valormax_stalenesspuede aumentar la aparición de trabajos de aplicación en segundo plano y trabajos de combinación del entorno de ejecución, que son más costosos y lentos que los trabajos de consulta. Para obtener orientación detallada, consulta Valor recomendado de la tablamax_staleness. - Considera configurar una reserva de BigQuery para usarla con tablas de CDC.
De lo contrario, los trabajos de aplicación en segundo plano y los trabajos de combinación del entorno de ejecución usan precios según demanda, lo que puede ser más costoso debido al procesamiento de datos. Para obtener más información, consulta las reservas de BigQuery y sigue las instrucciones sobre cómo dimensionar y supervisar una reserva
BACKGROUNDpara usar con los CDC de BigQuery.
¿Qué sigue?
- Obtén información para implementar la transmisión predeterminada de la API de Storage Write.
- Obtén información sobre las prácticas recomendadas para la API de Storage Write.
- Aprende a usar Datastream para replicar bases de datos transaccionales en BigQuery con la CDC de BigQuery.