In dieser Anleitung erfahren Sie, wie Sie ein multivariates Zeitachsenmodell (ARIMA_PLUS_XREG) erstellen, um Zeitachsenprognosen mithilfe folgender Beispieltabellen aus dem epa_historical_air_quality-Dataset durchzuführen:
epa_historical_air_quality.pm25_nonfrm_daily_summary-Beispieltabelle.epa_historical_air_quality.wind_daily_summary-Beispieltabelle.epa_historical_air_quality.temperature_daily_summary-Beispieltabelle.
Das epa_historical_air_quality-Dataset enthält Tagesinformationen zu PM-2.5, Temperatur und Windgeschwindigkeiten, die in mehreren Städten in den USA erfasst wurden.
Ziele
In dieser Anleitung verwenden Sie Folgendes:
- Die
CREATE MODEL-Anweisung zum Erstellen eines Zeitachsenmodells. - Die
ML.ARIMA_EVALUATE-Funktion zum Prüfen der ARIMA-bezogenen Bewertungsinformationen im Modell. - Die
ML.ARIMA_COEFFICIENTS-Funktion zum Prüfen der Modellkoeffizienten. - Die
ML.FORECAST-Funktion zur Prognose des täglichen PM 2.5. - Die
ML.EVALUATE-Funktion zum Bewerten des Modells mit tatsächlichen Daten. - Die Funktion
ML.EXPLAIN_FORECASTzum Abrufen verschiedener Komponenten der Zeitreihe (z. B. Saisonalität, Trend und Feature-Attributionen), die Sie zur Erklärung der Prognoseergebnisse verwenden können.
Kosten
In dieser Anleitung werden kostenpflichtige Komponenten von Google Cloud verwendet, darunter:
- BigQuery
- BigQuery ML
Weitere Informationen zu den Kosten von BigQuery finden Sie auf der Seite BigQuery-Preise.
Weitere Informationen zu den Kosten für BigQuery ML finden Sie unter BigQuery ML-Preise.
Vorbereitung
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- BigQuery ist in neuen Projekten automatisch aktiviert.
Zum Aktivieren von BigQuery in einem vorhandenen Projekt wechseln Sie zu
Enable the BigQuery API.
.
Schritt 1: Dataset erstellen
Erstellen Sie ein BigQuery-Dataset, um Ihr ML-Modell zu speichern:
Rufen Sie in der Google Cloud Console die Seite „BigQuery“ auf.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.
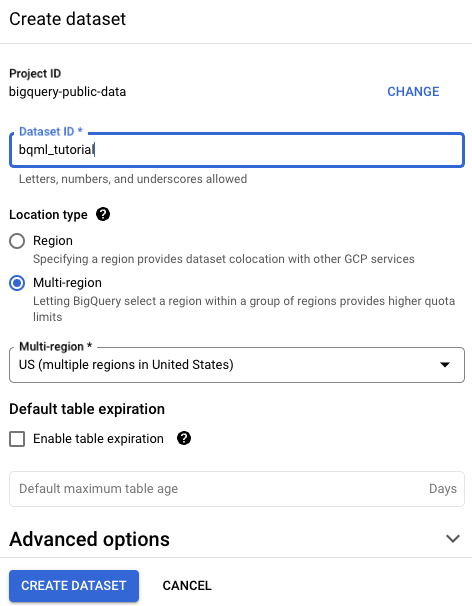
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
bqml_tutorialein.Wählen Sie als Standorttyp die Option Mehrere Regionen und dann USA (mehrere Regionen in den USA) aus.
Die öffentlichen Datasets sind am multiregionalen Standort
USgespeichert. Der Einfachheit halber sollten Sie Ihr Dataset am selben Standort speichern.Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf Dataset erstellen.
Schritt 2: Zeitachsentabelle mit zusätzlichen Features erstellen
Die Daten zu PM2.5, Temperatur und Windgeschwindigkeit befinden sich in separaten Tabellen.
Zur Vereinfachung der folgenden Abfragen können Sie eine neue Tabelle bqml_tutorial.seattle_air_quality_daily erstellen. Dazu verknüpfen Sie diese Tabellen mit folgenden Spalten:
- Datum: das Datum der Beobachtung
- PM2.5: der durchschnittliche PM2.5-Wert je Tag
- wind_speed: durchschnittliche Windgeschwindigkeit je Tag
- Temperatur: die Höchsttemperatur je Tag
Die neue Tabelle enthält Tagesdaten vom 11.08.2009 bis zum 31.01.2022.
In der folgenden GoogleSQL-Abfrage gibt die FROM bigquery-public-data.epa_historical_air_quality.*_daily_summary-Klausel an, dass Sie die *_daily_summary-Tabellen im epa_historical_air_quality-Dataset abfragen. Diese Tabellen sind partitionierte Tabellen.
#standardSQL CREATE TABLE `bqml_tutorial.seattle_air_quality_daily` AS WITH pm25_daily AS ( SELECT avg(arithmetic_mean) AS pm25, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.pm25_nonfrm_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Acceptable PM2.5 AQI & Speciation Mass' GROUP BY date_local ), wind_speed_daily AS ( SELECT avg(arithmetic_mean) AS wind_speed, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.wind_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Wind Speed - Resultant' GROUP BY date_local ), temperature_daily AS ( SELECT avg(first_max_value) AS temperature, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.temperature_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Outdoor Temperature' GROUP BY date_local ) SELECT pm25_daily.date AS date, pm25, wind_speed, temperature FROM pm25_daily JOIN wind_speed_daily USING (date) JOIN temperature_daily USING (date)
Die Abfrage führen Sie so aus:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im obigen Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
Klicken Sie auf Ausführen.
Schritt 3 (optional): Vorherzusagende Zeitachsen visualisieren
Schauen Sie sich Ihre Eingabezeitachse genau an, bevor Sie das Modell erstellen. Verwenden Sie dazu Looker Studio.
In der folgenden GoogleSQL-Abfrage gibt die FROM bqml_tutorial.seattle_air_quality_daily-Klausel an, dass Sie die seattle_air_quality_daily-Tabelle im gerade erstellten bqml_tutorial-Dataset abfragen.
#standardSQL SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`
Die Abfrage führen Sie so aus:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
#standardSQL SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`
Klicken Sie auf Ausführen.
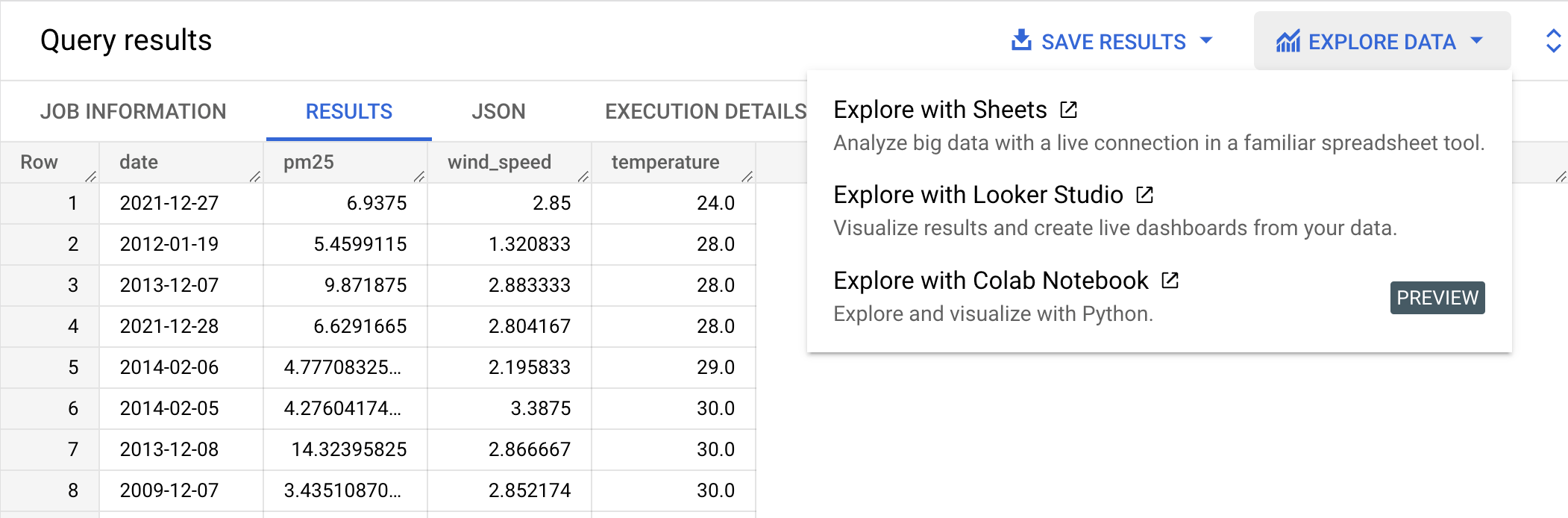
Nachdem diese Abfrage ausgeführt wurde, sieht die Ausgabe dem folgenden Screenshot ähnlich. Im Screenshot sehen Sie, dass diese Zeitachse 3960 Datenpunkte enthält. Klicken Sie auf die Schaltfläche Daten auswerten und dann auf Mit Looker Studio auswerten. Looker Studio wird in einem neuen Tab geöffnet. Führen Sie die folgenden Schritte in dem neuen Tab aus.
Wählen Sie im Bereich Diagramm die Option Zeitachsendiagramm aus:
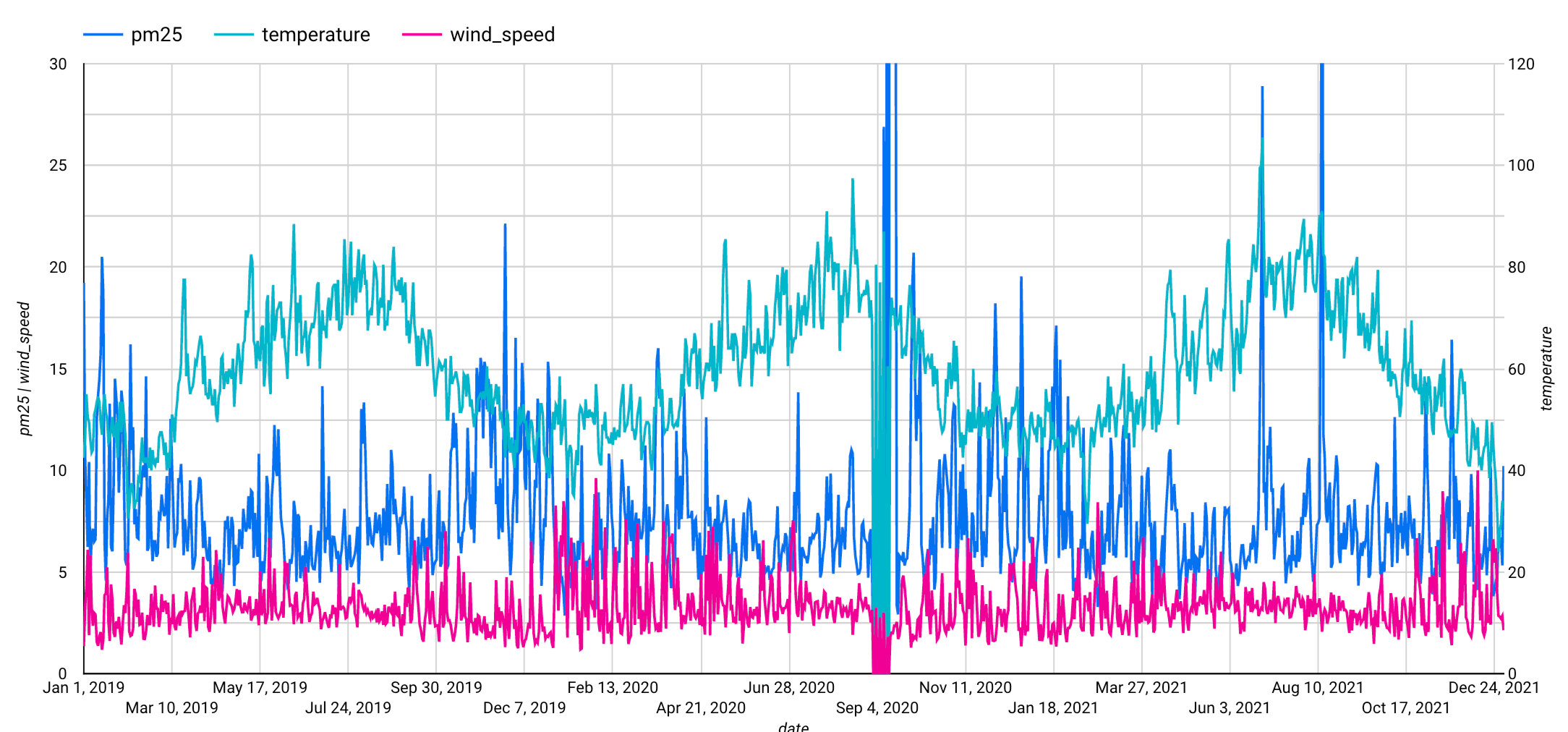
Gehen Sie im SETUPBildschirm im Bereich Grafik zum Abschnitt Messwert. Fügen Sie die Felder pm25, temperature und wind_speed hinzu und entfernen Sie dann den Standardmesswert Record Count. Sie können auch einen benutzerdefinierten Zeitraum festlegen, z. B. 1. Januar 2019 bis 31. Dezember 2021, um die Zeitreihe zu verkürzen. Dies wird in der folgenden Abbildung dargestellt.
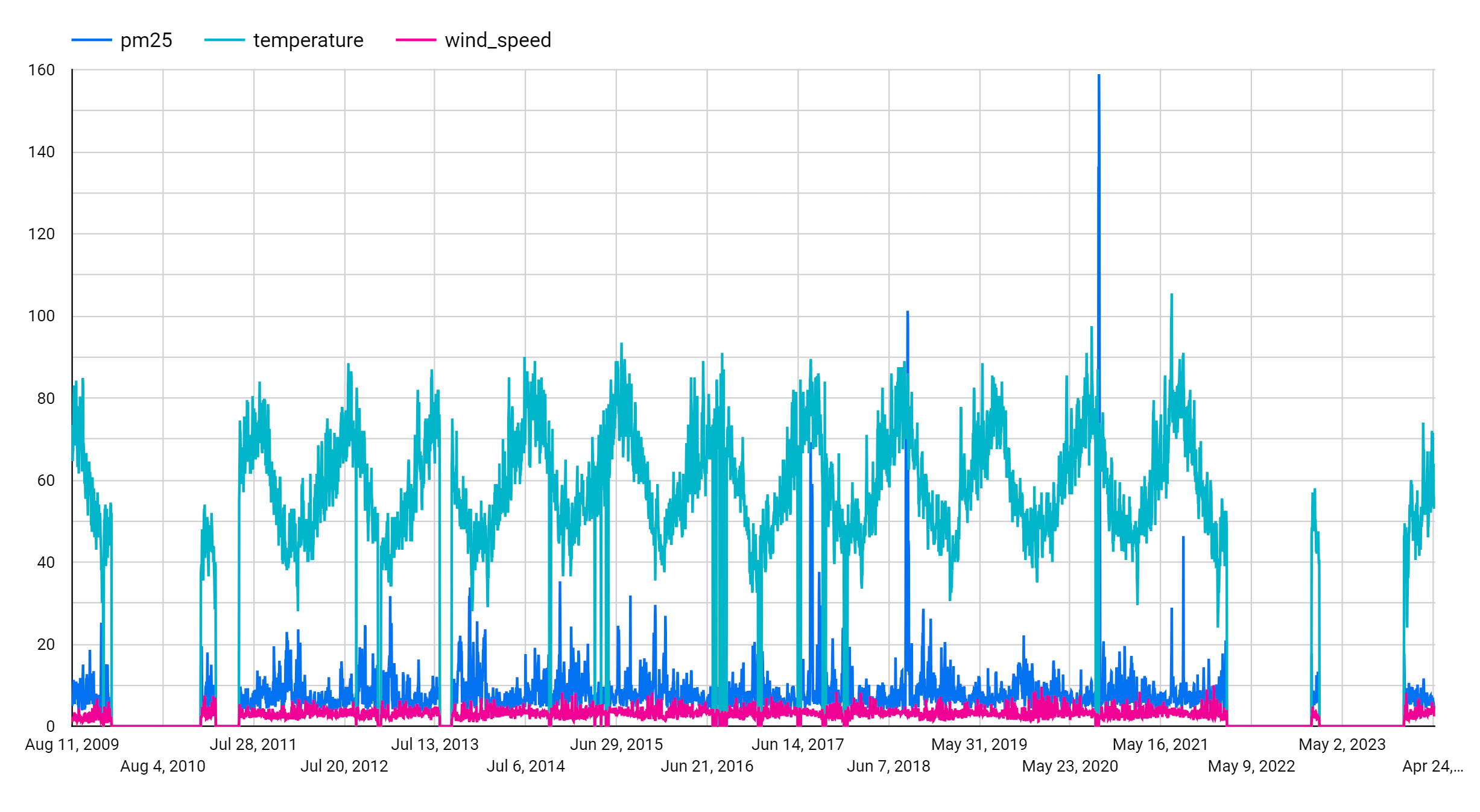
Nachdem Sie diese Schritte abgeschlossen haben, wird das folgende Diagramm angezeigt. Dem Diagramm können Sie entnehmen, dass die Eingabezeitachse ein wöchentliches saisonales Muster aufweist.
Schritt 4: Zeitachsenmodell erstellen
Erstellen Sie als Nächstes ein Zeitachsenmodell mit den obigen Luftqualitätsdaten.
Die folgende GoogleSQL-Abfrage erstellt ein Modell für die Prognose von pm25.
Die CREATE MODEL-Klausel erstellt und trainiert ein Modell mit dem Namen bqml_tutorial.seattle_pm25_xreg_model.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.seattle_pm25_xreg_model` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS_XREG', time_series_timestamp_col = 'date', time_series_data_col = 'pm25') AS SELECT date, pm25, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31')
Die OPTIONS(model_type='ARIMA_PLUS_XREG', time_series_timestamp_col='date', ...)-Klausel gibt an, dass Sie ein ARIMA-Modell mit externen Regressoren erstellen. Standardmäßig wird auto_arima=TRUE verwendet, sodass der auto.ARIMA-Algorithmus die Hyperparameter in ARIMA_PLUS_XREG-Modellen automatisch abstimmt. Der Algorithmus passt Dutzende von Kandidatenmodellen an und wählt das beste Modell mit dem niedrigsten Akaike-Informationskriterium (AIC) aus.
Da der Standardwert data_frequency='AUTO_FREQUENCY' ist, leitet der Trainingsprozess außerdem automatisch die Datenhäufigkeit der Eingabezeitachse ab.
Führen Sie die CREATE MODEL-Abfrage aus, um Ihr Modell zu erstellen und zu trainieren:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im obigen Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
Klicken Sie auf Ausführen.
Die Abfrage dauert ungefähr 20 Sekunden. Anschließend wird das Modell (
seattle_pm25_xreg_model) im Navigationsbereich angezeigt. Da die Abfrage eineCREATE MODEL-Anweisung zum Erstellen eines Modells verwendet, werden keine Abfrageergebnisse ausgegeben.
Schritt 5: Bewertungsmesswerte aller bewerteten Modelle prüfen
Nachdem Sie Ihr Modell erstellt haben, verwenden Sie die ML.ARIMA_EVALUATE-Funktion, die Bewertungsmesswerte aller infrage kommenden Modelle anzeigt, die während der automatischen Hyperparameter-Abstimmung bewertet wurden.
In folgender GoogleSQL-Abfrage verwendet die FROM-Klausel die ML.ARIMA_EVALUATE-Funktion für Ihr Modell, bqml_tutorial.seattle_pm25_xreg_model. Standardmäßig werden mit dieser Abfrage die Bewertungsmesswerte aller Kandidatenmodelle zurückgegeben.
Führen Sie die ML.ARIMA_EVALUATE-Abfrage mit folgenden Schritten aus:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
#standardSQL SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.seattle_pm25_xreg_model`)
Klicken Sie auf Ausführen.
Sobald die Abfrage abgeschlossen ist, klicken Sie unterhalb des Textbereichs der Abfrage auf den Tab Ergebnisse. Die Ergebnisse sollten in etwa so aussehen:

Die Ergebnisse enthalten die folgenden Spalten:
non_seasonal_pnon_seasonal_dnon_seasonal_qhas_driftlog_likelihoodAICvarianceseasonal_periodshas_holiday_effecthas_spikes_and_dipshas_step_changeserror_message
Die folgenden vier Spalten (
non_seasonal_{p,d,q}undhas_drift) definieren ein ARIMA-Modell in der Trainingspipeline. Die drei folgenden Messwerte (log_likelihood,AICundvariance) sind für den ARIMA-Modellanpassungsprozess relevant.Der
auto.ARIMA-Algorithmus verwendet zuerst den KPSS-Test, um zu bestimmen, dass der beste Wert fürnon_seasonal_d1 ist. Wennnon_seasonal_d1 ist, trainiert auto.ARIMA anschließend 42 verschiedene ARIMA-Kandidatenmodelle parallel. Beachten Sie, dass auto.ARIMA 21 verschiedene Kandidatenmodelle trainiert, wennnon_seasonal_dnicht 1 ist. In diesem Beispiel sind alle 42 Kandidatenmodelle gültig. Daher enthält die Ausgabe 42 Zeilen, wobei jede Zeile einem ARIMA-Kandidatenmodell zugeordnet ist. Für einige Zeitachsen können mehrere mögliche Modelle ungültig sein, da sie entweder nicht umkehrbar oder nicht stationär sind. Diese ungültigen Modelle werden aus der Ausgabe ausgeschlossen, sodass die Ausgabe weniger als 42 Zeilen hat. Diese Kandidatenmodelle werden gemäß dem AIC in aufsteigender Reihenfolge sortiert. Das Modell in der ersten Zeile hat den niedrigsten AIC und gilt als bestes Modell. Dieses Modell wird dann als endgültiges Modell gespeichert und verwendet, wenn Sie, wie in den folgenden Schritten gezeigt,ML.FORECAST,ML.EVALUATEundML.ARIMA_COEFFICIENTSaufrufen.Die Spalte
seasonal_periodsbezieht sich auf das saisonale Muster innerhalb der Eingabezeitachse. Es hat nichts mit der ARIMA-Modellierung zu tun und hat daher in allen Ausgabezeilen denselben Wert. Es wird ein wöchentliches Muster gemeldet, was unseren Erwartungen in Schritt 2 entspricht.Die Spalten
has_holiday_effect,has_spikes_and_dipsundhas_step_changeswerden nur ausgefüllt, wenndecompose_time_series=TRUE. Sie betreffen den Urlaubseffekt, Spitzen und Einbrüche sowie Schrittwechsel innerhalb der Eingabezeitachse, die nicht mit der ARIMA-Modellierung zusammenhängen. Aus diesem Grund sind sie für alle Ausgabezeilen gleich, außer für die fehlgeschlagenen Modelle.Die Spalte
error_messagezeigt an, dass der mögliche Fehler bei derauto.ARIMA-Anpassung aufgetreten ist. Ein möglicher Grund dafür ist, dass die ausgewählten Spaltennon_seasonal_p,non_seasonal_d,non_seasonal_qundhas_driftdie Zeitachse nicht stabilisieren können. Legen Sieshow_all_candidate_models=truefest, um die mögliche Fehlermeldung aller Kandidatenmodelle abzurufen.
Schritt 6: Koeffizienten Ihres Modells prüfen
Die Funktion ML.ARIMA_COEFFICIENTS ruft die Modellkoeffizienten Ihres ARIMA_PLUS-Modells bqml_tutorial.seattle_pm25_xreg_model ab. ML.ARIMA_COEFFICIENTS verwendet das Modell als einzige Eingabe.
Führen Sie die ML.ARIMA_COEFFICIENTS-Abfrage aus:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
#standardSQL SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.seattle_pm25_xreg_model`)
Klicken Sie auf Ausführen.
Die Ergebnisse sollten so aussehen:
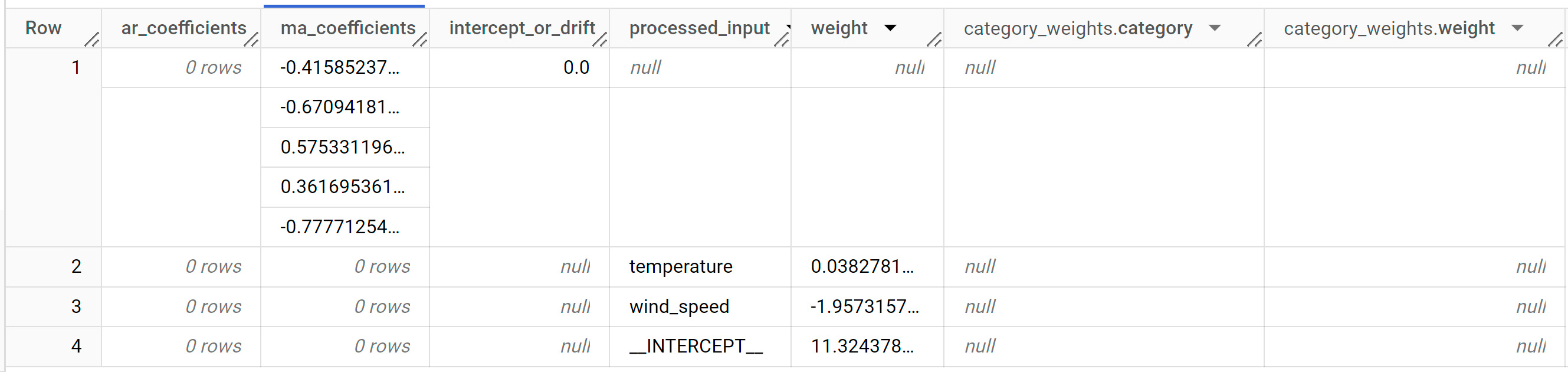
Die Ergebnisse enthalten die folgenden Spalten:
ar_coefficientsma_coefficientsintercept_or_driftprocessed_inputweightcategory_weights.categorycategory_weights.weight
ar_coefficientszeigt die Modellkoeffizienten des autoregressiven (AR) Teils des ARIMA-Modells an. Auf ähnliche Weise zeigtma_coefficientsdie Modellkoeffizienten des gleitenden Durchschnitts (Moving Average, MA) an. Beide sind Arrays, deren Längenon_seasonal_pbzw.non_seasonal_qentspricht. In der Ausgabe vonML.ARIMA_EVALUATEhat das beste Modell in der obersten Zeile einen Wert von 0 fürnon_seasonal_pund einen Wert von 5 fürnon_seasonal_q. Daher istar_coefficientsein leeres Array undma_coefficientsein Array der Länge 5.intercept_or_driftist der konstante Begriff im ARIMA-Modell.processed_inputund die entsprechendenweight- undcategory_weights-Spalten zeigen die Gewichtungen für jedes Feature und den Abfang im linearen Regressionsmodell an. Wenn es sich um ein numerisches Feature handelt, wird die Gewichtung in derweight-Spalte angezeigt. Wenn es sich bei dem Feature um ein kategorisches Feature handelt, istcategory_weightseinARRAYvonSTRUCT, wobei derSTRUCTdie Namen und Gewichtungen der Kategorien enthält.
Schritt 7: Modell zur Prognose der Zeitachsen verwenden
Die ML.FORECAST-Funktion prognostiziert zukünftige Zeitachsenwerte mit einem Vorhersageintervall unter Verwendung des Modells bqml_tutorial.seattle_pm25_xreg_model und der zukünftigen Featurewerte.
In der folgenden GoogleSQL-Abfrage gibt die STRUCT(30 AS horizon, 0.8 AS confidence_level)-Klausel an, dass die Abfrage 30 zukünftige Zeitpunkte prognostiziert und ein Vorhersageintervall mit einem Konfidenzniveau von 80 % generiert. ML.FORECAST verwendet das Modell, zukünftige Featurewerte sowie einige optionale Argumente.
Führen Sie die ML.FORECAST-Abfrage mit folgenden Schritten aus:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
#standardSQL SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ))
Klicken Sie auf Ausführen.
Die Ergebnisse sollten so aussehen:
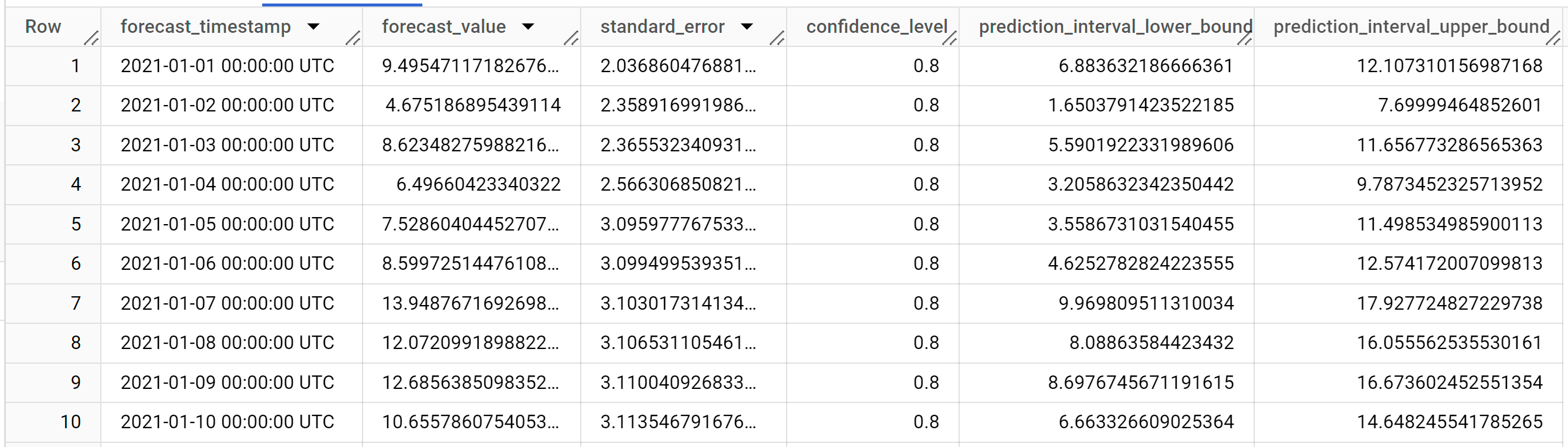
Die Ergebnisse enthalten die folgenden Spalten:
forecast_timestampforecast_valuestandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_upper_bound
Die Ausgabezeilen werden in chronologischer Reihenfolge nach
forecast_timestampangeordnet. In der Zeitachsenprognose ist das Vorhersageintervall, das sich aus der Unter- und Obergrenze ergibt, genauso wichtig wieforecast_value. Derforecast_valueist der Mittelpunkt des Vorhersageintervall. Das Vorhersageintervall hängt vonstandard_errorundconfidence_levelab.
Schritt 8: Prognosegenauigkeit mit tatsächlichen Daten bewerten
Um die Vorhersagegenauigkeit anhand der tatsächlichen Daten zu bewerten, nutzen Sie die ML.EVALUATE-Funktion mit Ihrem Modell (bqml_tutorial.seattle_pm25_xreg_model) und die Tabelle der tatsächlichen Daten.
Führen Sie die ML.EVALUATE-Abfrage mit folgenden Schritten aus:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
#standardSQL SELECT * FROM ML.EVALUATE( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, ( SELECT date, pm25, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ), STRUCT( TRUE AS perform_aggregation, 30 AS horizon))
Der zweite Parameter enthält die tatsächlichen Daten mit den zukünftigen Features, die für die Prognose der zukünftigen Werte mit den tatsächlichen Daten verwendet werden. Der dritte Parameter steht für eine Parameterstruktur für diese Funktion.
Klicken Sie auf Ausführen.
Die Ergebnisse sollten so aussehen:

Schritt 9: Prognoseergebnisse erklären
Um zu verstehen, wie die Zeitreihe prognostiziert wird, prognostiziert die Funktion ML.EXPLAIN_FORECAST zukünftige Zeitreihenwerte mit einem Vorhersageintervall unter Verwendung des Modells bqml_tutorial.seattle_pm25_xreg_model und gibt gleichzeitig alle einzelnen Komponenten der Zeitreihe zurück.
Wie die Funktion ML.FORECAST gibt die Klausel STRUCT(30 AS horizon, 0.8 AS confidence_level) an, dass die Abfrage 30 zukünftige Zeitpunkte prognostiziert und ein Vorhersageintervall mit einer Konfidenz von 80 % generiert. Die Funktion ML.EXPLAIN_FORECAST verwendet das Modell, zukünftige Featurewerte und einige optionale Argumente als Eingabe.
Führen Sie die ML.EXPLAIN_FORECAST-Abfrage mit folgenden Schritten aus:
Klicken Sie in der Google Cloud Console auf Neue Abfrage erstellen.
Geben Sie im Textfeld des Abfrageeditors die folgende GoogleSQL-Abfrage ein.
#standardSQL SELECT * FROM ML.EXPLAIN_FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ))
Klicken Sie auf Ausführen.
Die Abfrage dauert weniger als eine Sekunde. Die Ergebnisse sollten so aussehen:
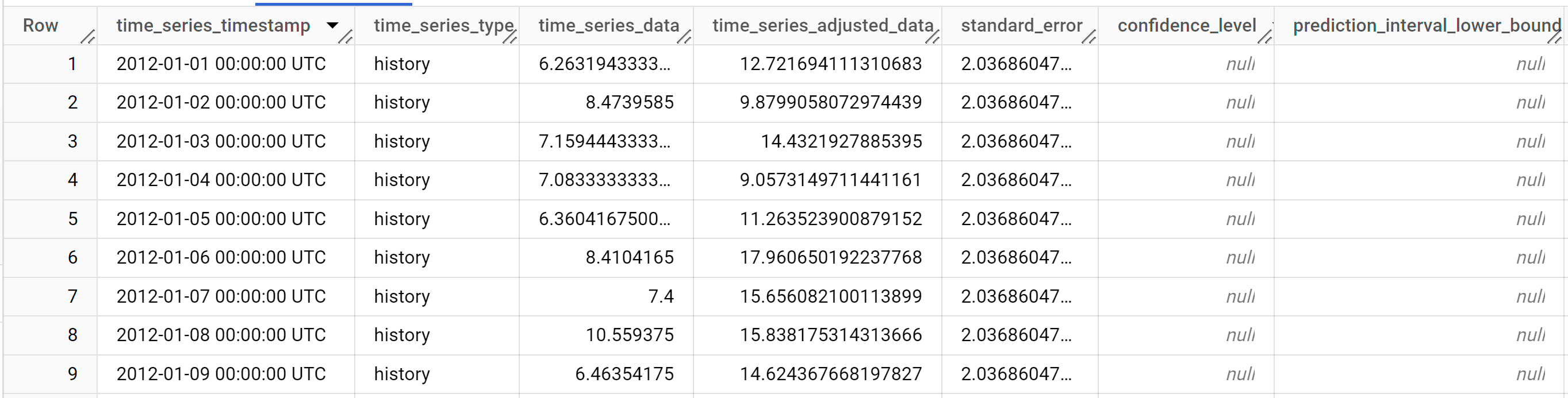
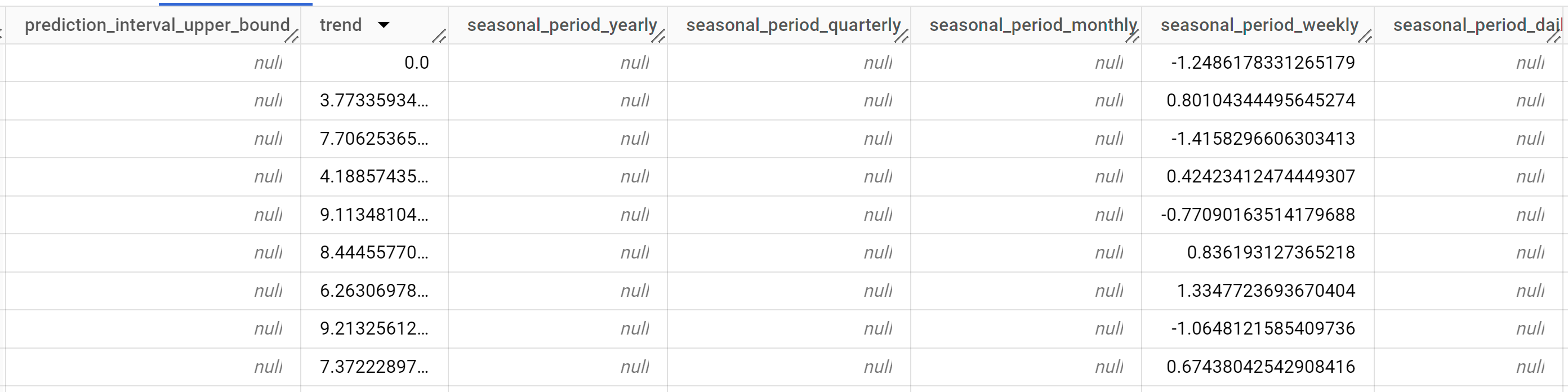
Die Ergebnisse enthalten die folgenden Spalten:
time_series_timestamptime_series_typetime_series_datatime_series_adjusted_datastandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_lower_boundtrendseasonal_period_yearlyseasonal_period_quarterlyseasonal_period_monthlyseasonal_period_weeklyseasonal_period_dailyholiday_effectspikes_and_dipsstep_changesresidualattribution_temperatureattribution_wind_speedattribution___INTERCEPT__
Die Ausgabezeilen werden in chronologischer Reihenfolge nach
time_series_timestampangeordnet. Verschiedene Komponenten werden als Spalten der Ausgabe aufgeführt. Weitere Informationen finden Sie unterML.EXPLAIN_FORECAST.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
- Sie können das von Ihnen erstellte Projekt löschen.
- Sie können das Projekt aber auch behalten und das Dataset löschen.
Dataset löschen
Wenn Sie Ihr Projekt löschen, werden alle Datasets und Tabellen entfernt. Wenn Sie das Projekt wieder verwenden möchten, können Sie das in dieser Anleitung erstellte Dataset löschen:
Rufen Sie, falls erforderlich, die Seite "BigQuery" in der Google Cloud Console auf.
Wählen Sie im Navigationsbereich das Dataset bqml_tutorial aus, das Sie erstellt haben.
Klicken Sie rechts im Fenster auf Delete dataset (Dataset löschen). Dadurch werden das Dataset, die Tabelle und alle Daten gelöscht.
Bestätigen Sie im Dialogfeld Delete dataset (Dataset löschen) den Löschbefehl. Geben Sie dazu den Namen des Datasets (
bqml_tutorial) ein und klicken Sie auf Delete (Löschen).
Projekt löschen
So löschen Sie das Projekt:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
- Prognosen für mehrere Zeitachsen mit einer einzigen Abfrage für "NYC Citi Bike"-Fahrten durchführen
- Erfahren Sie, wie Sie ARIMA_PLUS beschleunigen, um eine Million Zeitachsen innerhalb von Stunden zu prognostizieren.
- Mehr über das maschinelle Lernen im Machine Learning Crash Course erfahren
- Eine Übersicht über BigQuery ML finden Sie unter Einführung in BigQuery ML.
- Weitere Informationen zur Google Cloud Console finden Sie unter Google Cloud Console verwenden.