BI Engine とは
BigQuery BI Engine は、頻繁に使用するデータをインテリジェントにキャッシュに保存することで、BigQuery の多くの SQL クエリを高速化する高速なメモリ内分析サービスです。データ可視化ツールにより作成されたものを含む任意のソースからの SQL クエリを高速化し、継続的な最適化のためにキャッシュ テーブルを管理します。これにより、手動調整やデータ階層化を行わずに、クエリのパフォーマンスを向上させることができます。クラスタリングとパーティショニングを使用すると、BI Engine で大規模なテーブルのパフォーマンスをさらに最適化できます。
たとえば、ダッシュボードに直前の四半期のデータのみを表示する場合は、最新のパーティションのみがメモリに読み込まれるように、テーブルを時間で分割することを検討します。また、マテリアライズド ビューと BI Engine のメリットを組み合わせることもできます。これは、マテリアライズド ビューを使用してデータを結合、フラット化して BI Engine の構造を最適化する場合に特に効果的です。
BI Engine には次の利点があります。
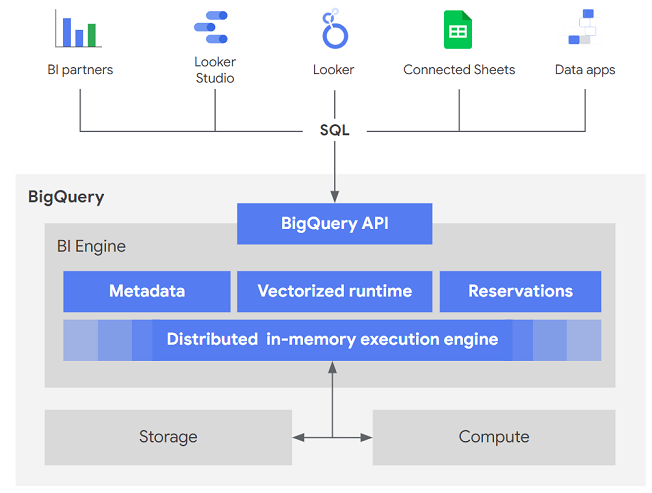
- BigQuery API: BI Engine は BigQuery API と直接統合されます。BI ソリューションまたは REST ドライバや JDBC ODBC ドライバなどの標準メカニズムを介して BigQuery API と連携するカスタム アプリケーションは、変更なしで BI Engine を使用できます。
- ベクトル化ランタイム: BI Engine では、BigQuery はベクトル処理と呼ばれる最新の手法を使用します。実行エンジンでベクトル化された処理を使用すると、データのバッチを一度に処理することで、最新の CPU アーキテクチャをより効率的に利用できます。BI Engine はさらに、高度なデータ エンコード(具体的には、辞書のランレングス圧縮)を使用して、メモリ内レイヤに保存されているデータをさらに圧縮します。
- シームレスな統合: BI Engine は、承認済みビュー、行レベルのセキュリティ、データ マスキングなど、BigQuery 機能やメタデータと連携します。
- 予約: BI Engine の予約では、プロジェクトのロケーション レベルでメモリ割り当てを管理します。BI Engine は、クエリ対象の特定の列またはパーティションをキャッシュに保存し、テーブル内でそれらを「優先」とマークします。
BI Engine のアーキテクチャ
BI Engine は、Looker、Tableau、Power BI、カスタム アプリケーションなどのビジネス インテリジェンス(BI)ツールと統合され、データ探索と分析を高速化します。
BI Engine のユースケース
BI Engine は、BI ダッシュボードに使用される SQL クエリなど、多くの SQL クエリを大幅に高速化できます。クエリに必要なテーブルを特定してから優先テーブルとマークする場合、高速化が最も効果的です。BI Engine を使用するには、BI Engine 専用のストレージ容量を定義する予約を作成します。BigQuery は、プロジェクトの使用パターンに基づいてキャッシュに保存するテーブルを決定できます。また、特定のテーブルにマークを付けて、他のトラフィックが高速化を妨げないようにすることもできます。
BI Engine は、次のユースケースで役立ちます。
- BI ツールを使用してデータを分析する: BI Engine は、BigQuery コンソール、クライアント ライブラリ、または API、ODBC コネクタまたは JDBC コネクタのいずれで実行するかに関係なく、BigQuery クエリを高速化できます。これにより、組み込みの接続(API)やコネクタを介して BigQuery に接続するダッシュボードのパフォーマンスが大幅に向上します。
- 最も頻繁に照会される特定のテーブルがある場合: BI Engine では、高速化する特定の優先テーブルを指定できます。これは、最も頻繁に照会されるテーブルのサブセットがある場合や、可視性の高いダッシュボードに使用される場合に便利です。
次のような場合には、BI Engine がニーズに合わない可能性があります。
クエリでワイルドカードを使用する: ワイルドカード テーブルを参照するクエリは BI Engine でサポートされておらず、高速化のメリットはありません。
サポートされていない BigQuery の機能に大いに依存する: BI Engine は、ビジネス インテリジェンス(BI)ツールを BigQuery に接続する場合に、ほとんどの SQL 関数と演算子をサポートしていますが、外部テーブルや SQL 以外のユーザー定義関数など、サポートされていない機能もあります。
BI Engine に関する考慮事項
BI Engine の構成方法を決定する際には、次の点を考慮してください。
特定のクエリが必ず高速化されるようにする
特定のクエリセットが常に高速化されるようにするには、BI Engine 予約を使用して別のプロジェクトを作成します。そのためには、そのプロジェクトの BI Engine 予約が、それらのクエリで使用されるすべてのテーブルのサイズに十分対応していることを確認し、それらのテーブルを BI Engine の優先テーブルとして指定します。そのプロジェクトで実行する必要があるのは、高速化が必要なクエリのみです。
結合を最小化する
BI Engine は、事前に結合されたか事前に集計されたデータと、少数の結合でのデータで最適に動作します。これは、小さいディメンション テーブルと結合された大きなファクト テーブルをクエリする場合など、結合の片側が大きくもう一方がはるかに小さい場合に特に当てはまります。BI Engine を、結合を行って単一の大規模なフラット テーブルを生成するマテリアライズド ビューと組み合わせることができます。この場合、すべてのクエリで同じ結合を実行する必要はありません。
BI Engine の影響を把握する
Cloud Monitoring での使用統計情報を確認するか、BigQuery で INFORMATION_SCHEMA に対してクエリを実行することで、ワークロードが BI Engine からどのようなメリットを得るかを理解できます。最も正確な比較を行うために、BigQuery の [キャッシュされた結果を使用] オプションを無効にしてください。詳細については、キャッシュに保存されたクエリ結果を使用するをご覧ください。
制限事項
VECTOR_SEARCH 関数を含むクエリは、BigQuery BI Engine による高速化が行われません。
割り当てと上限
BI Engine に適用される割り当てと上限については、BigQuery の割り当てと上限をご覧ください。
料金
BI Engine の料金の詳細については、BigQuery の料金ページをご覧ください。
クエリの最適化と高速化
BigQuery と拡張 BI Engine では、SQL クエリ用に生成されたクエリプランがサブクエリに分割されます。サブクエリには、データのスキャン、フィルタリング、集計などのさまざまなオペレーションが含まれ、多くの場合、シャードでの実行単位になります。
BigQuery でサポートされている SQL クエリはすべて BI Engine によって正しく実行されますが、特定のサブクエリのみが最適化されます。特に BI Engine は、ストレージからデータをスキャンし、フィルタ、コンピューティング、集計、並べ替え、特定の種類の結合などのオペレーションを実行するリーフレベルのサブクエリに最も最適化されています。BI Engine によってまだ完全に高速化されてないその他のサブクエリは、実行のために BigQuery に戻されます。
このように選択的に最適化することで、実行時間の大部分が元データを処理するリーフレベルのサブクエリに費やされるため、より簡単なビジネス インテリジェンスまたはダッシュボード タイプのクエリ(サブクエリの数が少なくなる)は BI Engine で最も効果があります。
次のステップ
- BI Engine の最適化される関数について学習する。
- BI Engine 予約の作成方法については、BI Engine の容量を予約するをご覧ください。
- 優先テーブルの指定については、BI Engine 優先テーブルをご覧ください。
- BI Engine の使用率を理解するには、Cloud Monitoring で BI Engine をモニタリングするをご覧ください。