Migrar código com o tradutor de SQL em lote
Neste documento, descrevemos como usar o tradutor de SQL em lote no BigQuery para traduzir scripts escritos em outros dialetos de SQL em consultas do GoogleSQL. Este documento é destinado a usuários familiarizados com o console do Google Cloud .
Antes de começar
Antes de enviar um job de tradução, siga estas etapas:
- Verifique se você tem todas ss permissões necessárias.
- Ative a API BigQuery Migration.
- Colete os arquivos de origem que contêm os scripts SQL e as consultas a serem traduzidos.
- Opcional. Crie um arquivo de metadados para melhorar a precisão da tradução.
- Opcional. Decida se você precisa mapear nomes de objetos SQL nos arquivos de origem para novos nomes no BigQuery. Determine quais regras de mapeamento de nome usar se isso for necessário.
- Decida qual método usar para enviar o job de tradução.
- Faça upload dos arquivos de origem para o Cloud Storage.
Permissões necessárias
É necessário ter as seguintes permissões no projeto para ativar o serviço de migração do BigQuery:
resourcemanager.projects.getserviceusage.services.enableserviceusage.services.get
Você precisa das seguintes permissões no projeto para acessar e usar o serviço de migração do BigQuery:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.listComo alternativa, é possível usar os seguintes papéis para receber as mesmas permissões:
bigquerymigration.viewer: acesso somente de leitura.bigquerymigration.editor: acesso de leitura e gravação.
Para acessar os buckets do Cloud Storage para arquivos de entrada e saída:
storage.objects.getno bucket de origem do Cloud Storage.storage.objects.listno bucket de origem do Cloud Storage.storage.objects.createno bucket de destino do Cloud Storage.
É possível conseguir todas as permissões necessárias do Cloud Storage com estes papéis:
roles/storage.objectAdminroles/storage.admin
Ativar a API BigQuery Migration
Se o projeto da Google Cloud CLI foi criado antes de 15 de fevereiro de 2022, ative a API BigQuery Migration da seguinte maneira:
No console do Google Cloud , acesse a página API BigQuery Migration.
Clique em Ativar.
Coletar arquivos de origem
Os arquivos de origem precisam ser arquivos de texto com SQL válido para o dialeto de origem. Os arquivos de origem também podem incluir comentários. Faça o possível para garantir que o SQL seja válido usando os métodos disponíveis.
Criar arquivos de metadados
Para ajudar o serviço a gerar resultados de tradução mais precisos, recomendamos que você forneça arquivos de metadados. No entanto, isso não é obrigatório.
Use a ferramenta de extração de linha de comando dwh-migration-dumper para gerar as informações de metadados ou forneça seus próprios arquivos de metadados. Depois que os arquivos de metadados forem preparados, será possível incluí-los com os arquivos de origem na pasta de
origem da tradução. O tradutor os detecta automaticamente e os aproveita
para traduzir arquivos de origem. Não é necessário definir configurações extras para isso.
Para gerar informações de metadados usando a
ferramenta dwh-migration-dumper, consulte
Gerar metadados para tradução.
Para fornecer seus próprios metadados, colete as instruções de linguagem de definição de dados (DDL) dos objetos SQL do sistema de origem em arquivos de texto separados.
Decidir como enviar o trabalho de tradução
Você tem três opções para enviar um job de tradução em lote:
Cliente da tradução em lote: para definir um job, altere as configurações em um arquivo de configuração e envie o job usando a linha de comando. Essa abordagem não exige o upload manual dos arquivos de origem para o Cloud Storage. O cliente ainda usa o Cloud Storage para armazenar arquivos durante o processamento do job de tradução.
O cliente de tradução em lote legada é um cliente Python de código aberto que permite traduzir arquivos de origem localizados na máquina local e fazer com que os arquivos traduzidos sejam enviados para um diretório local. Defina o cliente para uso básico alterando algumas configurações no arquivo de configuração. Se quiser, também é possível configurar o cliente para realizar tarefas mais complexas, como substituição de macros e pré e pós-processamento de entradas e saídas de tradução. Para mais informações, consulte o readme do cliente de tradução em lote.
Console doGoogle Cloud : configure e envie um job usando uma interface de usuário. Essa abordagem exige que você faça upload de arquivos de origem para o Cloud Storage.
Criar arquivos YAML de configuração
Também é possível criar e usar arquivos YAML de configuração para personalizar as traduções em lote. Esses arquivos podem ser usados para transformar a saída da tradução de várias maneiras. Por exemplo, é possível criar um arquivo YAML de configuração para alterar o caso de um objeto SQL durante a conversão.
Se você quiser usar o Google Cloud console ou a API BigQuery Migration para um job de tradução em lote, faça upload do arquivo YAML de configuração para o bucket do Cloud Storage que contém os arquivos de origem.
Se você quiser usar o cliente de tradução em lote, coloque o arquivo YAML de configuração na pasta de entrada da tradução local.
Fazer upload de arquivos de entrada no Cloud Storage
Se você quiser usar o Google Cloud console ou a API BigQuery Migration para executar um job de tradução, faça upload dos arquivos de origem que contêm as consultas e os scripts que você quer traduzir para o Cloud Storage. Também é possível fazer upload de qualquer arquivo de metadados ou arquivos YAML de configuração para o mesmo bucket e diretório do Cloud Storage que contém os arquivos de origem. Para mais informações sobre como criar buckets e fazer upload de arquivos para o Cloud Storage, consulte Criar buckets e Fazer upload de objetos de um sistema de arquivos.
Dialetos SQL compatíveis
O tradutor do SQL em lote faz parte do Serviço de migração do BigQuery. O tradutor de SQL em lote traduz os seguintes dialetos SQL em GoogleSQL:
- SQL do Amazon Redshift
- Apache HiveQL e CLI Beeline
- IBM Netezza SQL e NZPLSQL
- Teradata e Teradata Vantage
- SQL
- Basic Teradata Query (BTEQ)
- Transporte paralelo do Teradata (TPT)
Além disso, a tradução dos seguintes dialetos SQL é suportada na versão de pré-lançamento:
- SQL do Apache Spark
- T-SQL do Azure Synapse
- SQL do Greenplum
- SQL do IBM DB2
- SQL para MySQL
- SQL da Oracle, PL/SQL, Exadata
- SQL do PostgreSQL
- Trino ou PrestoSQL
- SQL do Snowflake
- T-SQL do SQL Server
- SQLite
- SQL da Vertica
Como processar funções SQL sem suporte com UDFs auxiliares
Ao traduzir SQL de um dialeto de origem para o BigQuery, algumas funções podem não ter um equivalente direto. Para resolver isso, o BigQuery Migration Service (e a comunidade mais ampla do BigQuery) oferecem funções definidas pelo usuário (UDFs) auxiliares que replicam o comportamento dessas funções de dialeto de origem sem suporte.
Essas UDFs geralmente são encontradas no conjunto de dados públicos bqutil, permitindo que as consultas traduzidas se refiram a elas inicialmente usando o formato bqutil.<dataset>.<function>(). Por exemplo, bqutil.fn.cw_count().
Considerações importantes para ambientes de produção:
Embora o bqutil ofereça acesso conveniente a essas UDFs auxiliares para tradução e testes iniciais, não é recomendável depender diretamente do bqutil para cargas de trabalho de produção por vários motivos:
- Controle de versão: o projeto
bqutilhospeda a versão mais recente dessas UDFs, o que significa que as definições podem mudar com o tempo. Depender diretamente debqutilpode levar a um comportamento inesperado ou a mudanças incompatíveis nas consultas de produção se a lógica de uma UDF for atualizada. - Isolamento de dependências: a implantação de UDFs no seu próprio projeto isola o ambiente de produção de mudanças externas.
- Personalização: talvez seja necessário modificar ou otimizar essas UDFs para se adequar melhor à sua lógica de negócios ou requisitos de performance específicos. Isso só é possível se eles estiverem no seu projeto.
- Segurança e governança: as políticas de segurança da sua organização podem restringir o acesso direto a conjuntos de dados públicos, como
bqutil, para o processamento de dados de produção. Copiar UDFs para seu ambiente controlado está de acordo com essas políticas.
Como implantar UDFs auxiliares no projeto:
Para um uso de produção confiável e estável, implante essas UDFs auxiliares no seu próprio projeto e conjunto de dados. Assim, você tem controle total sobre a versão, a personalização e o acesso. Para instruções detalhadas sobre como implantar essas UDFs, consulte o guia de implantação de UDFs no GitHub. Este guia fornece os scripts e as etapas necessárias para copiar as UDFs para seu ambiente.
Locais
O conversor de SQL em lote está disponível nos seguintes locais de processamento:
| Descrição da região | Nome da região | Detalhes | |
|---|---|---|---|
| Ásia-Pacífico | |||
| Délhi | asia-south2 |
||
| Hong Kong | asia-east2 |
||
| Jacarta | asia-southeast2 |
||
| Melbourne | australia-southeast2 |
||
| Mumbai | asia-south1 |
||
| Osaka | asia-northeast2 |
||
| Seul | asia-northeast3 |
||
| Singapura | asia-southeast1 |
||
| Sydney | australia-southeast1 |
||
| Taiwan | asia-east1 |
||
| Tóquio | asia-northeast1 |
||
| Europa | |||
| Bélgica | europe-west1 |
|
|
| Berlim | europe-west10 |
|
|
| UE multirregião | eu |
||
| Finlândia | europe-north1 |
|
|
| Frankfurt | europe-west3 |
||
| Londres | europe-west2 |
|
|
| Madri | europe-southwest1 |
|
|
| Milão | europe-west8 |
||
| Países Baixos | europe-west4 |
|
|
| Paris | europe-west9 |
|
|
| Estocolmo | europe-north2 |
|
|
| Turim | europe-west12 |
||
| Varsóvia | europe-central2 |
||
| Zurique | europe-west6 |
|
|
| América | |||
| Columbus, Ohio | us-east5 |
||
| Dallas | us-south1 |
|
|
| Iowa | us-central1 |
|
|
| Las Vegas | us-west4 |
||
| Los Angeles | us-west2 |
||
| México | northamerica-south1 |
||
| Norte da Virgínia | us-east4 |
||
| Oregon | us-west1 |
|
|
| Quebec | northamerica-northeast1 |
|
|
| São Paulo | southamerica-east1 |
|
|
| Salt Lake City | us-west3 |
||
| Santiago | southamerica-west1 |
|
|
| Carolina do Sul | us-east1 |
||
| Toronto | northamerica-northeast2 |
|
|
| EUA multirregião | us |
||
| África | |||
| Johannesburgo | africa-south1 |
||
| MiddleEast | |||
| Damã | me-central2 |
||
| Doha | me-central1 |
||
| Israel | me-west1 |
||
Enviar um job de tradução
Siga estas etapas para iniciar um job de tradução, ver o progresso dele e ver os resultados.
Console
Para seguir essas etapas, é necessário ter feito upload dos arquivos de origem em um bucket do Cloud Storage.
No console do Google Cloud , acesse a página BigQuery.
No menu de navegação, clique em Ferramentas e guia.
No painel Traduzir SQL, clique em Traduzir > Tradução em lote.
A página de configuração de tradução é aberta. Digite os seguintes detalhes:
- Em Nome de exibição, digite um nome para o job de tradução. O nome pode conter letras, números ou sublinhados.
- Em local de processamento, selecione o local em que você quer que o
trabalho de tradução seja executado. Por exemplo, se você estiver na Europa e não quiser que seus dados cruzem os limites de local, selecione a região
eu. O job de tradução tem um desempenho melhor quando você escolhe o mesmo local que seu bucket de arquivo de origem. - Em Dialeto de origem, selecione o dialeto SQL que você quer traduzir.
- Em Dialeto desejado, selecione BigQuery.
Clique em Próxima.
Em Local da origem, especifique o caminho da pasta do Cloud Storage que contém os arquivos a serem traduzidos. É possível digitar o caminho no formato
bucket_name/folder_name/ou usar a opção Procurar.Clique em Próxima.
Em Região de destino, especifique o caminho da pasta de destino do Cloud Storage para os arquivos traduzidos. É possível digitar o caminho no formato
bucket_name/folder_name/ou usar a opção Procurar.Se você estiver fazendo traduções que não precisem ter nomes de objetos padrão ou mapeamento de nomes de origem para destino especificado, pule para a etapa 11. Caso contrário, clique em Próxima.
Preencha as configurações opcionais necessárias.
Opcional. Em Banco de dados padrão, digite um nome de banco de dados padrão para usar com os arquivos de origem. O tradutor usa esse nome de banco de dados padrão para resolver os nomes totalmente qualificados dos objetos SQL em que o nome do banco de dados está ausente.
Opcional. Em Armazenamento em cache de metadados, clique na caixa de seleção Ativar o armazenamento em cache de metadados para armazenar informações dos arquivos ZIP de metadados gerados pela ferramenta
dwh-migration-dumperno back-end do BigQuery. Para jobs com arquivos de metadados grandes, esse processo reduz significativamente a latência de tradução para solicitações subsequentes. Os metadados armazenados em cache ficam ativos por até sete dias. Esse recurso está na visualização. Para pedir suporte ou enviar feedback sobre esse recurso, entre em contato com bq-edw-migration-support@google.com.Opcional. No Caminho de pesquisa de esquema, especifique o esquema a ser pesquisado quando o tradutor precisar resolver nomes totalmente qualificados de objetos SQL nos arquivos de origem em que o nome do esquema esteja ausente. Se os arquivos de origem usarem vários nomes de esquema diferentes, clique em Adicionar nome de esquema e adicione um valor para cada nome de esquema que possa ser referenciado.
O tradutor faz pesquisas nos arquivos de metadados fornecidos para validar tabelas com os nomes dos esquemas. Se não for possível determinar uma opção definida usando os metadados, o primeiro nome de esquema inserido será usado como padrão. Para mais informações sobre como o nome do esquema padrão é usado, consulte esquema padrão.
Opcional. Se quiser especificar regras de mapeamento de nome para renomear objetos SQL entre o sistema de origem e o BigQuery durante a conversão, forneça um arquivo JSON pelo par de mapeamento de nomes ou use o console doGoogle Cloud para especificar os valores a serem mapeados.
Para usar um arquivo JSON:
- Clique em Fazer upload do arquivo JSON para mapeamento de nome.
Acesse o local de um arquivo de mapeamento de nome no formato adequado, selecione-o e clique em Abrir.
O tamanho do arquivo precisa ser inferior a 5 MB.
Para usar o console do Google Cloud :
- Clique em Adicionar par de mapeamento de nomes.
- Adicione as partes apropriadas do nome do objeto de origem aos campos Database, Schema, Relationship e Attribute na coluna Source.
- Adicione as partes do nome do objeto de destino no BigQuery nos campos da coluna Target.
- Em Tipo, selecione o tipo de objeto que descreve o objeto que você está mapeando.
- Repita as etapas de 1 a 4 até especificar todos os pares de mapeamento de nome necessários. Só é possível especificar até 25 pares de mapeamento de nome ao usar o console Google Cloud .
Opcional. Para gerar sugestões de IA de tradução usando o modelo do Gemini, marque a caixa de seleção Sugestões de IA do Gemini. As sugestões são baseadas no arquivo YAML de configuração que termina em
.ai_config.yamle está localizado no diretório do Cloud Storage. Cada tipo de saída de sugestão é salvo em um subdiretório próprio na pasta de saída com o padrão de nomenclaturaREWRITETARGETSUGGESTION_TYPE_suggestion. Por exemplo, as sugestões para a personalização de SQL de destino aprimorada do Gemini são armazenadas emtarget_sql_query_customization_suggestion, e a explicação da tradução gerada pelo Gemini é armazenada emtranslation_explanation_suggestion. Para saber como escrever o arquivo YAML de configuração para sugestões de IA, consulte Criar um arquivo YAML de configuração baseado no Gemini.
Clique em Criar para iniciar o job de tradução.
Depois que o job de tradução for criado, será possível ver o status na lista de jobs de tradução.
Cliente de tradução em lote
No diretório de instalação do cliente de tradução em lote, use o editor de texto de sua preferência para abrir o arquivo
config.yamle modificar as seguintes configurações:project_number: digite o número do projeto que você quer usar para o job de tradução em lote. É possível encontrá-lo no painel Informações do projeto na página de boas-vindas do console doGoogle Cloud do projeto.gcs_bucket: digite o nome do bucket do Cloud Storage que o cliente de tradução em lote usa para armazenar arquivos durante o processamento do job de tradução.input_directory: digite o caminho absoluto ou relativo para o diretório que contém os arquivos de origem e os de metadados.output_directory: digite o caminho absoluto ou relativo para o diretório de destino dos arquivos traduzidos.
Salve as alterações e feche o arquivo
config.yaml.Coloque os arquivos de origem e de metadados no diretório de entrada.
Execute o cliente de tradução em lote usando o seguinte comando:
bin/dwh-migration-clientDepois que o job de tradução for criado, será possível ver o status dele na lista de jobs de tradução no console do Google Cloud .
Opcional. Depois que o job de tradução for concluído, exclua os arquivos criados no bucket do Cloud Storage especificado para evitar custos de armazenamento.
Explorar o resultado da tradução
Depois de executar o job de tradução, é possível ver informações sobre ele no Google Cloud console. Se você usou o console Google Cloud para executar o job, poderá ver os resultados dele no bucket de destino do Cloud Storage especificado. Se você usou o cliente de tradução em lote para executar o job, será possível ver os resultados do job no diretório de saída especificado. O tradutor SQL em lote gera os seguintes arquivos para o destino especificado:
- Os arquivos traduzidos.
- O relatório de resumo da tradução no formato CSV.
- O mapeamento do nome de saída consumido no formato JSON.
- Os arquivos de sugestão de IA.
Saída doGoogle Cloud console
Para ver detalhes do job de tradução, siga estas etapas:
No console do Google Cloud , acesse a página BigQuery.
No menu de navegação, clique em Tradução de SQL.
Na lista de jobs de tradução, localize aquele para o qual você quer ver os detalhes de tradução. Em seguida, clique no nome do job de tradução. Você pode conferir uma visualização de Sankey que ilustra a qualidade geral do job, o número de linhas de código de entrada (excluindo linhas em branco e comentários) e uma lista de problemas que ocorreram durante o processo de tradução. Priorize as correções da esquerda para a direita. Problemas em um estágio inicial podem causar outros problemas em etapas subsequentes.
Mantenha o ponteiro sobre as barras de erro ou aviso e analise as sugestões para determinar as próximas etapas de depuração do job de tradução.
Selecione a guia Resumo do registro para ver um resumo dos problemas de tradução, incluindo as categorias de problemas, as ações sugeridas e a frequência com que cada problema ocorreu. Clique nas barras de visualização de Sankey para filtrar problemas. Você também pode selecionar uma categoria de problema para ver as mensagens de registro associadas a ela.
Selecione a guia Log Messages para ver mais detalhes sobre cada problema de tradução, incluindo a categoria dele, a mensagem específica e um link para o arquivo em que o problema ocorreu. Clique nas barras de visualização de Sankey para filtrar problemas. Selecione um problema na guia Mensagem de registro para abrir a guia "Código", que exibe o arquivo de entrada e saída se aplicável.
Clique na guia Detalhes do job para ver os detalhes da configuração do job.
Relatório do resumo
O relatório de resumo é um arquivo CSV que contém uma tabela de todas as mensagens de aviso e erro encontradas durante o job de tradução.
Para ver o arquivo de resumo no Google Cloud console, siga estas etapas:
No console do Google Cloud , acesse a página BigQuery.
No menu de navegação, clique em Tradução de SQL.
Na lista de jobs de tradução, localize o job que você quer e clique no nome dele ou em Mais opções > Mostrar detalhes.
Na guia Detalhes do job, na seção Relatório de tradução, clique em translation_report.csv.
Na página Detalhes do objeto, clique no valor na linha URL autenticado para ver o arquivo no navegador.
A tabela a seguir descreve as colunas do arquivo de resumo:
| Coluna | Descrição |
|---|---|
| Carimbo de data/hora | O carimbo de data/hora em que o problema ocorreu. |
| FilePath | O caminho para o arquivo de origem ao qual o problema está associado. |
| FileName | O nome do arquivo de origem ao qual o problema está associado. |
| ScriptLine | O número da linha em que o problema ocorreu. |
| ScriptColumn | O número da coluna em que o problema ocorreu |
| TranspilerComponent | O componente interno do mecanismo de tradução em que ocorreu o aviso ou o erro. Essa coluna pode estar vazia. |
| Ambiente | Ambiente de dialeto de tradução associado ao aviso ou erro. Essa coluna pode estar vazia. |
| ObjectName | O objeto SQL no arquivo de origem associado ao aviso ou erro. Essa coluna pode estar vazia. |
| Gravidade | A gravidade do problema, seja de aviso ou erro. |
| Categoria | É a categoria do problema de tradução. |
| SourceType | A origem do problema. O valor nesta coluna pode ser SQL, indicando um problema nos arquivos SQL de entrada, ou METADATA, indicando um problema no pacote de metadados. |
| Mensagem | O aviso ou a mensagem de erro do problema de tradução. |
| ScriptContext | O snippet SQL no arquivo de origem associado ao problema. |
| Ação | A ação recomendada para resolver o problema. |
Guia "Código"
A guia de código permite revisar mais informações sobre os arquivos de entrada e saída de um job de tradução específico. Na guia de código, é possível examinar os arquivos usados em um job de tradução, analisar uma comparação lado a lado de um arquivo de entrada e a tradução dele em busca de imprecisões e ver mensagens e resumos de registro. para um arquivo específico em um job.
Para acessar a guia "Código", siga estas etapas:
No console do Google Cloud , acesse a página BigQuery.
No menu de navegação, clique em Tradução de SQL.
Na lista de jobs de tradução, localize o job que você quer e clique no nome dele ou em Mais opções > Mostrar detalhes.
Selecione a guia "Código". A guia "Código" consiste nos seguintes painéis:
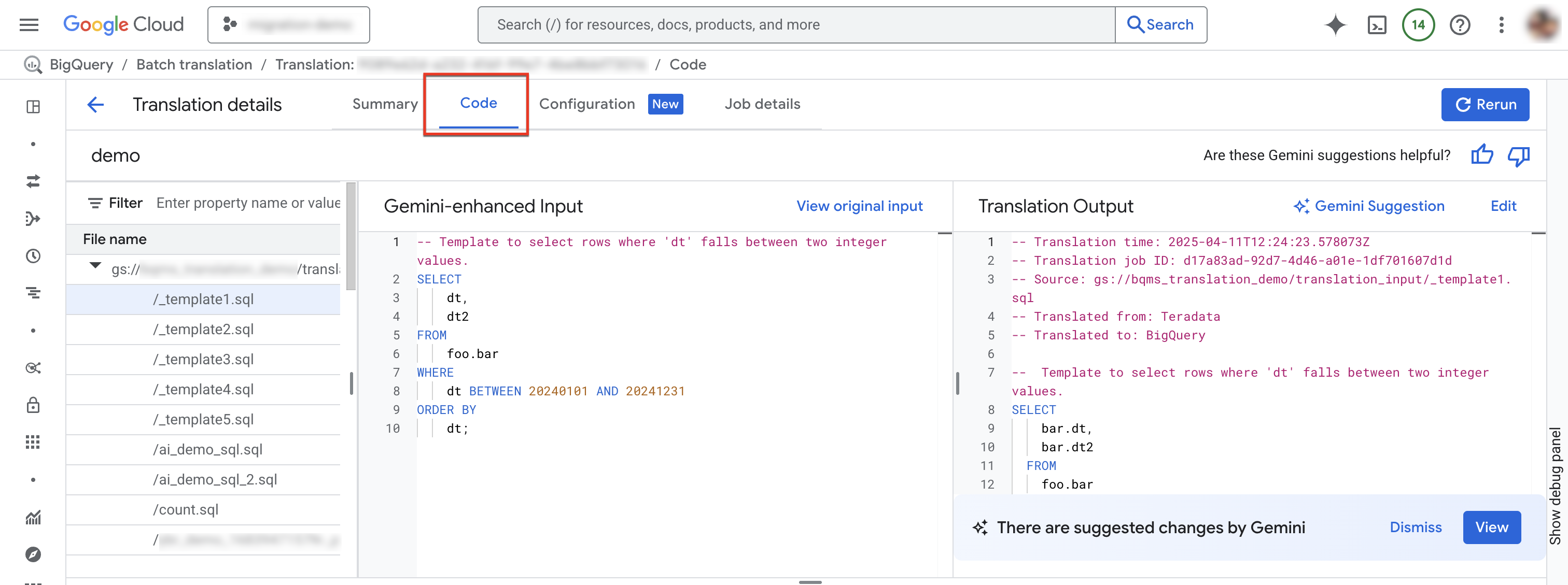
- Explorador de arquivos: contém todos os arquivos SQL usados para tradução. Clique em um arquivo para ver a entrada e a saída da tradução, além de problemas de tradução do texto.
- Entrada aprimorada com o Gemini: o SQL de entrada que foi traduzido pelo mecanismo de tradução. Se você especificou regras de personalização do Gemini para o SQL de origem na configuração do Gemini, o conversor transforma a entrada original primeiro e depois traduz a entrada aprimorada pelo Gemini. Para conferir a entrada original, clique em Abrir entrada original.
- Saída da tradução: o resultado da tradução. Se você especificou regras de personalização do Gemini para o SQL de destino na configuração do Gemini, a transformação será aplicada ao resultado traduzido como uma saída aprimorada pelo Gemini. Se uma saída aprimorada pelo Gemini estiver disponível, clique no botão Sugestão do Gemini para revisar a saída aprimorada.
Opcional: para ver um arquivo de entrada e um de saída no tradutor de SQL interativo do BigQuery, clique em Editar. É possível editar os arquivos e salvar o arquivo de saída de volta no Cloud Storage.
Guia "Configuração"
É possível adicionar, renomear, visualizar ou editar os arquivos YAML de configuração na guia Configuração.O Explorador de esquemas mostra a documentação dos tipos de configuração compatíveis para ajudar você a escrever os arquivos YAML de configuração. Depois de editar os arquivos YAML de configuração, é possível executar o job novamente para usar a nova configuração.
Para acessar a guia "Configuração", siga estas etapas:
No console do Google Cloud , acesse a página BigQuery.
No menu de navegação, clique em Tradução de SQL.
Na lista de jobs de tradução, localize o job que você quer e clique no nome dele ou em Mais opções > Mostrar detalhes.
Na janela Detalhes da tradução, clique na guia Configuração.
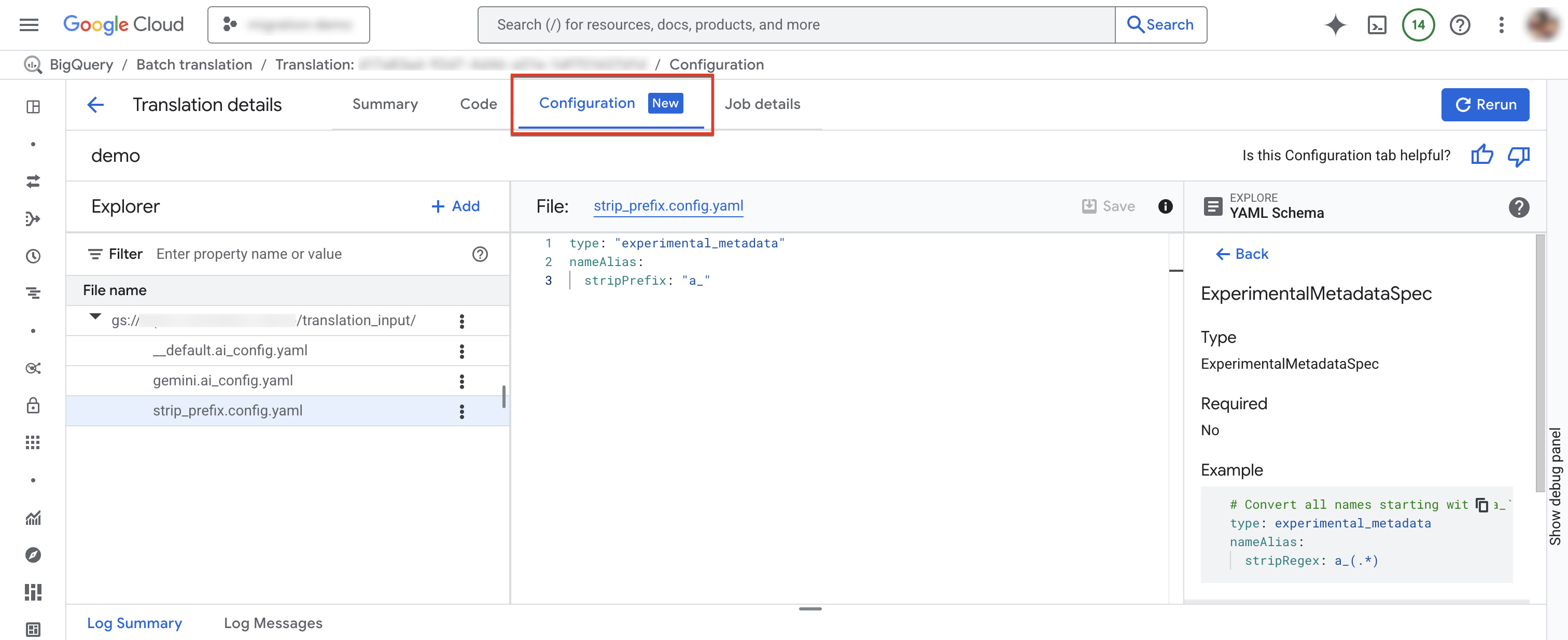
Para adicionar um novo arquivo de configuração:
- Clique em more_vert Mais opções > Criar arquivo YAML de configuração.
- Um painel vai aparecer para que você escolha o tipo, o local e o nome do novo arquivo YAML de configuração.
- Clique em Criar.
Para editar um arquivo de configuração atual:
- Clique no arquivo YAML de configuração.
- Edite o arquivo e clique em Salvar.
- Clique em Executar novamente para executar um novo job de tradução que usa os arquivos YAML de configuração editados.
Para renomear um arquivo de configuração, clique em more_vert Mais opções > Renomear.
Arquivo de mapeamento de nome de saída consumido
Esse arquivo JSON contém as regras de mapeamento do nome de saída que foram usadas pelo job de tradução. As regras nesse arquivo podem ser diferentes das regras de mapeamento de nome de saída especificadas para o job de tradução devido a conflitos nas regras de mapeamento de nome ou falta de regras de mapeamento de nome para objetos SQL que foram identificados durante a tradução. Revise esse arquivo para determinar se as regras de mapeamento de nome precisam de correção. Se isso acontecer, crie novas regras de mapeamento de nome de saída para resolver os problemas identificados e execute um novo job de tradução.
Arquivos traduzidos
Para cada arquivo de origem, um arquivo de saída correspondente é gerado no caminho de destino. O arquivo de saída contém a consulta traduzida.
Depurar consultas SQL traduzidas em lote com o tradutor de SQL interativo
Use o tradutor de SQL interativo do BigQuery para analisar ou depurar uma consulta SQL usando os mesmos metadados ou informações de mapeamento de objetos do banco de dados de origem. Depois de concluir um job de tradução em lote, o BigQuery gera um ID de configuração de tradução com informações sobre os metadados do job, o mapeamento de objetos ou o caminho de pesquisa do esquema, conforme aplicável para a consulta. Use o ID de configuração da tradução em lote com o tradutor de SQL interativo para executar consultas SQL com a configuração especificada.
Para iniciar uma tradução de SQL interativa usando um ID de configuração de tradução em lote, siga estas etapas:
No console do Google Cloud , acesse a página BigQuery.
No menu de navegação, clique em Tradução de SQL.
Na lista de jobs de tradução, localize o job que você quer e clique em Mais opções > Abrir tradução interativa.
O tradutor de SQL interativo do BigQuery agora é aberto com o ID de configuração da tradução em lote correspondente. Para consultar o ID de configuração da tradução interativa, clique em Mais > Configurações de tradução no tradutor de SQL interativo.
Para depurar um arquivo de tradução em lote no tradutor de SQL interativo, siga estas etapas:
No console do Google Cloud , acesse a página BigQuery.
No menu de navegação, clique em Tradução de SQL.
Na lista de jobs de tradução, localize o job que você quer e clique no nome dele ou em Mais opções > Mostrar detalhes.
Na janela Detalhes da tradução, clique na guia Código.
No "Explorador de arquivos", clique no nome do arquivo para abrir.
Ao lado do nome do arquivo de saída, clique em Editar para abrir os arquivos no conversor de SQL interativo (Prévia).
Os arquivos de entrada e saída são preenchidos no tradutor de SQL interativo, que agora usa o ID de configuração da tradução em lote correspondente.
Para salvar o arquivo de saída editado de volta no Cloud Storage, no tradutor interativo de SQL, clique em Salvar > Salvar no GCS.
Limitações
O tradutor não pode traduzir funções definidas pelo usuário (UDFs) de linguagens que não sejam SQL, porque não é possível analisá-las para determinar os tipos de dados de entrada e saída. Isso faz com que a conversão de instruções SQL que façam referência a essas UDFs seja imprecisa. Para garantir que as UDFs não SQL sejam referenciadas corretamente durante a conversão, use SQL válido para criar UDFs de marcador com as mesmas assinaturas.
Por exemplo, digamos que você tenha uma UDF escrita em C que calcula a soma de dois inteiros. Para garantir que as instruções SQL que se referem a essa UDF sejam traduzidas corretamente, crie uma UDF em SQL com marcador que compartilhe a mesma assinatura da UDF em C, conforme mostrado no exemplo a seguir:
CREATE FUNCTION Test.MySum (a INT, b INT)
RETURNS INT
LANGUAGE SQL
RETURN a + b;
Salve essa UDF de marcador em um arquivo de texto e inclua-o como um dos arquivos de origem do job de tradução. Isso permite que o tradutor aprenda a definição de UDF e identifique os tipos de dados de entrada e saída esperados.
Cotas e limites
- Aplicam-se as cotas da API BigQuery Migration.
- Cada projeto pode ter no máximo 10 tarefas de tradução ativas.
- Não há um limite rígido para o número total de arquivos de origem e de metadados, mas recomendamos manter o número de arquivos abaixo de 1.000 para melhor desempenho.
Resolver erros de tradução
Problemas de tradução do RelationNotFound ou AttributeNotFound
A tradução funciona melhor com DDLs de metadados. Quando as definições de objetos SQL não são encontradas, o mecanismo de tradução gera problemas RelationNotFound ou AttributeNotFound. Recomendamos o uso do extrator de metadados para gerar pacotes de metadados e garantir que todas as definições de objetos estejam presentes. Adicionar metadados é a primeira etapa recomendada para resolver a maioria dos erros de tradução, já que geralmente pode corrigir muitos outros erros causados indiretamente pela falta de metadados.
Para mais informações, consulte Gerar metadados para tradução e avaliação.
Preços
Não há cobrança para usar o conversor de SQL em lote. No entanto, o armazenamento usado para armazenar arquivos de entrada e saída incorre em taxas normais. Para mais informações, consulte preços de armazenamento.
A seguir
Saiba mais sobre as seguintes etapas na migração do armazenamento de dados:
- Visão geral da migração
- Avaliação da migração
- Visão geral de esquema e transferência de dados
- Pipelines de dados
- Tradução de SQL interativo
- Segurança e governança de dados
- Ferramenta de validação de dados