Diffuser les mises à jour des tables avec la capture des données modifiées
La capture des données modifiées (CDC, Change Data Capture) de BigQuery met à jour vos tables BigQuery en traitant et en appliquant les modifications en streaming aux données existantes. Cette synchronisation est effectuée via des opérations d'insertion et de suppression des lignes diffusées en temps réel par l'API BigQuery Storage Write, que vous devez connaître avant de continuer.
Avant de commencer
Attribuez aux utilisateurs des rôles IAM (Identity and Access Management) incluant les autorisations nécessaires pour effectuer l'ensemble des tâches du présent document et assurez-vous que votre workflow remplit chaque condition préalable.
Autorisations requises
Pour obtenir l'autorisation dont vous avez besoin pour utiliser l'API Storage Write, demandez à votre administrateur de vous accorder le rôle IAM Éditeur de données BigQuery (roles/bigquery.dataEditor).
Pour en savoir plus sur l'attribution de rôles, consultez la page Gérer l'accès aux projets, aux dossiers et aux organisations.
Ce rôle prédéfini contient l'autorisation bigquery.tables.updateData requise pour utiliser l'API Storage Write.
Vous pouvez également obtenir cette autorisation avec des rôles personnalisés ou d'autres rôles prédéfinis.
Pour plus d'informations sur les rôles et les autorisations IAM dans BigQuery, consultez la page Présentation d'IAM.
Prérequis
Pour utiliser la CDC BigQuery, votre workflow doit remplir les conditions suivantes :
- Vous devez utiliser l'API Storage Write dans le flux par défaut.
- Vous devez utiliser le format protobuf comme format d'ingestion. Le format Apache Arrow n'est pas accepté.
- Vous devez déclarer les clés primaires pour la table de destination dans BigQuery. Les clés primaires composites contenant jusqu'à 16 colonnes sont acceptées.
- Des ressources de calcul BigQuery suffisantes doivent être disponibles pour effectuer les opérations CDC de ligne. Sachez que si les opérations CDC de modification de ligne échouent, vous risquez de conserver involontairement des données que vous souhaitez supprimer. Pour en savoir plus, consultez la section Remarques sur les données supprimées.
Spécifier les modifications apportées aux enregistrements existants
Dans la CDC BigQuery, la pseudo-colonne _CHANGE_TYPE indique le type de modification à traiter pour chaque ligne. Pour utiliser la CDC, définissez _CHANGE_TYPE lorsque vous diffusez des modifications de ligne à l'aide de l'API Storage Write. La pseudo-colonne _CHANGE_TYPE n'accepte que les valeurs UPSERT et DELETE.
Une table est considérée comme compatible avec CDC, tandis que l'API Storage Write diffuse des modifications de ligne sur la table de cette manière.
Exemple avec les valeurs UPSERT et DELETE
Prenons l'exemple de table suivant dans BigQuery :
| ID | Nom | Salaire |
|---|---|---|
| 100 | Charlie | 2000 |
| 101 | Tal | 3000 |
| 102 | Lee | 5000 |
Les modifications de ligne suivantes sont diffusées par l'API Storage Write :
| ID | Nom | Salaire | _CHANGE_TYPE |
|---|---|---|---|
| 100 | SUPPRIMER | ||
| 101 | Tal | 8000 | UPSERT |
| 105 | Izumi | 6000 | UPSERT |
La table mise à jour est maintenant la suivante :
| ID | Nom | Salaire |
|---|---|---|
| 101 | Tal | 8000 |
| 102 | Lee | 5000 |
| 105 | Izumi | 6000 |
Gérer l'obsolescence de la table
Par défaut, chaque fois que vous exécutez une requête, BigQuery renvoie les résultats les plus récents. Pour fournir les résultats les plus récents lors de l'interrogation d'une table compatible CDC, BigQuery doit appliquer chaque modification de ligne diffusée jusqu'à l'heure de début de la requête, de sorte que la version la plus récente de la table soit interrogée. L'application de ces modifications de ligne au moment de l'exécution de la requête augmente la latence et le coût de la requête. Toutefois, si vous n'avez pas besoin de résultats de requête entièrement à jour, vous pouvez réduire le coût et la latence des requêtes en définissant l'option max_staleness sur votre table. Lorsque cette option est définie, BigQuery applique les modifications de ligne au moins une fois dans l'intervalle défini par la valeur max_staleness. Vous pouvez ainsi exécuter des requêtes sans attendre que les mises à jour soient appliquées, au prix d'une certaine obsolescence des données.
Ce comportement est particulièrement utile pour les tableaux de bord et les rapports pour lesquels la fraîcheur des données n'est pas essentielle. Il est également utile pour la gestion des coûts en vous permettant de mieux contrôler la fréquence à laquelle BigQuery applique les modifications de ligne.
Interroger des tables avec l'option max_staleness définie
Lorsque vous interrogez une table avec l'option max_staleness définie, BigQuery renvoie le résultat en fonction de la valeur de max_staleness et l'heure à laquelle la dernière tâche d'application a eu lieu, représentée par le code temporel upsert_stream_apply_watermark de la table.
Prenons l'exemple suivant, dans lequel une table a l'option max_staleness définie sur 10 minutes et la tâche d'application la plus récente a eu lieu à T20 :
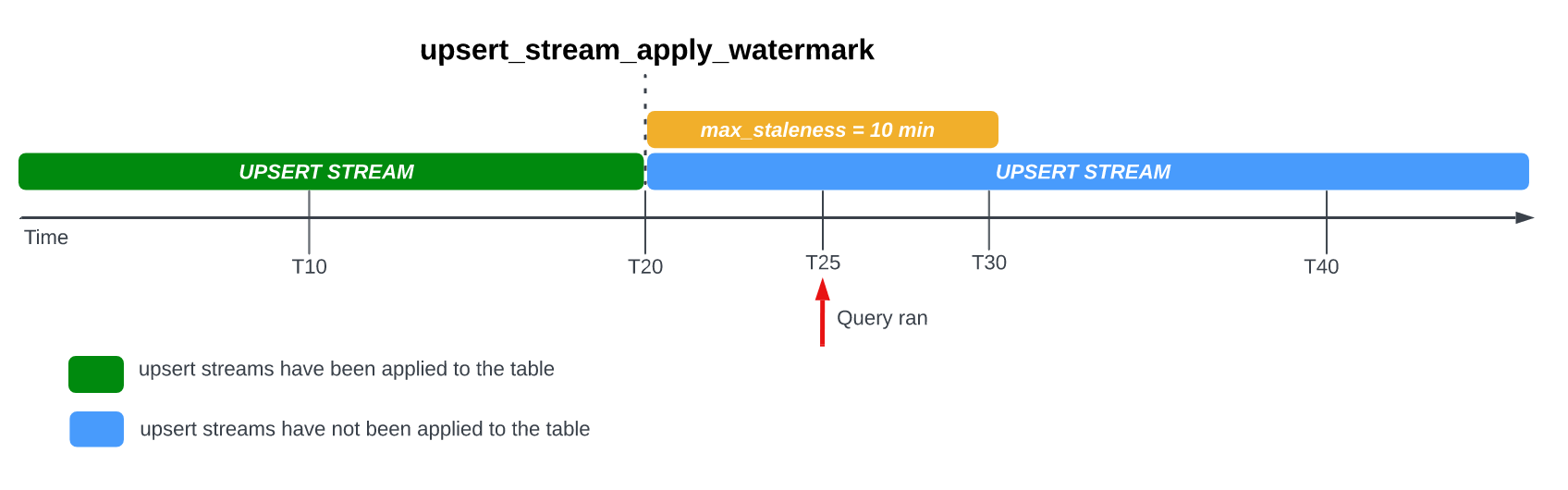
Si vous interrogez la table à T25, la version actuelle de la table est obsolète de 5 minutes, ce qui est inférieur à l'intervalle max_staleness de 10 minutes. Dans ce cas, BigQuery renvoie la version de la table à T20, ce qui signifie que les données renvoyées sont également obsolètes de 5 minutes.
Lorsque vous définissez l'option max_staleness sur votre table, BigQuery applique au moins une modification de ligne en attente dans l'intervalle max_staleness. Cependant, dans certains cas, BigQuery peut ne pas terminer le processus d'application de ces modifications de ligne en attente dans l'intervalle.
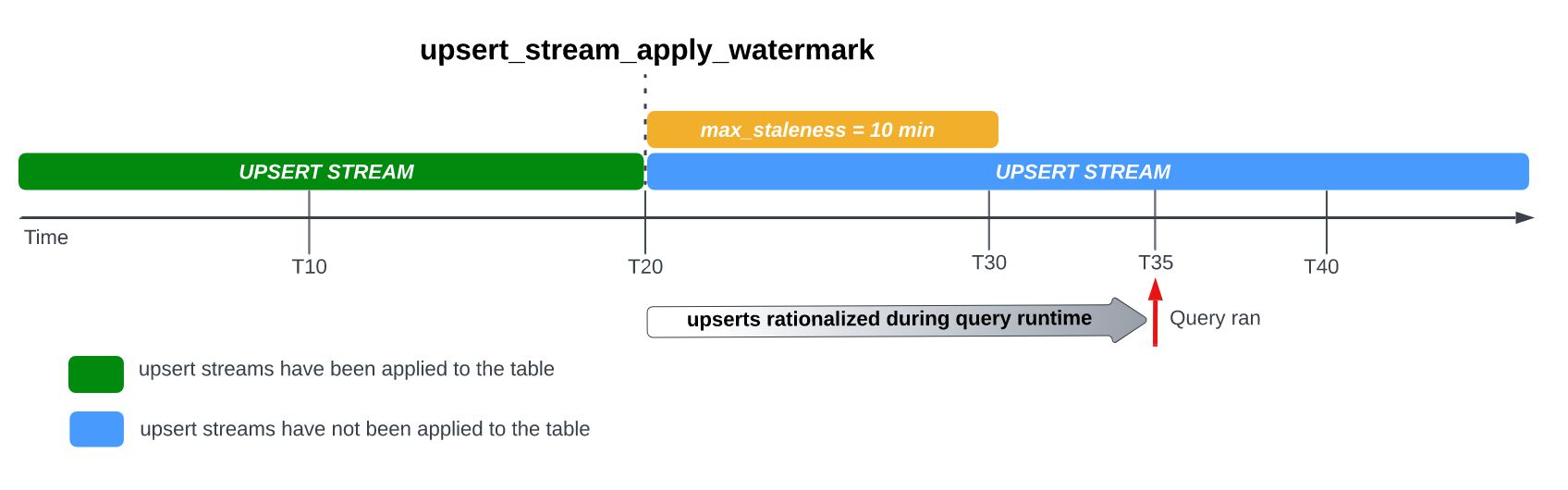
Par exemple, si vous interrogez la table à T35 et que le processus d'application des modifications de lignes en attente n'est pas terminé, la version actuelle de la table est à 15 minutes, ce qui est supérieur à l'intervalle max_staleness de 10 minutes.
Dans ce cas, au moment de l'exécution de la requête, BigQuery applique toutes les modifications de ligne comprises entre T20 et T35 pour la requête en cours, ce qui signifie que les données interrogées sont entièrement à jour, au prix d'une latence de requête supplémentaire.
Il s'agit d'un job de fusion d'environnements d'exécution.
Valeur max_staleness recommandée pour une table
La valeur max_staleness d'une table doit généralement être la plus élevée des deux valeurs suivantes :
- Obsolescence maximale des données pour votre workflow.
- Deux fois plus de temps qu'il n'en faut pour appliquer des modifications dans votre table, plus un tampon supplémentaire.
Pour calculer le temps nécessaire à l'application de modifications dans une table existante, utilisez la requête SQL suivante pour déterminer la durée du 95e centile des jobs d'application en arrière-plan, à laquelle vous ajoutez un tampon de sept minutes pour autoriser la conversion d'un espace de stockage optimisé pour l'écriture dans BigQuery (tampon de flux).
SELECT project_id, destination_table.dataset_id, destination_table.table_id, APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)] AS p95_background_apply_duration_in_seconds, CEILING(APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)]*2/60)+7 AS recommended_max_staleness_with_buffer_in_minutes FROM `region-REGION`.INFORMATION_SCHEMA.JOBS AS job WHERE project_id = 'PROJECT_ID' AND DATE(creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE "%cdc_background%" GROUP BY 1,2,3;
Remplacez les éléments suivants :
REGION: nom de la région où se trouve votre projet. Exemple :us.PROJECT_ID: ID du projet contenant les tables BigQuery en cours de modification par la CDC BigQuery.
La durée des jobs d'application en arrière-plan est affectée par plusieurs facteurs, dont le nombre et la complexité des opérations CDC émises dans l'intervalle d'obsolescence, la taille de la table et la disponibilité des ressources BigQuery. Pour en savoir plus sur la disponibilité des ressources, consultez Dimensionner et surveiller les réservations BACKGROUND.
Créer une table avec l'option max_staleness
Pour créer une table avec l'option max_staleness, utilisez l'instruction CREATE TABLE.
L'exemple suivant crée la table employees avec une limite max_staleness de 10 minutes :
CREATE TABLE employees ( id INT64 PRIMARY KEY NOT ENFORCED, name STRING) CLUSTER BY id OPTIONS ( max_staleness = INTERVAL 10 MINUTE);
Modifier l'option max_staleness pour une table existante
Pour ajouter ou modifier une limite max_staleness dans une table existante, utilisez l'instruction ALTER TABLE.
L'exemple suivant remplace la limite max_staleness de la table employees par 15 minutes :
ALTER TABLE employees SET OPTIONS ( max_staleness = INTERVAL 15 MINUTE);
Déterminer la valeur max_staleness actuelle d'une table
Pour déterminer la valeur max_staleness actuelle d'une table, interrogez la vue INFORMATION_SCHEMA.TABLE_OPTIONS.
L'exemple suivant vérifie la valeur max_staleness actuelle de la table mytable :
SELECT option_name, option_value FROM DATASET_NAME.INFORMATION_SCHEMA.TABLE_OPTIONS WHERE option_name = 'max_staleness' AND table_name = 'TABLE_NAME';
Remplacez les éléments suivants :
DATASET_NAME: nom de l'ensemble de données dans lequel se trouve la table compatible avec la CDC.TABLE_NAME: nom de la table compatible avec la CDC.
Les résultats montrent que la valeur max_staleness est de 10 minutes :
+---------------------+--------------+ | Row | option_name | option_value | +---------------------+--------------+ | 1 | max_staleness | 0-0 0 0:10:0 | +---------------------+--------------+
Surveiller la progression des opérations upsert d'une table
Pour surveiller l'état d'une table et vérifier à quel moment les modifications de ligne ont été appliquées pour la dernière fois, interrogez la vue INFORMATION_SCHEMA.TABLES pour obtenir le code temporel upsert_stream_apply_watermark.
L'exemple suivant vérifie la valeur upsert_stream_apply_watermark de la table mytable :
SELECT upsert_stream_apply_watermark FROM DATASET_NAME.INFORMATION_SCHEMA.TABLES WHERE table_name = 'TABLE_NAME';
Remplacez les éléments suivants :
DATASET_NAME: nom de l'ensemble de données dans lequel se trouve la table compatible avec la CDC.TABLE_NAME: nom de la table compatible avec la CDC.
Le résultat ressemble à ce qui suit :
[{
"upsert_stream_apply_watermark": "2022-09-15T04:17:19.909Z"
}]
Les opérations upsert sont effectuées par le compte de service bigquery-adminbot@system.gserviceaccount.com et apparaissent dans l'historique des tâches du projet contenant la table compatible CDC.
Gérer l'ordre de tri personnalisé
Lors de la diffusion d'opérations upsert vers BigQuery, le comportement par défaut consistant à classer les enregistrements avec des clés primaires identiques est déterminé par l'heure système BigQuery à laquelle l'enregistrement a été ingéré dans BigQuery. En d'autres termes, l'enregistrement ingéré le plus récemment avec le dernier horodatage a priorité sur l'enregistrement ingéré précédemment avec un ancien horodatage. Dans certains cas d'utilisation, par exemple ceux où des opérations upsert très fréquentes peuvent survenir sur la même clé primaire dans un très court intervalle, ou lorsque l'ordre upsert n'est pas garanti, cela peut ne pas être suffisant. Dans ces cas, une clé de tri fournie par l'utilisateur peut être nécessaire.
Pour configurer les clés de tri fournies par l'utilisateur, la pseudo-colonne _CHANGE_SEQUENCE_NUMBER permet d'indiquer l'ordre dans lequel BigQuery doit appliquer les enregistrements, en fonction de la valeur _CHANGE_SEQUENCE_NUMBER la plus élevée entre deux enregistrements correspondants ayant la même clé primaire. La pseudo-colonne _CHANGE_SEQUENCE_NUMBER est une colonne facultative qui n'accepte que les valeurs au format fixe STRING.
Format _CHANGE_SEQUENCE_NUMBER
La pseudo-colonne _CHANGE_SEQUENCE_NUMBER n'accepte que les valeurs STRING, écrites dans un format fixe. Ce format fixe utilise des valeurs STRING écrites en hexadécimal, séparées en sections par une barre oblique /. Chaque section peut être exprimée avec un maximum de 16 caractères hexadécimaux, et jusqu'à quatre sections sont autorisées par _CHANGE_SEQUENCE_NUMBER. La plage autorisée de _CHANGE_SEQUENCE_NUMBER accepte des valeurs comprises entre 0/0/0/0 et FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF.
Les valeurs _CHANGE_SEQUENCE_NUMBER acceptent les majuscules et les minuscules.
L'expression des clés de tri de base peut être effectuée à l'aide d'une seule section. Par exemple, pour ordonner les clés uniquement en fonction de l'horodatage de traitement d'un enregistrement à partir d'un serveur d'applications, vous pouvez utiliser une section, '2024-04-30 11:19:44 UTC', exprimée en hexadécimal en convertissant l'horodatage en millisecondes à partir de l'epoch, '18F2EBB6480' dans ce cas. La logique de conversion des données en hexadécimal incombe au client qui effectue l'écriture dans BigQuery à l'aide de l'API Storage Write.
La prise en charge de plusieurs sections vous permet de combiner plusieurs valeurs de logique de traitement dans une seule clé pour des cas d'utilisation plus complexes. Par exemple, pour classer les clés en fonction de l'horodatage de traitement d'un enregistrement provenant d'un serveur d'applications, d'un numéro de séquence de journal et de l'état de l'enregistrement, vous pouvez utiliser trois sections : '2024-04-30 11:19:44 UTC' / '123' / 'complete', chacune exprimée en hexadécimal.
L'ordre des sections est un aspect important à prendre en compte pour classer votre logique de traitement. BigQuery compare les valeurs _CHANGE_SEQUENCE_NUMBER en comparant la première section, puis la section suivante uniquement si les sections précédentes étaient égales.
BigQuery utilise _CHANGE_SEQUENCE_NUMBER pour effectuer un tri en comparant deux champs _CHANGE_SEQUENCE_NUMBER ou plus en tant que valeurs numériques non signées.
Examinez les exemples de comparaison _CHANGE_SEQUENCE_NUMBER suivants et leurs résultats de priorité :
Exemple 1 :
- Enregistrement n° 1 :
_CHANGE_SEQUENCE_NUMBER= "77" - Enregistrement n° 2 :
_CHANGE_SEQUENCE_NUMBER= "7B"
Résultat : l'enregistrement n° 2 est considéré comme le plus récent, car "7B" > "77" (c.-à-d. "123" > "119")
- Enregistrement n° 1 :
Exemple 2 :
- Enregistrement n° 1 :
_CHANGE_SEQUENCE_NUMBER= "FFF/B" - Enregistrement"n° 2 :
_CHANGE_SEQUENCE_NUMBER= "FFF/ABC"
Résultat : l'enregistrement n° 2 est considéré comme le dernier, car "FFF/ABC" > "FFF/B" (c.-à-d. "4095/2748" > "4095/11").
- Enregistrement n° 1 :
Exemple 3 :
- Enregistrement n° 1 :
_CHANGE_SEQUENCE_NUMBER= "BA/FFFFFFFF" - Enregistrement n° 2 :
_CHANGE_SEQUENCE_NUMBER= "ABC"
Résultat : l'enregistrement n° 2 est considéré comme le dernier enregistrement, car "ABC" > "BA/FFFFFFFF" (c.-à-d. "2748" > "186/4294967295").
- Enregistrement n° 1 :
Exemple 4 :
- Enregistrement n° 1 :
_CHANGE_SEQUENCE_NUMBER= "FFF/ABC" - Enregistrement n° 2 :
_CHANGE_SEQUENCE_NUMBER= "ABC"
Résultat : l'enregistrement n° 1 est considéré comme le dernier enregistrement, car "FFF/ABC" > "ABC" (c.-à-d. "4095/2748" > "2748").
- Enregistrement n° 1 :
Si deux valeurs _CHANGE_SEQUENCE_NUMBER sont identiques, l'enregistrement avec le dernier temps d'ingestion du système BigQuery a priorité sur les enregistrements ingérés précédemment.
Lorsque le tri personnalisé est utilisé pour un tableau, la valeur _CHANGE_SEQUENCE_NUMBER doit toujours être fournie. Toutes les requêtes d'écriture qui ne spécifient pas la valeur _CHANGE_SEQUENCE_NUMBER, ce qui entraîne un mélange de lignes avec et sans valeurs _CHANGE_SEQUENCE_NUMBER, entraînent un ordre imprévisible.
Configurer une réservation BigQuery à utiliser avec la CDC
Vous pouvez utiliser des réservations BigQuery pour allouer des ressources de calcul BigQuery dédiées aux opérations CDC de modification de ligne. Les réservations vous permettent de définir un plafond du coût d'exécution de ces opérations. Cette approche est particulièrement utile pour les workflows avec des opérations CDC fréquentes sur des tables volumineuses qui entraînent des coûts à la demande élevés en raison du grand nombre d'octets traités lors de l'exécution de chaque opération.
Les jobs de CDC BigQuery qui appliquent des modifications de ligne en attente dans l'intervalle max_staleness sont considérés comme des jobs d'arrière-plan et utilisent le type d'attribution BACKGROUND plutôt que le type d'attribution QUERY.
En revanche, les requêtes en dehors de l'intervalle max_staleness exigeant l'application des modifications de ligne au moment de l'exécution de la requête utilisent le type d'attribution QUERY. Les tables sans paramètre max_staleness ou dont le paramètre max_staleness est défini sur 0 utilisent également le type d'attribution QUERY.
Les jobs de CDC BigQuery en arrière-plan effectués sans attribution BACKGROUND utilisent la tarification à la demande.
Ce point est important lorsque vous concevez votre stratégie de gestion de la charge de travail pour la CDC BigQuery.
Pour configurer une réservation BigQuery à utiliser avec la CDC, commencez par configurer une réservation dans la région où se trouvent vos tables BigQuery. Pour obtenir des conseils sur la taille de votre réservation, consultez la section Dimensionner et surveiller les réservations BACKGROUND.
Une fois que vous avez créé une réservation, attribuez le projet BigQuery à la réservation, puis définissez l'option job_type sur BACKGROUND en exécutant l'instruction CREATE ASSIGNMENT suivante :
CREATE ASSIGNMENT `ADMIN_PROJECT_ID.region-REGION.RESERVATION_NAME.ASSIGNMENT_ID` OPTIONS ( assignee = 'projects/PROJECT_ID', job_type = 'BACKGROUND');
Remplacez les éléments suivants :
ADMIN_PROJECT_ID: ID du projet d'administration propriétaire de la réservation.REGION: nom de la région où se trouve votre projet. Exemple :us.RESERVATION_NAME: nom de la réservation.ASSIGNMENT_ID: ID de l'attribution. L'ID doit être unique au projet et à l'emplacement. Il doit commencer et se terminer par une lettre minuscule ou un chiffre, et ne doit contenir que des lettres minuscules, des chiffres et des tirets.PROJECT_ID: ID du projet contenant les tables BigQuery en cours de modification par la CDC BigQuery. Ce projet est attribué à la réservation.
Dimensionner et surveiller les réservations BACKGROUND
Les réservations déterminent la quantité de ressources de calcul disponibles pour effectuer des opérations de calcul BigQuery. Le sous-dimensionnement d'une réservation peut augmenter le temps de traitement des opérations CDC de modification de ligne. Pour dimensionner une réservation avec précision, surveillez l'historique de consommation des emplacements pour le projet qui effectue les opérations CDC en interrogeant la vue INFORMATION_SCHEMA.JOBS_TIMELINE :
SELECT period_start, SUM(period_slot_ms) / (1000 * 60) AS slots_used FROM region-REGION.INFORMATION_SCHEMA.JOBS_TIMELINE_BY_PROJECT WHERE DATE(job_creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE '%cdc_background%' GROUP BY period_start ORDER BY period_start DESC;
Remplacez REGION par le nom de la région où se trouve votre projet. Exemple : us.
Remarques concernant les données supprimées
- Les opérations CDC BigQuery utilisent les ressources de calcul BigQuery. Si les opérations CDC sont configurées pour utiliser la facturation à la demande, elles sont effectuées régulièrement à l'aide de ressources BigQuery internes. Si les opérations CDC sont configurées avec une réservation
BACKGROUND, les opérations CDC sont soumises à la disponibilité des ressources de la réservation configurée. Si les ressources disponibles dans la réservation configurée sont insuffisantes, le traitement des opérations CDC, y compris leur suppression, peut prendre plus de temps que prévu. - Une opération CDC
DELETEn'est considérée comme appliquée que lorsque le code temporelupsert_stream_apply_watermarka dépassé celui auquel l'API Storage Write a diffusé l'opération. Pour plus d'informations sur le code temporelupsert_stream_apply_watermark, consultez la page Surveiller la progression des opérations upsert de la table. - Pour appliquer les opérations CDC
DELETEqui arrivent dans le désordre, BigQuery conserve une période de rétention de suppression de deux jours. Les opérations sur la tableDELETEsont stockées pendant cette période avant le début du processus standard de suppression des donnéesGoogle Cloud . Les opérationsDELETEeffectuées pendant la période de conservation pour suppression utilisent les tarifs de stockage BigQuery standards.
Limites
- La CDC BigQuery n'appliquant pas l'utilisation obligatoire de clés, il est essentiel que vos clés primaires soient uniques.
- Les clés primaires ne peuvent pas dépasser 16 colonnes.
- Les tables compatibles CDC ne peuvent pas comporter plus de 2 000 colonnes de premier niveau définies par le schéma de la table.
- Les tables compatibles avec la CDC ne sont pas compatibles avec les éléments suivants :
- Instructions de langage de manipulation de données (LMD) telles que
DELETE,UPDATEetMERGE - Interroger des tables génériques
- Rechercher dans les index
- Instructions de langage de manipulation de données (LMD) telles que
- Les tables compatibles avec la CDC qui effectuent des jobs de fusion d'environnements d'exécution en raison de la valeur
max_stalenesstrop faible de la table ne peuvent pas accepter les éléments suivants : - Les opérations d'exportation de BigQuery sur les tables compatibles avec la CDC n'exportent pas les modifications de lignes récemment diffusées qui n'ont pas encore été appliquées par un job en arrière-plan. Pour exporter la table complète, utilisez une instruction
EXPORT DATA. - Si votre requête déclenche une fusion d'environnements d'exécution sur une table partitionnée, l'intégralité de la table est analysée, que la requête soit limitée ou non à un sous-ensemble de partitions.
- Si vous utilisez l'Édition standard, les réservations
BACKGROUNDne sont pas disponibles. Par conséquent, l'application des modifications de lignes en attente utilise le modèle de tarification à la demande. Toutefois, vous pouvez interroger des tables avec la CDC activée, quelle que soit votre édition. - Les pseudo-colonnes
_CHANGE_TYPEet_CHANGE_SEQUENCE_NUMBERne sont pas des colonnes pouvant être interrogées lors de la lecture d'une table. - Il n'est pas possible de mélanger des lignes avec des valeurs
UPSERTouDELETEpour_CHANGE_TYPEavec des lignes avec des valeursINSERTou non spécifiées pour_CHANGE_TYPEdans la même connexion. Cela génère l'erreur de validation suivante :The given value is not a valid CHANGE_TYPE.
Tarifs de la CDC BigQuery
La CDC BigQuery utilise l'API Storage Write pour l'ingestion de données, le stockage BigQuery pour le stockage de données et le calcul BigQuery pour les opérations de modification de ligne, qui entraînent tous des coûts. Pour en savoir plus sur les tarifs, consultez la page Tarifs de BigQuery.
Estimer les coûts liés à la CDC BigQuery
Outre les Bonnes pratiques générales pour l'estimation des coûts BigQuery, l'estimation des coûts liés à la CDC BigQuery peut être importante pour les workflows comportant de grandes quantités de données, une faible configuration max_staleness ou des données qui changent fréquemment.
Les tarifs d'ingestion de données BigQuery et les tarifs de stockage de BigQuery sont calculés directement à partir de la quantité de données que vous ingérez et stockez, y compris les pseudo-colonnes. Cependant, la tarification des ressources de calcul BigQuery peut être plus difficile à estimer, car elle concerne la consommation de ressources de calcul utilisées pour exécuter des jobs BigQuery CDC.
Les jobs BigQuery CDC sont divisées en trois catégories :
- Jobs d'application en arrière-plan : jobs qui s'exécutent en arrière-plan à intervalles réguliers, qui sont définis par la valeur
max_stalenessde la table. Ces jobs appliquent des modifications de ligne récemment diffusées dans la table avec CDC. - Jobs de requête : requêtes GoogleSQL qui s'exécutent dans la fenêtre
max_stalenesset qui ne lisent que la table de référence CDC. - Jobs de fusion de l'environnement d'exécution : jobs déclenchés par des requêtes Google SQL ad hoc qui s'exécutent en dehors de la fenêtre
max_staleness. Ces jobs doivent effectuer une fusion instantanée de la table de référence CDC et des modifications récemment apportées aux lignes lors de l'exécution de la requête.
Seuls les jobs de requête exploitent le partitionnement BigQuery. Les jobs d'application en arrière-plan et les jobs de fusion de l'environnement d'exécution ne peuvent pas utiliser le partitionnement, car lors de l'application des modifications de lignes récemment diffusées, il n'existe aucune garantie quant à la partition de table à laquelle les dernières sauvegardes en flux continu sont appliquées. En d'autres termes, la table de référence complète est lue pendant les jobs d'application en arrière-plan et les jobs de fusion de l'environnement d'exécution. Pour la même raison, seuls les jobs de requête peuvent bénéficier de filtres sur les colonnes de clustering BigQuery. Comprendre que la quantité de données en cours de lecture pour effectuer des opérations CDC est utile pour estimer le coût total.
Si la quantité de données lues dans la table de référence est élevée, envisagez d'utiliser le modèle de tarification de la capacité BigQuery, qui n'est pas basé sur la quantité de données traitées.
Bonnes pratiques concernant les coûts pour la CDC BigQuery
Outre les bonnes pratiques générales concernant les coûts BigQuery, utilisez les techniques suivantes pour optimiser les coûts des opérations BigQuery CDC :
- À moins que cela ne soit nécessaire, évitez de configurer l'option
max_stalenessd'une table avec une valeur très faible. La valeurmax_stalenesspeut augmenter l'occurrence des jobs d'application en arrière-plan et des jobs de fusion de l'environnement d'exécution, qui sont plus coûteux et plus lents que les jobs de requête. Pour obtenir des conseils détaillés, consultez la section Valeurmax_stalenessrecommandée de la table. - Envisagez de configurer une réservation BigQuery à utiliser avec des tables CDC.
Sinon, les jobs d'application en arrière-plan et les jobs de fusion de l'environnement d'exécution utilisent la tarification à la demande, qui peut s'avérer plus coûteuse en raison de davantage de traitement des données. Pour en savoir plus, découvrez les réservations BigQuery et suivez les instructions dans Comment dimensionner et surveiller une réservation
BACKGROUNDpour utiliser BigQuery CDC.
Étapes suivantes
- Découvrez comment implémenter le flux par défaut de l'API Storage Write.
- Découvrez les bonnes pratiques pour l'API Storage Write.
- Découvrez comment utiliser Datastream pour répliquer des bases de données transactionnelles vers BigQuery avec la CDC BigQuery.