Menggunakan kolom bertingkat dan berulang
BigQuery dapat digunakan dengan berbagai metode pemodelan data, dan umumnya memberikan performa tinggi di banyak metodologi model data. Untuk menyesuaikan performa model data lebih lanjut, salah satu metode yang dapat Anda pertimbangkan adalah denormalisasi data, yang berarti menambahkan kolom data ke satu tabel untuk mengurangi atau menghapus penggabungan tabel.
Praktik terbaik: Gunakan kolom bertingkat dan berulang untuk melakukan denormalisasi penyimpanan data dan meningkatkan performa kueri.
Denormalisasi adalah strategi umum guna meningkatkan performa baca untuk set data relasional yang sebelumnya dinormalkan. Cara yang direkomendasikan untuk melakukan denormalisasi data di BigQuery adalah menggunakan kolom bertingkat dan berulang. Sebaiknya gunakan strategi ini saat hubungan bersifat hierarkis dan sering dikueri bersama, seperti dalam hubungan induk-turunan.
Penghematan penyimpanan dari penggunaan data yang dinormalkan kurang begitu berpengaruh dalam sistem modern. Peningkatan biaya penyimpanan sebanding dengan peningkatan performa dari penggunaan data yang didenormalisasi. Penggabungan memerlukan koordinasi data (bandwidth komunikasi). Denormalisasi melokalkan data ke setiap slot, sehingga eksekusi dapat dilakukan secara paralel.
Untuk mempertahankan hubungan sekaligus melakukan denormalisasi data, Anda dapat menggunakan kolom bertingkat dan berulang, bukan meratakan data sepenuhnya. Jika data relasional sepenuhnya diratakan, komunikasi jaringan (pengacakan) dapat berdampak negatif pada performa kueri.
Misalnya, denormalisasi skema pesanan tanpa menggunakan kolom bertingkat dan berulang mungkin mengharuskan Anda mengelompokkan data berdasarkan kolom seperti order_id (saat ada hubungan one-to-many). Karena proses shuffling, pengelompokan data kurang efektif dibandingkan dengan denormalisasi data menggunakan kolom bertingkat dan berulang.
Dalam beberapa situasi, denormalisasi data serta penggunaan kolom bertingkat dan berulang tidak menghasilkan peningkatan performa. Misalnya, skema bintang biasanya adalah skema yang dioptimalkan untuk analisis, sehingga performa mungkin tidak berbeda secara signifikan jika Anda mencoba melakukan denormalisasi lebih lanjut.
Menggunakan kolom bertingkat dan berulang
BigQuery tidak memerlukan denormalisasi yang rata sepenuhnya. Anda dapat menggunakan kolom bertingkat dan berulang untuk mempertahankan hubungan.
Data bertingkat (
STRUCT)- Data bertingkat memungkinkan Anda mewakili entity asing secara inline.
- Kueri data bertingkat menggunakan sintaksis "dot" untuk merujuk ke kolom leaf, yang serupa dengan sintaksis yang menggunakan penggabungan.
- Data bertingkat direpresentasikan sebagai jenis
STRUCTdi GoogleSQL.
Data berulang (
ARRAY)- Membuat kolom jenis
RECORDdengan mode yang ditetapkan keREPEATEDmemungkinkan Anda mempertahankan hubungan one-to-many secara inline (selama hubungan tersebut bukan kardinalitas tinggi). - Dengan data berulang, pengacakan tidak diperlukan.
- Data berulang direpresentasikan sebagai
ARRAY. Anda dapat menggunakan fungsiARRAYdi GoogleSQL saat membuat kueri data berulang.
- Membuat kolom jenis
Data bertingkat dan berulang (
ARRAYdariSTRUCT)- Susunan bertingkat dan pengulangan saling melengkapi.
- Misalnya, dalam tabel data transaksi, Anda dapat menyertakan array item baris
STRUCT.
Untuk mengetahui informasi selengkapnya, lihat Menentukan kolom bertingkat dan berulang dalam skema tabel.
Untuk mengetahui informasi selengkapnya tentang denormalisasi data, lihat Denormalisasi.
Contoh
Pertimbangkan tabel Orders dengan baris untuk setiap item baris yang terjual:
| Order_Id | Item_Name |
|---|---|
| 001 | A1 |
| 001 | B1 |
| 002 | A1 |
| 002 | C1 |
Jika ingin menganalisis data dari tabel ini, Anda harus menggunakan klausa GROUP BY, seperti berikut:
SELECT COUNT (Item_Name) FROM Orders GROUP BY Order_Id;
Klausa GROUP BY melibatkan overhead komputasi tambahan, tetapi hal ini dapat dihindari dengan menyusun data berulang secara bertingkat. Anda dapat menghindari penggunaan klausa GROUP BY
dengan membuat tabel berisi satu pesanan per baris, tempat item baris pesanan berada dalam kolom bertingkat:
| Order_Id | Item_Name |
|---|---|
| 001 |
A1 B1 |
| 002 |
A1 C1 |
Dalam BigQuery, Anda biasanya menetapkan skema bertingkat sebagai ARRAY dari objek STRUCT. Anda menggunakan operator UNNEST untuk meratakan data bertingkat, seperti yang ditunjukkan dalam kueri berikut:
SELECT * FROM UNNEST( [ STRUCT('001' AS Order_Id, ['A1', 'B1'] AS Item_Name), STRUCT('002' AS Order_Id, ['A1', 'C1'] AS Item_Name) ] );
Kueri ini memberikan hasil yang mirip dengan kueri berikut:
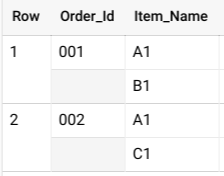
Jika data ini tidak bertingkat, Anda berpotensi memiliki beberapa baris untuk setiap pesanan, satu untuk setiap item yang terjual dalam pesanan tersebut, yang akan menghasilkan tabel besar dan operasi GROUP BY yang mahal.
Olahraga
Anda dapat melihat perbedaan performa pada kueri yang menggunakan kolom bertingkat dibandingkan dengan yang tidak menggunakan kolom bertingkat dengan mengikuti langkah-langkah di bagian ini.
Buat tabel berdasarkan set data publik
bigquery-public-data.stackoverflow.comments:CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow` AS ( SELECT user_id, post_id, creation_date FROM `bigquery-public-data.stackoverflow.comments` );
Dengan menggunakan tabel
stackoverflow, jalankan kueri berikut untuk melihat komentar paling awal bagi setiap pengguna:SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date AS earliest_comment) ORDER BY creation_date ASC LIMIT 1)[OFFSET(0)].* FROM `PROJECT.DATASET.stackoverflow` GROUP BY user_id ORDER BY user_id ASC;
Kueri ini membutuhkan waktu sekitar 25 detik untuk berjalan dan memproses data 1,88 GB.
Buat tabel kedua dengan data identik yang membuat kolom
commentsmenggunakan jenisSTRUCTuntuk menyimpan datapost_iddancreation_date, bukan dua kolom individual:CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow_nested` AS ( SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date) ORDER BY creation_date ASC) AS comments FROM `bigquery-public-data.stackoverflow.comments` GROUP BY user_id );
Dengan menggunakan tabel
stackoverflow_nested, jalankan kueri berikut untuk melihat komentar paling awal untuk setiap pengguna:SELECT user_id, (SELECT AS STRUCT post_id, creation_date as earliest_comment FROM UNNEST(comments) ORDER BY creation_date ASC LIMIT 1).* FROM `PROJECT.DATASET.stackoverflow_nested` ORDER BY user_id ASC;
Kueri ini membutuhkan waktu sekitar 10 detik untuk berjalan dan memproses data 1,28 GB.
Hapus tabel
stackoverflowdanstackoverflow_nestedsetelah selesai.