Blob Storage-Daten in BigQuery laden
Mit dem Connector für BigQuery Data Transfer Service für Blob Storage können Sie Daten aus Blob Storage in BigQuery laden. Mit dem BigQuery Data Transfer Service können Sie wiederkehrende Übertragungsjobs planen, mit denen Ihre neuesten Daten aus Blob Storage in BigQuery eingefügt werden.
Hinweise
Führen Sie vor dem Erstellen einer Blob Storage-Datenübertragung die folgenden Schritte aus:
- Überprüfen Sie, ob Sie alle erforderlichen Aktionen ausgeführt haben, damit Sie den BigQuery Data Transfer Service aktivieren können.
- Wählen Sie ein vorhandenes BigQuery-Dataset aus oder erstellen Sie ein neues Dataset zum Speichern Ihrer Daten.
- Wählen Sie eine vorhandene BigQuery-Tabelle aus oder erstellen Sie eine neue Zieltabelle für Ihre Datenübertragung und geben Sie die Schemadefinition an. Die Zieltabelle muss den Regeln für die Tabellenbenennung folgen. In Namen von Zieltabellen sind auch Parameter möglich.
- Rufen Sie den Namen des Blob-Speicherspeichers-Kontos, den Containernamen, den Datenpfad (optional) und das SAS-Token ab. Informationen zum Gewähren des Zugriffs auf Blob Storage mithilfe einer Shared Access Signature (SAS) finden Sie unter Shared Access Signature (SAS).
- Wenn Sie den Zugriff auf Ihre Azure-Ressourcen über eine Azure Storage-Firewall beschränken, fügen Sie der Liste der zulässigen IP-Adressen die BigQuery Data Transfer Service-Worker hinzu.
- Wenn Sie einen vom Kunden verwalteten Verschlüsselungsschlüssel (CMEK) angeben möchten, muss Ihr Dienstkonto über die Berechtigungen zum Verschlüsseln und Entschlüsseln verfügen und Sie müssen die für die Verwendung von CMEK erforderliche Cloud KMS-Schlüsselressourcen-ID haben. Informationen zur Funktionsweise von CMEK mit dem BigQuery Data Transfer Service finden Sie unter Verschlüsselungsschlüssel mit Übertragungen angeben.
Erforderliche Berechtigungen
Prüfen Sie, ob Sie die folgenden Berechtigungen erteilt haben.
Erforderliche BigQuery-Rollen
Bitten Sie Ihren Administrator, Ihnen die IAM-Rolle BigQuery-Administrator (roles/bigquery.admin) für Ihr Projekt zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Erstellen einer BigQuery Data Transfer Service-Datenübertragung benötigen.
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Diese vordefinierte Rolle enthält die Berechtigungen, die zum Erstellen einer BigQuery Data Transfer Service-Datenübertragung erforderlich sind. Erweitern Sie den Abschnitt Erforderliche Berechtigungen, um die erforderlichen Berechtigungen anzuzeigen:
Erforderliche Berechtigungen
Die folgenden Berechtigungen sind erforderlich, um eine Datenübertragung für den BigQuery Data Transfer Service zu erstellen:
-
Berechtigungen für BigQuery Data Transfer Service:
-
bigquery.transfers.update -
bigquery.transfers.get
-
-
BigQuery-Berechtigungen:
-
bigquery.datasets.get -
bigquery.datasets.getIamPolicy -
bigquery.datasets.update -
bigquery.datasets.setIamPolicy -
bigquery.jobs.create
-
Sie können diese Berechtigungen auch mit benutzerdefinierten Rollen oder anderen vordefinierten Rollen erhalten.
Weitere Informationen finden Sie unter Zugriff auf bigquery.admin gewähren.
Erforderliche Blob Storage-Rollen
Informationen zu den erforderlichen Berechtigungen in Blob Storage zum Aktivieren der Datenübertragung finden Sie unter Shared Access Signature (SAS).
Beschränkungen
Blob Storage-Datenübertragungen unterliegen den folgenden Einschränkungen:
- Das Mindestintervall zwischen wiederkehrenden Datenübertragungen beträgt 1 Stunde. Das Standardintervall beträgt 24 Stunden.
- Je nach Format Ihrer Blob Storage-Quelldaten sind weitere Beschränkungen möglich.
- Datenübertragungen zu BigQuery Omni-Speicherorten werden nicht unterstützt.
Blob Storage-Datenübertragung einrichten
Wählen Sie eine der folgenden Optionen aus:
Console
Rufen Sie in der Google Cloud -Console die Seite „Datenübertragungen“ auf.
Klicken Sie auf Übertragung erstellen.
Führen Sie auf der Seite Übertragung erstellen die folgenden Schritte aus:
Wählen Sie im Abschnitt Quelltyp für Quelle die Option Azure Blob Storage & ADLS aus:
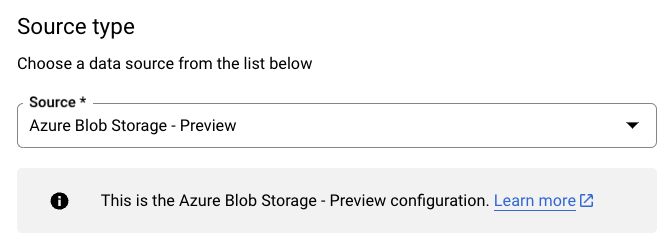
Geben Sie im Abschnitt Konfigurationsname für Übertragung als Anzeigename einen Namen für die Datenübertragung ein.
Im Abschnitt Zeitplanoptionen:
- Wählen Sie eine Wiederholungshäufigkeit aus. Wenn Sie Stunden, Tage, Wochen oder Monate auswählen, müssen Sie auch eine Häufigkeit angeben. Sie können auch Benutzerdefiniert auswählen, um eine benutzerdefinierte Wiederholungshäufigkeit anzugeben. Wenn Sie On demand auswählen, wird diese Datenübertragung ausgeführt, wenn Sie die Übertragung manuell auslösen.
- Wählen Sie gegebenenfalls Jetzt starten oder Zu festgelegter Zeit starten aus und geben Sie ein Startdatum und eine Ausführungszeit an.
Wählen Sie im Abschnitt Zieleinstellungen als Dataset das Dataset aus, das Sie zum Speichern Ihrer Daten erstellt haben.
Führen Sie im Abschnitt Details zur Datenquelle folgende Schritte aus:
- Geben Sie für Zieltabelle den Namen der Tabelle ein, die Sie zum Speichern Ihrer Daten in BigQuery erstellt haben. In Namen von Zieltabellen sind auch Parameter möglich.
- Geben Sie unter Storage-Kontoname den Namen des Blob-Speicherkontos ein.
- Geben Sie unter Containername den Namen des Blob-Speichercontainers ein.
- Geben Sie unter Datenpfad den Pfad zum Filtern der Dateien ein, die übertragen werden sollen. Beispiele
- Geben Sie unter SAS-Token das Azure-SAS-Token ein.
- Wählen Sie als Dateiformat Ihr Quelldatenformat aus.
- Wählen Sie unter Schreibanordnung die Option
WRITE_APPENDaus, um neue Daten schrittweise an die Zieltabelle anzuhängen, oderWRITE_TRUNCATE, um Daten in der Zieltabelle bei jeder Übertragung zu überschreiben.WRITE_APPENDist der Standardwert für die Schreibanordnung.
Weitere Informationen dazu, wie der BigQuery Data Transfer Service Daten mit
WRITE_APPENDoderWRITE_TRUNCATEaufnimmt, finden Sie unter Datenaufnahme für Azure Blob-Übertragungen. Weitere Informationen zum FeldwriteDispositionfinden Sie unterJobConfigurationLoad.
Führen Sie im Abschnitt Übertragungsoptionen folgende Schritte aus:
- Geben Sie unter Anzahl zulässiger Fehler einen ganzzahligen Wert für die maximale Anzahl der fehlerhaften Datensätze ein, die ignoriert werden dürfen. Der Standardwert ist 0.
- (Optional) Geben Sie unter Dezimalzieltypen eine durch Kommas getrennte Liste möglicher SQL-Datentypen ein, in die Dezimalwerte in den Quelldaten konvertiert werden. Welcher SQL-Datentyp für die Konvertierung ausgewählt wird, hängt von folgenden Bedingungen ab:
- In der Reihenfolge
NUMERIC,BIGNUMERICundSTRINGwird ein Typ ausgewählt, wenn er in der angegebenen Liste enthalten ist und die Genauigkeit und Skalierung unterstützt. - Wenn keiner der aufgelisteten Datentypen die Genauigkeit und Skalierung unterstützt, wird der Datentyp aus der Liste ausgewählt, der den breitesten Bereich unterstützt. Geht ein Wert beim Lesen der Quelldaten über den unterstützten Bereich hinaus, wird ein Fehler ausgegeben.
- Der Datentyp
STRINGunterstützt alle Genauigkeits- und Skalierungswerte. - Wenn dieses Feld leer bleibt, wird der Datentyp standardmäßig auf
NUMERIC,STRINGfür ORC undNUMERICfür andere Dateiformate gesetzt. - Dieses Feld darf keine doppelten Datentypen enthalten.
- Die Reihenfolge der aufgelisteten Datentypen wird ignoriert.
- In der Reihenfolge
Wenn Sie als Dateiformat CSV oder JSON ausgewählt haben, aktivieren Sie im Abschnitt JSON, CSV die Option Unbekannte Werte ignorieren, um Zeilen zu akzeptieren, die Werte enthalten, die nicht mit dem Schema übereinstimmen.
Wenn Sie als Dateiformat CSV ausgewählt haben, geben Sie im Abschnitt CSV weitere CSV-Optionen zum Laden von Daten ein.
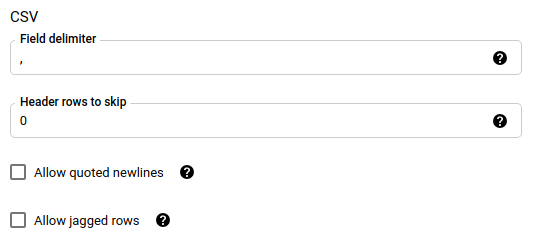
Im Bereich Benachrichtigungsoptionen können Sie E-Mail-Benachrichtigungen und Pub/Sub-Benachrichtigungen aktivieren.
- Wenn Sie E‑Mail-Benachrichtigungen aktivieren, erhält der Übertragungsadministrator eine E‑Mail-Benachrichtigung, wenn ein Übertragungsvorgang fehlschlägt.
- Wenn Sie Pub/Sub-Benachrichtigungen aktivieren, wählen Sie ein Thema aus, in dem Sie veröffentlichen möchten, oder klicken Sie auf Thema erstellen, um eines zu erstellen.
Wenn Sie CMEKs verwenden, wählen Sie im Abschnitt Erweiterte Optionen die Option Vom Kunden verwalteter Schlüssel aus. Es wird eine Liste der verfügbaren CMEKs angezeigt, aus denen Sie wählen können. Informationen zur Funktionsweise von CMEKs mit dem BigQuery Data Transfer Service finden Sie unter Verschlüsselungsschlüssel mit Übertragungen angeben.
Klicken Sie auf Speichern.
bq
Verwenden Sie den Befehl bq mk --transfer_config, um eine Blob Storage-Übertragung zu erstellen:
bq mk \ --transfer_config \ --project_id=PROJECT_ID \ --data_source=DATA_SOURCE \ --display_name=DISPLAY_NAME \ --target_dataset=DATASET \ --destination_kms_key=DESTINATION_KEY \ --params=PARAMETERS
Dabei gilt:
PROJECT_ID: (Optional) Die Projekt-ID, die Ihr Ziel-Dataset enthält. Wenn keine Angabe erfolgt, wird das Standardprojekt verwendet.DATA_SOURCE:azure_blob_storage.DISPLAY_NAME: Der Anzeigename für die Datenübertragungskonfiguration. Der Übertragungsname kann ein beliebiger Wert sein, mit dem Sie die Übertragung identifizieren können, wenn Sie sie später ändern müssen.DATASET: Das Ziel-Dataset für die Datenübertragungskonfiguration.DESTINATION_KEY: (Optional) Die Cloud KMS-Schlüsselressourcen-ID, z. B.projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name.- Die Parameter für die Datenübertragungskonfiguration gelistet im JSON-Format:
PARAMETERS. Beispiel:--params={"param1":"value1", "param2":"value2"}Im Folgenden finden Sie die Parameter für eine Blob Storage-Datenübertragung:destination_table_name_template: erforderlich. Der Name der Zieltabelle.storage_account: erforderlich. Der Name des Blob-Speicherkontos.container: erforderlich. Der Blob-Speichername des Blobs.data_path: Optional. Der Pfad zum Filtern von Dateien, die übertragen werden sollen. Beispiele ansehensas_token: erforderlich. Das Azure SAS-Tokenfile_format: Optional. Der Typ der Dateien, die Sie übertragen möchten:CSV,JSON,AVRO,PARQUEToderORC. Der Standardwert istCSV.write_disposition: Optional. Wählen SieWRITE_APPENDaus, um Daten an die Zieltabelle anzuhängen, oderWRITE_TRUNCATE, um Daten in der Zieltabelle zu überschreiben. Der Standardwert istWRITE_APPEND.max_bad_records: Optional. Die Anzahl der zulässigen ungültigen Datensätze. Der Standardwert ist 0.decimal_target_types: Optional. Eine durch Kommas getrennte Liste möglicher SQL-Datentypen, in die Dezimalwerte in den Quelldaten konvertiert werden. Wenn dieses Feld nicht angegeben ist, wird der Datentyp für ORC standardmäßig aufNUMERIC,STRINGund für die anderen Dateiformate aufNUMERICgesetzt.ignore_unknown_values: Optional und wird ignoriert, wennfile_formatnichtJSONoderCSVist. Legen Sietruefest, um Zeilen zu akzeptieren, die Werte enthalten, die nicht mit dem Schema übereinstimmen.field_delimiter: Optional und gilt nur, wennfile_formatgleichCSVist. Das Zeichen, das Felder trennt. Der Standardwert ist,.skip_leading_rows: Optional und gilt nur, wennfile_formatgleichCSVist. Gibt die Anzahl der Kopfzeilen an, die nicht importiert werden sollen. Der Standardwert ist 0.allow_quoted_newlines: Optional und gilt nur, wennfile_formatgleichCSVist. Gibt an, ob Zeilenumbrüche in Feldern in Anführungszeichen zulässig sind.allow_jagged_rows: Optional und gilt nur, wennfile_formatgleichCSVist. Gibt an, ob Zeilen ohne nachgestellte optionale Spalten zulässig sind. Die fehlenden Werte werden mitNULLausgefüllt.
Im Folgenden wird beispielsweise eine Blob Storage-Datenübertragung mit dem Namen mytransfer erstellt:
bq mk \ --transfer_config \ --data_source=azure_blob_storage \ --display_name=mytransfer \ --target_dataset=mydataset \ --destination_kms_key=projects/myproject/locations/us/keyRings/mykeyring/cryptoKeys/key1 --params={"destination_table_name_template":"mytable", "storage_account":"myaccount", "container":"mycontainer", "data_path":"myfolder/*.csv", "sas_token":"my_sas_token_value", "file_format":"CSV", "max_bad_records":"1", "ignore_unknown_values":"true", "field_delimiter":"|", "skip_leading_rows":"1", "allow_quoted_newlines":"true", "allow_jagged_rows":"false"}
API
Verwenden Sie die Methode projects.locations.transferConfigs.create und geben Sie eine Instanz der Ressource TransferConfig an.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Verschlüsselungsschlüssel mit Übertragungen angeben
Sie können vom Kunden verwaltete Verschlüsselungsschlüssel (CMEKs) angeben, um Daten für eine Übertragungsausführung zu verschlüsseln. Sie können einen CMEK verwenden, um Übertragungen von Azure Blob Storage zu unterstützen.Wenn Sie einen CMEK mit einer Übertragung angeben, wendet der BigQuery Data Transfer Service den CMEK auf einen zwischengeschalteten Festplatten-Cache von aufgenommenen Daten an, sodass der gesamte Datenübertragungsworkflow CMEK-konform ist.
Sie können eine vorhandene Übertragung nicht aktualisieren, um einen CMEK hinzuzufügen, wenn die Übertragung nicht ursprünglich mit einem CMEK erstellt wurde. Sie können beispielsweise keine Zieltabelle ändern, die ursprünglich standardmäßig verschlüsselt wurde, um jetzt mit CMEK zu verschlüsseln. Umgekehrt können Sie eine CMEK-verschlüsselte Zieltabelle auch nicht auf einen anderen Verschlüsselungstyp ändern.
Sie können einen CMEK für eine Übertragung aktualisieren, wenn die Übertragungskonfiguration ursprünglich mit einer CMEK-Verschlüsselung erstellt wurde. Wenn Sie einen CMEK für eine Übertragungskonfiguration aktualisieren, leitet der BigQuery Data Transfer Service den CMEK bei der nächsten Ausführung der Übertragung an die Zieltabellen weiter, wobei der BigQuery Data Transfer Service während der Übertragungsausführung alle veralteten CMEKs durch den neuen CMEK ersetzt. Weitere Informationen finden Sie unter Übertragung aktualisieren.
Sie können auch Standardschlüssel für Projekte verwenden. Wenn Sie einen Projektstandardschlüssel für eine Übertragung angeben, verwendet der BigQuery Data Transfer Service den Standardschlüssel des Projekts als Standardschlüssel für neue Übertragungskonfigurationen.
Fehler bei der Übertragungseinrichtung beheben
Bei Problemen mit der Einrichtung von Datenübertragungen finden Sie weitere Informationen unter Übertragungsprobleme mit Blob Storage.
Nächste Schritte
- Weitere Informationen zu Laufzeitparametern für Übertragungen
- Weitere Informationen zum BigQuery Data Transfer Service
- Daten mit cloudübergreifenden Vorgängen laden