本教程旨在向数据分析师介绍 BigQuery ML 中的矩阵分解模型。通过 BigQuery ML,用户可以利用 SQL 查询在 BigQuery 中创建和执行机器学习模型。其目标是让 SQL 专业人员能够利用现有的工具构建模型,并通过消除数据移动需求来提高开发速度,从而实现机器学习的普及。
在本教程中,您将学习如何使用 movielens1m 数据集根据显式反馈创建一个根据给定电影 ID 和用户 ID 作出推荐的模型。
Movielens 数据集包含用户对电影的评分(从 1 到 5),以及电影的元数据(如类型)。
目标
在本教程中,您将需要:
- 使用 BigQuery ML,通过
CREATE MODEL语句创建显式推荐模型 ML.EVALUATE函数,用于评估机器学习模型ML.WEIGHTS函数,用于检查训练过程中生成的潜在因子权重。ML.RECOMMEND函数,用于为用户作出推荐。
费用
本教程使用 Google Cloud 的收费组件,包括以下组件:
- BigQuery
- BigQuery ML
如需了解有关 BigQuery 费用的更多信息,请参阅 BigQuery 价格页面。
如需详细了解 BigQuery ML 费用,请参阅 BigQuery ML 价格。
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- 新项目会自动启用 BigQuery。如需在现有项目中激活 BigQuery,请转到
Enable the BigQuery API.
第一步:创建数据集
创建 BigQuery 数据集以存储您的机器学习模型:
在 Google Cloud 控制台中,转到 BigQuery 页面。
在探索器窗格中,点击您的项目名称。
点击 查看操作 > 创建数据集。
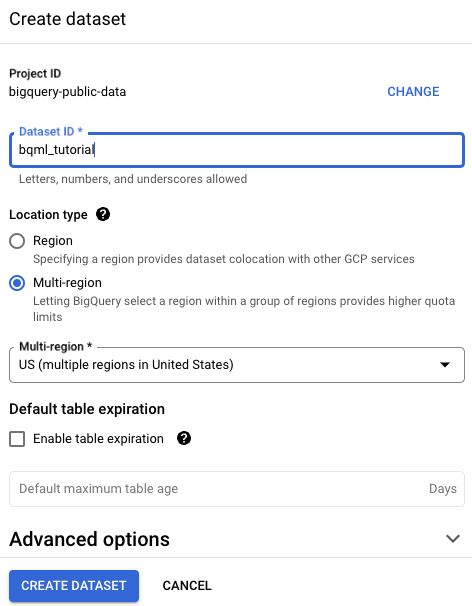
在创建数据集页面上,执行以下操作:
在数据集 ID 部分,输入
bqml_tutorial。在位置类型部分,选择多区域,然后选择 US (multiple regions in United States)(美国[美国的多个区域])。
公共数据集存储在
US多区域中。为简单起见,请将数据集存储在同一位置。保持其余默认设置不变,然后点击创建数据集。
第二步:将 Movielens 数据集加载到 BigQuery 中
以下是使用 BigQuery 命令行工具将 1m movielens 数据集加载到 BigQuery 中的步骤。
系统将创建一个名为 movielens 的数据集,并在其中存储相关的 movielens 表。
curl -O 'http://files.grouplens.org/datasets/movielens/ml-1m.zip'
unzip ml-1m.zip
bq mk --dataset movielens
sed 's/::/,/g' ml-1m/ratings.dat > ratings.csv
bq load --source_format=CSV movielens.movielens_1m ratings.csv \
user_id:INT64,item_id:INT64,rating:FLOAT64,timestamp:TIMESTAMP
由于电影标题包含冒号、逗号和竖线,因此我们需要使用不同的分隔符。如需加载电影标题,应使用最后两个命令略有不同的变体。
sed 's/::/@/g' ml-1m/movies.dat > movie_titles.csv
bq load --source_format=CSV --field_delimiter=@ \
movielens.movie_titles movie_titles.csv \
movie_id:INT64,movie_title:STRING,genre:STRING
第三步:创建显式推荐模型
接下来,您将使用在上一步中加载的 movielens 示例表创建显式推荐模型。以下 GoogleSQL 查询用于创建将用来预测每个“用户-推荐项”对的评分的模型。
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_explicit_mf_model` OPTIONS (model_type='matrix_factorization', user_col='user_id', item_col='item_id', l2_reg=9.83, num_factors=34) AS SELECT user_id, item_id, rating FROM `movielens.movielens_1m`
除了创建模型外,运行 CREATE MODEL 命令还可训练您创建的模型。
查询详情
CREATE MODEL 子句用于创建和训练名为 bqml_tutorial.my_explicit_mf_model 的模型。
OPTIONS(model_type='matrix_factorization', user_col='user_id', ...) 子句表示您正在创建矩阵分解模型。默认情况下,除非指定 feedback_type='IMPLICIT',否则此操作将创建显式矩阵分解模型。如需查看创建隐式矩阵分解模型的示例,请参阅使用 BigQuery ML 为隐式反馈作出推荐。
此查询的 SELECT 语句使用以下列生成推荐。
user_id- 用户 ID (INT64)。item_id- 电影 ID (INT64)。rating-user_id给item_id的明确评分(从 1 到 5)(FLOAT64)。
FROM 子句 - movielens.movielens_1m - 表示您正在查询 movielens 数据集中的 movielens_1m 表。
如果按照第二步中的说明操作,则此数据集位于您的 BigQuery 项目中。
运行 CREATE MODEL 查询
要运行 CREATE MODEL 查询来创建和训练模型,请执行以下操作:
在 Google Cloud 控制台中,点击编写新查询按钮。
在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_explicit_mf_model` OPTIONS (model_type='matrix_factorization', user_col='user_id', item_col='item_id', l2_reg=9.83, num_factors=34) AS SELECT user_id, item_id, rating FROM `movielens.movielens_1m`
点击运行。
查询大约需要 10 分钟才能完成,之后您的模型 (
my_explicit_mf_model) 将显示在 Google Cloud 控制台的导航面板中。由于查询使用CREATE MODEL语句来创建模型,因此您看不到查询结果。
第四步(可选):获取训练统计信息
如需查看模型训练的结果,您可以使用 ML.TRAINING_INFO 函数,也可以在 Google Cloud 控制台中查看统计信息。在本教程中,您将使用 Google Cloud 控制台。
机器学习算法通过检查众多示例并尝试找到实现损失最小化的模型来构建模型。该过程称为经验风险最小化。
要查看运行 CREATE MODEL 查询时生成的模型训练统计信息,请执行以下操作:
在 Google Cloud 控制台导航面板的资源部分中,展开 [PROJECT_ID] > bqml_tutorial,然后点击 my_explicit_mf_model。
点击训练标签页,然后点击表。结果应如下所示:
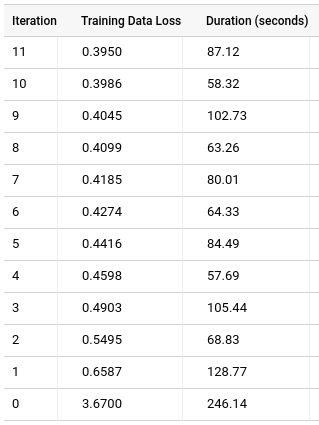
训练数据丢失列表示在训练数据集上训练模型后计算得出的损失指标。由于您执行了矩阵分解,因此该列为均方误差。默认情况下,矩阵分解模型不会拆分数据,因此除非指定保留数据集,否则评估数据损失列不会显示,因为拆分数据可能会丢失用户或推荐项的所有评分。因此,该模型不会显示有关丢失用户或推荐项的潜在因子信息。
如需详细了解
ML.TRAINING_INFO函数,请参阅 BigQuery ML 语法参考。
第五步:评估模型
创建模型后,您可以使用 ML.EVALUATE 函数评估推荐模型的性能。ML.EVALUATE 函数根据实际评分来评估预测评分。
用于评估模型的查询如下所示:
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`, ( SELECT user_id, item_id, rating FROM `movielens.movielens_1m`))
查询详情
最顶层的 SELECT 语句从模型中检索列。
FROM 子句使用 ML.EVALUATE 函数评估模型 bqml_tutorial.my_explicit_mf_model。
此查询的嵌套 SELECT 语句和 FROM 子句与 CREATE MODEL 查询中的相同。
您也可以在不提供输入数据的情况下调用 ML.EVALUATE。它将使用在训练期间计算得出的评估指标:
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`)
运行 ML.EVALUATE 查询
要运行 ML.EVALUATE 查询以评估模型,请执行以下操作:
在 Google Cloud 控制台中,点击编写新查询按钮。
在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`, ( SELECT user_id, item_id, rating FROM `movielens.movielens_1m`))
(可选)如需设置处理位置,请依次点击更多 > 查询设置。在处理位置部分中,选择
US。此步骤是可选的,因为系统将根据数据集的位置自动检测处理位置。
点击运行。
查询完成后,点击查询文本区域下方的结果标签页。结果应如下所示:

由于您执行了显式矩阵分解,因此结果包含以下列:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
评估结果中的一项重要指标为 R2 得分。R2 得分为统计测量结果,用于确定线性回归预测是否接近实际数据。0 表示该模型未能说明响应数据相对于平均值的可变性。1 表示该模型说明了响应数据相对于平均值的所有可变性。
第六步:使用模型预测评分并作出推荐
查找一组用户的所有推荐项评分
ML.RECOMMEND 不需要接受除模型之外的任何其他参数,但可以接受可选表。如果输入表中只有一列与输入 user 或输入 item 列的名称匹配,则将输出每个 user 的所有预测推荐项评分,反之亦然。请注意,如果输入表中包含所有 users 或所有 items,则 ML.RECOMMEND 的输出结果与不传递可选参数时相同。
以下示例演示了查询如何提取 5 个用户的所有预测电影评分:
#standardSQL SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`, ( SELECT user_id FROM `movielens.movielens_1m` LIMIT 5))
查询详情
最顶层的 SELECT 语句检索 user、item 和 predicted_rating 列。最后一列由 ML.RECOMMEND 函数生成。当您使用 ML.RECOMMEND 函数时,模型的输出列名称为 predicted_<rating_column_name>。对于显式矩阵分解模型来说,predicted_rating 为 rating 的估计值。
ML.RECOMMEND 函数用于通过模型 bqml_tutorial.my_explicit_mf_model 预测评分。
此查询的嵌套 SELECT 语句仅从用于训练的原始表中选择 user_id 列。
LIMIT 子句 - LIMIT 5 - 将随机过滤出 5 个 user_id 以发送到 ML.RECOMMEND。
查找所有“用户-推荐项”对的评分
您现已对模型进行了评估,下一步是用其预测评分。您可以使用模型在以下查询中预测每个“用户-推荐项”组合的评分:
#standardSQL SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
查询详情
最顶层的 SELECT 语句检索 user、item 和 predicted_rating 列。最后一列由 ML.RECOMMEND 函数生成。当您使用 ML.RECOMMEND 函数时,模型的输出列名称为 predicted_<rating_column_name>。对于显式矩阵分解模型来说,predicted_rating 为 rating 的估计值。
ML.RECOMMEND 函数用于通过模型 bqml_tutorial.my_explicit_mf_model 预测评分。
将结果保存到表的一种方法如下:
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_1m` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
如果 ML.RECOMMEND 发生 Query Exceeded Resource Limits 错误,请使用较高的结算层级重试。在 BigQuery 命令行工具中,可以使用 --maximum_billing_tier 标志设置结算层级。
生成推荐
使用之前的推荐查询,我们可以按预测评分排序,并为每个用户输出预测最准的推荐项。以下查询将 item_ids 和之前上传的 movielens.movie_titles 表中的 movie_ids 联接起来,为每位用户输出推荐的前 5 部电影。
#standardSQL SELECT user_id, ARRAY_AGG(STRUCT(movie_title, genre, predicted_rating) ORDER BY predicted_rating DESC LIMIT 5) FROM ( SELECT user_id, item_id, predicted_rating, movie_title, genre FROM `bqml_tutorial.recommend_1m` JOIN `movielens.movie_titles` ON item_id = movie_id) GROUP BY user_id
查询详情
内层 SELECT 语句对推荐结果表中的 item_id 和 movielens.movie_titles 表中的 movie_id 执行内联接。movielens.movie_titles 不仅将 movie_id 映射到电影名称,还包括 IMDB 列出的电影类型。
外层 SELECT 语句使用 GROUPS BY user_id 聚合嵌套 SELECT 语句的结果,以按降序聚合 movie_title,
genre, 和 predicted_rating,结果仅保留前 5 部电影。
运行 ML.RECOMMEND 查询
如需运行 ML.RECOMMEND 查询为每位用户输出推荐的前 5 部电影,请执行以下操作:
在 Google Cloud 控制台中,点击编写新查询按钮。
在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_1m` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
点击运行。
查询运行完毕后,(
bqml_tutorial.recommend_1m) 将显示在导航面板中。由于查询使用CREATE TABLE语句来创建表,因此您看不到查询结果。编写新查询。在上一个查询运行完毕后,在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL SELECT user_id, ARRAY_AGG(STRUCT(movie_title, genre, predicted_rating) ORDER BY predicted_rating DESC LIMIT 5) FROM ( SELECT user_id, item_id, predicted_rating, movie_title, genre FROM `bqml_tutorial.recommend_1m` JOIN `movielens.movie_titles` ON item_id = movie_id) GROUP BY user_id
(可选)如需设置处理位置,请依次点击更多 > 查询设置。在处理位置部分中,选择
US。此步骤是可选的,因为系统将根据数据集的位置自动检测处理位置。 点击运行。
查询完成后,点击查询文本区域下方的结果标签页。结果应如下所示:
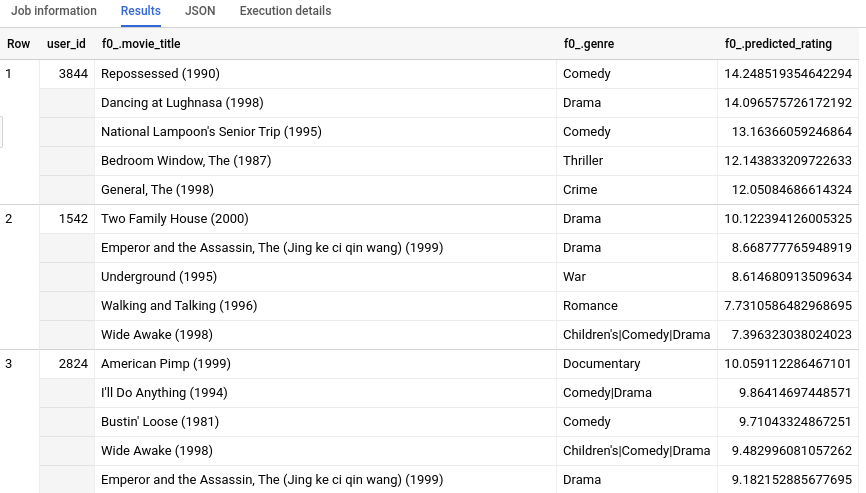
由于除了 INT64 之外,我们还拥有关于每个 movie_id 的其他元数据信息,因此我们可以看到为每位用户推荐的前 5 部电影的信息,如类型。如果您的训练数据没有 movietitles 等效表,则结果可能仅包含数字 ID 或哈希值这些人类不容易解释的内容。
每种因子的前几个类型
如果您想知道每个潜在因子可能与哪些类型相关,您可以运行以下查询:
#standardSQL SELECT factor, ARRAY_AGG(STRUCT(feature, genre, weight) ORDER BY weight DESC LIMIT 10) AS weights FROM ( SELECT * EXCEPT(factor_weights) FROM ( SELECT * FROM ( SELECT factor_weights, CAST(feature AS INT64) as feature FROM ML.WEIGHTS(model `bqml_tutorial.my_explicit_mf_model`) WHERE processed_input= 'item_id') JOIN `movielens.movie_titles` ON feature = movie_id) weights CROSS JOIN UNNEST(weights.factor_weights) ORDER BY feature, weight DESC) GROUP BY factor
查询详情
最内层的 SELECT 语句获取 item_id 或电影因子权重数组,然后将其与 movielens.movie_titles 表联接以获取每个推荐项 ID 的类型。
然后,将其结果与每个 factor_weights 数组进行 CROSS JOIN,然后对其结果执行 ORDER BY feature, weight DESC 操作。
最后,外层 SELECT 语句按 factor 聚合其内部语句的结果,并为每个因子创建一个数组,该数组按每个类型的权重排序。
运行查询
如需运行上述查询按因子输出前 10 个电影类型,请执行以下操作:
在 Google Cloud 控制台中,点击编写新查询按钮。
在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL SELECT factor, ARRAY_AGG(STRUCT(feature, genre, weight) ORDER BY weight DESC LIMIT 10) AS weights FROM ( SELECT * EXCEPT(factor_weights) FROM ( SELECT * FROM ( SELECT factor_weights, CAST(feature AS INT64) as feature FROM ML.WEIGHTS(model `bqml_tutorial.my_explicit_mf_model`) WHERE processed_input= 'item_id') JOIN `movielens.movie_titles` ON feature = movie_id) weights CROSS JOIN UNNEST(weights.factor_weights) ORDER BY feature, weight DESC) GROUP BY factor
(可选)如需设置处理位置,请依次点击更多 > 查询设置。在处理位置部分中,选择
US。此步骤是可选的,因为系统将根据数据集的位置自动检测处理位置。 点击运行。
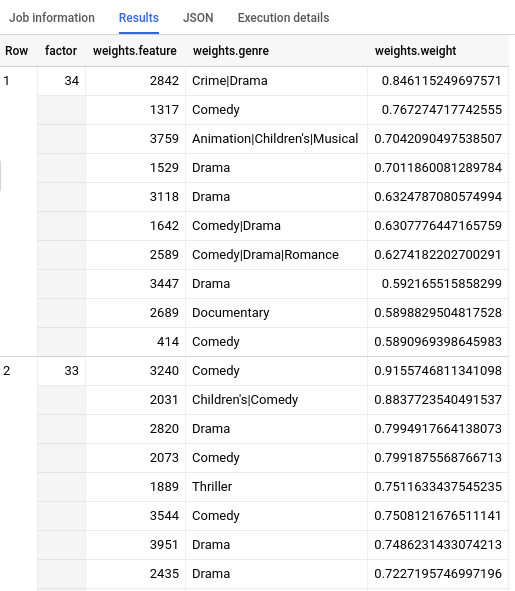
查询完成后,点击查询文本区域下方的结果标签页。结果应如下所示:
清除数据
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
- 删除您在教程中创建的项目。
- 或者,保留项目但删除数据集。
删除数据集
删除项目也将删除项目中的所有数据集和所有表。如果您希望重复使用该项目,则可以删除在本教程中创建的数据集:
如有必要,请在 Google Cloud 控制台中打开 BigQuery 页面。
在导航窗格中,点击您创建的 bqml_tutorial 数据集。
点击窗口右侧的删除数据集。此操作会删除相关数据集、表和所有数据。
在删除数据集对话框中,输入您的数据集的名称 (
bqml_tutorial),然后点击删除以确认删除命令。
删除项目
要删除项目,请执行以下操作:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
- 要详细了解机器学习,请参阅机器学习速成课程。
- 如需大致了解 BigQuery ML,请参阅 BigQuery ML 简介。
- 如需详细了解 Google Cloud 控制台,请参阅使用 Google Cloud 控制台。