Carregar dados do Blob Storage no BigQuery
É possível carregar dados do Blob Storage para o BigQuery usando o conector do serviço de transferência de dados do BigQuery para o Blob Storage. Com o serviço de transferência de dados do BigQuery, é possível programar jobs de transferência recorrentes que adicionam seus dados mais recentes do Armazenamento de Blobs ao BigQuery.
Antes de começar
Antes de criar uma transferência de dados do Armazenamento de Blobs, realize estas ações:
- Verifique se você concluiu todas as ações necessárias para ativar o serviço de transferência de dados do BigQuery.
- Escolha um conjunto de dados do BigQuery já existente ou crie um novo conjunto de dados para armazenar os dados.
- Escolha uma tabela do BigQuery já existente ou crie uma nova tabela de destino para a transferência de dados e especifique a definição do esquema. A tabela de destino precisa seguir as regras de nomenclatura de tabela. O nome da tabela de destino também aceita parâmetros.
- Recupere o nome da conta do Armazenamento de Blobs, o nome do contêiner, o caminho de dados (opcional) e o token SAS. Para mais informações sobre como conceder acesso ao Armazenamento de Blobs usando uma assinatura de acesso compartilhado (SAS), consulte Assinatura de acesso compartilhado (SAS).
- Se você restringir o acesso aos recursos do Azure usando um firewall do Azure Storage, adicione os workers do serviço de transferência de dados do BigQuery à sua lista de IPs permitidos.
- Se você planeja especificar uma chave de criptografia gerenciada pelo cliente (CMEK), verifique se a conta de serviço tem permissões para criptografar e descriptografar e que você tem o Cloud KMS ID do recurso da chave necessário para usar a CMEK. Para informações sobre como a CMEK funciona com o serviço de transferência de dados do BigQuery, consulte Especificar chave de criptografia com transferências.
Permissões necessárias
Verifique se você concedeu as seguintes permissões.
Papéis obrigatórios do BigQuery
Para receber as permissões necessárias para criar uma transferência de dados do serviço de transferência de dados do BigQuery,
peça ao administrador para conceder a você o papel do IAM
Administrador do BigQuery (roles/bigquery.admin)
no seu projeto.
Para mais informações sobre a concessão de papéis, consulte Gerenciar o acesso a projetos, pastas e organizações.
Esse papel predefinido contém as permissões necessárias para criar uma transferência de dados do serviço de transferência de dados do BigQuery. Para acessar as permissões exatas necessárias, expanda a seção Permissões necessárias:
Permissões necessárias
As seguintes permissões são necessárias para criar uma transferência de dados do serviço de transferência de dados do BigQuery:
-
Permissões do serviço de transferência de dados do BigQuery:
-
bigquery.transfers.update -
bigquery.transfers.get
-
-
Permissões do BigQuery:
-
bigquery.datasets.get -
bigquery.datasets.getIamPolicy -
bigquery.datasets.update -
bigquery.datasets.setIamPolicy -
bigquery.jobs.create
-
Essas permissões também podem ser concedidas com funções personalizadas ou outros papéis predefinidos.
Para mais informações, consulte Conceder acesso ao bigquery.admin.
Papéis obrigatórios do Blob Storage
Para informações sobre as permissões necessárias no Armazenamento de Blobs para ativar a transferência de dados, consulte Assinatura de acesso compartilhado (SAS).
Limitações
As transferências de dados do Armazenamento de Blobs estão sujeitas a estas limitações:
- O tempo mínimo de intervalo entre transferências de dados recorrentes é de 1 hora. O intervalo padrão é de 24 horas.
- Dependendo do formato dos dados de origem do Armazenamento de Blobs, pode haver outras limitações:
- As transferências de dados para locais do BigQuery Omninão são compatíveis.
Configurar uma transferência de dados do Armazenamento de Blobs
Selecione uma das seguintes opções:
Console
Acesse a página "Transferências de dados" no console Google Cloud .
Clique em Criar transferência.
Na página Criar transferência, faça o seguinte:
Na seção Tipo de origem, em Origem, selecione Armazenamento de Blobs do Azure e ADLS:
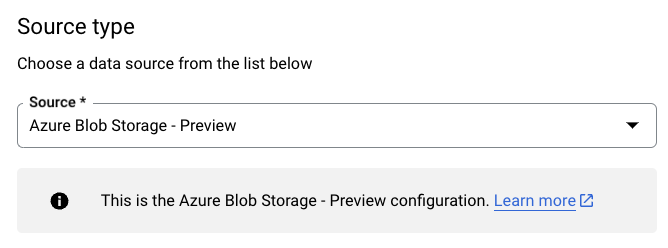
No campo Nome de exibição, na seção Transferir nome da configuração, insira um nome para a transferência de dados.
Na seção Opções de programação, faça o seguinte:
- Selecione uma Frequência de repetição. Se você selecionar Horas, Dias, Semanas ou Meses, também precisará especificar uma frequência. Também é possível selecionar Personalizada para especificar uma frequência de repetição personalizada. Se você selecionar On demand, essa transferência de dados vai ser executada quando você acioná-la manualmente.
- Se aplicável, selecione Começar agora ou Começar no horário definido e forneça uma data de início e um horário de execução.
No campo Conjunto de dados da seção Configurações de destino, escolha o conjunto criado para armazenar seus dados.
Na seção Detalhes da fonte de dados, faça o seguinte:
- Para a Tabela de destino, insira o nome da tabela criada para armazenar os dados no BigQuery. Os nomes de tabelas de destino aceitam parâmetros.
- Em Nome da conta do Armazenamento do Azure, insira o nome da conta do Armazenamento de Blobs.
- Em Nome do contêiner, insira o nome do contêiner do Armazenamento de Blobs.
- Em Caminho de dados, digite o caminho para filtrar os arquivos a serem transferidos. Confira exemplos.
- Em Token SAS, insira o token SAS do Azure.
- Em Formato do arquivo, escolha o formato dos dados de origem.
- Em Disposição de gravação, selecione
WRITE_APPENDpara anexar novos dados à tabela de destino de maneira incremental ouWRITE_TRUNCATEpara substituir dados na tabela de destino durante cada execução de transferência.WRITE_APPENDé o valor padrão para Disposição de gravação.
Para saber como o serviço de transferência de dados do BigQuery ingere dados usando
WRITE_APPENDouWRITE_TRUNCATE, consulte Ingestão de dados para transferências do Armazenamento de Blobs do Azure. Para saber mais sobre o campowriteDisposition, consulteJobConfigurationLoad.
Na seção Opções de transferência, realize estas ações:
- Em Número de erros permitidos, insira um valor inteiro para o número máximo de registros inválidos que podem ser ignorados. O valor padrão é 0.
- (Opcional) Em Tipos de destinos decimais, insira uma lista separada por vírgulas
de possíveis tipos de dados SQL em que os valores decimais nos dados
de origem são convertidos. O tipo de dados SQL selecionado para
conversão depende destas condições:
- Na ordem de
NUMERIC,BIGNUMERICeSTRING, um tipo será escolhido se estiver na lista especificada e se for compatível com a precisão e a escala. - Se nenhum dos tipos de dados listados for compatível com a precisão e a escala, o tipo de dados compatível com o intervalo mais amplo da lista especificada será selecionado. Se um valor exceder o intervalo compatível durante a leitura dos dados de origem, um erro será gerado.
- O tipo de dados
STRINGé compatível com todos os valores de precisão e escala. - Se esse campo for deixado em branco, o tipo de dados será definido por padrão como
NUMERIC,STRINGpara ORC eNUMERICpara outros formatos de arquivo. - Este campo não pode conter tipos de dados duplicados.
- A ordem dos tipos de dados listados é ignorada.
- Na ordem de
Se você escolheu CSV ou JSON como o formato do arquivo, na seção JSON, CSV, marque Ignorar valores desconhecidos para aceitar linhas que contenham valores que não correspondam ao esquema.
Se você escolheu CSV como o formato do arquivo, na seção CSV, insira outras opções CSV para carregar dados.
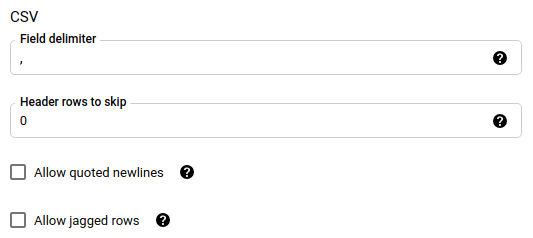
Na seção Opções de notificação, é possível ativar as notificações por e-mail e do Pub/Sub.
- Quando você ativa as notificações por e-mail, o administrador de transferências recebe uma notificação por e-mail quando ocorre uma falha na execução de uma transferência.
- Ao ativar as notificações do Pub/Sub, escolha um nome de tópico para publicar ou clique em Criar tópico.
Se você usa CMEKs, na seção Opções avançadas, selecione Chave gerenciada pelo cliente. Uma lista das CMEKs disponíveis será exibida. Para saber como as CMEKs funcionam com o serviço de transferência de dados do BigQuery, consulte Especificar a chave de criptografia com transferências.
Clique em Salvar.
bq
Use o comando bq mk --transfer_config para criar uma transferência do Armazenamento de Blobs:
bq mk \ --transfer_config \ --project_id=PROJECT_ID \ --data_source=DATA_SOURCE \ --display_name=DISPLAY_NAME \ --target_dataset=DATASET \ --destination_kms_key=DESTINATION_KEY \ --params=PARAMETERS
Substitua:
PROJECT_ID: (opcional) o ID do projeto que contém o conjunto de dados de destino. Se não for especificado, seu projeto padrão será usado.DATA_SOURCE:azure_blob_storage.DISPLAY_NAME: o nome de exibição da configuração da transferência de dados. O nome da transferência pode ser qualquer valor que permita identificá-la, caso você precise modificá-la mais tarde.DATASET: o conjunto de dados de destino na configuração da transferência de dados.DESTINATION_KEY: (opcional) o ID de recurso da chave do Cloud KMS, por exemplo,projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name.PARAMETERS: os parâmetros da configuração da transferência de dados, listados no formato JSON. Por exemplo,--params={"param1":"value1", "param2":"value2"}. Confira a seguir os parâmetros para uma transferência de dados do Armazenamento de Blobs:destination_table_name_template: obrigatório. É o nome da tabela de destino.storage_account: obrigatório. O nome da conta do Armazenamento de Blobs.container: obrigatório. Nome do contêiner do Armazenamento de Blobs.data_path: opcional. O caminho para filtrar os arquivos a serem transferidos. Confira exemplos.sas_token: obrigatório. O token SAS do Azure.file_format: opcional. O tipo de arquivo que você quer transferir:CSV,JSON,AVRO,PARQUETouORC. O valor padrão éCSV.write_disposition: opcional. SelecioneWRITE_APPENDpara anexar dados à tabela de destino ouWRITE_TRUNCATEpara substituir dados na tabela de destino. O valor padrão éWRITE_APPEND.max_bad_records: opcional. O número de registros inválidos permitidos. O valor padrão é 0.decimal_target_types: opcional. Uma lista separada por vírgulas de possíveis tipos de dados SQL em que os valores decimais nos dados de origem são convertidos. Se esse campo não for configurado, o tipo de dados será definido por padrão comoNUMERIC,STRINGpara ORC eNUMERICpara os outros formatos de arquivo.ignore_unknown_values: opcional e ignorado sefile_formatnão forJSONouCSV. Defina comotruepara aceitar linhas que contenham valores que não correspondem ao esquema.field_delimiter: opcional e aplicável somente quandofile_formatéCSV. É o caractere que separa os campos. O valor padrão é,.skip_leading_rows: opcional e aplicável somente quandofile_formatéCSV. Indica o número de linhas de cabeçalho que você não quer importar. O valor padrão é 0.allow_quoted_newlines: opcional e aplicável somente quandofile_formatéCSV. Indica se novas linhas são permitidas dentro de campos entre aspas.allow_jagged_rows: opcional e aplicável somente quandofile_formatéCSV. Indica se você aceitará linhas que estão faltando em colunas opcionais. Os valores ausentes são preenchidos comNULL.
Por exemplo, o código a seguir cria uma transferência de dados do Armazenamento de Blobs chamada mytransfer:
bq mk \ --transfer_config \ --data_source=azure_blob_storage \ --display_name=mytransfer \ --target_dataset=mydataset \ --destination_kms_key=projects/myproject/locations/us/keyRings/mykeyring/cryptoKeys/key1 --params={"destination_table_name_template":"mytable", "storage_account":"myaccount", "container":"mycontainer", "data_path":"myfolder/*.csv", "sas_token":"my_sas_token_value", "file_format":"CSV", "max_bad_records":"1", "ignore_unknown_values":"true", "field_delimiter":"|", "skip_leading_rows":"1", "allow_quoted_newlines":"true", "allow_jagged_rows":"false"}
API
Use o método projects.locations.transferConfigs.create
e forneça uma instância do recurso
TransferConfig.
Java
Antes de testar esta amostra, siga as instruções de configuração do Java no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Java.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Especificar a chave de criptografia com transferências
É possível especificar chaves de criptografia gerenciadas pelo cliente (CMEKs, na sigla em inglês) para criptografar dados de uma execução de transferência. Use uma CMEK para dar suporte a transferências do Armazenamento de Blobs do Azure.Quando você especifica uma CMEK com uma transferência, o serviço de transferência de dados do BigQuery aplica a CMEK a qualquer cache intermediário no disco de dados ingeridos para que todo o fluxo de trabalho de transferência de dados fique em conformidade com a CMEK.
Não é possível atualizar uma transferência atual para adicionar uma CMEK se a transferência não tiver sido criada originalmente com uma CMEK. Por exemplo, não é possível alterar uma tabela de destino que, originalmente, estava criptografada por padrão, para ser criptografada com CMEKs. Por outro lado, também não é possível alterar uma tabela de destino criptografada por CMEK para ter um tipo diferente de criptografia.
É possível atualizar uma CMEK para uma transferência se a configuração de transferência tiver sido criada originalmente com uma criptografia CMEK. Quando você atualiza uma CMEK para uma configuração de transferência, o serviço de transferência de dados do BigQuery propaga a CMEK para as tabelas de destino na próxima execução da transferência, em que o serviço de transferência de dados do BigQuery substitui todas as CMEKs desatualizadas pela nova CMEK durante a execução da transferência. Para saber mais, consulte Atualizar uma transferência.
Também é possível usar as chaves padrão do projeto. Quando você especifica uma chave padrão do projeto com uma transferência, o serviço de transferência de dados do BigQuery a usa como padrão para qualquer nova configuração de transferência.
Resolver problemas na configuração da transferência
Se você tiver problemas para configurar a transferência de dados, consulte Problemas de transferência no Armazenamento de blobs.
A seguir
- Saiba mais sobre parâmetros de ambiente de execução em transferências.
- Saiba mais sobre o serviço de transferência de dados do BigQuery.
- Saiba como carregar dados com operações entre nuvens.