クエリ パフォーマンスの最適化の概要
このドキュメントでは、BigQuery でのクエリ パフォーマンスを向上できる最適化手法の概要について説明します。一般的に、処理の少ないクエリほど優れたパフォーマンスを発揮します。実行速度が速く、より少ないリソースしか消費しないため、費用を削減でき、障害も発生しにくくなります。
クエリのパフォーマンス
BigQuery でのクエリのパフォーマンスの評価には、いくつかの要因が関わります。
- 入力データとデータソース(I/O): クエリで何バイト読み取るか。
- ノード間の通信(シャッフル): クエリから次の段階に何バイト転送するか。クエリは各スロットに何バイトずつ渡すか。
- コンピューティング: クエリにはどのくらいの CPU 作業が必要か。
- 出力(実体化): クエリは何バイト書き込むか。
- 容量と同時実行: 使用可能なスロットの数と、同時に実行されている他のクエリの数。
- クエリのパターン: クエリは SQL のベスト プラクティスに従っているか。
特定のクエリを評価する、またはリソースの競合が発生しているかを評価するには、Cloud Monitoring または BigQuery 管理リソースグラフを使用して、BigQuery ジョブによるリソース消費の推移をモニタリングします。低速またはリソースを大量消費しているクエリを特定すれば、そのクエリのパフォーマンス最適化に注力できます。
一部のクエリパターン、特にビジネス インテリジェンス ツールによって生成されたクエリパターンは、BigQuery BI Engine を使用すると高速化できます。BI Engine は、頻繁に使用するデータをインテリジェントにキャッシュに保存することで、BigQuery の多くの SQL クエリを高速化する、高速なメモリ内分析サービスです。BI Engine は BigQuery に組み込まれているため、クエリを変更することなくパフォーマンスを向上できることがよくあります。
他のシステムと同様に、パフォーマンスの最適化にもトレードオフが伴います。たとえば、高度な SQL 構文を使用すると、複雑さが増し、SQL の専門家ではないとクエリを理解できなくなる可能性もあります。また、重要ではないワークロードのマイクロ最適化に時間を費やすと、アプリケーションの新機能の構築や、より重要な最適化の特定を行うためのリソースが不足することになります。費用対効果を最大にするため、データ分析パイプラインで最も重要なワークロードの最適化に集中することをおすすめします。
容量と同時実行への最適化
BigQuery では、クエリに関してオンデマンドと容量ベースの 2 種類の料金モデルが用意されています。オンデマンド モデルは容量の共有プールを提供します。料金は、実行する各クエリで処理されるデータの量に基づきます。
容量ベース モデルは、毎月の支出を一定にしたい場合や、オンデマンド モデルで使用可能な容量よりも多くの容量が必要な場合におすすめです。容量ベースの料金を使用する場合は、スロット単位で測定される専用のクエリ処理容量を割り当てます。容量ベースの料金には、処理されたすべてのバイト数の費用が含まれます。固定のスロット コミットメントに加えて、自動スケーリング スロットを使用できます。これは、クエリ ワークロードに基づいて動的な容量を提供します。
同じデータに対して繰り返し実行されるクエリのパフォーマンスは変動する可能性があります。一般に、オンデマンド スロットを使用するクエリでは、スロット予約を使用するクエリよりも変動が大きくなります。
BigQuery は、SQL クエリの処理中に、クエリの各ステージの実行に必要な計算能力をスロットに分割します。BigQuery では、同時に実行できるクエリの数は次のように自動的に決定されます。
- オンデマンド モデル: プロジェクトで使用可能なスロットの数
- 容量ベースのモデル: 予約で使用可能なスロットの数
使用可能なスロットよりも多くのスロットを必要とするクエリは、処理リソースが使用可能になるまでキューに入れられます。クエリの実行が開始されると、BigQuery は、ステージのサイズと複雑さ、使用可能なスロット数に基づいて、各クエリステージで使用するスロット数を計算します。BigQuery は、フェア スケジューリングと呼ばれる手法を使用して、各クエリが進行できるだけの十分な容量を確保します。
利用できるスロットが多いからといって、必ずしもクエリのパフォーマンスが速くなるとは限りません。ただし、スロットプールが大きいほど、大規模なクエリや複雑なクエリのパフォーマンスと、同時実行の多いワークロードのパフォーマンスが向上します。クエリのパフォーマンスを向上させるには、スロット予約を変更するか、スロットの自動スケーリングの上限を高く設定します。
クエリプランとタイムライン
BigQuery は、クエリを実行するたびにクエリプランを生成します。クエリを効果的に最適化するには、このプランを把握することが重要です。クエリプランには、読み取りバイト数や消費されたスロット時間など、実行統計が含まれます。クエリプランには実行のさまざまなステージの詳細も含まれており、クエリのパフォーマンスを診断して改善するうえで役立ちます。クエリ実行グラフは、クエリプランを表示してクエリのパフォーマンスに関する問題を診断するためのグラフィカル インターフェースを提供します。
また、jobs.get API メソッドまたは INFORMATION_SCHEMA.JOBS ビューを使用してクエリプランとタイムライン情報を取得することもできます。この情報は、BigQuery ジョブの実行ステージのフローを視覚的に表すオープンソース ツールである BigQuery Visualiser で使用されます。
BigQuery がクエリジョブを実行すると、宣言型の SQL ステートメントを実行グラフに変換し、一連のクエリステージに分割します。クエリステージは、より細かい実行ステップから構成されます。BigQuery は、高度に分散された並列アーキテクチャを利用して、これらのクエリを実行します。BigQuery ステージは、多くのワーカーを同時に実行できる作業単位をモデル化しています。ステージは、高速の分散シャッフル アーキテクチャを介して相互に通信を行います。
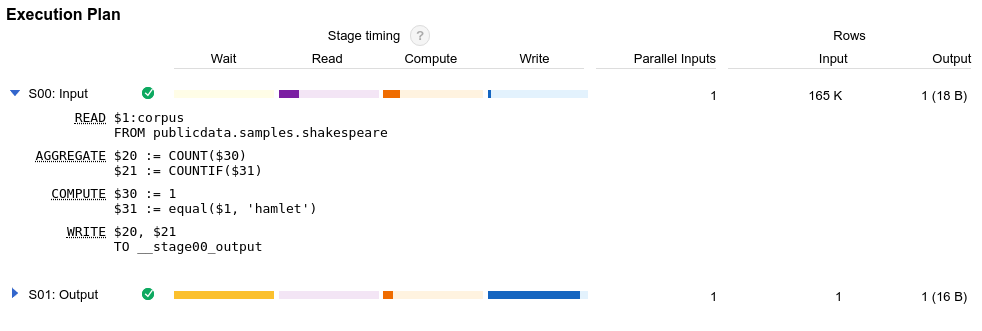
クエリプランに加えて、クエリジョブは実行のタイムラインを公開します。このタイムラインにより、クエリワーカー内で完了している作業単位、保留中の作業単位、アクティブな作業単位の数を確認できます。1 つのクエリで複数のステージが同時に処理される場合もあるため、タイムラインはクエリ全体の進行状況を把握する際に役立ちます。
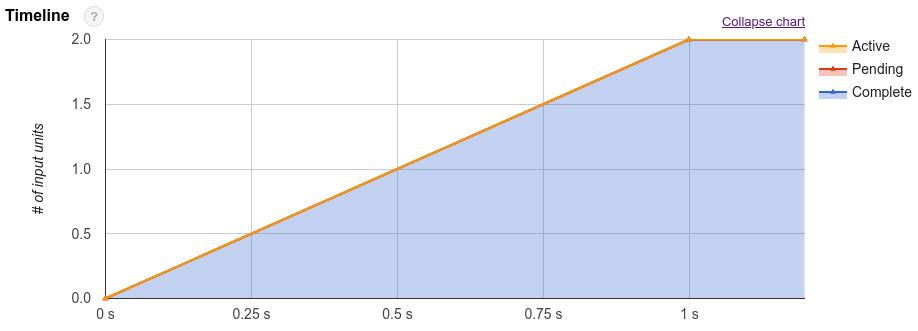
クエリの計算コストは、クエリが 1 秒あたりに消費するスロット数の合計で判断します。1 秒間で消費されるスロット数が少ないほど、同じプロジェクトで同時に実行されている他のクエリがより多くのリソースを使用できることを意味します。
クエリプランとタイムラインの統計情報は、BigQuery でのクエリの実行状態や、特定のステージでのリソースの使用状況の把握に役立ちます。たとえば、JOIN ステージで入力行よりも出力行が多い場合は、クエリの前にフィルタリングが必要かもしれません。ただし、サービスの管理特性のため、この情報をそのまま利用できるとは限りません。クエリの実行とパフォーマンスを改善するためのベスト プラクティスと手法については、クエリ計算の最適化をご覧ください。
次のステップ
- BigQuery 監査ログを使用して、クエリの実行の問題のトラブルシューティング方法を学習する。
- BigQuery のその他の費用管理手法を学習する。
INFORMATION_SHEMA.JOBSビューを使用して、BigQuery ジョブに関するニア リアルタイムのメタデータを表示する。- BigQuery システム テーブル レポートを使用して、BigQuery の使用状況をモニタリングする方法を学習する。