Charger des données Blob Storage dans BigQuery
Vous pouvez charger des données depuis Blob Storage vers BigQuery à l'aide du connecteur Service de transfert de données BigQuery pour Blob Storage. Le service de transfert de données BigQuery vous permet de planifier des tâches de transfert récurrentes qui ajoutent vos dernières données Blob Storage à BigQuery.
Avant de commencer
Avant de créer un transfert de données de stockage de blobs, procédez comme suit :
- Vérifiez que vous avez effectué toutes les actions requises pour activer le service de transfert de données BigQuery.
- Choisissez un ensemble de données BigQuery existant ou créez-en un pour stocker vos données.
- Choisissez une table BigQuery existante ou créez une table de destination pour votre transfert de données, puis spécifiez la définition du schéma. Le nom de la table de destination doit respecter les règles de dénomination des tables. Les noms de table de destination acceptent également les paramètres.
- Récupérez le nom de votre compte de stockage Blob Storage, le nom du conteneur, le chemin d'accès aux données (facultatif) et le jeton SAP. Pour en savoir plus sur l'attribution d'un accès à Blob Storage à l'aide d'une signature d'accès partagé (SAP), consultez la section Signature d'accès partagé (SAP).
- Si vous limitez l'accès à vos ressources Azure à l'aide d'un pare-feu Azure Storage, ajoutez des nœuds de calcul du service de transfert de données BigQuery à votre liste d'adresses IP autorisées.
- Si vous envisagez de spécifier une clé de chiffrement gérée par le client (CMEK), assurez-vous que votre compte de service est autorisé à procéder au chiffrement et au déchiffrement, et que vous disposez de l'ID de ressource de la clé Cloud KMS requis pour utiliser des clés CMEK. Pour en savoir plus sur le fonctionnement des clés CMEK avec le service de transfert de données BigQuery, consultez la page Spécifier une clé de chiffrement avec des transferts.
Autorisations requises
Assurez-vous d'avoir accordé les autorisations suivantes.
Rôles BigQuery requis
Pour obtenir les autorisations nécessaires pour créer un transfert de données Service de transfert de données BigQuery, demandez à votre administrateur de vous accorder le rôle IAM Administrateur BigQuery (roles/bigquery.admin) sur votre projet.
Pour en savoir plus sur l'attribution de rôles, consultez la page Gérer l'accès aux projets, aux dossiers et aux organisations.
Ce rôle prédéfini contient les autorisations requises pour créer un transfert de données du service de transfert de données BigQuery. Pour connaître les autorisations exactes requises, développez la section Autorisations requises :
Autorisations requises
Les autorisations suivantes sont requises pour créer un transfert de données du service de transfert de données BigQuery :
-
Autorisations du service de transfert de données BigQuery :
-
bigquery.transfers.update -
bigquery.transfers.get
-
-
Autorisations BigQuery :
-
bigquery.datasets.get -
bigquery.datasets.getIamPolicy -
bigquery.datasets.update -
bigquery.datasets.setIamPolicy -
bigquery.jobs.create
-
Vous pouvez également obtenir ces autorisations avec des rôles personnalisés ou d'autres rôles prédéfinis.
Pour en savoir plus, consultez Accorder l'accès bigquery.admin.
Rôles Blob Storage requis
Pour en savoir plus sur les autorisations requises dans Blob Storage pour activer le transfert de données, consultez la section Signature d'accès partagé (SAP).
Limites
Les transferts de données du stockage de blobs sont soumis aux limitations suivantes :
- L'intervalle minimum entre deux transferts de données récurrents est de 1 heure. L'intervalle par défaut est de 24 heures.
- Selon le format de vos données sources Blob Storage, des limitations supplémentaires peuvent s'appliquer.
- Les transferts de données vers des emplacements BigQuery Omni ne sont pas compatibles.
Configurer un transfert de données de stockage de blobs
Sélectionnez l'une des options suivantes :
Console
Accédez à la page "Transferts de données" dans la console Google Cloud .
Cliquez sur Créer un transfert.
Sur la page Créer un transfert, procédez comme suit :
Dans la section Type de source, accédez à la liste déroulante Source, puis sélectionnez Azure Blob Storage et ADLS :
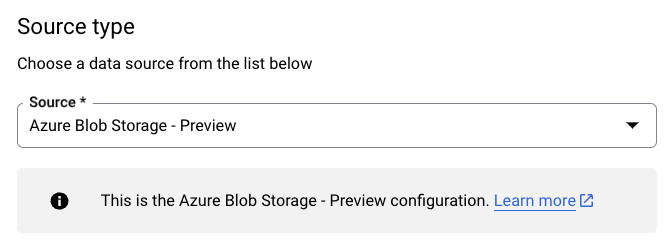
Dans la section Nom de la configuration de transfert, sous Nom à afficher, saisissez le nom du transfert de données.
Dans la section Schedule options (Options de programmation) :
- Choisissez une fréquence de répétition. Si vous sélectionnez Heures, Jours, Semaines ou Mois, vous devez également spécifier une fréquence. Vous pouvez également sélectionner Personnalisé pour spécifier une fréquence de répétition personnalisée. Si vous sélectionnez À la demande, le transfert de données s'exécute lorsque vous le déclenchez manuellement.
- Le cas échéant, sélectionnez Commencer ou Commencer à l'heure définie, puis indiquez une date de début et une heure d'exécution.
Dans la section Paramètres de destination, accédez au menu déroulant Ensemble de données, puis sélectionnez l'ensemble de données que vous avez créé pour stocker vos données.
Dans la section Data source details (Détails de la source de données), procédez comme suit :
- Pour le champ Destination table (Table de destination), saisissez le nom de la table que vous avez créée pour stocker les données dans BigQuery. Les noms de table de destination sont compatibles avec les paramètres.
- Dans le champ Nom du compte de stockage Azure, saisissez le nom du compte Blob Storage.
- Dans le champ Nom du conteneur, saisissez le nom du conteneur Blob Storage.
- Dans le champ Chemin d'accès aux données, saisissez le chemin d'accès permettant de filtrer les fichiers à transférer. Consultez ces exemples.
- Dans le champ Jeton SAP, saisissez le jeton Azure SAP.
- Dans le champ Format de fichier, choisissez le format des données source.
- Sous Disposition d'écriture, sélectionnez
WRITE_APPENDpour ajouter des données de manière incrémentielle à la table de destination, ouWRITE_TRUNCATEpour écraser les données dans la table de destination à chaque exécution du transfert.WRITE_APPENDest la valeur par défaut pour la disposition d'écriture.
Pour en savoir plus sur la manière dont le Service de transfert de données BigQuery ingère les données avec
WRITE_APPENDouWRITE_TRUNCATE, consultez Ingestion de données pour Azure Blob Transfers. Pour en savoir plus sur le champwriteDisposition, consultezJobConfigurationLoad.
Dans la section Options de transfert, procédez comme suit :
- Dans le champ Nombre d'erreurs autorisées, saisissez un nombre entier pour indiquer le nombre maximal d'enregistrements incorrects pouvant être ignorés. La valeur par défaut est 0.
- (Facultatif) Pour les types de cibles décimaux, saisissez une liste de types de données SQL possibles (séparés par une virgule) pour la conversion des valeurs décimales sources. Le type de données SQL sélectionné pour la conversion dépend des conditions suivantes :
- Dans l'ordre
NUMERIC,BIGNUMERICetSTRING, un type est choisi s'il figure dans votre liste spécifiée et s'il est compatible avec la précision et l'échelle. - Si aucun des types de données listés n'accepte la précision et l'échelle, le type de données acceptant la plus large plage parmi la liste spécifiée est sélectionné. Si une valeur dépasse la plage acceptée lors de la lecture des données sources, une erreur est renvoyée.
- Le type de données
STRINGaccepte toutes les valeurs de précision et d'échelle. - Si ce champ n'est pas renseigné, le type de données est défini par défaut sur
NUMERIC,STRINGpour ORC et surNUMERICpour les autres formats de fichiers. - Ce champ ne peut pas contenir de types de données en double.
- L'ordre dans lequel vous répertoriez les types de données est ignoré.
- Dans l'ordre
Si vous avez choisi CSV ou JSON comme format de fichier, dans la section JSON, CSV, cochez Ignorer les valeurs inconnues pour accepter les lignes contenant des valeurs qui ne correspondent pas au schéma.
Si vous avez choisi CSV comme format de fichier, dans la section CSV, saisissez les options CSV supplémentaires pour le chargement des données.
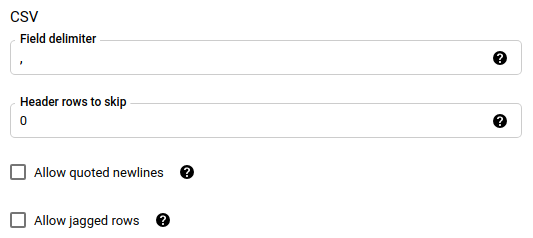
Dans la section Options de notification, vous pouvez choisir d'activer les notifications par e-mail et les notifications Pub/Sub.
- Lorsque vous activez les notifications par e-mail, l'administrateur du transfert reçoit une notification par e-mail si l'exécution du transfert échoue.
- Lorsque vous activez les notifications Pub/Sub, choisissez un nom de sujet pour publier ou cliquez sur Créer un sujet pour en créer un.
Si vous utilisez des CMEK, dans la section Options avancées, sélectionnez Clé gérée par le client. La liste des CMEK disponibles s'affiche. Pour en savoir plus sur le fonctionnement des CMEK avec le Service de transfert de données BigQuery, consultez Spécifier une clé de chiffrement avec les transferts.
Cliquez sur Enregistrer.
bq
Exécutez la commande bq mk --transfer_config pour créer un transfert de stockage de blobs :
bq mk \ --transfer_config \ --project_id=PROJECT_ID \ --data_source=DATA_SOURCE \ --display_name=DISPLAY_NAME \ --target_dataset=DATASET \ --destination_kms_key=DESTINATION_KEY \ --params=PARAMETERS
Remplacez les éléments suivants :
PROJECT_ID: (facultatif) ID du projet contenant votre ensemble de données cible. Si non spécifié, votre projet par défaut est utilisé.DATA_SOURCE:azure_blob_storage.DISPLAY_NAME: nom à afficher de la configuration de transfert de données. Ce nom peut correspondre à toute valeur permettant d'identifier le transfert si vous devez le modifier ultérieurement.DATASET: ensemble de données cible de la configuration de transfert de données.DESTINATION_KEY: (facultatif) ID de ressource de la clé Cloud KMS (par exemple,projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name).PARAMETERS: paramètres de la configuration de transfert de données, répertoriés au format JSON. Exemple :--params={"param1":"value1", "param2":"value2"}. Voici les paramètres d'un transfert de données de stockage de blobs :destination_table_name_template: valeur obligatoire. Le nom de votre table de destination.storage_account: valeur obligatoire. Nom du compte Blob Storage.container: valeur obligatoire. Nom du conteneur Blob Storage.data_path: facultatif. Chemin d'accès pour filtrer les fichiers à transférer. Affichez des exemples.sas_token: valeur obligatoire. Le jeton Azure SAS.file_format: facultatif. Le type de fichiers que vous souhaitez transférer :CSV,JSON,AVRO,PARQUETouORC. La valeur par défaut estCSV.write_disposition: facultatif. SélectionnezWRITE_APPENDpour ajouter des données à la table de destination, ouWRITE_TRUNCATEpour écraser les données de la table de destination. La valeur par défaut estWRITE_APPEND.max_bad_records: facultatif. Le nombre d'enregistrements incorrects autorisés. La valeur par défaut est 0.decimal_target_types: facultatif. Liste de types de données SQL possibles, séparés par des virgules, vers lesquels les valeurs décimales des données sources sont converties. Si ce champ n'est pas renseigné, le type de données par défaut estNUMERIC,STRINGpour ORC etNUMERICpour les autres formats de fichiers.ignore_unknown_values: facultatif. Cette valeur est ignorée sifile_formatn'est pas défini surJSONouCSV. Définissez la valeur surtruepour accepter les lignes contenant des valeurs qui ne correspondent pas au schéma.field_delimiter: facultatif. Cette valeur s'applique uniquement lorsquefile_formatest défini surCSV. Le caractère de séparation des champs. La valeur par défaut est,.skip_leading_rows: facultatif. Cette valeur s'applique uniquement lorsquefile_formatest défini surCSV. Indique le nombre de lignes d'en-tête que vous ne souhaitez pas importer. La valeur par défaut est 0.allow_quoted_newlines: facultatif. Cette valeur s'applique uniquement lorsquefile_formatest défini surCSV. Indique si les sauts de ligne doivent être autorisés dans les champs entre guillemets.allow_jagged_rows: facultatif. Cette valeur s'applique uniquement lorsquefile_formatest défini surCSV. Indique s'il faut accepter les lignes pour lesquelles il manque des colonnes facultatives finales. Les valeurs manquantes sont renseignées avecNULL.
Par exemple, la commande suivante crée un transfert de données de stockage de blobs appelé mytransfer :
bq mk \ --transfer_config \ --data_source=azure_blob_storage \ --display_name=mytransfer \ --target_dataset=mydataset \ --destination_kms_key=projects/myproject/locations/us/keyRings/mykeyring/cryptoKeys/key1 --params={"destination_table_name_template":"mytable", "storage_account":"myaccount", "container":"mycontainer", "data_path":"myfolder/*.csv", "sas_token":"my_sas_token_value", "file_format":"CSV", "max_bad_records":"1", "ignore_unknown_values":"true", "field_delimiter":"|", "skip_leading_rows":"1", "allow_quoted_newlines":"true", "allow_jagged_rows":"false"}
API
Utilisez la méthode projects.locations.transferConfigs.create et fournissez une instance de la ressource TransferConfig.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Spécifier une clé de chiffrement avec les transferts
Vous pouvez spécifier des clés de chiffrement gérées par le client (CMEK) pour chiffrer les données d'une exécution de transfert. Vous pouvez utiliser une clé CMEK pour assurer le transfert depuis Azure Blob Storage.Lorsque vous spécifiez une clé CMEK avec un transfert, le service de transfert de données BigQuery l'applique à tous les caches sur disque intermédiaires des données ingérées afin que l'intégralité du workflow de transfert de données soit compatible avec CMEK.
Vous ne pouvez pas mettre à jour un transfert existant pour ajouter une clé CMEK si le transfert n'a pas été initialement créé avec une clé CMEK. Par exemple, vous ne pouvez pas modifier une table de destination initialement chiffrée par défaut pour être chiffrée avec des clés CMEK. À l'inverse, vous ne pouvez pas modifier une table de destination chiffrée par CMEK pour obtenir un type de chiffrement différent.
Vous pouvez mettre à jour une clé CMEK pour un transfert si la configuration de celui-ci a été initialement créée avec un chiffrement CMEK. Lorsque vous mettez à jour une clé CMEK pour une configuration de transfert, le service de transfert de données BigQuery propage cette clé aux tables de destination à la prochaine exécution du transfert, où le service de transfert de données BigQuery remplace toutes les clés CMEK obsolètes par la nouvelle clé lors de l'exécution du transfert. Pour en savoir plus, consultez Mettre à jour un transfert.
Vous pouvez également utiliser les clés par défaut d'un projet. Lorsque vous spécifiez une clé de projet par défaut avec un transfert, le service de transfert de données BigQuery utilise cette clé pour toutes les nouvelles configurations de transfert.
Résoudre les problèmes liés à la configuration d'un transfert
Si vous rencontrez des problèmes lors de la configuration de votre transfert de données, consultez la section Problèmes de transfert de données avec stockage de blobs.
Étape suivante
- Obtenez plus d'informations sur les paramètres d'exécution dans les transferts.
- Obtenez plus d'informations sur le Service de transfert de données BigQuery.
- Découvrez comment charger des données avec des opérations multicloud.