Einführung in die Optimierung der Abfrageleistung
Dieses Dokument bietet einen Überblick über Optimierungstechniken, die die Abfrageleistung in BigQuery verbessern können. Einfachere Abfragen sind in der Regel effizienter. Sie werden schneller ausgeführt und verbrauchen weniger Ressourcen, was zu geringeren Kosten und weniger Fehlern führen kann.
Abfrageleistung
Die Evaluierung der Abfrageleistung in BigQuery umfasst mehrere Faktoren:
- Eingabedaten und Datenquellen (E/A): Wie viele Byte liest die Abfrage?
- Kommunikation zwischen Knoten (nach dem Zufallsprinzip): Wie viele Byte werden bei der Abfrage an die nächste Phase übergeben? Wie viele Byte werden bei der Abfrage an jeden Slot übergeben?
- Verarbeitung: Wie viel CPU-Leistung benötigt die Anfrage?
- Ausgaben (Schreibergebnisse): Wie viele Byte schreibt die Abfrage?
- Kapazität und Gleichzeitigkeit: Wie viele Slots sind verfügbar und wie viele andere Abfragen werden gleichzeitig ausgeführt?
- Abfragemuster: Entsprechen die Abfragen den Best Practices für SQL?
Um festzustellen, ob bestimmte Abfragen problematisch sind oder ob Ressourcenkonflikte auftreten, können Sie Cloud Monitoring oder die administrativen BigQuery-Ressourcendiagramme verwenden, um zu überwachen, wie Ihre BigQuery-Jobs im Laufe der Zeit Ressourcen nutzen. Wenn Sie eine langsame oder ressourcenintensive Abfrage feststellen, können Sie sich auf Ihre Leistungsoptimierungen dafür konzentrieren.
Einige Abfragemuster, insbesondere solche, die von Business-Intelligence-Tools generiert werden, können mit BigQuery BI Engine beschleunigt werden. BI Engine ist ein schneller In-Memory-Analysedienst, der viele SQL-Abfragen in BigQuery beschleunigt. Dazu werden die am häufigsten verwendeten Daten auf intelligente Weise im Cache gespeichert. BI Engine ist in BigQuery eingebunden, sodass Sie häufig ohne Abfrageänderungen eine bessere Leistung erzielen.
Wie bei allen anderen Systemen auch, müssen bei der Leistungsoptimierung manchmal Kompromisse eingegangen werden. Beispielsweise macht die erweiterte SQL-Syntax die Dinge manchmal kompliziert und Abfragen für Nutzer, die keine SQL-Experten sind, weniger verständlich. Wenn Sie Zeit für kleinere Optimierungen für nicht kritische Arbeitslasten aufwenden, dann haben Sie möglicherweise weniger Ressourcen zum Erstellen neuer Funktionen für Ihre Anwendungen oder für die Identifizierung wichtigerer Optimierungen. Aus diesem Grund empfehlen wir Ihnen, sich bei der Optimierung auf die Arbeitslasten zu konzentrieren, die für Ihre Datenanalyse-Pipelines am wichtigsten sind, damit Sie den höchstmöglichen Return on Investment erzielen.
Kapazität und Nebenläufigkeit optimieren
Für Abfragen bietet BigQuery zwei Preismodelle: On-Demand- und kapazitätsbasierte Preise. Das On-Demand-Modell bietet einen gemeinsamen Kapazitätspool. Die Preise basieren auf der Datenmenge, die durch die einzelnen ausgeführten Abfragen verarbeitet wird.
Das kapazitätsbasierte Modell wird empfohlen, wenn Sie konsistente monatliche Ausgaben planen möchten oder mehr Kapazität benötigen, als beim On-Demand-Modell verfügbar ist. Wenn Sie kapazitätsbasierte Preise verwenden, weisen Sie eine dedizierte Abfrageverarbeitungskapazität zu, die in Slots gemessen wird. Die Kosten für alle verarbeiteten Byte sind im kapazitätsbasierten Preis enthalten. Zusätzlich zu den festen Slot-Zusicherungen können Sie Autoscaling-Slots verwenden, die basierend auf der Abfragearbeitslast eine dynamische Kapazität bieten.
Die Leistung von Abfragen, die wiederholt für dieselben Daten ausgeführt werden, kann variieren und die Abweichung ist bei Abfragen mit On-Demand-Slots im Allgemeinen größer als bei Abfragen mit Slot-Reservierungen.
Während der SQL-Abfrageverarbeitung teilt BigQuery die Rechenkapazität, die zum Ausführen der einzelnen Phasen einer Abfrage erforderlich ist, in Slots auf. So bestimmt BigQuery automatisch die Anzahl der Abfragen, die gleichzeitig ausgeführt werden können:
- On-Demand-Modell: Anzahl der im Projekt verfügbaren Slots
- Kapazitätsbasiertes Modell: Anzahl der in der Reservierung verfügbaren Slots
Abfragen, die mehr Slots benötigen als verfügbar sind, werden in die Warteschlange gestellt, bis die Verarbeitungsressourcen verfügbar sind. Nach dem Start der Abfrage berechnet BigQuery anhand der Größe und Komplexität der Abfragephasen sowie der Anzahl der verfügbaren Slots, wie viele Slots für jede Phase verwendet werden. BigQuery verwendet eine Methode namens faire Planung, um dafür zu sorgen, dass jede Abfrage über ausreichend Kapazität verfügt.
Der Zugang zu mehr Slots führt nicht immer zu einer schnelleren Abfrage. Ein größerer Slot-Pool kann jedoch die Leistung bei großen oder komplexen Abfragen sowie bei hohen gleichzeitigen Arbeitslasten verbessern. Zur Verbesserung der Abfrageleistung können Sie Ihre Slot-Reservierungen ändern oder ein höheres Limit für das Slot-Autoscaling festlegen.
Abfrageplan und Zeitachse
BigQuery generiert bei jeder Abfrageausführung einen Abfrageplan. Dieser Plan ist für eine effektive Abfrageoptimierung entscheidend. Der Abfrageplan enthält Ausführungsstatistiken wie die gelesenen Byte und die verbrauchte Slot-Zeit an. Der Abfrageplan enthält auch Details zu den verschiedenen Ausführungsphasen, was Ihnen dabei hilft, die Abfrageleistung zu diagnostizieren und zu verbessern. Das Diagramm zur Abfrageausführung bietet eine grafische Oberfläche zum Anzeigen des Abfrageplans und zum Diagnostizieren von Abfrageleistungsproblemen.
Sie können auch die API-Methode jobs.get oder die Ansicht INFORMATION_SCHEMA.JOBS verwenden, um Informationen zum Abfrageplan und zur Zeitachse abzurufen. Diese Informationen werden von BigQuery Visualiser verwendet, einem Open-Source-Tool, mit dem der Ablauf der Ausführungsphasen in einem BigQuery-Job visuell dargestellt wird.
Bei der Ausführung eines Abfragejobs in BigQuery wird die deklarative SQL-Anweisung in eine Ausführungsgrafik umgewandelt. Diese Grafik wird in eine Reihe von Abfragephasen aufgeteilt, die sich wiederum aus detaillierten Sätzen von Ausführungsschritten zusammensetzen. BigQuery nutzt eine stark verteilte parallele Architektur zum Ausführen dieser Abfragen. Dabei werden von den BigQuery-Phasen die Arbeitseinheiten modelliert, die viele potenzielle Worker parallel ausführen können. Phasen kommunizieren über eine schnelle verteilte Shuffle-Architektur miteinander.
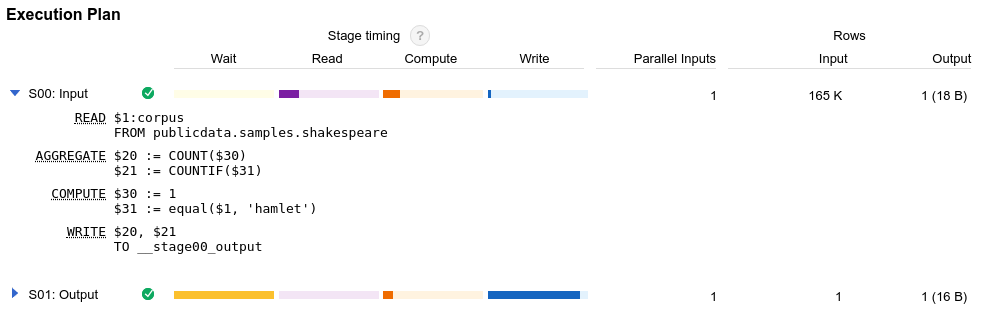
Neben dem Abfrageplan stellen Abfragejobs auch eine Zeitachse für die Ausführung bereit. In dieser Zeitachse werden die abgeschlossenen, ausstehenden und aktiven Arbeitseinheiten in den Abfrage-Workern aufgeführt. Eine Abfrage kann sich gleichzeitig in mehreren Phasen mit aktiven Workern befinden. Die Zeitachse dient also dazu, den Gesamtfortschritt der Abfrage anzuzeigen.
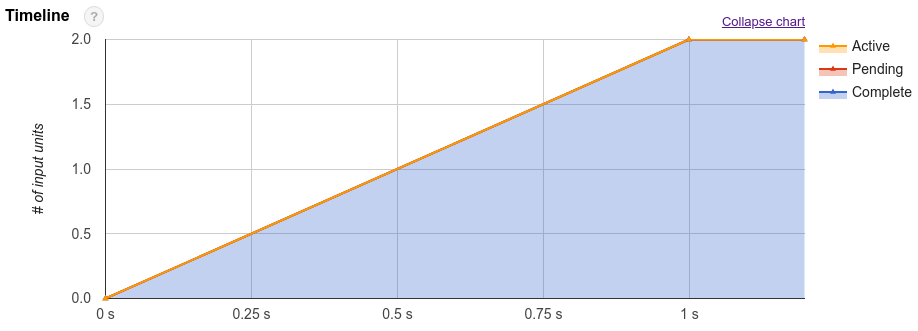
Wenn Sie einschätzen möchten, wie rechenintensiv eine Abfrage ist, können Sie sich die Gesamtzahl der Slotsekunden ansehen, die für die Abfrage gebraucht wurden. Je niedriger die Anzahl der Slotsekunden, desto besser. Denn niedriger bedeutet, dass mehr Ressourcen für andere Abfragen zur Verfügung stehen, die zur selben Zeit im selben Projekt ausgeführt werden.
Anhand des Abfrageplans und der Zeitachsenstatistiken können Sie nachvollziehen, wie Abfragen von BigQuery ausgeführt werden und ob die Ressourcenauslastung in bestimmten Phasen besonders hoch ist. Eine JOIN-Phase, in der weit mehr Ausgabezeilen als Eingabezeilen generiert werden, könnte zum Beispiel darauf hindeuten, dass früher in der Abfrage gefiltert werden sollte.
Da es sich um einen verwalteten Dienst handelt, sind allerdings die Möglichkeiten für die direkte Umsetzung einiger Details begrenzt. Best Practices und Techniken zur Verbesserung der Ausführung und Leistung von Abfragen finden Sie unter Abfrageberechnung optimieren.
Nächste Schritte
- Probleme mit der Abfrageausführung mithilfe von BigQuery-Audit-Logs beheben
- Weitere Kostenkontrolltechniken für BigQuery
- Metadaten zu BigQuery-Jobs mit der Ansicht
INFORMATION_SHEMA.JOBSnahezu in Echtzeit aufrufen - BigQuery-Nutzung mithilfe von BigQuery-Systemtabellenberichten überwachen