空间分析最佳实践
本文档介绍了在 BigQuery 中优化地理空间查询性能的最佳实践。您可以采用这些最佳实践来提高性能并降低成本和缩短延迟时间。
数据集可以包含大量多边形、多边形集形状和线串,用来表示复杂的特征,例如道路、地块和洪泛区。每个形状都可以包含数千个点。在 BigQuery 的大多数空间运算(例如,交集和距离计算)中,底层算法通常需要遍历每个形状中的大多数点才能生成结果。对于某些运算,算法会遍历所有点。对于复杂形状,遍历每个点可能会增加空间运算的费用和时长。您可以使用本指南中介绍的策略和方法来优化这些常见的空间运算,从而提高性能并降低费用。
本文档假定您的 BigQuery 地理空间表按地理位置列进行聚簇。
简化形状
最佳实践:使用简化和网格对齐函数将原始数据集的简化版本存储为物化视图。
许多包含大量点的复杂形状都可以简化,而不会损失太多精度。单独或同时使用 BigQuery ST_SIMPLIFY 和 ST_SNAPTOGRID 函数可减少复杂形状中的点数。将这些函数与 BigQuery 物化视图结合使用,以将原始数据集的简化版本存储为物化视图,该视图会根据基表自动保持最新状态。
简化形状对于在以下应用场景中降低数据集的费用和提高数据集的性能最有用:
- 您需要保持与真实形状高度相似。
- 您必须执行高精度、高准确度的操作。
- 您希望加快可视化速度,同时不会明显丢失形状细节。
以下代码示例展示了如何对具有名为 geom 的 GEOGRAPHY 列的基表使用 ST_SIMPLIFY 函数。该代码会简化形状并移除点,而不会使形状的任何边缘超出给定的容差 1.0 米。
CREATE MATERIALIZED VIEW project.dataset.base_mv
CLUSTER BY geom
AS (
SELECT
* EXCEPT (geom),
ST_SIMPLIFY(geom, 1.0) AS geom
FROM base_table
)
以下代码示例展示了如何使用 ST_SNAPTOGRID 函数将点对齐分辨率为 0.00001 度的网格:
CREATE MATERIALIZED VIEW project.dataset.base_mv
CLUSTER BY geom
AS (
SELECT
* EXCEPT (geom),
ST_SNAPTOGRID(geom, -5) AS geom
FROM base_table
)
此函数中的 grid_size 参数用作指数,这意味着 10e-5 = 0.00001。该精度分辨率在精度最低的情况下(出现在赤道时)大约相当于 1 米。
创建这些视图后,使用用于查询基表的相同查询语义来查询 base_mv 视图。您可以使用此方法快速确定需要更深入分析的一组形状,然后对基表执行第二次更深入的分析。测试查询,了解哪些阈值最适合您的数据。
对于测量应用场景,请确定您的应用场景所需的准确度。使用 ST_SIMPLIFY 函数时,将 threshold_meters 参数设置为所需的准确度。在城市及以上尺度的距离测量中,请将阈值设置为 10 米。在较小尺度下(例如测量建筑物与最近水体的距离时),请考虑使用 1 米或更小的阈值。使用较小的阈值会导致从给定形状中移除的点更少。
从 Web 服务提供地图图层时,您可以使用 bigquery-geotools 项目预先计算不同缩放级别的物化视图,该项目是 Geoserver 的驱动机制,可让您从 BigQuery 提供空间图层。此驱动机制会创建多个具有不同 ST_SIMPLIFY 阈值参数的物化视图,以便在较高缩放级别呈现较少的细节。
使用点和矩形
最佳实践:将形状缩减为点或矩形,以表示其位置。
您可以将形状缩减为单个点或矩形,从而提高查询性能。本部分中的方法无法准确表示形状的详细信息和比例,而是针对表示形状的位置进行了优化。
您可以使用形状的地理中心点(其形心)来表示整个形状的位置。使用包含形状的矩形来创建形状的范围,您可以使用该范围来表示形状的位置并保留其相对大小的信息。
当您需要测量两点(例如两座城市)之间的距离时,使用点和矩形对于改善数据集的成本和性能最有用。
例如,考虑将美国地块的数据库加载到 BigQuery 表中,然后确定最近的水域。
在这种情况下,使用 ST_CENTROID 函数结合本文档简化形状部分中所述的方法预计算地块形心,可以减少使用 ST_DISTANCE 或 ST_DWITHIN 函数时执行的比较次数。使用 ST_CENTROID 函数时,需要在计算中考虑地块形心。以这种方式预计算地块形心还可以减少性能波动,因为不同的地块形状可能包含不同数量的点。
此方法的一种变体是使用 ST_BOUNDINGBOX 函数(而非 ST_CENTROID 函数),来计算输入形状的矩形包络。虽然这种方法不如使用单个节点高效,但可以减少某些边缘情况的发生。此变体仍能提供良好且一致的性能,因为 ST_BOUNDINGBOX 函数的输出始终只包含四个需要考虑的点。边界框结果的类型为 STRUCT,这意味着您需要手动计算距离,或使用本文档后面介绍的向量索引方法。
使用包 (hull)
最佳实践:使用包进行优化以表示形状的位置。
如果将某个形状进行收缩包裹并计算收缩包裹的边界,该边界称为包。在凸包中,生成的形状的所有角度都是凸的。与形状的范围一样,凸包会保留有关底层形状的相对大小和比例的一些信息。不过,使用包的代价是需要在后续分析中存储和考虑更多点。
您可以使用 ST_CONVEXHULL 函数进行优化以表示形状的位置。使用此函数可提高准确性,但代价是降低性能。ST_CONVEXHULL 函数类似于 ST_EXTENT 函数,不同之处在于输出形状包含更多点,且点数因输入形状的复杂程度而异。对于非复杂形状的小型数据集,性能优势可能微不足道;但对于形状较大且复杂的大型数据集,ST_CONVEXHULL 函数可在成本、性能和准确性之间取得良好的平衡。
使用网格系统
最佳实践:使用地理空间网格系统比较区域。
如果您的应用场景涉及汇总本地化区域内的数据,并将这些区域的统计汇总数据进行比较,那么您可以利用标准化网格系统来比较不同区域。
例如,零售商可能希望分析其商店所在区域或他们考虑开设新店的区域的人口特征随时间的变化情况。或者,保险公司可能希望通过分析特定区域的普遍自然灾害风险,来加深对房产风险的了解。
使用标准网格系统(例如 S2 和 H3)可以加快此类统计汇总和空间分析的速度。使用这些网格系统还可以简化分析开发并提高开发效率。
例如,使用美国人口普查区进行比较会遇到大小不一致的问题,这意味着需要应用修正因子才能在人口普查区之间进行类似比较。此外,人口普查区和其他行政区划会随着时间的推移而发生变化,需要付出努力来修正这些变化。使用网格系统进行空间分析可以解决此类问题。
使用向量搜索和向量索引
最佳实践:使用向量搜索和向量索引进行最近邻地理空间查询。
BigQuery 中引入了向量搜索功能,以支持语义搜索、相似性检测和检索增强生成等机器学习应用场景。实现这些应用场景的关键是使用一种称为近似最近邻搜索的索引编制方法。您可以使用向量搜索,通过比较表示空间中点的向量来加快和简化最近邻地理空间查询。
您可以使用向量搜索按半径搜索特征。首先,为搜索建立半径。您可以在最近邻搜索的结果集中发现最佳半径。建立半径后,使用 ST_DWITHIN 函数识别附近的特征。
例如,可以考虑查找距离您已知位置的特定锚定建筑物最近的 10 栋建筑物。您可以将每栋建筑的形心作为向量存储在新表中,为表建立索引,并使用向量搜索进行搜索。
在本例中,您还可以使用 BigQuery 中的 Overture Maps 数据创建一个单独的建筑物形状表,该表对应感兴趣的地区和一个名为 geom_vector 的向量。本示例中的感兴趣的地区是美国弗吉尼亚州诺福克市,由 FIPS 代码 51710 表示,如以下代码示例所示:
CREATE TABLE vector_search.norfolk_buildings
AS (
SELECT
*,
[
ST_X(ST_CENTROID(building.geometry)),
ST_Y(ST_CENTROID(building.geometry))] AS geom_vector
FROM `bigquery-public-data.overture_maps.building` AS building
INNER JOIN `bigquery-public-data.geo_us_boundaries.counties` AS county
ON (st_intersects(county.county_geom, building.geometry))
WHERE county.county_fips_code = '51710'
)
以下代码示例展示了如何对表创建向量索引:
CREATE
vector index building_vector_index
ON
vector_search.norfolk_buildings(geom_vector)
OPTIONS (index_type = 'IVF')
此查询会标识距离特定锚定建筑物最近的 10 栋建筑物:
SELECT base.*
FROM
VECTOR_SEARCH(
TABLE vector_search.norfolk_buildings,
'geom_vector',
(
SELECT
geom_vector
FROM
vector_search.norfolk_buildings
WHERE id = '56873794-9873-4fe1-871a-5987bb3a0efb'
),
top_k => 10,
distance_type => 'EUCLIDEAN',
options => '{"fraction_lists_to_search":0.1}')
在查询结果窗格中,点击可视化图表标签页。该地图显示了与锚定建筑物最近的一组建筑物形状:
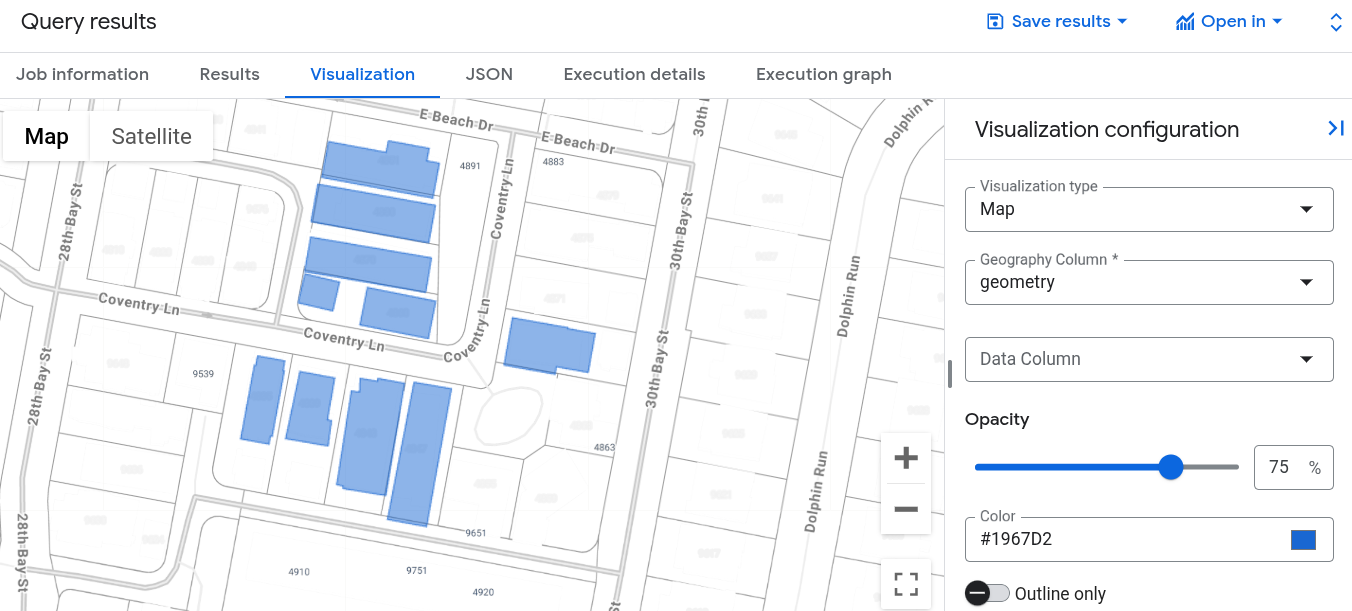
在 Google Cloud 控制台中运行此查询时,点击作业信息,并验证向量索引使用模式是否已设置为 FULLY_USED。这表示查询正在利用您之前创建的 building_vector_index 向量索引。
细分大型图形
最佳实践:使用 ST_SUBDIVIDE 函数细分大型形状。
使用 ST_SUBDIVIDE 函数可将大型形状或长线字符串拆分为较小形状。
后续步骤
- 了解如何使用网格系统进行空间分析。
- 详细了解 BigQuery 地理位置函数。
- 了解如何管理向量索引。
- 详细了解 BigQuery 中空间索引和聚簇的最佳实践。
- 如需详细了解如何在 BigQuery 中分析和直观呈现地理空间数据,请参阅地理空间分析使用入门。