使用批量 SQL 转换器迁移代码
本文档介绍了如何在 BigQuery 中使用批量 SQL 转换器将用其他 SQL 方言编写的脚本转换为 GoogleSQL 查询。本文档适用于熟悉 Google Cloud 控制台的用户。
准备工作
在提交转换作业之前,请完成以下步骤:
- 确保您拥有所需的所有权限。
- 启用 BigQuery Migration API。
- 收集包含待转换的 SQL 脚本和查询的源文件。
- 可选。创建元数据文件以提高转换的准确性。
- 可选。确定是否需要将源文件中的 SQL 对象名称映射到 BigQuery 中的新名称。确定必要的名称映射规则。
- 确定用于提交转换作业的方法。
- 将源文件上传到 Cloud Storage。
所需权限
您必须拥有项目的以下权限才能启用 BigQuery Migration Service:
resourcemanager.projects.getserviceusage.services.enableserviceusage.services.get
您需要拥有项目的以下权限才能访问和使用 BigQuery Migration Service:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.list或者,您可以使用以下角色获取相同的权限:
bigquerymigration.viewer- 只读权限。bigquerymigration.editor- 读写权限。
要访问 Cloud Storage 存储桶的输入和输出文件,您需要拥有以下权限:
- 针对源 Cloud Storage 存储桶的
storage.objects.get权限。 - 针对源 Cloud Storage 存储桶的
storage.objects.list权限。 - 针对目标 Cloud Storage 存储桶的
storage.objects.create权限。
您可以从以下角色获得上述所有必要的 Cloud Storage 权限:
roles/storage.objectAdminroles/storage.admin
启用 BigQuery Migration API
如果您的 Google Cloud CLI 项目是在 2022 年 2 月 15 日之前创建的,请按如下方式启用 BigQuery Migration API:
在 Google Cloud 控制台中,前往 BigQuery Migration API 页面。
点击启用。
收集源文件
源文件必须是包含源方言有效 SQL 的文本文件。源文件也可以包含注释。尽量使用您可以使用的任何方法确保 SQL 有效。
创建元数据文件
为帮助该服务生成更准确的转换结果,我们建议您提供元数据文件。不过,这并非强制性要求。
您可以使用 dwh-migration-dumper 命令行提取工具生成元数据信息,也可以提供自己的元数据文件。元数据文件准备就绪后,您可以将其与源文件一起添加到转换来源文件夹中。转换程序会自动检测这些文件并利用它们来转换源文件,您无需配置任何额外设置即可实现该转换。
如需使用 dwh-migration-dumper 工具生成元数据信息,请参阅生成转换元数据。
如需提供您自己的元数据,请将源系统中 SQL 对象的数据定义语言 (DDL) 语句收集到单独的文本文件中。
确定如何提交转换作业
您可以通过以下三种方式提交批量转换作业:
批量转换客户端:通过更改配置文件中的设置来配置作业,并使用命令行提交作业。此方法不要求您将源文件手动上传到 Cloud Storage。客户端在转换作业处理期间仍使用 Cloud Storage 存储文件。
旧版批量转换客户端是一个开源 Python 客户端,可让您转换本地机器上的源文件,并将转换后的文件输出到本地目录。您可以通过更改客户端配置文件中的一些设置来配置客户端的基本用法。如果您愿意,还可以配置客户端来处理更复杂的任务,例如宏替换以及转换输入和输出的预处理和后处理。如需了解详情,请参阅批量转换客户端的readme。
Google Cloud 控制台:使用界面配置和提交作业。此方法要求您将源文件上传到 Cloud Storage。
创建配置 YAML 文件
您可以酌情创建和使用配置 YAML 文件,以自定义批量转换。这些文件可用于通过各种方式对转换输出进行转换。例如,您可以创建配置 YAML 文件,以在转换期间更改 SQL 对象的大小写。
如果要使用 Google Cloud 控制台或 BigQuery Migration API 执行批量转换作业,您可以将配置 YAML 文件上传到包含源文件的 Cloud Storage 存储桶。
如果您要使用批量转换客户端,则可以将配置 YAML 文件放在本地转换输入文件夹中。
将输入文件上传到 Cloud Storage
如果您要使用 Google Cloud 控制台或 BigQuery Migration API 执行转换作业,则必须将包含待转换查询和脚本的源文件上传到 Cloud Storage。您还可以将任何元数据文件或配置 YAML 文件上传到包含源文件的同一 Cloud Storage 存储桶和目录。如需详细了解如何创建存储桶并将文件上传到 Cloud Storage,请参阅创建存储桶,以及从文件系统上传对象。
支持的 SQL 语言
批量 SQL 转换器是 BigQuery Migration Service 的一部分。批量 SQL 转换器可以将以下 SQL 方言转换为 GoogleSQL:
- Amazon Redshift SQL
- Apache HiveQL 和 Beeline CLI
- IBM Netezza SQL 和 NZPLSQL
- Teradata 和 Teradata Vantage
- SQL
- Basic Teradata Query (BTEQ)
- Teradata 并行传输 (TPT)
此外,预览版还支持转换以下 SQL 方言:
- Apache Spark SQL
- Azure Synapse T-SQL
- Greenplum SQL
- IBM DB2 SQL
- MySQL SQL
- Oracle SQL、PL/SQL、Exadata
- PostgreSQL SQL
- Trino 或 PrestoSQL
- Snowflake SQL
- SQL Server T-SQL
- SQLite
- Vertica SQL
使用辅助 UDF 处理不受支持的 SQL 函数
将 SQL 从源方言转换为 BigQuery 时,某些函数可能没有直接对应的函数。为解决此问题,BigQuery Migration Service(以及更广泛的 BigQuery 社区)提供了辅助用户定义的函数 (UDF),用于复制这些不受支持的来源方言函数的行为。
这些 UDF 通常位于 bqutil 公共数据集中,因此转换后的查询最初可以使用 bqutil.<dataset>.<function>() 格式引用它们。例如 bqutil.fn.cw_count()。
生产环境的重要注意事项:
虽然 bqutil 可为初始转换和测试提供对这些辅助 UDF 的便捷访问,但出于以下几个原因,不建议直接依赖 bqutil 来处理生产工作负载:
- 版本控制:
bqutil项目托管这些 UDF 的最新版本,这意味着它们的定义可能会随时间而变化。直接依赖bqutil可能会在 UDF 的逻辑更新时,导致生产查询出现意外行为或破坏性更改。 - 依赖项隔离:将 UDF 部署到您自己的项目可将生产环境与外部更改隔离开来。
- 自定义:您可能需要修改或优化这些 UDF,以更好地满足您的特定业务逻辑或性能要求。只有当它们位于您自己的项目中时,才能实现此目的。
- 安全和治理:组织的安全政策可能会限制直接访问公共数据集(例如
bqutil)来进行生产数据处理。将 UDF 复制到受控环境符合此类政策。
将辅助 UDF 部署到您的项目:
为了在生产环境中可靠、稳定地使用,您应将这些辅助 UDF 部署到您自己的项目和数据集中。这样一来,您就可以完全控制其版本、自定义设置和访问权限。如需详细了解如何部署这些 UDF,请参阅 GitHub 上的 UDF 部署指南。本指南提供了将 UDF 复制到您的环境所需的脚本和步骤。
位置
批量 SQL 转换器可在以下处理位置使用:
| 区域说明 | 区域名称 | 详情 | |
|---|---|---|---|
| 亚太地区 | |||
| 德里 | asia-south2 |
||
| 香港 | asia-east2 |
||
| 雅加达 | asia-southeast2 |
||
| 墨尔本 | australia-southeast2 |
||
| 孟买 | asia-south1 |
||
| 大阪 | asia-northeast2 |
||
| 首尔 | asia-northeast3 |
||
| 新加坡 | asia-southeast1 |
||
| 悉尼 | australia-southeast1 |
||
| 台湾 | asia-east1 |
||
| 东京 | asia-northeast1 |
||
| 欧洲 | |||
| 比利时 | europe-west1 |
|
|
| 柏林 | europe-west10 |
||
| 欧盟多区域 | eu |
||
| 芬兰 | europe-north1 |
|
|
| 法兰克福 | europe-west3 |
||
| 伦敦 | europe-west2 |
|
|
| 马德里 | europe-southwest1 |
|
|
| 米兰 | europe-west8 |
||
| 荷兰 | europe-west4 |
|
|
| 巴黎 | europe-west9 |
|
|
| 斯德哥尔摩 | europe-north2 |
|
|
| 都灵 | europe-west12 |
||
| 华沙 | europe-central2 |
||
| 苏黎世 | europe-west6 |
|
|
| 美洲 | |||
| 俄亥俄州,哥伦布 | us-east5 |
||
| 达拉斯 | us-south1 |
|
|
| 艾奥瓦 | us-central1 |
|
|
| 拉斯维加斯 | us-west4 |
||
| 洛杉矶 | us-west2 |
||
| 墨西哥 | northamerica-south1 |
||
| 北弗吉尼亚 | us-east4 |
||
| 俄勒冈 | us-west1 |
|
|
| 魁北克 | northamerica-northeast1 |
|
|
| 圣保罗 | southamerica-east1 |
|
|
| 盐湖城 | us-west3 |
||
| 圣地亚哥 | southamerica-west1 |
|
|
| 南卡罗来纳 | us-east1 |
||
| 多伦多 | northamerica-northeast2 |
|
|
| 美国多区域 | us |
||
| 非洲 | |||
| 约翰内斯堡 | africa-south1 |
||
| MiddleEast | |||
| Dammam | me-central2 |
||
| 多哈 | me-central1 |
||
| 以色列 | me-west1 |
||
提交转换作业
请按照以下步骤启动转换作业、监控其进度并查看结果。
控制台
这些步骤假定您已将源文件上传到 Cloud Storage 存储桶中。
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击工具和指南。
在转换 SQL面板中,依次点击转换 > 批量转换。
系统会打开转换配置页面。输入以下详细信息:
- 在显示名称部分,输入转换作业的名称。名称可以包含字母、数字或下划线。
- 在处理位置部分,选择要运行转换作业的位置。例如,如果您在欧洲,并且不希望您的数据跨越任何位置边界,那么请选择
eu区域。当您选择与源文件存储桶相同的位置时,转换作业效果最佳。 - 在源方言部分,选择要转换的 SQL 方言。
- 在目标方言部分,选择 BigQuery。
点击下一步。
在源位置部分,指定包含待转换文件的 Cloud Storage 文件夹的路径。您可以按
bucket_name/folder_name/格式输入路径,也可以使用浏览选项。点击下一步。
在目标位置部分,指定用于存储转换后文件的目标 Cloud Storage 文件夹的路径。您可以按
bucket_name/folder_name/格式输入路径,也可以使用浏览选项。如果您执行的转换不需要指定默认对象名称或从来源到目标的名称映射,请跳到第 11 步。否则,请点击下一步。
填写所需的可选设置。
可选。在默认数据库部分,输入要用于源文件的默认数据库名称。转换程序会使用此默认数据库名称来解析缺少数据库名称的 SQL 对象的完全限定名称。
可选。在架构搜索路径部分,指定当转换程序需要解析源文件中缺少架构名称的 SQL 对象的完全限定名称时要搜索的架构。如果源文件使用多个不同的架构名称,请点击添加架构名称,以便为可能引用的每个架构名称添加一个值。
转换程序会搜索您提供的元数据文件,以通过架构名称对表进行验证。如果无法从元数据确定确切的架构,则您输入的第一个架构名称将用作默认值。如需详细了解如何使用默认架构名称,请参阅默认架构。
可选。如果要指定名称映射规则以在转换期间重命名源系统和 BigQuery 之间的 SQL 对象,您可以提供包含名称映射对的 JSON 文件,也可以使用Google Cloud 控制台指定要映射的值。
如需使用 JSON 文件,请执行以下操作:
- 点击上传用于名称映射的 JSON 文件。
浏览到采用适当格式的名称映射文件的位置,选择该文件,然后点击打开。
请注意,该文件必须小于 5 MB。
如需使用 Google Cloud 控制台,请执行以下操作:
- 点击添加名称映射对。
- 在来源列的数据库、架构、关系和特性字段中,添加源对象名称的相应部分。
- 在目标列的相应字段中,添加 BigQuery 中的目标对象名称的各个部分。
- 在类型部分,选择描述您要映射的对象的对象类型。
- 重复第 1 - 4 步,直到指定完所需的所有名称映射对。请注意,使用 Google Cloud 控制台时,最多只能指定 25 个名称映射对。
可选。如需使用 Gemini 模型生成转换 AI 建议,请选中 Gemini AI 建议复选框。建议基于位于 Cloud Storage 目录中且以
.ai_config.yaml结尾的配置 YAML 文件。每种类型的建议输出都保存在输出文件夹中自己的子目录中,命名格式为REWRITETARGETSUGGESTION_TYPE_suggestion。例如,由 Gemini 增强的目标 SQL 自定义建议存储在target_sql_query_customization_suggestion中,而 Gemini 生成的转换说明存储在translation_explanation_suggestion中。如需了解如何为 AI 建议编写配置 YAML 文件,请参阅创建基于 Gemini 的配置 YAML 文件。
点击创建以启动转换作业。
创建转换作业后,您可以在转换作业列表中查看其状态。
批量转换客户端
在批量转换客户端安装目录中,使用您选择的文本编辑器打开
config.yaml文件并修改以下设置:project_number:输入要用于批量转换作业的项目的编号。您可以在项目的Google Cloud 控制台欢迎页面的项目信息窗格中找到此编号。gcs_bucket:输入批量转换客户端在转换作业处理期间用来存储文件的 Cloud Storage 存储桶的名称。input_directory:输入包含源文件和任何元数据文件的目录的绝对或相对路径。output_directory:输入转换后文件的目标目录的绝对或相对路径。
保存更改并关闭
config.yaml文件。将源文件和元数据文件放在输入目录中。
使用以下命令运行批量转换客户端:
bin/dwh-migration-client创建转换作业后,您可以在 Google Cloud 控制台的转换作业列表中查看其状态。
可选。转换作业完成后,便可以删除该作业在您指定的 Cloud Storage 存储桶中创建的文件,以避免产生存储费用。
浏览转换输出
运行转换作业后,您可以在 Google Cloud 控制台中查看有关该作业的信息。如果您使用 Google Cloud 控制台运行作业,则可以在您指定的目标 Cloud Storage 存储桶中查看作业结果。如果您使用批量转换客户端运行作业,则可以在您指定的输出目录中查看作业结果。批量 SQL 转换器会将以下文件输出到指定目标位置:
- 转换后的文件。
- CSV 格式的转换摘要报告。
- 所使用的输出名称映射(采用 JSON 格式)。
- AI 建议文件。
Google Cloud 控制台输出
如需查看转换作业详情,请按照以下步骤操作:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击 SQL 转换。
在转换作业列表中,找到要查看其转换详细信息的作业。然后,点击相应转换作业名称。 您可以看到 Sankey 可视化图,其中显示了作业的整体质量、输入代码行数(不包括空白行和注释)以及转换过程中出现的问题列表。您应优先解决左侧的问题。早期阶段的问题可能会在后续阶段导致更多问题。
将光标悬停在错误或警告栏上,查看建议,以确定调试转换作业的后续步骤。
选择日志摘要标签页以查看转换问题摘要,包括问题类别、建议的操作以及每个问题的发生频率。您可以点击 Sankey 可视化图表的柱形图来过滤问题。您还可以选择问题类别,以查看与该问题类别关联的日志消息。
选择日志消息标签页以查看有关每个转换问题的更多详细信息,包括问题类别、特定问题消息以及指向出现问题的文件的链接。您可以点击 Sankey 可视化图表的柱形图来过滤问题。您可以在日志消息标签页中选择一个问题,以打开显示输入和输出文件(如果适用)的代码标签页。
点击作业详情标签页可查看转换作业配置详情。
摘要报告
摘要报告是一个 CSV 文件,其中包含一个表,显示了转换作业处理期间出现的所有警告和错误消息。
如需在 Google Cloud 控制台中查看摘要文件,请按以下步骤操作:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击 SQL 转换。
在转换作业列表中,找到相关作业,然后点击作业名称或点击更多选项 > 显示详细信息。
在作业详情标签页的转换报告部分中,点击 translation_report.csv。
在对象详情页面上,点击经过身份验证的网址行中的值以在浏览器中查看该文件。
下表介绍了摘要文件中的各列:
| 列 | 说明 |
|---|---|
| 时间戳 | 出现问题时的时间戳。 |
| FilePath | 与问题关联的源文件的路径。 |
| FileName | 与问题关联的源文件的名称。 |
| ScriptLine | 出现问题的行号。 |
| ScriptColumn | 出现问题的列号。 |
| TranspilerComponent | 发生警告或错误的转换引擎内部组件。此列可能为空。 |
| 环境 | 与警告或错误关联的转换方言环境。此列可能为空。 |
| ObjectName | 源文件中与警告或错误关联的 SQL 对象。此列可能为空。 |
| 严重级别 | 问题的严重程度,即警告或错误。 |
| Category | 转换问题的类别。 |
| SourceType | 此问题的来源。此列中的值可以是 SQL(表示输入 SQL 文件中的问题)或 METADATA(表示元数据包中的问题)。 |
| Message | 转换问题的警告或错误消息。 |
| ScriptContext | 源文件中与问题关联的 SQL 代码段。 |
| Action | 我们建议您采取的解决该问题的操作。 |
代码标签页
借助代码标签页,您可以查看有关特定转换作业的输入文件和输出文件的详细信息。在代码标签页中,您可以检查转换作业中使用的文件、查看输入文件及其转换的对照比较以发现任何不准确的情况,并查看作业中特定文件的日志摘要和消息。
如需访问代码标签页,请按照以下步骤操作:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击 SQL 转换。
在转换作业列表中,找到相关作业,然后点击作业名称或点击更多选项 > 显示详细信息。
选择“代码”标签页。 “代码”标签页包含以下面板:
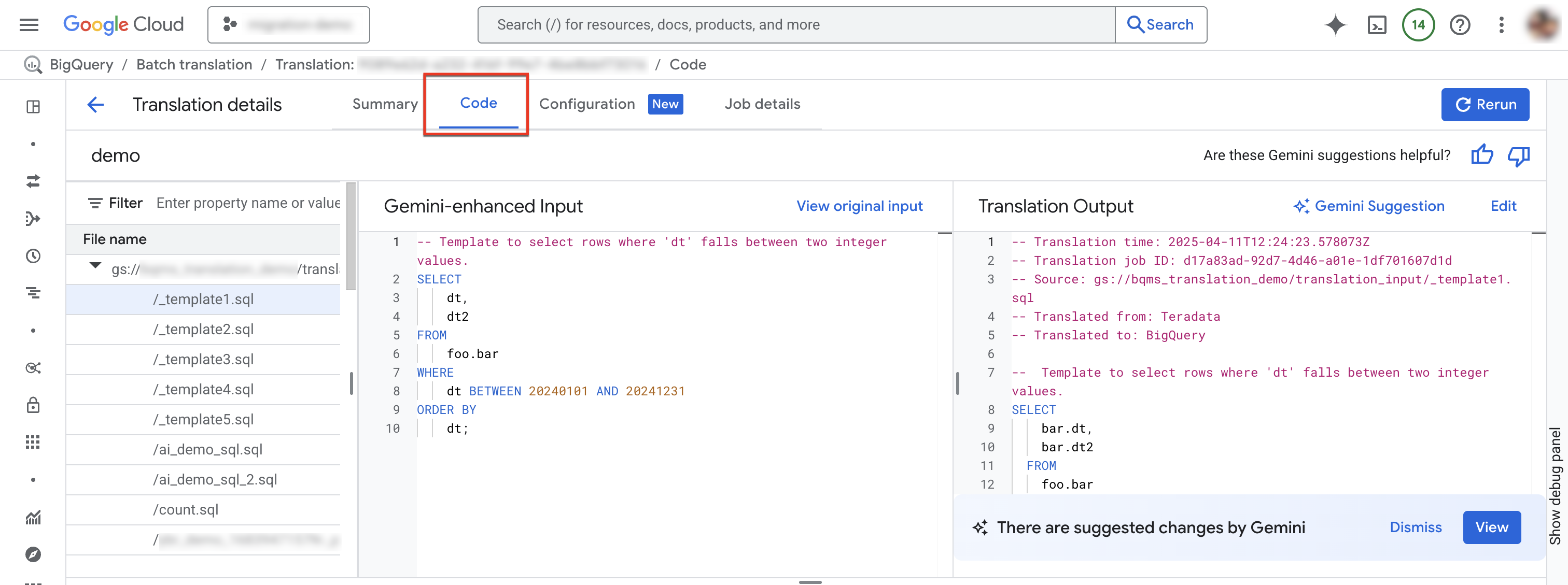
- 文件资源管理器:包含用于转换的所有 SQL 文件。点击文件即可查看其转换输入和输出,以及转换中存在的任何转换问题。
- Gemini 增强型输入:由转换引擎转换的输入 SQL。如果您已在 Gemini 配置中为源 SQL 指定了 Gemini 自定义规则,则转换器会先转换原始输入,然后转换 Gemini 增强型输入。如需查看原始输入,请点击查看原始输入。
- 转换输出:转换结果。如果您已在 Gemini 配置中为目标 SQL 指定了 Gemini 自定义规则,则转换会作为 Gemini 增强型输出应用于转换结果。如果有由 Gemini 增强的输出,您可以点击 Gemini 建议按钮查看由 Gemini 增强的输出。
可选:如需在 BigQuery 交互式 SQL 转换器中查看输入文件及其输出文件,请点击修改。您可以修改文件,并将输出文件保存回 Cloud Storage。
“配置”标签页
您可以在配置标签页中添加、重命名、查看或修改配置 YAML 文件。Schema Explorer 会显示受支持的配置类型的文档,以帮助您编写配置 YAML 文件。修改配置 YAML 文件后,您可以重新运行作业以使用新配置。
如需访问配置标签页,请按照以下步骤操作:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击 SQL 转换。
在转换作业列表中,找到相关作业,然后点击作业名称或点击更多选项 > 显示详细信息。
在转换详情窗口中,点击配置标签页。
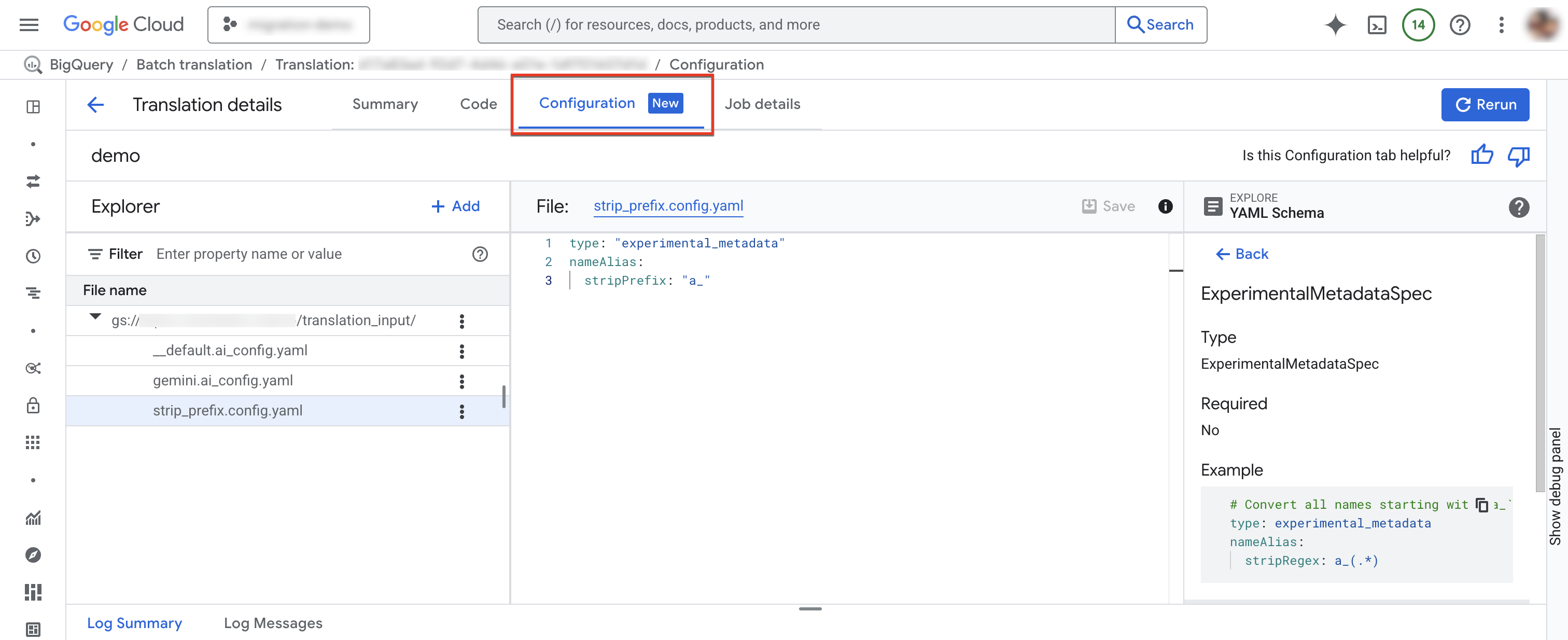
如需添加新的配置文件,请执行以下操作:
- 依次点击 more_vert 更多选项 > 创建配置 YAML 文件。
- 系统会显示一个面板,您可以在其中选择新配置 YAML 文件的类型、位置和名称。
- 点击创建。
如需修改现有配置文件,请执行以下操作:
- 点击配置 YAML 文件。
- 修改文件,然后点击保存。
- 点击重新运行,以运行使用修改后的配置 YAML 文件的新转换作业。
您可以通过点击 more_vert 更多选项 > 重命名来重命名现有配置文件。
所使用的输出名称映射文件
此 JSON 文件包含转换作业所使用的输出名称映射规则。由于名称映射规则冲突,或者缺少在转换期间识别的 SQL 对象的名称映射规则,此文件中的规则可能与您为转换作业指定的输出名称映射规则不同。查看此文件以确定名称映射规则是否需要更正。如果需要这样做,请创建新的输出名称映射规则来解决您发现的任何问题,并运行新的转换作业。
转换后的文件
对于每个源文件,系统都会在目标路径中生成一个相应的输出文件。输出文件包含转换后的查询。
使用交互式 SQL 转换器调试批量转换的 SQL 查询
借助 BigQuery 交互式 SQL 转换器,您可以使用与源数据库相同的元数据或对象映射信息来查看或调试 SQL 查询。完成批量转换作业后,BigQuery 会生成转换配置 ID,其中包含有关适用于查询的作业元数据、对象映射或架构搜索路径的信息。您可以将批量转换配置 ID 与交互式 SQL 转换器搭配使用,以通过指定的配置运行 SQL 查询。
如需使用批量转换配置 ID 启动交互式 SQL 转换,请按照以下步骤操作:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击 SQL 转换。
在转换作业列表中,找到相关作业,然后点击 更多选项 > 打开交互式转换。
BigQuery 交互式 SQL 转换器现在会使用相应的批量转换配置 ID 打开。如需查看交互式转换的配置 ID,请点击交互式SQL转换器中的更多 > 转换设置。
如需在交互式 SQL 转换器中调试批量转换文件,请按以下步骤操作:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击 SQL 转换。
在转换作业列表中,找到相关作业,然后点击作业名称或点击更多选项 > 显示详细信息。
在转换详情窗口中,点击代码标签页。
在文件浏览器中,点击文件名以打开文件。
在输出文件名旁边,点击修改以在交互式 SQL 转换器中打开文件 (预览)。
您会看到,交互式 SQL 转换器中填充了输入和输出文件,并且现在使用相应的批量转换配置 ID。
如需将修改后的输出文件保存回 Cloud Storage,请在交互式 SQL 转换器中依次点击保存 > 保存到 GCS。
限制
转换器无法转换 SQL 以外的语言的用户定义函数 (UDF),因为转换器无法解析这些语言的此类函数,从而无法确定其输入和输出数据类型。这会导致引用这些 UDF 的 SQL 语句的转换不准确。为了确保在转换期间正确引用非 SQL 语言的 UDF,请使用有效的 SQL 来创建具有相同签名的占位符 UDF。
例如,假设您有一个使用 C 语言编写的 UDF,用来计算两个整数的总和。为了确保引用此 UDF 的 SQL 语句能够正确转换,请创建一个与该 C 语言版 UDF 共用签名的占位符 SQL UDF,如以下示例所示:
CREATE FUNCTION Test.MySum (a INT, b INT)
RETURNS INT
LANGUAGE SQL
RETURN a + b;
将此占位符 UDF 保存在一个文本文件中,并将该文件添加为转换作业的一个源文件。如此,转换器就能了解 UDF 定义并确定预期的输入和输出数据类型。
配额和限制
- BigQuery Migration API 配额适用。
- 每个项目最多可以有 10 个活跃的转换任务。
- 虽然源文件和元数据文件的总数没有硬性限制,但我们建议让文件数量少于 1000 个,以获得更好的性能。
排查转换错误
RelationNotFound 或 AttributeNotFound 转换问题
Translation 最适合元数据 DDL。如果找不到 SQL 对象定义,则转换引擎会引发 RelationNotFound 或 AttributeNotFound 问题。我们建议您使用元数据提取器生成元数据包,以确保所有对象定义都存在。添加元数据是解决大多数转换错误的建议第一步,因为这通常可以解决许多因缺少元数据而间接引发的其他错误。
如需了解详情,请参阅生成元数据以进行转换和评估。
价格
使用交互式 SQL 转换器无需付费。但是,用于存储输入和输出文件的存储空间会产生正常费用。如需了解详情,请参阅存储价格。
后续步骤
详细了解迁移数据仓库的以下步骤: