In dieser Anleitung erfahren Sie, wie Sie ein multivariates Zeitreihenmodell verwenden, um den zukünftigen Wert für eine bestimmte Spalte basierend auf dem historischen Wert mehrerer Eingabe-Features vorherzusagen.
In dieser Anleitung wird eine einzelne Zeitachse prognostiziert. Prognostizierte Werte werden einmal für jeden Zeitpunkt in den Eingabedaten berechnet.
In dieser Anleitung werden Daten aus dem öffentlichen Dataset bigquery-public-data.epa_historical_air_quality verwendet. Dieses Dataset enthält Informationen zu täglichen Feinstaubwerten (PM2.5), Temperatur und Windgeschwindigkeit, die in mehreren US-Städten erfasst wurden.
Ziele
In dieser Anleitung werden Sie durch die folgenden Aufgaben geführt:
- Erstellen eines Zeitreihenmodells zur Vorhersage von PM2.5-Werten mit der Anweisung
CREATE MODEL. - Bewerten der Informationen zum autoregressiven integrierten gleitenden Durchschnitt (ARIMA) im Modell mit der
ML.ARIMA_EVALUATE-Funktion. - Die Modellkoeffizienten mit der Funktion
ML.ARIMA_COEFFICIENTSprüfen. - Die prognostizierten PM2.5-Werte aus dem Modell werden mit der
ML.FORECAST-Funktion abgerufen. - Bewerten der Modellgenauigkeit mit der Funktion
ML.EVALUATE. - Abrufen von Komponenten der Zeitreihe, z. B. Saisonalität, Trend und Feature-Attributionen, mithilfe der Funktion
ML.EXPLAIN_FORECAST. Sie können diese Zeitreihenkomponenten untersuchen, um die prognostizierten Werte zu erklären.
Kosten
In dieser Anleitung werden kostenpflichtige Komponenten von Google Cloudverwendet, darunter:
- BigQuery
- BigQuery ML
Weitere Informationen zu den Kosten von BigQuery finden Sie auf der Seite BigQuery-Preise.
Weitere Informationen zu den Kosten für BigQuery ML finden Sie unter BigQuery ML-Preise.
Hinweise
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery ist in neuen Projekten automatisch aktiviert.
So aktivieren Sie BigQuery in einem vorhandenen Projekt:
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Sie benötigen die IAM-Berechtigung
bigquery.datasets.create, um das Dataset zu erstellen.Zum Erstellen des Modells benötigen Sie die folgenden Berechtigungen:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Zum Ausführen von Inferenzen benötigen Sie die folgenden Berechtigungen:
bigquery.models.getDatabigquery.jobs.create
Erforderliche Berechtigungen
Weitere Informationen zu IAM-Rollen und Berechtigungen in BigQuery finden Sie unter Einführung in IAM.
Dataset erstellen
Erstellen Sie ein BigQuery-Dataset zum Speichern Ihres ML-Modells.
Konsole
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
bqml_tutorialein.Wählen Sie als Standorttyp die Option Mehrere Regionen und dann USA (mehrere Regionen in den USA) aus.
Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf Dataset erstellen.
bq
Wenn Sie ein neues Dataset erstellen möchten, verwenden Sie den Befehl bq mk mit dem Flag --location. Eine vollständige Liste der möglichen Parameter finden Sie in der bq mk --dataset-Befehlsreferenz.
Erstellen Sie ein Dataset mit dem Namen
bqml_tutorial, wobei der Datenspeicherort aufUSund die Beschreibung aufBigQuery ML tutorial datasetfestgelegt ist:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Anstelle des Flags
--datasetverwendet der Befehl die verkürzte Form-d. Wenn Sie-dund--datasetauslassen, wird standardmäßig ein Dataset erstellt.Prüfen Sie, ob das Dataset erstellt wurde:
bq ls
API
Rufen Sie die Methode datasets.insert mit einer definierten Dataset-Ressource auf.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Tabelle mit Eingabedaten erstellen
Erstellen Sie eine Datentabelle, die Sie zum Trainieren und Bewerten des Modells verwenden können. In dieser Tabelle werden Spalten aus mehreren Tabellen im Dataset bigquery-public-data.epa_historical_air_quality kombiniert, um tägliche Wetterdaten bereitzustellen. Außerdem erstellen Sie die folgenden Spalten, die als Eingabevariablen für das Modell verwendet werden:
date: das Datum der Beobachtungpm25: der durchschnittliche PM2.5-Wert je Tagwind_speed: durchschnittliche Windgeschwindigkeit je Tagtemperature: Temperatur: die Höchsttemperatur je Tag
In der folgenden GoogleSQL-Abfrage gibt die FROM bigquery-public-data.epa_historical_air_quality.*_daily_summary-Klausel an, dass Sie die *_daily_summary-Tabellen im epa_historical_air_quality-Dataset abfragen. Diese Tabellen sind partitionierte Tabellen.
So erstellen Sie die Eingabedatentabelle:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
CREATE TABLE `bqml_tutorial.seattle_air_quality_daily` AS WITH pm25_daily AS ( SELECT avg(arithmetic_mean) AS pm25, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.pm25_nonfrm_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Acceptable PM2.5 AQI & Speciation Mass' GROUP BY date_local ), wind_speed_daily AS ( SELECT avg(arithmetic_mean) AS wind_speed, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.wind_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Wind Speed - Resultant' GROUP BY date_local ), temperature_daily AS ( SELECT avg(first_max_value) AS temperature, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.temperature_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Outdoor Temperature' GROUP BY date_local ) SELECT pm25_daily.date AS date, pm25, wind_speed, temperature FROM pm25_daily JOIN wind_speed_daily USING (date) JOIN temperature_daily USING (date);
Eingabedaten visualisieren
Bevor Sie das Modell erstellen, können Sie Ihre Eingabezeitachsendaten optional visualisieren, um einen Eindruck von der Verteilung zu erhalten. Verwenden Sie dazu Looker Studio.
So visualisieren Sie die Zeitreihendaten:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`;
Klicken Sie nach Abschluss der Abfrage auf Daten auswerten > Mit Looker Studio auswerten. Looker Studio wird in einem neuen Tab geöffnet. Führen Sie die folgenden Schritte in dem neuen Tab aus.
Klicken Sie in Looker Studio auf Einfügen > Zeitreihendiagramm.
Wählen Sie im Bereich Diagramm den Tab Einrichtung aus.
Fügen Sie im Bereich Messwert die Felder pm25, temperature und wind_speed hinzu und entfernen Sie den Standardmesswert Anzahl der Datensätze. Das resultierende Diagramm sieht etwa so aus:
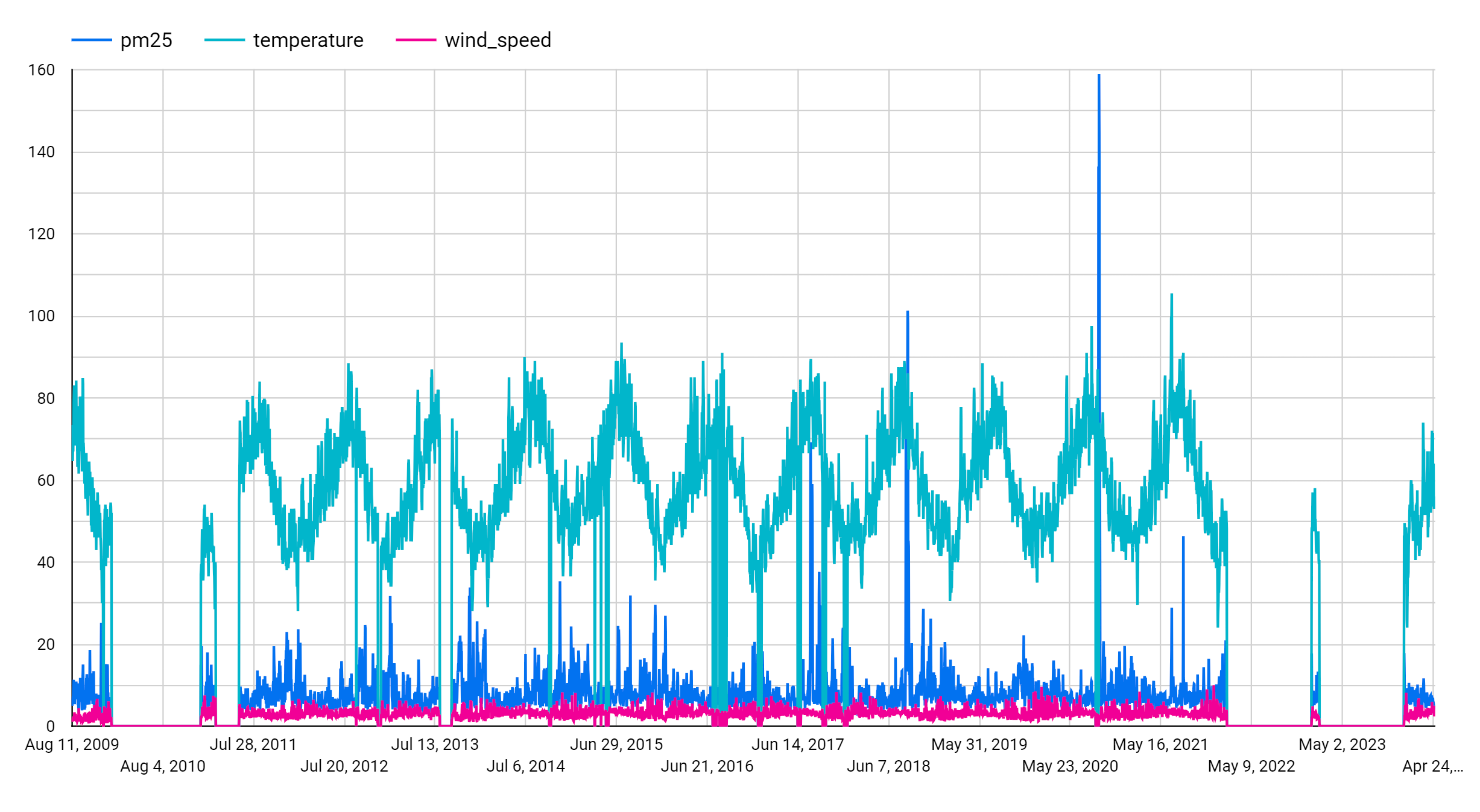
Dem Diagramm können Sie entnehmen, dass die Eingabezeitachse ein wöchentliches saisonales Muster aufweist.
Zeitachsenmodell erstellen
Erstellen Sie ein Zeitreihenmodell, um die Werte für Feinstaub (pm25) anhand der Werte der Spalten pm25, wind_speed und temperature als Eingabevariablen vorherzusagen. Trainieren Sie das Modell mit den Luftqualitätsdaten aus der Tabelle bqml_tutorial.seattle_air_quality_daily. Wählen Sie dazu die Daten aus, die zwischen dem 1. Januar 2012 und dem 31. Dezember 2020 erhoben wurden.
In der folgenden Abfrage gibt die OPTIONS(model_type='ARIMA_PLUS_XREG',
time_series_timestamp_col='date', ...)-Anweisung an, dass Sie ein ARIMA-Modell mit externen Regressoren erstellen. Die auto_arima-Option der CREATE MODEL-Anweisung hat standardmäßig den Wert TRUE. Der auto.ARIMA-Algorithmus stimmt die Hyperparameter im Modell also automatisch ab. Der Algorithmus passt Dutzende von Kandidatenmodellen an und wählt das beste Modell aus, also das Modell mit dem niedrigsten Akaike-Informationskriterium (AIC).
Die data_frequency-Option der CREATE MODEL-Anweisungen hat standardmäßig den Wert AUTO_FREQUENCY. Der Trainingsprozess leitet also automatisch die Datenhäufigkeit der Eingabezeitachse ab.
So erstellen Sie das Modell:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
CREATE OR REPLACE MODEL `bqml_tutorial.seattle_pm25_xreg_model` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS_XREG', time_series_timestamp_col = 'date', # Identifies the column that contains time points time_series_data_col = 'pm25') # Identifies the column to forecast AS SELECT date, # The column that contains time points pm25, # The column to forecast temperature, # Temperature input to use in forecasting wind_speed # Wind speed input to use in forecasting FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31');
Die Abfrage dauert etwa 20 Sekunden. Anschließend wird das Modell
seattle_pm25_xreg_modelim Bereich Explorer angezeigt. Da die Abfrage eineCREATE MODEL-Anweisung zum Erstellen eines Modells verwendet, werden keine Abfrageergebnisse ausgegeben.
Kandidatenmodelle bewerten
Bewerten Sie die Zeitreihenmodelle mit der Funktion ML.ARIMA_EVALUATE. Die ML.ARIMA_EVALUATE-Funktion zeigt die Bewertungsmesswerte aller Kandidatenmodelle an, die während der automatischen Hyperparameter-Abstimmung bewertet wurden.
So bewerten Sie das Modell:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.seattle_pm25_xreg_model`);
Die Antwort sollte in etwa so aussehen:

Die Ausgabespalten
non_seasonal_p,non_seasonal_d,non_seasonal_qundhas_driftdefinieren ein ARIMA-Modell in der Trainingspipeline. Die Ausgabespaltenlog_likelihood,AICundvariancesind für den ARIMA-Modellanpassungsprozess relevant.Der
auto.ARIMA-Algorithmus verwendet den KPSS-Test, um den besten Wert fürnon_seasonal_dzu ermitteln. In diesem Fall ist das1. Wennnon_seasonal_d1ist, trainiert derauto.ARIMA-Algorithmus 42 verschiedene ARIMA-Kandidatenmodelle parallel. In diesem Beispiel sind alle 42 Kandidatenmodelle gültig. Die Ausgabe enthält also 42 Zeilen, eine für jedes ARIMA-Kandidatenmodell. Wenn einige der Modelle ungültig sind, werden sie aus der Ausgabe ausgeschlossen. Diese Kandidatenmodelle werden in aufsteigender Reihenfolge nach AIC zurückgegeben. Das Modell in der ersten Zeile hat den niedrigsten AIC und gilt als bestes Modell. Das beste Modell wird als endgültiges Modell gespeichert und verwendet, wenn Sie Funktionen wieML.FORECASTfür das Modell aufrufen.Die Spalte
seasonal_periodsenthält Informationen zum saisonalen Muster, das in den Zeitachsendaten ermittelt wurde. Es hat nichts mit der ARIMA-Modellierung zu tun und hat daher in allen Ausgabezeilen denselben Wert. Es wird ein Wochenmuster gemeldet, das mit den Ergebnissen übereinstimmt, die Sie gesehen haben, wenn Sie die Eingabedaten visualisiert haben.Die Spalten
has_holiday_effect,has_spikes_and_dipsundhas_step_changesenthalten Informationen zu den Eingabezeitreihendaten und stehen nicht im Zusammenhang mit der ARIMA-Modellierung. Diese Spalten werden zurückgegeben, weil der Wert der Optiondecompose_time_seriesin der AnweisungCREATE MODELTRUEist. Diese Spalten haben auch in allen Ausgabezeilen dieselben Werte.In der Spalte
error_messagewerden alle Fehler angezeigt, die während derauto.ARIMA-Anpassung aufgetreten sind. Ein möglicher Grund für Fehler ist, dass die ausgewählten Spaltennon_seasonal_p,non_seasonal_d,non_seasonal_qundhas_driftdie Zeitachse nicht stabilisieren können. Legen Sie beim Erstellen des Modells die Optionshow_all_candidate_modelsaufTRUEfest, um die Fehlermeldung aller Kandidatenmodelle abzurufen.Weitere Informationen zu den Ausgabespalten finden Sie unter
ML.ARIMA_EVALUATE-Funktion.
Koeffizienten des Modells prüfen
Prüfen Sie die Koeffizienten des Zeitachsenmodells mit der Funktion ML.ARIMA_COEFFICIENTS.
So rufen Sie die Koeffizienten des Modells ab:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.seattle_pm25_xreg_model`);
Die Antwort sollte in etwa so aussehen:
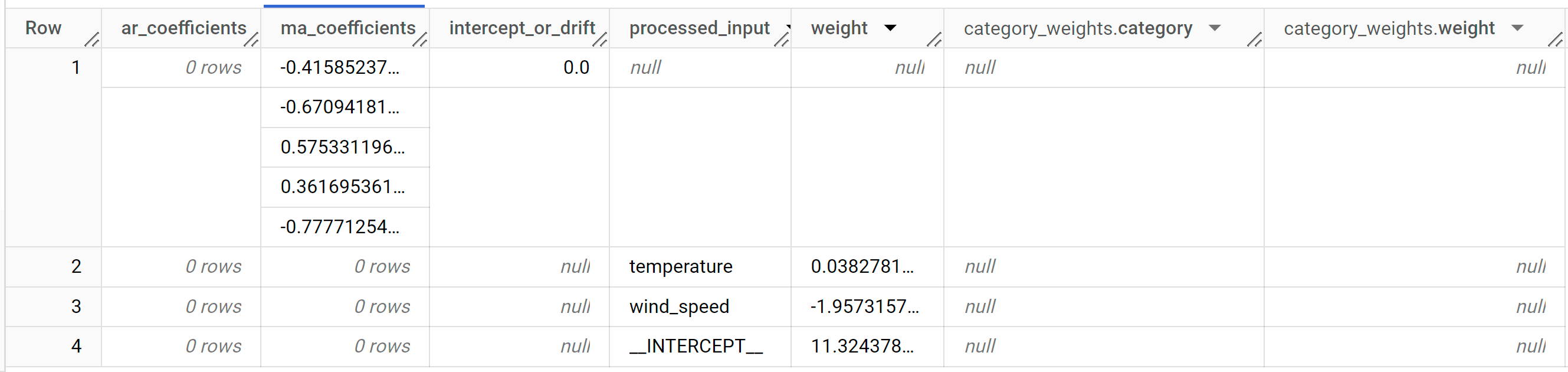
In der Ausgabespalte
ar_coefficientswerden die Modellkoeffizienten des autoregressiven (AR) Teils des ARIMA-Modells angezeigt. Entsprechend zeigt die Ausgabespaltema_coefficientsdie Modellkoeffizienten des gleitenden Durchschnitts (Moving Average, MA) des ARIMA-Modells an. Beide Spalten enthalten Array-Werte, deren Längenon_seasonal_pbzw.non_seasonal_qentspricht. In der Ausgabe der FunktionML.ARIMA_EVALUATEhaben Sie gesehen, dass das beste Modell einennon_seasonal_p-Wert von0und einennon_seasonal_q-Wert von5hat. Daher ist imML.ARIMA_COEFFICIENTS-Ergebnis derar_coefficients-Wert ein leeres Array und derma_coefficients-Wert ein Array mit fünf Elementen. Der Wert fürintercept_or_driftist der konstante Begriff im ARIMA-Modell.In den Ausgabespalten
processed_input,weightundcategory_weightswerden die Gewichte für jedes Feature und der Achsenabschnitt im linearen Regressionsmodell angezeigt. Wenn es sich um ein numerisches Feature handelt, wird die Gewichtung in der Spalteweightangezeigt. Wenn es sich bei dem Feature um ein kategorisches Feature handelt, ist der Wertcategory_weightsein Array von Strukturwerten, wobei jeder Strukturwert den Namen und die Gewichtung einer bestimmten Kategorie enthält.Weitere Informationen zu den Ausgabespalten finden Sie unter
ML.ARIMA_COEFFICIENTS-Funktion.
Modell zum Vorhersagen von Daten verwenden
Mit der Funktion ML.FORECAST können Sie zukünftige Zeitachsenwerte prognostizieren.
In der folgenden GoogleSQL-Abfrage gibt die STRUCT(30 AS horizon, 0.8 AS confidence_level)-Klausel an, dass die Abfrage 30 zukünftige Zeitpunkte prognostiziert und ein Vorhersageintervall mit einem Konfidenzniveau von 80 % generiert.
So prognostizieren Sie Daten mit dem Modell:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ));
Die Antwort sollte in etwa so aussehen:
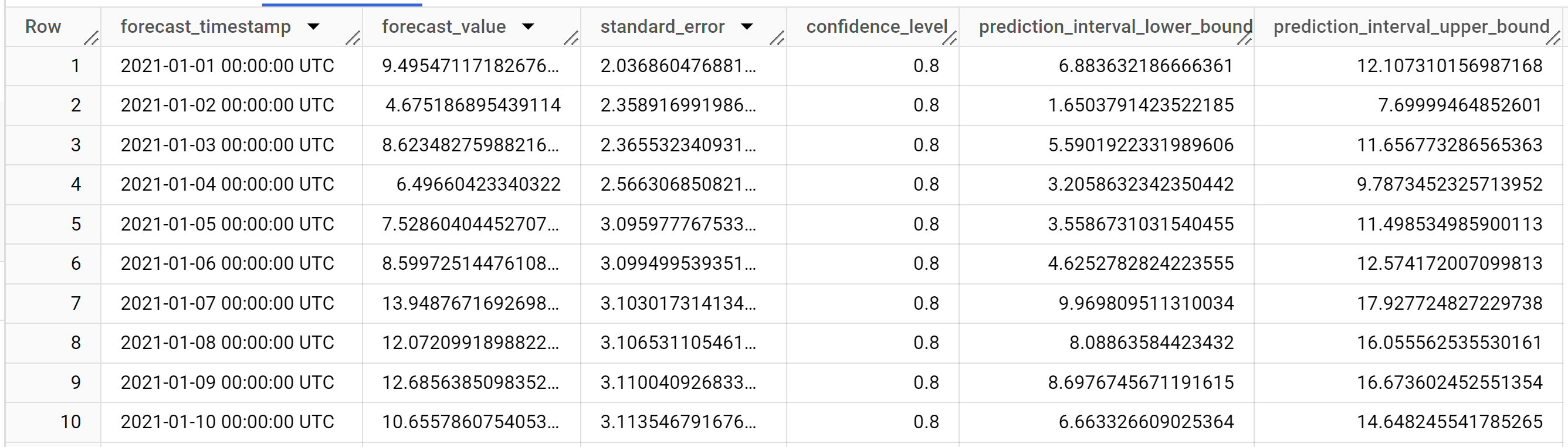
Die Ausgabezeilen sind in chronologischer Reihenfolge nach dem Wert der Spalte
forecast_timestampsortiert. In der Zeitachsenprognose ist das Vorhersageintervall, das durch die Spaltenwerteprediction_interval_lower_boundundprediction_interval_upper_bounddargestellt wird, genauso wichtig wie der Spaltenwertforecast_value. Derforecast_value-Wert ist der Mittelpunkt des Vorhersageintervalls. Das Vorhersageintervall hängt von den Spaltenwertenstandard_errorundconfidence_levelab.Weitere Informationen zu den Ausgabespalten finden Sie unter
ML.FORECAST-Funktion.
Prognosegenauigkeit bewerten
Bewerten Sie die Prognosegenauigkeit des Modells mit der Funktion ML.EVALUATE.
In der folgenden GoogleSQL-Abfrage enthält die zweite SELECT-Anweisung die Daten mit den zukünftigen Features, die für die Prognose der zukünftigen Werte verwendet werden, um sie mit den tatsächlichen Daten zu vergleichen.
So bewerten Sie die Genauigkeit des Modells:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.EVALUATE( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, ( SELECT date, pm25, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ), STRUCT( TRUE AS perform_aggregation, 30 AS horizon));
Die Ergebnisse sollten in etwa so aussehen:

Weitere Informationen zu den Ausgabespalten finden Sie unter
ML.EVALUATE-Funktion.
Prognoseergebnisse erklären
Mit der Funktion ML.EXPLAIN_FORECAST können Sie neben Prognosedaten auch Messwerte zur Erklärbarkeit abrufen. Die Funktion ML.EXPLAIN_FORECAST prognostiziert zukünftige Zeitreihenwerte und gibt auch alle separaten Komponenten der Zeitreihe zurück.
Ähnlich wie bei der Funktion ML.FORECAST gibt die in der Funktion ML.EXPLAIN_FORECAST verwendete Klausel STRUCT(30 AS horizon, 0.8 AS confidence_level) an, dass die Abfrage 30 zukünftige Zeitpunkte prognostiziert und ein Vorhersageintervall mit einer Konfidenz von 80% generiert.
So erklären Sie die Ergebnisse des Modells:
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.EXPLAIN_FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ));
Die Antwort sollte in etwa so aussehen:
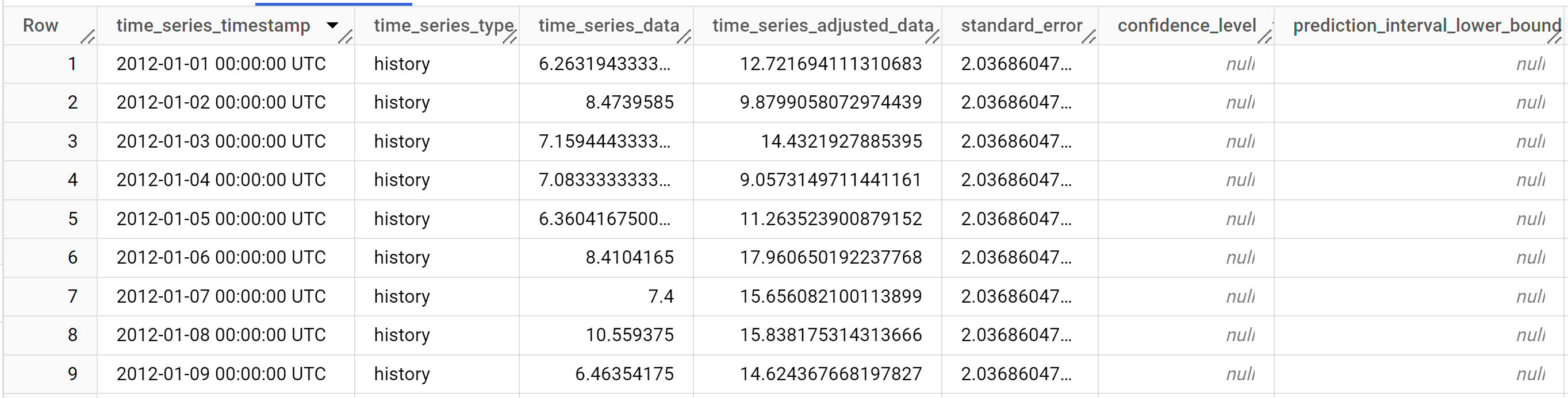
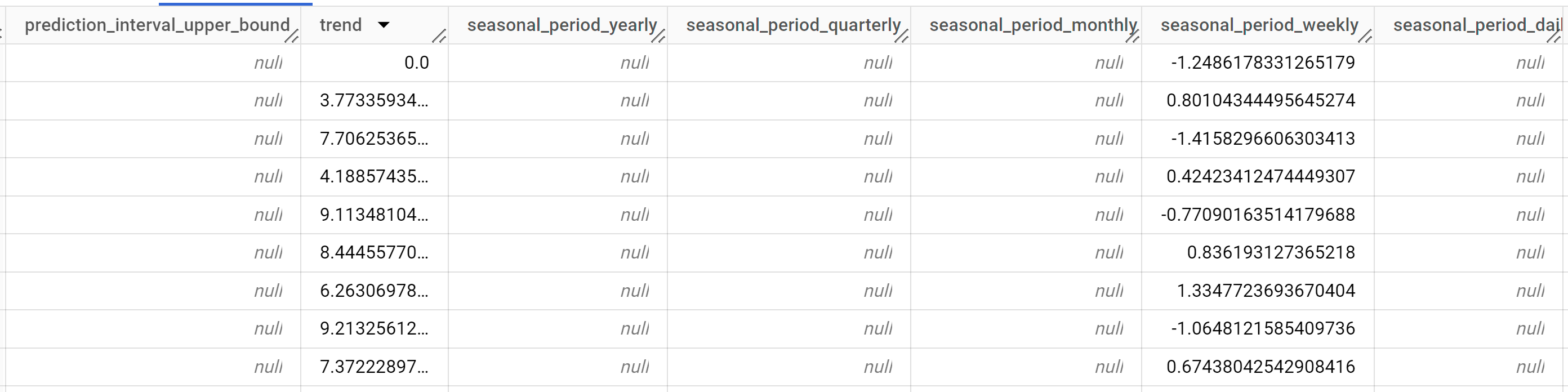
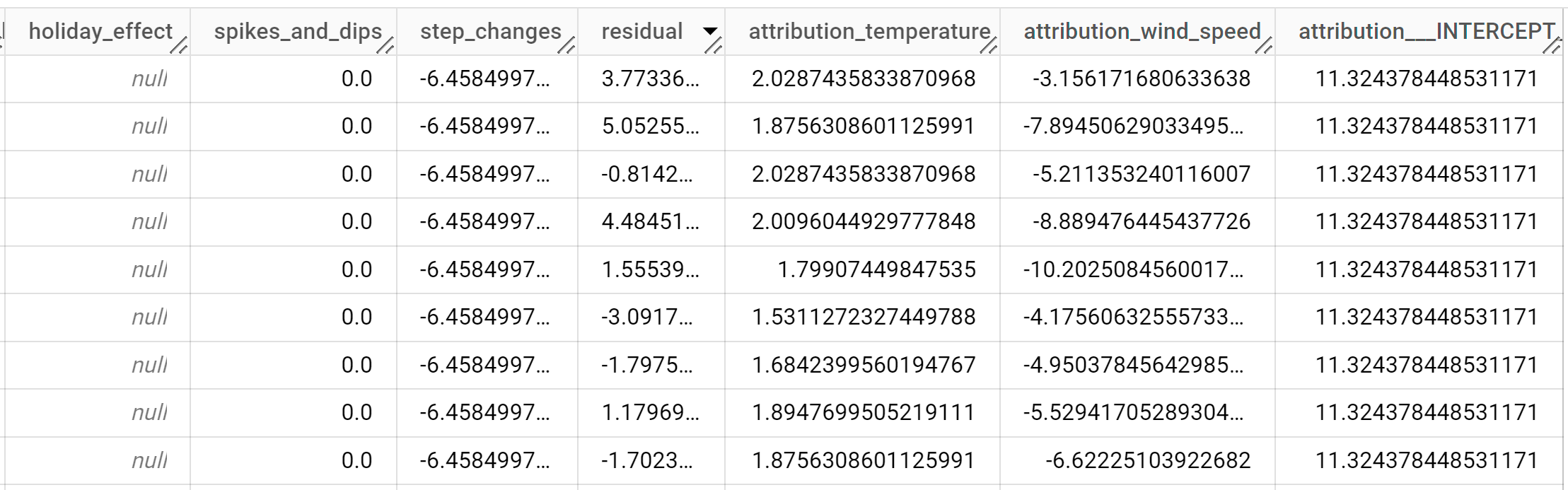
Die Ausgabezeilen werden chronologisch nach dem Spaltenwert
time_series_timestampsortiert.Weitere Informationen zu den Ausgabespalten finden Sie unter
ML.EXPLAIN_FORECAST-Funktion.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
- Sie können das von Ihnen erstellte Projekt löschen.
- Sie können das Projekt aber auch behalten und das Dataset löschen.
Dataset löschen
Wenn Sie Ihr Projekt löschen, werden alle Datasets und Tabellen entfernt. Wenn Sie das Projekt wieder verwenden möchten, können Sie das in dieser Anleitung erstellte Dataset löschen:
Rufen Sie, falls erforderlich, die Seite „BigQuery“ in derGoogle Cloud Console auf.
Wählen Sie im Navigationsbereich das Dataset bqml_tutorial aus, das Sie erstellt haben.
Klicken Sie rechts im Fenster auf Delete dataset (Dataset löschen). Dadurch werden das Dataset, die Tabelle und alle Daten gelöscht.
Bestätigen Sie im Dialogfeld Dataset löschen den Löschbefehl. Geben Sie dazu den Namen des Datasets (
bqml_tutorial) ein und klicken Sie auf Löschen.
Projekt löschen
So löschen Sie das Projekt:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
- Informationen zum Prognostizieren einer einzelnen Zeitachse mit einem univariaten Modell
- Mehrere Zeitreihen mit einem univariaten Modell prognostizieren
- Informationen zum Skalieren eines univariaten Modells bei der Prognose mehrerer Zeitreihen über viele Zeilen hinweg
- Hierarchische Prognosen für mehrere Zeitachsen mit einem univariaten Modell erstellen
- Eine Übersicht über BigQuery ML finden Sie unter Einführung in KI und ML in BigQuery.