使用批次 SQL 翻譯器遷移程式碼
本文說明如何使用 BigQuery 的批次 SQL 翻譯器,將以其他 SQL 方言編寫的指令碼翻譯成 GoogleSQL 查詢。本文適用於熟悉Google Cloud 控制台的使用者。
事前準備
提交翻譯工作前,請先完成下列步驟:
- 確認您具備所有必要權限。
- 啟用 BigQuery Migration API。
- 收集含有待翻譯 SQL 指令碼和查詢的來源檔案。
- (選用步驟) 建立中繼資料檔案,提升翻譯準確度。
- (選用步驟) 決定是否需要將來源檔案中的 SQL 物件名稱對應至 BigQuery 中的新名稱。如有需要,請決定要使用哪些名稱對應規則。
- 決定要使用哪種方法提交翻譯工作。
- 將來源檔案上傳至 Cloud Storage。
所需權限
如要在專案中啟用 BigQuery 遷移服務,您必須具備下列權限:
resourcemanager.projects.getserviceusage.services.enableserviceusage.services.get
如要存取及使用 BigQuery 遷移服務,您必須具備專案的下列權限:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.list或者,您也可以使用下列角色取得相同權限:
bigquerymigration.viewer- 唯讀存取權。bigquerymigration.editor- 讀取/寫入權限。
如要存取輸入和輸出檔案的 Cloud Storage bucket,請按照下列步驟操作:
- 來源 Cloud Storage 值區的
storage.objects.get。 - 來源 Cloud Storage 值區的
storage.objects.list。 storage.objects.create。
您可以透過下列角色取得上述所有必要的 Cloud Storage 權限:
roles/storage.objectAdminroles/storage.admin
啟用 BigQuery Migration API
如果您的 Google Cloud CLI 專案是在 2022 年 2 月 15 日前建立,請按照下列步驟啟用 BigQuery Migration API:
前往 Google Cloud 控制台的「BigQuery Migration API」頁面。
按一下「啟用」。
收集來源檔案
來源檔案必須是文字檔,其中包含來源方言的有效 SQL。 來源檔案也可以包含註解。請盡可能確保 SQL 有效,並使用可用的方法。
建立中繼資料檔案
為協助服務產生更準確的翻譯結果,建議您提供中繼資料檔案。不過,這並非強制要求。
您可以使用 dwh-migration-dumper 指令列擷取工具產生中繼資料資訊,也可以提供自己的中繼資料檔案。準備好中繼資料檔案後,即可將這些檔案與來源檔案一併放入翻譯來源資料夾。翻譯人員會自動偵測並運用這些檔案翻譯來源檔案,您不需要設定任何額外設定來啟用這項功能。
如要使用 dwh-migration-dumper 工具產生中繼資料資訊,請參閱「產生翻譯中繼資料」。
如要提供自己的中繼資料,請將來源系統中 SQL 物件的資料定義語言 (DDL) 陳述式收集到個別文字檔中。
決定如何提交翻譯工作
提交批次翻譯作業有三種方式:
批次翻譯用戶端:在設定檔中變更設定來設定工作,並使用指令列提交工作。這種方法不需要手動將來源檔案上傳至 Cloud Storage。在翻譯工作處理期間,用戶端仍會使用 Cloud Storage 儲存檔案。
舊版批次翻譯用戶端是開放原始碼的 Python 用戶端,可讓您翻譯本機上的來源檔案,並將翻譯後的檔案輸出至本機目錄。您可以在用戶端的設定檔中變更幾項設定,設定用戶端以供基本用途。您也可以選擇設定用戶端,處理更複雜的工作,例如巨集取代,以及翻譯輸入和輸出內容的前後處理。詳情請參閱批次翻譯用戶端readme。
Google Cloud 控制台:使用使用者介面設定及提交工作。這個方法需要將來源檔案上傳至 Cloud Storage。
建立設定 YAML 檔案
您可以視需要建立及使用設定 YAML 檔案,自訂批次翻譯作業。這些檔案可用於以各種方式轉換翻譯輸出內容。舉例來說,您可以建立設定 YAML 檔案,在翻譯期間變更 SQL 物件的大小寫。
如要使用 Google Cloud 控制台或 BigQuery Migration API 執行批次轉換工作,請將設定 YAML 檔案上傳至含有來源檔案的 Cloud Storage bucket。
如要使用批次翻譯用戶端,您可以將設定 YAML 檔案放在本機翻譯輸入資料夾中。
將輸入檔案上傳至 Cloud Storage
如要使用 Google Cloud 控制台或 BigQuery Migration API 執行翻譯工作,請務必將包含要翻譯的查詢和指令碼的來源檔案上傳至 Cloud Storage。您也可以將任何中繼資料檔案或設定 YAML 檔案上傳至含有來源檔案的相同 Cloud Storage 值區和目錄。如要進一步瞭解如何建立值區,以及將檔案上傳至 Cloud Storage,請參閱「建立值區」和「從檔案系統上傳物件」。
支援的 SQL 方言
批次 SQL 翻譯器是 BigQuery 遷移服務的一部分。批次 SQL 翻譯器可將下列 SQL 方言翻譯為 GoogleSQL:
- Amazon Redshift SQL
- Apache HiveQL 和 Beeline CLI
- IBM Netezza SQL 和 NZPLSQL
- Teradata 和 Teradata Vantage
- SQL
- Basic Teradata Query (BTEQ)
- Teradata Parallel Transport (TPT)
此外,預覽版也支援翻譯下列 SQL 方言:
- Apache Spark SQL
- Azure Synapse T-SQL
- Greenplum SQL
- IBM DB2 SQL
- MySQL SQL
- Oracle SQL、PL/SQL、Exadata
- PostgreSQL SQL
- Trino 或 PrestoSQL
- Snowflake SQL
- SQL Server T-SQL
- SQLite
- Vertica SQL
使用輔助 UDF 處理不支援的 SQL 函式
將來源方言的 SQL 轉換為 BigQuery 時,部分函式可能沒有直接對應的函式。為解決這個問題,BigQuery 遷移服務 (和更廣泛的 BigQuery 社群) 提供輔助使用者定義函式 (UDF),可複製這些不支援的來源方言函式行為。
這些 UDF 通常位於 bqutil 公開資料集中,因此翻譯後的查詢一開始可以採用 bqutil.<dataset>.<function>() 格式參照這些 UDF。例如:bqutil.fn.cw_count()。
正式環境的重要注意事項:
雖然 bqutil 可方便存取這些輔助 UDF,以進行初始翻譯和測試,但基於下列原因,不建議直接依賴 bqutil 處理實際工作負載:
- 版本控管:
bqutil專案會代管這些 UDF 的最新版本,因此定義可能會隨時間變更。如果 UDF 的邏輯更新,直接依賴bqutil可能會導致生產查詢發生非預期行為或重大變更。 - 依附元件隔離:將 UDF 部署至您自己的專案,可將實際工作環境與外部變更隔離。
- 自訂:您可能需要修改或最佳化這些 UDF,進一步配合特定業務邏輯或成效需求。只有在這些資源位於您的專案中時,才能執行這項操作。
- 安全性和控管:貴機構的安全政策可能會限制直接存取公開資料集 (例如
bqutil),以處理實際工作環境資料。將 UDF 複製到受控環境,符合這類政策規定。
將輔助 UDF 部署至專案:
如要穩定可靠地用於實際工作環境,請將這些輔助 UDF 部署到自己的專案和資料集。您可以完全掌控這些應用程式的版本、自訂項目和存取權。 如需部署這些 UDF 的詳細操作說明,請參閱 GitHub 上的 UDF 部署指南。本指南提供必要的指令碼和步驟,協助您將 UDF 複製到環境中。
位置
批次 SQL 翻譯器可在下列處理位置使用:
| 地區說明 | 區域名稱 | 詳細資料 | |
|---|---|---|---|
| 亞太地區 | |||
| 德里 | asia-south2 |
||
| 香港 | asia-east2 |
||
| 雅加達 | asia-southeast2 |
||
| 墨爾本 | australia-southeast2 |
||
| 孟買 | asia-south1 |
||
| 大阪 | asia-northeast2 |
||
| 首爾 | asia-northeast3 |
||
| 新加坡 | asia-southeast1 |
||
| 雪梨 | australia-southeast1 |
||
| 台灣 | asia-east1 |
||
| 東京 | asia-northeast1 |
||
| 歐洲 | |||
| 比利時 | europe-west1 |
|
|
| 柏林 | europe-west10 |
||
| 歐盟多區域 | eu |
||
| 芬蘭 | europe-north1 |
|
|
| 法蘭克福 | europe-west3 |
||
| 倫敦 | europe-west2 |
|
|
| 馬德里 | europe-southwest1 |
|
|
| 米蘭 | europe-west8 |
||
| 荷蘭 | europe-west4 |
|
|
| 巴黎 | europe-west9 |
|
|
| 斯德哥爾摩 | europe-north2 |
|
|
| 杜林 | europe-west12 |
||
| 華沙 | europe-central2 |
||
| 蘇黎世 | europe-west6 |
|
|
| 美洲 | |||
| 俄亥俄州哥倫布 | us-east5 |
||
| 達拉斯 | us-south1 |
|
|
| 愛荷華州 | us-central1 |
|
|
| 拉斯維加斯 | us-west4 |
||
| 洛杉磯 | us-west2 |
||
| 墨西哥 | northamerica-south1 |
||
| 北維吉尼亞州 | us-east4 |
||
| 奧勒岡州 | us-west1 |
|
|
| 魁北克 | northamerica-northeast1 |
|
|
| 聖保羅 | southamerica-east1 |
|
|
| 鹽湖城 | us-west3 |
||
| 聖地亞哥 | southamerica-west1 |
|
|
| 南卡羅來納州 | us-east1 |
||
| 多倫多 | northamerica-northeast2 |
|
|
| 美國多區域 | us |
||
| 非洲 | |||
| 約翰尼斯堡 | africa-south1 |
||
| MiddleEast | |||
| 達曼 | me-central2 |
||
| 杜哈 | me-central1 |
||
| 以色列 | me-west1 |
||
提交翻譯工作
請按照下列步驟開始翻譯工作、查看進度,以及查看結果。
主控台
這些步驟假設您已將來源檔案上傳至 Cloud Storage bucket。
前往 Google Cloud 控制台的「BigQuery」頁面。
在導覽選單中,按一下「工具和指南」。
在「Translate SQL」(翻譯 SQL) 面板中,依序點選「Translate」>「Batch translation」(批次翻譯)。
翻譯設定頁面隨即開啟。輸入下列詳細資訊:
- 在「Display name」(顯示名稱) 中,輸入翻譯工作的名稱。名稱可包含英文字母、數字或底線。
- 在「Processing location」(處理位置) 中,選取要執行翻譯工作的地點。舉例來說,如果您位於歐洲,且不希望資料跨越任何位置限制範圍,請選取「
eu」區域。如果選擇與來源檔案 bucket 相同的位置,翻譯工作成效最佳。 - 在「來源方言」中,選取要翻譯的 SQL 方言。
- 在「目標方言」中,選取「BigQuery」。
點選「下一步」。
在「來源位置」中,指定包含待翻譯檔案的 Cloud Storage 資料夾路徑。您可以輸入
bucket_name/folder_name/格式的路徑,或使用「瀏覽」選項。點選「下一步」。
在「目標位置」中,指定翻譯後檔案的目標 Cloud Storage 資料夾路徑。您可以輸入
bucket_name/folder_name/格式的路徑,或使用「瀏覽」選項。如果翻譯作業不需要指定預設物件名稱或來源到目標的名稱對應,請跳至步驟 11。否則請按一下「下一步」。
填寫所需選填設定。
(選用步驟) 在「Default database」(預設資料庫) 中,輸入要搭配來源檔案使用的預設資料庫名稱。如果缺少資料庫名稱,翻譯器會使用這個預設資料庫名稱來解析 SQL 物件的完整名稱。
(選用步驟) 在「結構定義搜尋路徑」中,指定翻譯器需要解析來源檔案中 SQL 物件的完整名稱時,要搜尋的結構定義 (如果缺少結構定義名稱)。如果來源檔案使用多個不同的結構定義名稱,請按一下「新增結構定義名稱」,然後為每個可能參照的結構定義名稱新增值。
翻譯人員會搜尋您提供的中繼資料檔案,並使用結構定義名稱驗證資料表。如果系統無法從中繼資料判斷明確的選項,就會使用您輸入的第一個結構定義名稱做為預設值。如要進一步瞭解預設結構定義名稱的使用方式,請參閱預設結構定義。
(選用步驟) 如要指定名稱對應規則,在翻譯期間重新命名來源系統和 BigQuery 之間的 SQL 物件,您可以提供含有名稱對應配對的 JSON 檔案,也可以使用Google Cloud 控制台指定要對應的值。
如要使用 JSON 檔案,請按照下列步驟操作:
- 按一下「上傳 JSON 檔案進行名稱對應」。
瀏覽至適當格式的名稱對應檔所在位置,選取該檔案,然後按一下「開啟」。
請注意,檔案大小不得超過 5 MB。
如要使用 Google Cloud 控制台:
- 按一下「新增名稱對應組」。
- 在「來源」欄位的「資料庫」、「結構定義」、「關係」和「屬性」欄位中,加入來源物件名稱的適當部分。
- 在「目標」欄位的欄位中,加入 BigQuery 中目標物件名稱的各個部分。
- 在「類型」中,選取描述要對應物件的物件類型。
- 重複步驟 1 到 4,直到指定所有需要的名稱對應配對為止。請注意,使用 Google Cloud 控制台時,最多只能指定 25 個名稱對應組合。
(選用步驟) 如要使用 Gemini 模型生成翻譯 AI 建議,請選取「Gemini AI 建議」核取方塊。建議內容是根據結尾為
.ai_config.yaml的設定 YAML 檔案生成,該檔案位於 Cloud Storage 目錄。系統會將每種建議輸出內容儲存在輸出資料夾內的專屬子目錄中,命名模式為REWRITETARGETSUGGESTION_TYPE_suggestion。舉例來說,Gemini 強化目標 SQL 自訂項目的建議會儲存在target_sql_query_customization_suggestion,而 Gemini 生成的翻譯說明則會儲存在translation_explanation_suggestion。如要瞭解如何編寫 AI 建議的設定 YAML 檔,請參閱「建立以 Gemini 為基礎的設定 YAML 檔」。
按一下「建立」即可開始翻譯工作。
翻譯工作建立完成後,您可以在翻譯工作清單中查看狀態。
批次翻譯用戶端
在批次翻譯用戶端安裝目錄中,使用您選擇的文字編輯器開啟
config.yaml檔案,並修改下列設定:project_number:輸入要用於批次翻譯工作的專案號碼。您可以在專案的Google Cloud 控制台歡迎頁面中,找到「專案資訊」窗格。gcs_bucket:輸入 Cloud Storage 值區的名稱,批次翻譯用戶端會在翻譯作業處理期間使用該值區儲存檔案。input_directory:輸入含有來源檔案和任何中繼資料檔案的目錄絕對或相對路徑。output_directory:輸入翻譯檔案的目標目錄絕對或相對路徑。
儲存變更並關閉
config.yaml檔案。將來源和中繼資料檔案放在輸入目錄中。
使用下列指令執行批次翻譯用戶端:
bin/dwh-migration-client翻譯工作建立完成後,您可以在 Google Cloud 控制台的翻譯工作清單中查看工作狀態。
(選用步驟) 翻譯工作完成後,請刪除工作在指定 Cloud Storage bucket 中建立的檔案,以免產生儲存空間費用。
探索翻譯輸出內容
翻譯工作完成後,您可以在 Google Cloud 控制台中查看工作資訊。如果您使用 Google Cloud 控制台執行工作,可以在您指定的目的地 Cloud Storage 值區中查看工作結果。如果您使用批次翻譯用戶端執行工作,可以在指定的輸出目錄中查看工作結果。批次 SQL 翻譯器會將下列檔案輸出至指定目的地:
- 翻譯後的檔案。
- CSV 格式的翻譯摘要報告。
- JSON 格式的已用輸出名稱對應。
- AI 建議的檔案。
Google Cloud 控制台輸出內容
如要查看翻譯工作詳細資料,請按照下列步驟操作:
前往 Google Cloud 控制台的「BigQuery」頁面。
按一下導覽選單中的「SQL translation」(SQL 翻譯)。
在翻譯工作清單中,找到要查看翻譯詳細資料的工作。然後按一下翻譯工作名稱。 您可以查看桑基圖,瞭解作業的整體品質、輸入的程式碼行數 (不含空白行和註解),以及翻譯過程中發生的問題清單。您應優先修正左側的問題,早期階段的問題可能會導致後續階段出現其他問題。
將指標懸停在錯誤或警告長條上,然後查看建議,判斷偵錯翻譯工作的後續步驟。
選取「記錄摘要」分頁,即可查看翻譯問題摘要,包括問題類別、建議動作,以及每個問題的發生頻率。你可以點選桑基圖的長條,篩選問題。您也可以選取問題類別,查看與該類別相關聯的記錄訊息。
選取「記錄訊息」分頁,即可查看各項翻譯問題的詳細資訊,包括問題類別、具體問題訊息,以及發生問題的檔案連結。您可以點選桑基圖的長條,篩選問題。您可以在「Log Message」(記錄訊息) 分頁中選取問題,開啟「Code」(程式碼) 分頁,查看輸入和輸出檔案 (如有)。
按一下「工作詳細資料」分頁標籤,查看翻譯工作設定詳細資料。
摘要報告
摘要報告為 CSV 檔案,內含翻譯作業期間遇到的所有警告和錯誤訊息表格。
如要在 Google Cloud 控制台中查看摘要檔案,請按照下列步驟操作:
前往 Google Cloud 控制台的「BigQuery」頁面。
按一下導覽選單中的「SQL translation」(SQL 翻譯)。
在翻譯工作清單中找出感興趣的工作,然後按一下工作名稱,或依序點選「更多選項」>「顯示詳細資料」。
在「工作詳細資料」分頁的「翻譯報告」部分,按一下「translation_report.csv」。
在「物件詳細資料」頁面中,按一下「已通過驗證的網址」列中的值,即可在瀏覽器中查看檔案。
下表說明摘要檔案的資料欄:
| 欄 | 說明 |
|---|---|
| 時間戳記 | 問題發生時的時間戳記。 |
| FilePath | 與問題相關聯的來源檔案路徑。 |
| FileName | 與問題相關聯的來源檔案名稱。 |
| ScriptLine | 發生問題的行號。 |
| ScriptColumn | 發生問題的欄號。 |
| TranspilerComponent | 發生警告或錯誤的翻譯引擎內部元件。這個資料欄可能為空。 |
| 環境 | 與警告或錯誤相關的翻譯方言環境。這個資料欄可能為空。 |
| ObjectName | 來源檔案中與警告或錯誤相關聯的 SQL 物件。這個資料欄可能為空。 |
| 嚴重性 | 問題的嚴重程度,可能是警告或錯誤。 |
| 類別 | 翻譯問題類別。 |
| SourceType | 這個問題的來源。這個資料欄的值可以是 SQL (表示輸入 SQL 檔案有問題),也可以是 METADATA (表示中繼資料套件有問題)。 |
| 訊息 | 翻譯問題警告或錯誤訊息。 |
| ScriptContext | 與問題相關聯的來源檔案中的 SQL 程式碼片段。 |
| 動作 | 建議您採取哪些行動來解決問題。 |
「程式碼」分頁
您可以在「程式碼」分頁中,查看特定翻譯工作的輸入和輸出檔案詳細資訊。在「程式碼」分頁中,您可以檢查翻譯工作使用的檔案、並排比較輸入檔案和翻譯內容,找出任何不準確之處,以及查看工作中特定檔案的記錄摘要和訊息。
如要存取程式碼分頁,請按照下列步驟操作:
前往 Google Cloud 控制台的「BigQuery」頁面。
按一下導覽選單中的「SQL translation」(SQL 翻譯)。
在翻譯工作清單中找出感興趣的工作,然後按一下工作名稱,或依序點選「更多選項」>「顯示詳細資料」。
選取「程式碼」分頁標籤。「程式碼」分頁包含下列面板:
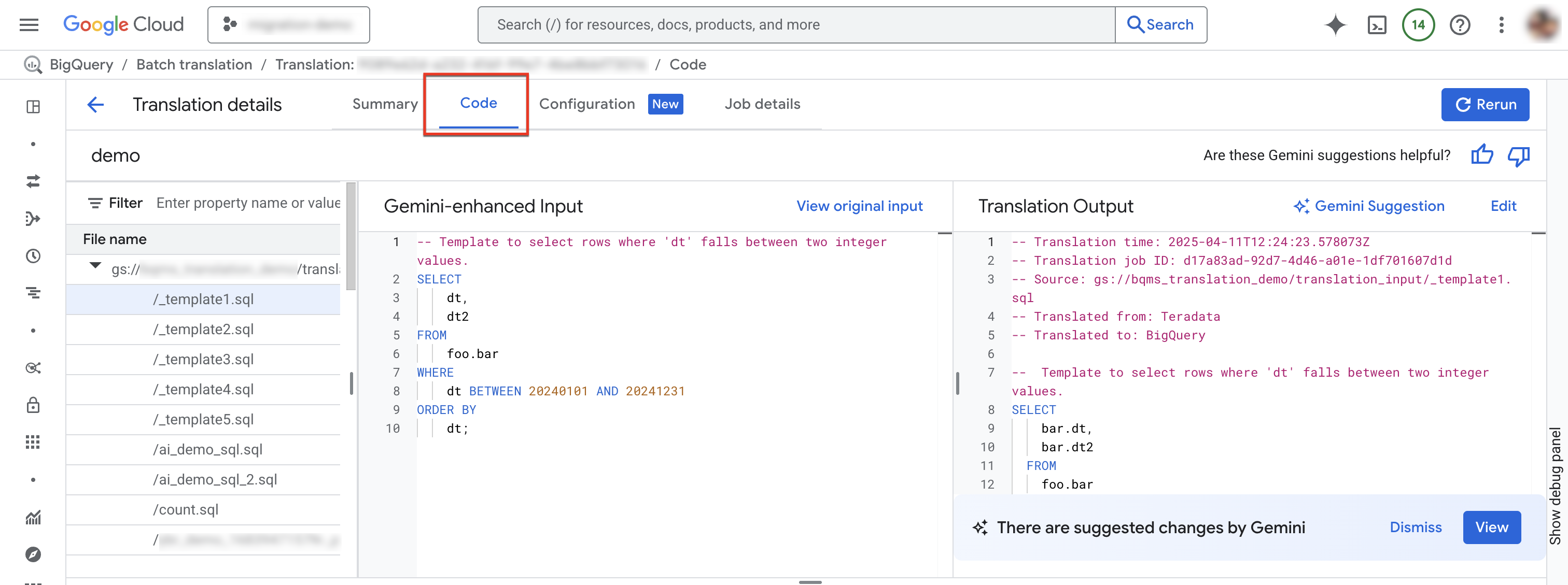
- 檔案總管:包含用於翻譯的所有 SQL 檔案。按一下檔案,即可查看翻譯輸入和輸出內容,以及翻譯時發生的任何問題。
- 以 Gemini 補強的輸入內容:翻譯引擎翻譯的輸入 SQL。如果您已在 Gemini 設定中指定來源 SQL 的 Gemini 自訂規則,翻譯工具會先轉換原始輸入內容,然後翻譯 Gemini 強化輸入內容。如要查看原始輸入內容,請按一下「查看原始輸入內容」。
- 翻譯輸出內容:翻譯結果。如果您已在 Gemini 設定中指定目標 SQL 的 Gemini 自訂規則,系統會將轉換套用至翻譯結果,做為 Gemini 強化輸出內容。如果系統提供 Gemini 強化版輸出內容,你可以點選「Gemini 建議」按鈕,查看這類內容。
選用:如要在 BigQuery 互動式 SQL 翻譯器中查看輸入和輸出檔案,請按一下「編輯」。 您可以編輯檔案,然後將輸出檔案儲存回 Cloud Storage。
「設定」分頁
您可以在「設定」分頁中新增、重新命名、查看或編輯設定 YAML 檔案。「結構定義探索器」會顯示支援的設定類型說明文件,協助您編寫設定 YAML 檔案。編輯設定 YAML 檔案後,您可以重新執行工作,使用新的設定。
如要存取設定分頁,請按照下列步驟操作:
前往 Google Cloud 控制台的「BigQuery」頁面。
按一下導覽選單中的「SQL translation」(SQL 翻譯)。
在翻譯工作清單中找出感興趣的工作,然後按一下工作名稱,或依序點選「更多選項」>「顯示詳細資料」。
在「翻譯詳細資料」視窗中,按一下「設定」分頁標籤。
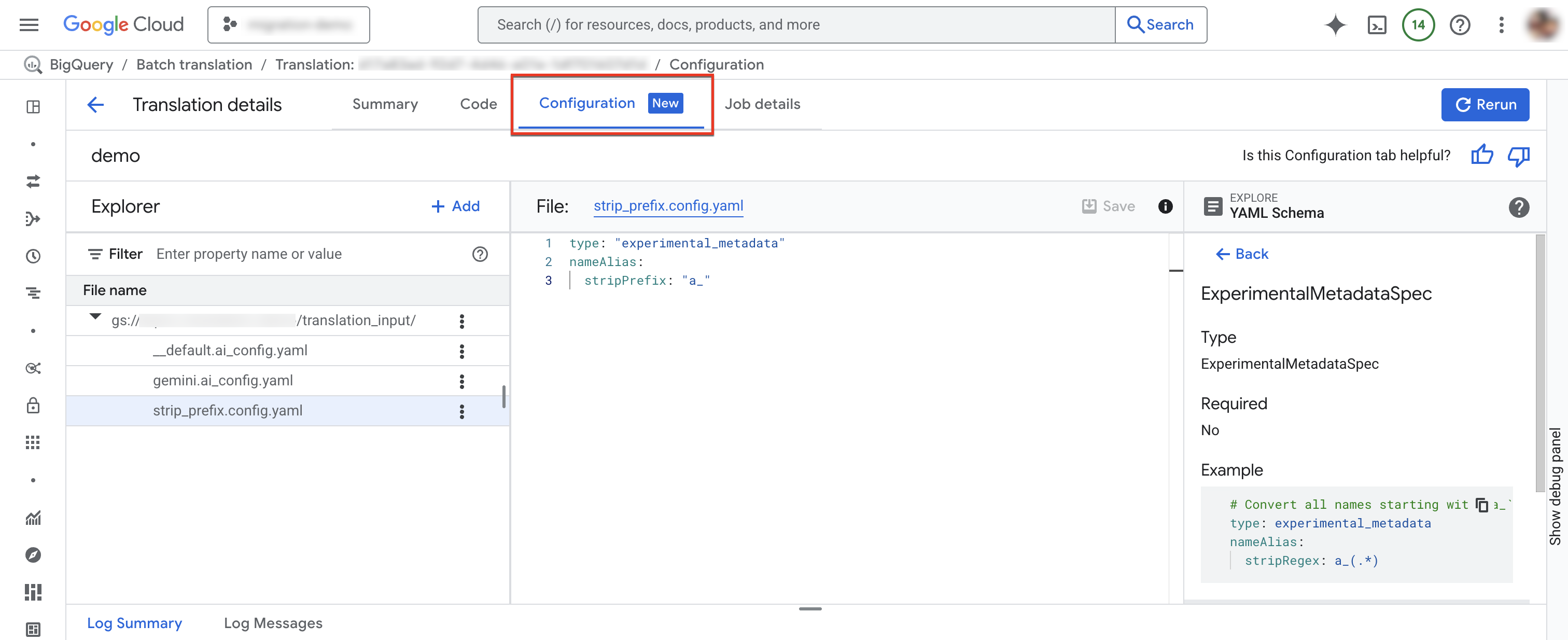
如要新增設定檔,請按照下列步驟操作:
- 依序點按「更多選項」圖示 more_vert>「建立設定 YAML 檔案」。
- 畫面上會顯示面板,供您選擇新設定 YAML 檔案的類型、位置和名稱。
- 點選「建立」。
如要編輯現有的設定檔:
- 按一下 YAML 設定檔。
- 編輯檔案,然後按一下「儲存」。
- 按一下「重新執行」,使用編輯過的設定 YAML 檔案執行新的翻譯工作。
如要重新命名現有的設定檔,請依序點選「more_vert」more_vert「更多選項」>「重新命名」。
使用的輸出名稱對應檔案
這個 JSON 檔案包含翻譯工作使用的輸出名稱對應規則。由於名稱對應規則發生衝突,或翻譯期間識別出的 SQL 物件缺少名稱對應規則,這個檔案中的規則可能與您為翻譯工作指定的輸出名稱對應規則不同。請檢查這個檔案,判斷名稱對應規則是否需要修正。如有,請建立新的輸出名稱對應規則,解決您發現的任何問題,然後執行新的翻譯工作。
翻譯後的檔案
系統會為每個來源檔案,在目的地路徑中產生對應的輸出檔案。輸出檔案包含翻譯後的查詢。
使用互動式 SQL 翻譯器偵錯批次翻譯的 SQL 查詢
您可以使用 BigQuery 互動式 SQL 翻譯器,透過與來源資料庫相同的中繼資料或物件對應資訊,檢查或偵錯 SQL 查詢。完成批次翻譯工作後,BigQuery 會產生翻譯設定 ID,其中包含工作的中繼資料、物件對應或結構定義搜尋路徑等資訊 (視查詢而定)。您可以使用互動式 SQL 翻譯器搭配批次翻譯設定 ID,執行指定設定的 SQL 查詢。
如要使用批次翻譯設定 ID 啟動互動式 SQL 翻譯,請按照下列步驟操作:
前往 Google Cloud 控制台的「BigQuery」頁面。
按一下導覽選單中的「SQL translation」(SQL 翻譯)。
在翻譯工作清單中,找出您感興趣的工作,然後依序點選 「更多選項」>「開啟互動式翻譯」。
BigQuery 互動式 SQL 翻譯器現在會開啟,並顯示對應的批次翻譯設定 ID。如要查看互動式翻譯的翻譯設定 ID,請在互動式 SQL 翻譯器中依序點選「更多」>「翻譯設定」。
如要在互動式 SQL 翻譯器中偵錯批次翻譯檔案,請按照下列步驟操作:
前往 Google Cloud 控制台的「BigQuery」頁面。
按一下導覽選單中的「SQL translation」(SQL 翻譯)。
在翻譯工作清單中找出感興趣的工作,然後按一下工作名稱,或依序點選「更多選項」>「顯示詳細資料」。
在「翻譯詳細資料」視窗中,按一下「程式碼」分頁標籤。
在檔案總管中,按一下檔案名稱即可開啟檔案。
按一下輸出檔名旁的「編輯」,即可在互動式 SQL 轉譯器中開啟檔案 (預覽)。
您會看到輸入和輸出檔案已填入互動式 SQL 翻譯器,該翻譯器現在使用對應的批次翻譯設定 ID。
如要將編輯後的輸出檔案儲存回 Cloud Storage,請在互動式 SQL 轉譯器中依序點選「儲存」> 儲存至 GCS。
限制
翻譯工具無法翻譯 SQL 以外語言的使用者定義函式 (UDF),因為無法剖析這些函式,判斷輸入和輸出資料類型。這會導致參照這些 UDF 的 SQL 陳述式翻譯不準確。為確保在轉換期間正確參照非 SQL UDF,請使用有效的 SQL 建立具有相同簽章的預留位置 UDF。
舉例來說,假設您有一個以 C 語言編寫的 UDF,用於計算兩個整數的總和。為確保參照這個 UDF 的 SQL 陳述式能正確轉換,請建立與 C UDF 具有相同簽章的預留位置 SQL UDF,如下列範例所示:
CREATE FUNCTION Test.MySum (a INT, b INT)
RETURNS INT
LANGUAGE SQL
RETURN a + b;
將這個預留位置 UDF 儲存為文字檔,並將該檔案做為翻譯工作的來源檔案之一。這有助於翻譯人員瞭解 UDF 定義,並識別預期的輸入和輸出資料類型。
配額與限制
- 適用 BigQuery Migration API 配額。
- 每個專案最多只能有 10 項有效翻譯工作。
- 雖然來源和中繼資料檔案總數沒有硬性限制,但建議檔案數不要超過 1000 個,以提升效能。
排解翻譯錯誤
RelationNotFound 或 AttributeNotFound 翻譯問題
翻譯服務最適合搭配中繼資料 DDL 使用。如果找不到 SQL 物件定義,轉譯引擎會引發 RelationNotFound 或 AttributeNotFound 問題。建議使用中繼資料擷取工具產生中繼資料套件,確保所有物件定義都存在。建議先新增中繼資料,因為這通常是解決大多數翻譯錯誤的第一步,而且往往能修正許多其他間接因缺少中繼資料而造成的錯誤。
詳情請參閱「產生翻譯和評估用的中繼資料」。
定價
批次 SQL 翻譯器為免費工具,使用者無須付費。不過,儲存輸入和輸出檔案所用的儲存空間仍須支付一般費用。詳情請參閱「儲存空間價格」。
後續步驟
進一步瞭解資料倉儲遷移作業的下列步驟: