En este instructivo, aprenderás a usar un modelo de serie temporal univariable ARIMA_PLUS para predecir el valor futuro de una columna determinada, según los valores históricos de esa columna.
En este instructivo, se realizan previsiones para varias series temporales. Los valores previstos se calculan para cada punto temporal y para cada valor en una o más columnas especificadas. Por ejemplo, si deseas predecir el clima y especificas una columna que contiene datos de la ciudad, los datos previstos contendrán predicciones para todos los puntos temporales de la ciudad A, luego los valores previstos para todos los puntos temporales de la ciudad B, y así sucesivamente.
En este instructivo, se usan datos de la tabla pública bigquery-public-data.new_york.citibike_trips. Esta tabla contiene información sobre los viajes de Citi Bike en la ciudad de Nueva York.
Antes de leer este instructivo, te recomendamos que leas Cómo predecir una sola serie temporal con un modelo univariado.
Objetivos
En este instructivo, se te guiará para que completes las siguientes tareas:
- Crear un modelo de series temporales para predecir la cantidad de viajes en bicicleta con la declaración
CREATE MODEL - Evalúa la información del modelo de promedio móvil integrado autorregresivo (ARIMA) con la función
ML.ARIMA_EVALUATE. - Inspecciona los coeficientes del modelo con la función
ML.ARIMA_COEFFICIENTS. - Recuperar la información pronosticada del viaje en bicicleta del modelo con la función
ML.FORECAST - Recuperar componentes de las series temporales, como la estacionalidad y la tendencia, con la función
ML.EXPLAIN_FORECASTPuedes inspeccionar estos componentes de series temporales para explicar los valores previstos.
Costos
En este instructivo, se usan los siguientes componentes facturables de Google Cloud:
- BigQuery
- BigQuery ML
Para obtener más información sobre los costos de BigQuery, consulta la página de precios de BigQuery.
Para obtener más información sobre los costos de BigQuery ML, consulta los precios de BigQuery ML.
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery se habilita automáticamente en proyectos nuevos.
Para activar BigQuery en un proyecto existente, ve a
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Para crear el conjunto de datos, necesitas el permiso
bigquery.datasets.createde IAM.Para crear el modelo, necesitas los siguientes permisos:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Para ejecutar inferencias, necesitas los siguientes permisos:
bigquery.models.getDatabigquery.jobs.create
Permisos necesarios
Para obtener más información sobre los roles y permisos de IAM en BigQuery, consulta Introducción a IAM.
Crea un conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tu modelo de AA.
Console
En la consola de Google Cloud , ve a la página BigQuery.
En el panel Explorador, haz clic en el nombre de tu proyecto.
Haz clic en Ver acciones > Crear conjunto de datos.
En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, ingresa
bqml_tutorial.En Tipo de ubicación, selecciona Multirregión y, luego, EE.UU. (varias regiones en Estados Unidos).
Deja la configuración predeterminada restante como está y haz clic en Crear conjunto de datos.
bq
Para crear un conjunto de datos nuevo, usa el comando bq mk con la marca --location. Para obtener una lista completa de los parámetros posibles, consulta la
referencia del
comando bq mk --dataset.
Crea un conjunto de datos llamado
bqml_tutorialcon la ubicación de los datos establecida enUSy una descripción deBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
En lugar de usar la marca
--dataset, el comando usa el acceso directo-d. Si omites-dy--dataset, el comando crea un conjunto de datos de manera predeterminada.Confirma que se haya creado el conjunto de datos:
bq ls
API
Llama al método datasets.insert con un recurso de conjunto de datos definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
Permite trabajar con BigQuery DataFrames.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Visualiza los datos de entrada
Antes de crear el modelo, puedes visualizar de forma opcional tus datos de series temporales de entrada para tener una idea de la distribución. Puedes hacerlo con Looker Studio.
SQL
La declaración SELECT de la siguiente consulta usa la función EXTRACT para extraer la información de la fecha de la columna starttime. La consulta usa la cláusula COUNT(*) para obtener la cantidad total diaria de viajes con Citi Bike.
Sigue estos pasos para visualizar los datos de series temporales:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date;
Cuando se complete la consulta, haz clic en Explorar datos > Explorar con Looker Studio. Looker Studio se abre en una pestaña nueva. Completa los siguientes pasos en la pestaña nueva.
En Looker Studio, haz clic en Insertar > Gráfico de serie temporal.
En el panel Gráfico, elige la pestaña Configuración.
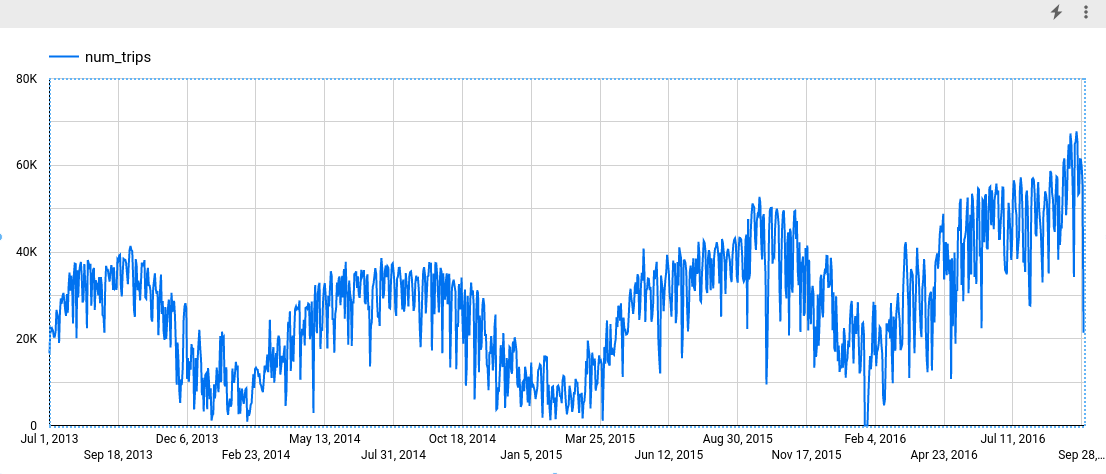
En la sección Métrica, agrega el campo num_trips y quita la métrica predeterminada Recuento de registros. El gráfico resultante es similar al siguiente:
Permite trabajar con BigQuery DataFrames.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Crea el modelo de serie temporal
Quieres prever la cantidad de viajes en bicicleta para cada estación de Citi Bike, lo que requiere muchos modelos de series temporales, uno para cada estación de Citi Bike que se incluye en los datos de entrada. Puedes crear varios modelos para hacerlo, pero puede ser un proceso tedioso y lento, en especial cuando tienes una gran cantidad de series temporales. En su lugar, puedes usar una sola consulta para crear y ajustar un conjunto de modelos de series temporales y, así, prever varias series temporales a la vez.
SQL
En la siguiente consulta, la cláusula OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) indica que creas un modelo de serie temporal basado en ARIMA. Usas la opción time_series_id_col de la sentencia CREATE MODEL para especificar una o más columnas en los datos de entrada para las que deseas obtener previsiones, en este caso, la estación de Citi Bike, como se representa en la columna start_station_name. Usas la cláusula WHERE para limitar las estaciones de inicio a aquellas con Central Park en el nombre. La opción auto_arima_max_order de la instrucción CREATE MODEL controla el espacio de búsqueda para el ajuste de hiperparámetros en el algoritmo auto.ARIMA. La opción decompose_time_series de la instrucción CREATE MODEL se establece de forma predeterminada en TRUE, de modo que se muestre información sobre los datos de series temporales cuando evalúes el modelo en el siguiente paso.
Sigue estos pasos para crear el modelo:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_group` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 5 ) AS SELECT start_station_name, EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` WHERE start_station_name LIKE '%Central Park%' GROUP BY start_station_name, date;
La consulta tarda aproximadamente 24 segundos en completarse, después de lo cual el modelo
nyc_citibike_arima_model_groupaparece en el panel Explorador. Como la consulta usa una declaraciónCREATE MODEL, no ves los resultados.
Esta consulta crea doce modelos de series temporales, uno para cada una de las doce estaciones de inicio de Citi Bike en los datos de entrada. El costo del tiempo, alrededor de 24 segundos, es solo 1.4 veces mayor que el de crear un solo modelo de serie temporal debido al paralelismo. Sin embargo, si quitas la cláusula WHERE ... LIKE ..., habrá más de 600 series temporales para prever y no se preverán por completo en paralelo debido a las limitaciones de capacidad de la ranura. En ese caso, la consulta tardaría aproximadamente 15 minutos en completarse. Para reducir el tiempo de ejecución de la consulta con la vulneración de una posible disminución leve en la calidad del modelo, puedes disminuir el valor de auto_arima_max_order.
Esto reduce el espacio de búsqueda del ajuste de hiperparámetros en el algoritmo auto.ARIMA. Para obtener más información, consulta Large-scale time series forecasting best practices.
Permite trabajar con BigQuery DataFrames.
En el siguiente fragmento, creas un modelo de serie temporal basado en ARIMA.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Esto crea doce modelos de series temporales, uno para cada una de las doce estaciones de inicio de Citi Bike en los datos de entrada. El costo del tiempo, alrededor de 24 segundos, es solo 1.4 veces mayor que el de crear un solo modelo de serie temporal debido al paralelismo.
Evalúa el modelo
SQL
Evalúa el modelo de series temporales con la función ML.ARIMA_EVALUATE. La función ML.ARIMA_EVALUATE te muestra las métricas de evaluación que se generaron para el modelo durante el proceso de ajuste automático de hiperparámetros.
Sigue estos pasos para evaluar el modelo:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`);
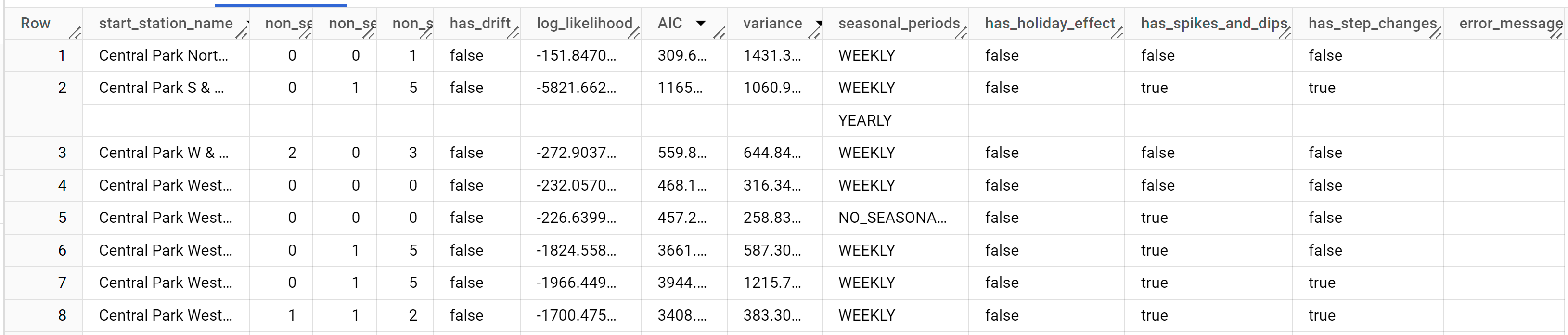
Los resultados deberían verse así:
Si bien
auto.ARIMAevalúa decenas de modelos candidatos de ARIMA para cada serie temporal,ML.ARIMA_EVALUATEde forma predeterminada solo genera la información del mejor modelo a fin de que la tabla de salida sea compacta. Para ver todos los modelos candidatos, puedes configurar el argumentoshow_all_candidate_modelde la funciónML.ARIMA_EVALUATEenTRUE.
Permite trabajar con BigQuery DataFrames.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
La columna start_station_name identifica la columna de datos de entrada para la que se crearon las series temporales. Esta es la columna que especificaste con la opción time_series_id_col cuando creaste el modelo.
Las columnas de salida non_seasonal_p, non_seasonal_d, non_seasonal_q y has_drift definen un modelo ARIMA en la canalización de entrenamiento. Las columnas de salida log_likelihood, AIC y variance son relevantes para el proceso de ajuste del modelo ARIMA.El proceso de ajuste determina el mejor modelo ARIMA con el algoritmo auto.ARIMA, uno para cada serie temporal.
El algoritmo auto.ARIMA usa la prueba de KPSS para determinar el mejor valor de non_seasonal_d, que en este caso es 1. Cuando non_seasonal_d es 1, el algoritmo auto.ARIMA entrena 42 modelos ARIMA candidatos diferentes en paralelo.
En este ejemplo, los 42 modelos candidatos son válidos, por lo que el resultado contiene 42 filas, una para cada modelo ARIMA candidato. En los casos en que algunos de los modelos no son válidos, se excluyen del resultado. Estos modelos candidatos se devuelven en orden ascendente según el AIC. El modelo de la primera fila tiene el AIC más bajo y se considera el mejor modelo. El mejor modelo se guarda como el modelo final y se usa cuando prevés datos, evalúas el modelo y examinas sus coeficientes, como se muestra en los siguientes pasos.
La columna seasonal_periods contiene información sobre el patrón estacional identificado en los datos de series temporales. Cada serie temporal puede tener diferentes patrones estacionales. Por ejemplo, en la figura, puedes ver que una serie temporal tiene un patrón anual, mientras que otras no.
Las columnas has_holiday_effect, has_spikes_and_dips y has_step_changes solo se propagan cuando decompose_time_series=TRUE. Estas columnas también reflejan información sobre los datos de la serie temporal de entrada y no están relacionadas con el modelado ARIMA. Estas columnas también tienen los mismos valores en todas las filas de salida.
Inspecciona los coeficientes del modelo
SQL
Inspecciona los coeficientes del modelo de series temporales con la función ML.ARIMA_COEFFICIENTS.
Sigue estos pasos para recuperar los coeficientes del modelo:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`);
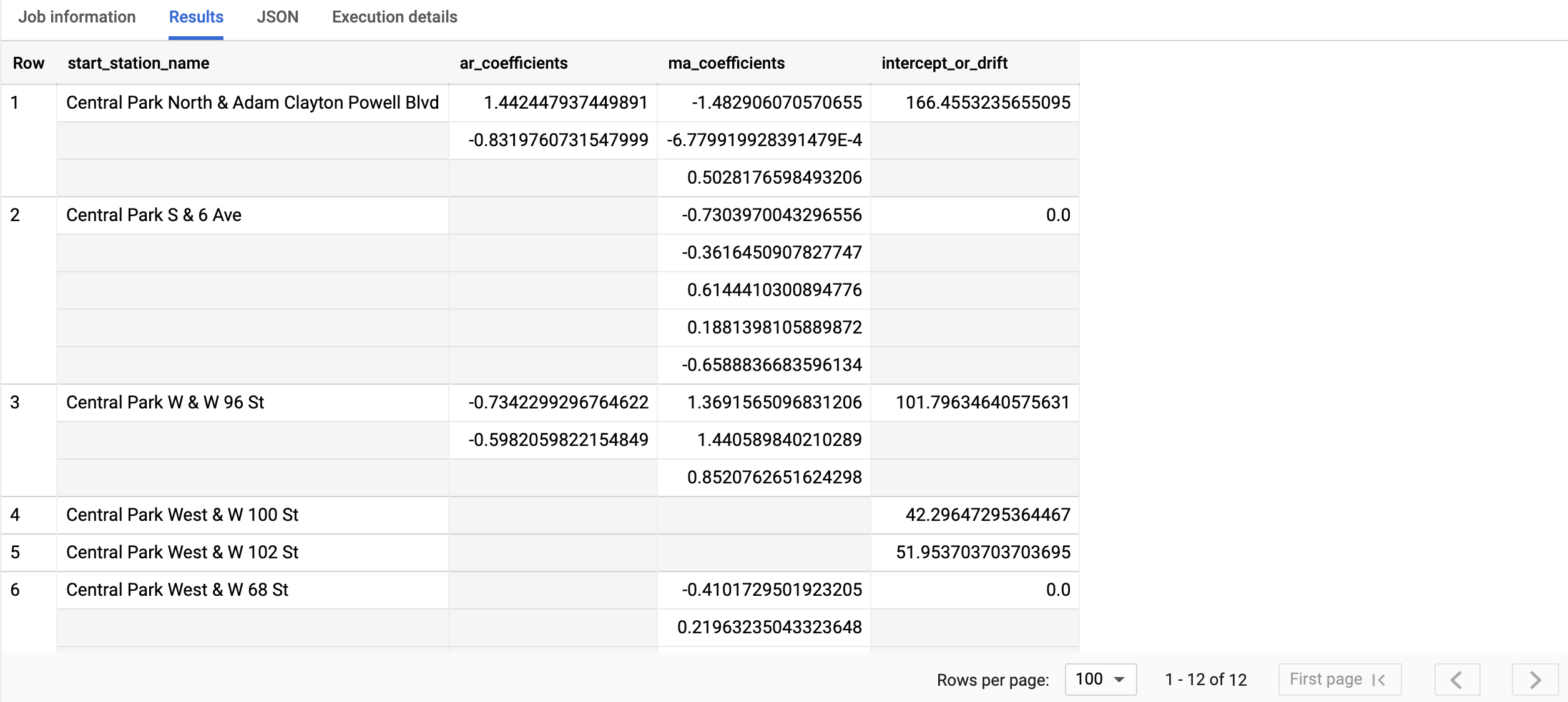
La consulta toma menos de un segundo en completarse. Los resultados debería ser similares al siguiente:
Para obtener más información sobre las columnas de salida, consulta la función
ML.ARIMA_COEFFICIENTS.
Permite trabajar con BigQuery DataFrames.
Inspecciona los coeficientes del modelo de series temporales con la función coef_.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
La columna start_station_name identifica la columna de datos de entrada para la que se crearon las series temporales. Esta es la columna que especificaste en la opción time_series_id_col cuando creaste el modelo.
La columna de salida ar_coefficients muestra los coeficientes del modelo de la parte autorregresiva (AR) del modelo ARIMA. De manera similar, la columna de salida ma_coefficients muestra los coeficientes del modelo de la parte de promedio móvil (MA) del modelo ARIMA. Ambas columnas contienen valores de array, cuyas longitudes son iguales a non_seasonal_p y non_seasonal_q, respectivamente. El valor intercept_or_drift es el término constante en el modelo ARIMA.
Usa el modelo para predecir datos
SQL
Prevé valores de series temporales futuras con la función ML.FORECAST.
En la siguiente consulta de GoogleSQL, la cláusula STRUCT(3 AS horizon, 0.9 AS confidence_level) indica que la consulta prevé 3 puntos futuros y genera un intervalo de predicción con un nivel de confianza del 90%.
Sigue estos pasos para predecir datos con el modelo:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT * FROM ML.FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level))
Haz clic en Ejecutar.
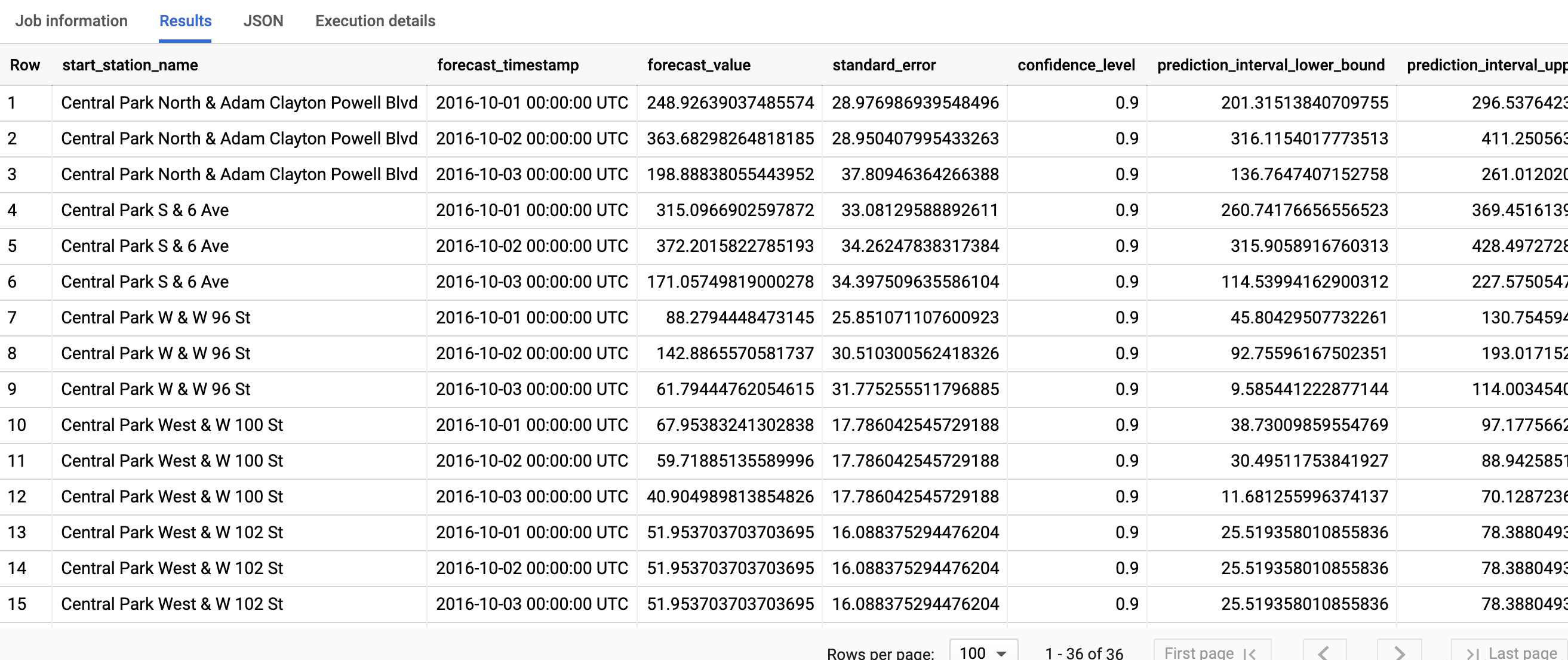
La consulta toma menos de un segundo en completarse. Los resultados deberían verse de la siguiente manera:
Para obtener más información sobre las columnas de salida, consulta la función ML.FORECAST.
Permite trabajar con BigQuery DataFrames.
Prevé valores de series temporales futuras con la función predict.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
start_station_name, la primera columna, anota la serie temporal en la que se ajusta cada modelo de serie temporal. Cada start_station_name tiene tres filas de resultados previstos, como se especifica en el valor de horizon.
Para cada start_station_name, las filas de salida se ordenan cronológicamente según el valor de la columna forecast_timestamp. En la previsión de series temporales, el intervalo de predicción, representado por los valores de las columnas prediction_interval_lower_bound y prediction_interval_upper_bound, es tan importante como el valor de la columna forecast_value. El valor de forecast_value es el punto medio del intervalo de predicción. El intervalo de predicción depende de los valores de las columnas standard_error y confidence_level.
Explica los resultados de la previsión
SQL
Puedes obtener métricas de interpretabilidad además de los datos de previsión con la función ML.EXPLAIN_FORECAST. La función ML.EXPLAIN_FORECAST prevé valores de series temporales futuras y también muestra todos los componentes separados de la serie temporal. Si solo deseas devolver datos de previsión, usa la función ML.FORECAST, como se muestra en Usa el modelo para prever datos.
La cláusula STRUCT(3 AS horizon, 0.9 AS confidence_level) que se usa en la función ML.EXPLAIN_FORECAST indica que la consulta prevé 3 puntos temporales futuros y genera un intervalo de predicción con un 90% de confianza.
Sigue estos pasos para explicar los resultados del modelo:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level));
La consulta toma menos de un segundo en completarse. Los resultados deberían verse de la siguiente manera:


Las primeras miles de filas que se muestran son todos datos históricos. Debes desplazarte por los resultados para ver los datos de previsión.
Las filas de salida se ordenan primero por
start_station_namey, luego, cronológicamente por el valor de la columnatime_series_timestamp. En la previsión de series temporales, el intervalo de predicción, representado por los valores de las columnasprediction_interval_lower_boundyprediction_interval_upper_bound, es tan importante como el valor de la columnaforecast_value. El valor deforecast_valuees el punto medio del intervalo de predicción. El intervalo de predicción depende de los valores de las columnasstandard_erroryconfidence_level.Para obtener más información sobre las columnas de salida, consulta
ML.EXPLAIN_FORECAST.
Permite trabajar con BigQuery DataFrames.
Puedes obtener métricas de interpretabilidad además de los datos de previsión con la función predict_explain. La función predict_explain prevé valores de series temporales futuras y también muestra todos los componentes separados de la serie temporal. Si solo deseas devolver datos de previsión, usa la función predict, como se muestra en Usa el modelo para prever datos.
La cláusula horizon=3, confidence_level=0.9 que se usa en la función predict_explain indica que la consulta prevé 3 puntos temporales futuros y genera un intervalo de predicción con un 90% de confianza.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Las filas de salida se ordenan primero por time_series_timestamp y, luego, cronológicamente por el valor de la columna start_station_name. En la previsión de series temporales, el intervalo de predicción, representado por los valores de las columnas prediction_interval_lower_bound y prediction_interval_upper_bound, es tan importante como el valor de la columna forecast_value. El valor de forecast_value es el punto medio del intervalo de predicción. El intervalo de predicción depende de los valores de las columnas standard_error y confidence_level.
Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
- Puedes borrar el proyecto que creaste.
- De lo contrario, puedes mantener el proyecto y borrar el conjunto de datos.
Borra tu conjunto de datos
Borrar tu proyecto quita todos sus conjuntos de datos y tablas. Si prefieres volver a usar el proyecto, puedes borrar el conjunto de datos que creaste en este instructivo:
Si es necesario, abre la página de BigQuery en la consola deGoogle Cloud .
En el panel de navegación, haz clic en el conjunto de datos bqml_tutorial que creaste.
Haz clic en Borrar conjunto de datos para borrar el conjunto de datos, la tabla y todos los datos.
En el cuadro de diálogo Borrar conjunto de datos, escribe el nombre del conjunto de datos (
bqml_tutorial) para confirmar el comando de borrado y, luego, haz clic en Borrar.
Borra tu proyecto
Para borrar el proyecto, haz lo siguiente:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
¿Qué sigue?
- Aprende a prever una sola serie temporal con un modelo univariable
- Aprende a prever una sola serie temporal con un modelo multivariable
- Obtén más información para escalar un modelo univariado cuando se prevén varias series temporales en muchas filas.
- Aprende a predecir jerárquicamente varias series temporales con un modelo univariable
- Para obtener una descripción general de BigQuery ML, consulta Introducción a la IA y el aprendizaje automático en BigQuery.