En este documento, se describe cómo implementar un mecanismo de exportación para transmitir registros de los recursos deGoogle Cloud a Splunk. Se supone que ya leíste la arquitectura de referencia correspondiente para este caso de uso.
Estas instrucciones están destinadas a administradores de operaciones y seguridad que desean transmitir registros de Google Cloud a Splunk. Debes estar familiarizado con Splunk y el recopilador de eventos HTTP (HEC) de Splunk cuando uses estas instrucciones para operaciones de TI o casos de uso de seguridad. Aunque no es obligatorio, es útil estar familiarizado con las canalizaciones de Dataflow, Pub/Sub, Cloud Logging, Identity and Access Management y Cloud Storage para esta implementación.
Para automatizar los pasos de implementación en esta arquitectura de referencia mediante el uso de la infraestructura como código (IaC), consulta el repositorio de GitHub terraform-splunk-log-export.
Arquitectura
En el siguiente diagrama, se muestra la arquitectura de referencia y se demuestra cómo fluyen los datos de registro de Google Cloud a Splunk.

Como se muestra en el diagrama, Cloud Logging recopila los registros en un receptor de registros a nivel de la organización y los envía a Pub/Sub. El servicio de Pub/Sub crea un solo tema y una suscripción para los registros y los reenvía a la canalización principal de Dataflow. La canalización principal de Dataflow es una canalización de transmisión de Pub/Sub a Splunk que extrae registros de la suscripción a Pub/Sub y los entrega a Splunk. En paralelo a la canalización principal de Dataflow, la canalización secundaria de Dataflow es una canalización de transmisión de Pub/Sub a Pub/Sub para volver a reproducir mensajes si falla una entrega. Al final del proceso, Splunk Enterprise o Splunk Cloud Platform actúan como un extremo de HEC y reciben los registros para un análisis más detallado. Para obtener más información, consulta la sección Arquitectura de la arquitectura de referencia.
Para implementar esta arquitectura de referencia, realiza las siguientes tareas:
- Realiza las tareas de configuración.
- Crear un receptor de registros agregado en un proyecto dedicado.
- Crea un tema de mensajes no entregados.
- Configura un extremo de HEC de Splunk.
- Configura la capacidad de la canalización de Dataflow.
- Exporta registros a Splunk.
- Transforma registros o eventos en tránsito con funciones definidas por el usuario (UDF) dentro de la canalización de Splunk Dataflow.
- Manejar fallas de entrega para evitar la pérdida de datos debido a posibles problemas de red temporales o configuraciones incorrectas.
Antes de comenzar
Completa los siguientes pasos para configurar un entorno para tu arquitectura de referencia deGoogle Cloud a Splunk:
- Abre un proyecto, habilita la facturación y activa las APIs.
- Asigna roles de IAM.
- Configurar el entorno
- Configura redes seguras.
Abre un proyecto, habilita la facturación y activa las APIs
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Monitoring API, Secret Manager, Compute Engine, Pub/Sub, and Dataflow APIs.
Asigna roles de IAM
En la consola de Google Cloud, asegúrate de tener los siguientes permisos de Identity and Access Management (IAM) para los recursos de la organización y del proyecto. Para obtener más información, consulta Otorga, cambia y revoca el acceso a los recursos.
| Permisos | Funciones predefinidas | Recurso |
|---|---|---|
|
|
Organización |
|
|
Proyecto |
|
|
Proyecto |
Si los roles predefinidos de IAM no incluyen suficientes permisos para realizar tus tareas, crea un rol personalizado. Un rol personalizado te dará el acceso que necesitas y te permitirá seguir el principio de menor privilegio.
Configure su entorno
In the Google Cloud console, activate Cloud Shell.
Configura el proyecto para tu sesión activa de Cloud Shell:
gcloud config set project
PROJECT_ID Reemplaza
PROJECT_IDcon el ID del proyecto.
Configura redes seguras
En este paso, configurarás herramientas de redes seguras antes de procesar y exportar registros a Splunk Enterprise.
Crea una red de VPC y una subred:
gcloud compute networks create
NETWORK_NAME --subnet-mode=custom gcloud compute networks subnets createSUBNET_NAME \ --network=NETWORK_NAME \ --region=REGION \ --range=192.168.1.0/24Reemplaza lo siguiente:
NETWORK_NAME: El nombre de tu red.SUBNET_NAME: Es el nombre de tu subred.REGION: Es la región que deseas usar para esta red.
Crea una regla de firewall para que las máquinas virtuales (VMs) de trabajador de Dataflow se comuniquen entre sí:
gcloud compute firewall-rules create allow-internal-dataflow \ --network=
NETWORK_NAME \ --action=allow \ --direction=ingress \ --target-tags=dataflow \ --source-tags=dataflow \ --priority=0 \ --rules=tcp:12345-12346Esta regla permite el tráfico interno entre las VMs de Dataflow que usan los puertos TCP 12345-12346. Además, el servicio de Dataflow establece la etiqueta
dataflow.Crea una puerta de enlace de Cloud NAT:
gcloud compute routers create nat-router \ --network=
NETWORK_NAME \ --region=REGION gcloud compute routers nats create nat-config \ --router=nat-router \ --nat-custom-subnet-ip-ranges=SUBNET_NAME \ --auto-allocate-nat-external-ips \ --region=REGION Habilita el Acceso privado a Google en la subred:
gcloud compute networks subnets update
SUBNET_NAME \ --enable-private-ip-google-access \ --region=REGION
Crear un receptor de registros
En esta sección, crearás el receptor de registros en toda la organización y su destino de Pub/Sub, junto con los permisos necesarios.
En Cloud Shell, crea un tema de Pub/Sub y una suscripción asociada como el destino del receptor de registros nuevo:
gcloud pubsub topics create
INPUT_TOPIC_NAME gcloud pubsub subscriptions create \ --topicINPUT_TOPIC_NAME INPUT_SUBSCRIPTION_NAME Reemplaza lo siguiente:
INPUT_TOPIC_NAME: El nombre del tema de Pub/Sub que se usará como destino del receptor de registros.INPUT_SUBSCRIPTION_NAME: El nombre de la suscripción a Pub/Sub del destino del receptor de registros.
Crea el receptor de registros de la organización:
gcloud logging sinks create
ORGANIZATION_SINK_NAME \ pubsub.googleapis.com/projects/PROJECT_ID /topics/INPUT_TOPIC_NAME \ --organization=ORGANIZATION_ID \ --include-children \ --log-filter='NOT logName:projects/PROJECT_ID /logs/dataflow.googleapis.com'Reemplaza lo siguiente:
ORGANIZATION_SINK_NAME: El nombre de tu receptor en la organizaciónORGANIZATION_ID: El ID de tu organización.
El comando consta de las siguientes marcas:
- La marca
--organizationespecifica que este es un receptor de registros a nivel de la organización. - La marca
--include-childrenes obligatoria y garantiza que el receptor de registros a nivel de la organización incluya todos los registros en todas las subcarpetas y proyectos. - La marca
--log-filterespecifica los registros que se deben enrutar. En este ejemplo, excluyes los registros de operaciones de Dataflow específicamente para el proyectoPROJECT_ID, ya que la canalización de exportación de registros de Dataflow genera más registros a medida que procesa los registros. El filtro evita que la canalización exporte sus propios registros, lo que evita un ciclo exponencial potencial. El resultado incluye una cuenta de servicio en el formatoo#####-####@gcp-sa-logging.iam.gserviceaccount.com.
Otorga el rol de IAM de publicador de Pub/Sub a la cuenta de servicio del receptor de registros en el tema de Pub/Sub
INPUT_TOPIC_NAME. Este rol permite que la cuenta de servicio del receptor de registros publique mensajes en el tema.gcloud pubsub topics add-iam-policy-binding
INPUT_TOPIC_NAME \ --member=serviceAccount:LOG_SINK_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com \ --role=roles/pubsub.publisherReemplaza
LOG_SINK_SERVICE_ACCOUNTpor el nombre de la cuenta de servicio de tu destino de registro.
Crea un tema de mensajes no entregados
Para evitar la posible pérdida de datos que se produce cuando no se entrega un mensaje, debes crear un tema de mensajes no entregados de Pub/Sub y la suscripción correspondiente. El mensaje con errores se almacena en el tema de mensajes no entregados hasta que un operador o ingeniero de confiabilidad de sitios pueda investigar y corregir la falla. Para obtener más información, consulta la sección Vuelve a reproducir mensajes con errores de la arquitectura de referencia.
En Cloud Shell, crea un tema y una suscripción de mensajes no entregados de Pub/Sub para evitar la pérdida de datos mediante el almacenamiento de cualquier mensaje no entregado:
gcloud pubsub topics create
DEAD_LETTER_TOPIC_NAME gcloud pubsub subscriptions create --topicDEAD_LETTER_TOPIC_NAME DEAD_LETTER_SUBSCRIPTION_NAME Reemplaza lo siguiente:
DEAD_LETTER_TOPIC_NAME: El nombre del tema de Pub/Sub que será el tema de los mensajes no entregadosDEAD_LETTER_SUBSCRIPTION_NAME: El nombre de la suscripción a Pub/Sub para el tema de mensajes no entregados.
Configura un extremo de HEC de Splunk
En los siguientes procedimientos, configurarás un extremo de HEC de Splunk y almacenarás el token de HEC recién creado como un secreto en Secret Manager. Cuando implementes la canalización de Splunk Dataflow, debes proporcionar la URL del extremo y el token.
Configura el HEC de Splunk
- Si todavía no tienes un extremo de HEC de Splunk, consulta la documentación de Splunk para obtener información sobre cómo configurar el HEC de Splunk. El HEC de Splunk se ejecuta en el servicio de Splunk Cloud Platform o en tu propia instancia de Splunk Enterprise. Mantén inhabilitada la opción de acuse de recibo del indexador de HEC de Splunk, ya que Splunk Dataflow no la admite.
- En Splunk, después de crear un token de HEC de Splunk, copia el valor del token.
- En Cloud Shell, guarda el valor del token del HEC de Splunk en un archivo temporal llamado
splunk-hec-token-plaintext.txt.
Almacena el token HEC de Splunk en Secret Manager
En este paso, crearás un secreto y una sola versión subyacente de secreto en la que almacenarás el valor del token de HEC de Splunk.
En Cloud Shell, crea un secreto para que contenga tu token del HEC de Splunk:
gcloud secrets create hec-token \ --replication-policy="automatic"
Para obtener más información sobre las políticas de replicación de secretos, consulta Elige una política de replicación.
Agrega el token como una versión secreta con el contenido del archivo
splunk-hec-token-plaintext.txt:gcloud secrets versions add hec-token \ --data-file="./splunk-hec-token-plaintext.txt"
Borra el archivo
splunk-hec-token-plaintext.txt, ya que ya no es necesario.
Configura la capacidad de la canalización de Dataflow
En la siguiente tabla, se resumen las prácticas recomendadas generales para configurar la configuración de capacidad de la canalización de Dataflow:
| Parámetro de configuración | Prácticas recomendadas generales |
|---|---|
Marca |
Configurarlo como tamaño de máquina de referencia |
Marca |
Configurarlo como la cantidad máxima de trabajadores necesarios para manejar el EPS máximo previsto según tus cálculos |
Parámetro |
Configúralo en 2 × CPUs virtuales/trabajador × la cantidad máxima de trabajadores para maximizar la cantidad de conexiones de HEC paralelas de Splunk |
|
Configurarlo como 10 a 50 eventos o solicitudes para registros, siempre que la demora máxima del almacenamiento en búfer de dos segundos sea aceptable |
Recuerda usar tus propios valores y cálculos únicos cuando implementes esta arquitectura de referencia en tu entorno.
Establece los valores para el tipo y la cantidad de máquinas. Si deseas calcular los valores apropiados para tu entorno de nube, consulta las secciones Tipo de máquina y Recuento de máquinas de la arquitectura de referencia.
DATAFLOW_MACHINE_TYPE DATAFLOW_MACHINE_COUNT Establece los valores para el paralelismo de Dataflow y el recuento de lotes. Para calcular los valores apropiados para tu entorno de nube, consulta las secciones Paralelismo y Recuento por lotes de la arquitectura de referencia.
JOB_PARALLELISM JOB_BATCH_COUNT
Para obtener más información sobre cómo calcular los parámetros de capacidad de canalización de Dataflow, consulta la sección Consideraciones sobre el diseño de optimización de costos y el rendimiento de la arquitectura de referencia.
Exporta registros mediante la canalización de Dataflow
En esta sección, implementarás la canalización de Dataflow con los siguientes pasos:
- Crea un bucket de Cloud Storage y una cuenta de servicio de trabajador de Dataflow.
- Otorga roles y acceso a la cuenta de servicio de trabajador de Dataflow.
- Implementa la canalización de Dataflow.
- Visualiza registros en Splunk.
La canalización entrega Google Cloud mensajes de registro al HEC de Splunk.
Crea un bucket de Cloud Storage y una cuenta de servicio de trabajador de Dataflow
En Cloud Shell, crea un bucket nuevo de Cloud Storage con una configuración de acceso uniforme a nivel de bucket:
gcloud storage buckets create gs://
PROJECT_ID -dataflow/ --uniform-bucket-level-accessEl bucket de Cloud Storage que acabas de crear es donde la tarea de Dataflow habilita por etapas los archivos temporales.
En Cloud Shell, crea una cuenta de servicio para los trabajadores de Dataflow:
gcloud iam service-accounts create
WORKER_SERVICE_ACCOUNT \ --description="Worker service account to run Splunk Dataflow jobs" \ --display-name="Splunk Dataflow Worker SA"Reemplaza
WORKER_SERVICE_ACCOUNTpor el nombre que deseas usar para la cuenta de servicio del trabajador de Dataflow.
Otorga roles y acceso a la cuenta de servicio de trabajador de Dataflow
En esta sección, otorga los roles necesarios a la cuenta de servicio de trabajador de Dataflow, como se muestra en la siguiente tabla.
| Rol | Ruta de acceso | Objetivo |
|---|---|---|
| Administrador de Dataflow |
|
Habilita la cuenta de servicio para que actúe como administrador de Dataflow. |
| Trabajador de Dataflow |
|
Habilita la cuenta de servicio para que actúe como un trabajador de Dataflow. |
| Administrador de objetos de Storage |
|
Habilita la cuenta de servicio para acceder al bucket de Cloud Storage que usa Dataflow para los archivos de etapa de pruebas. |
| Publicador de Pub/Sub |
|
Habilita la cuenta de servicio para que publique mensajes con errores en el tema de mensajes no entregados de Pub/Sub. |
| Suscriptor de Pub/Sub |
|
Habilita la cuenta de servicio para que acceda a la suscripción de entrada. |
| Visualizador de Pub/Sub |
|
Habilita la cuenta de servicio para que vea la suscripción. |
| Usuario con acceso a secretos de Secret Manager |
|
Habilita la cuenta de servicio para que acceda al secreto que contiene el token de HEC de Splunk. |
En Cloud Shell, otorga a la cuenta de servicio de trabajador de Dataflow los roles de administrador de Dataflow y trabajador de Dataflow que necesita esta cuenta para ejecutar las operaciones de trabajo de Dataflow y las tareas de administración:
gcloud projects add-iam-policy-binding
PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com" \ --role="roles/dataflow.admin"gcloud projects add-iam-policy-binding
PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com" \ --role="roles/dataflow.worker"Otorga acceso a la cuenta de servicio de trabajador de Dataflow para ver y consumir mensajes de la suscripción de entrada de Pub/Sub:
gcloud pubsub subscriptions add-iam-policy-binding
INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com" \ --role="roles/pubsub.subscriber"gcloud pubsub subscriptions add-iam-policy-binding
INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com" \ --role="roles/pubsub.viewer"Otorga acceso a la cuenta de servicio de trabajador de Dataflow para publicar cualquier mensaje con errores en el tema no procesado de Pub/Sub:
gcloud pubsub topics add-iam-policy-binding
DEAD_LETTER_TOPIC_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com" \ --role="roles/pubsub.publisher"Otorga a la cuenta de servicio de trabajador de Dataflow acceso al secreto del token de HEC de Splunk en Secret Manager:
gcloud secrets add-iam-policy-binding hec-token \ --member="serviceAccount:
WORKER_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com" \ --role="roles/secretmanager.secretAccessor"Otorga a la cuenta de servicio del trabajador de Dataflow acceso de lectura y escritura al bucket de Cloud Storage que usará el trabajo de Dataflow para los archivos de etapa de pruebas:
gcloud storage buckets add-iam-policy-binding gs://
PROJECT_ID -dataflow/ \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com" --role=”roles/storage.objectAdmin”
Implementa la canalización de Dataflow
En Cloud Shell, configura la siguiente variable de entorno para la URL de HEC de Splunk:
export SPLUNK_HEC_URL=
SPLUNK_HEC_URL Reemplaza la variable
SPLUNK_HEC_URLcon el formularioprotocol://host[:port], en el que se cumple lo siguiente:protocoleshttpohttps.hostes el nombre de dominio completamente calificado (FQDN) o la dirección IP de tu instancia de HEC de Splunk o, si tienes varias instancias de HEC, el balanceador de cargas HTTP(S) asociado (o basado en DNS).portes el número de puerto HEC. Es opcional y depende de la configuración del extremo del HEC de Splunk.
Un ejemplo de una entrada de URL de HEC válida de Splunk es
https://splunk-hec.example.com:8088. Si envías datos a HEC en Splunk Cloud Platform, consulta Enviar datos a HEC en Splunk Cloud para determinar las partes anterioreshostyportde tu URL específica de HEC de Splunk.La URL de HEC de Splunk no debe incluir la ruta de acceso del extremo HEC, por ejemplo,
/services/collector. Actualmente, la plantilla de Dataflow de Pub/Sub a Splunk solo admite el extremo/services/collectorpara eventos con formato JSON y agrega automáticamente esa ruta a la entrada de URL de HEC de Splunk. Para obtener más información sobre ese extremo del HEC, consulta la documentación de Splunk para services/collector endpoint.Implementa la canalización de Dataflow con la plantilla de Dataflow de Pub/Sub a Splunk:
gcloud beta dataflow jobs run
JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --staging-location=gs://PROJECT_ID -dataflow/temp/ \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION /subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID /subscriptions/INPUT_SUBSCRIPTION_NAME ,\ outputDeadletterTopic=projects/PROJECT_ID /topics/DEAD_LETTER_TOPIC_NAME ,\ url=SPLUNK_HEC_URL ,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID /secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT ,\ parallelism=JOB_PARALLELISM ,\ javascriptTextTransformGcsPath=gs://splk-public/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=processReemplaza
JOB_NAMEpor el formato de nombrepubsub-to-splunk-date+"%Y%m%d-%H%M%S".Los parámetros opcionales
javascriptTextTransformGcsPathyjavascriptTextTransformFunctionNameespecifican una UDF de muestra disponible públicamente:gs://splk-public/js/dataflow_udf_messages_replay.js. La UDF de muestra incluye ejemplos de código para la transformación de eventos y la lógica de decodificación que usas para volver a reproducir las publicaciones con errores. Para obtener más información sobre las UDF, consulta Transforma eventos en tránsito con UDF.Una vez que se complete el trabajo de canalización, busca el ID de trabajo nuevo en el resultado, cópialo y guárdalo. Ingresarás este ID de trabajo en un paso posterior.
Visualiza registros en Splunk
Los trabajadores de la canalización de Dataflow tardan unos minutos en aprovisionarse y estar listos para entregar los registros al HEC de Splunk. Puedes confirmar que los registros se reciben y se indexan correctamente en la interfaz de búsqueda de Splunk Enterprise o Splunk Cloud Platform. Para ver la cantidad de registros por tipo de recurso supervisado, sigue estos pasos:
En Splunk, abre Informes y búsqueda de Splunk.
Ejecuta el
index=[MY_INDEX] | stats count by resource.typede búsqueda donde se configura el índiceMY_INDEXpara tu token del HEC de Splunk: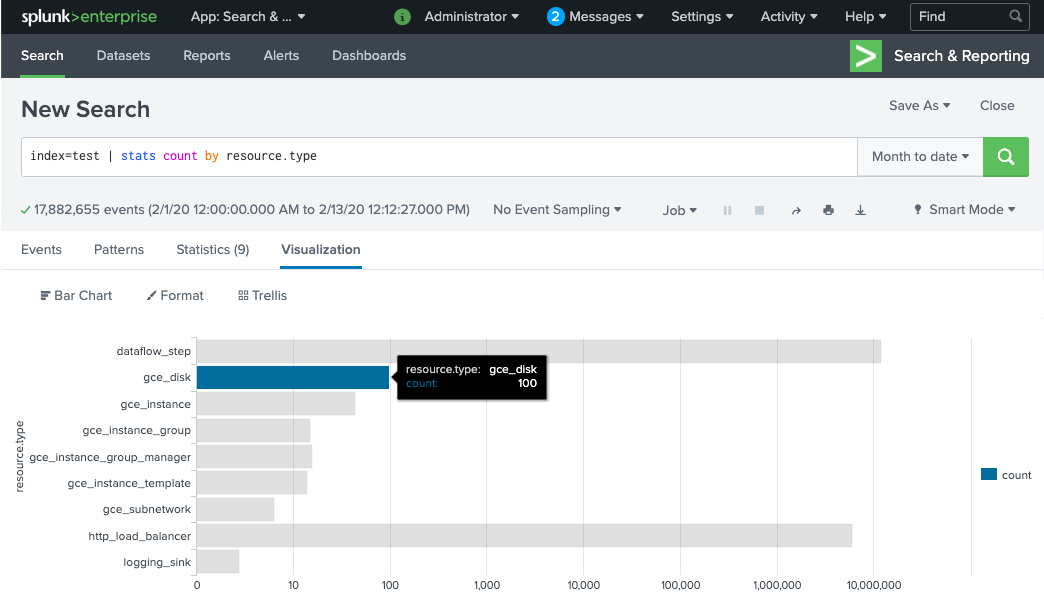
Si no ves ningún evento, consulta Controla los errores en la entrega.
Transforma eventos en tránsito con UDF
La plantilla de Dataflow de Pub/Sub a Splunk admite una UDF de JavaScript para la transformación de eventos personalizados, como agregar campos nuevos o configurar metadatos de HEC de Splunk según el evento. La canalización que implementaste usa esta UDF de muestra.
En esta sección, editarás primero la función UDF de muestra para agregar un nuevo campo de evento. En este campo nuevo, se especifica el valor de la suscripción de Pub/Sub de origen como información contextual adicional. Luego, actualizarás la canalización de Dataflow con la UDF modificada.
Modifica la UDF de muestra
En Cloud Shell, descarga el archivo JavaScript que contiene la función UDF de muestra:
wget https://storage.googleapis.com/splk-public/js/dataflow_udf_messages_replay.js
En el editor de texto que prefieras, abre el archivo JavaScript, busca el campo
event.inputSubscription, quita el comentario de esa línea y reemplazasplunk-dataflow-pipelineporINPUT_SUBSCRIPTION_NAME:event.inputSubscription = "
INPUT_SUBSCRIPTION_NAME ";Guarda el archivo.
Sube el archivo al bucket de Cloud Storage.
gcloud storage cp ./dataflow_udf_messages_replay.js gs://
PROJECT_ID -dataflow/js/
Actualiza la canalización de Dataflow con la UDF nueva
En Cloud Shell, detén la canalización con la Opción de desvío para asegurarte de que no se pierdan los registros que ya se extrajeron de Pub/Sub:
gcloud dataflow jobs drain
JOB_ID --region=REGION Ejecuta el trabajo de canalización de Dataflow con la UDF actualizada.
gcloud beta dataflow jobs run
JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION /subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID /subscriptions/INPUT_SUBSCRIPTION_NAME ,\ outputDeadletterTopic=projects/PROJECT_ID /topics/DEAD_LETTER_TOPIC_NAME ,\ url=SPLUNK_HEC_URL ,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID /secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT ,\ parallelism=JOB_PARALLELISM ,\ javascriptTextTransformGcsPath=gs://PROJECT_ID -dataflow/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=processReemplaza
JOB_NAMEpor el formato de nombrepubsub-to-splunk-date+"%Y%m%d-%H%M%S".
Controla los errores en la entrega
Los errores en la entrega pueden ocurrir debido a errores en el procesamiento de eventos o la conexión con el HEC de Splunk. En esta sección, ingresarás una falla de entrega para demostrar el flujo de trabajo de manejo de errores. También aprenderás a ver y activar la entrega de los mensajes con errores a Splunk.
Activa errores en la entrega
Para ingresar una falla de entrega de forma manual en Splunk, haz lo siguiente:
- Si ejecutas una sola instancia, detén el servidor de Splunk para provocar errores de conexión.
- Inhabilita el token de HEC correspondiente de tu configuración de entrada de Splunk.
Solución de problemas de los mensajes con errores
Para investigar un mensaje con errores, puedes usar la consola de Google Cloud:
En la consola de Google Cloud, ve a la página Suscripciones de Pub/Sub.
Haz clic en la suscripción no procesada que creaste. Si usaste el ejemplo anterior, el nombre de la suscripción es:
projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME.Para abrir el visualizador de mensajes, haz clic en Ver mensajes.
Para ver los mensajes, haz clic en Extraer y asegúrate de dejar en blanco la opción Habilitar mensajes de confirmación.
Inspecciona los mensajes con errores. Presta atención a lo siguiente:
- La carga útil del evento de Splunk en la columna
Message body. - El mensaje de error en la columna
attribute.errorMessage. - La marca de tiempo del error en la columna
attribute.timestamp.
- La carga útil del evento de Splunk en la columna
En la siguiente captura de pantalla, se muestra un ejemplo de un mensaje de error que recibes si el extremo del HEC de Splunk está fuera de servicio temporalmente o no se puede acceder a él. Observa que el texto del atributo errorMessage dice The target server failed to respond.
El mensaje también muestra la marca de tiempo asociada con cada falla. Puedes usar esta marca de tiempo para solucionar la causa raíz de la falla.
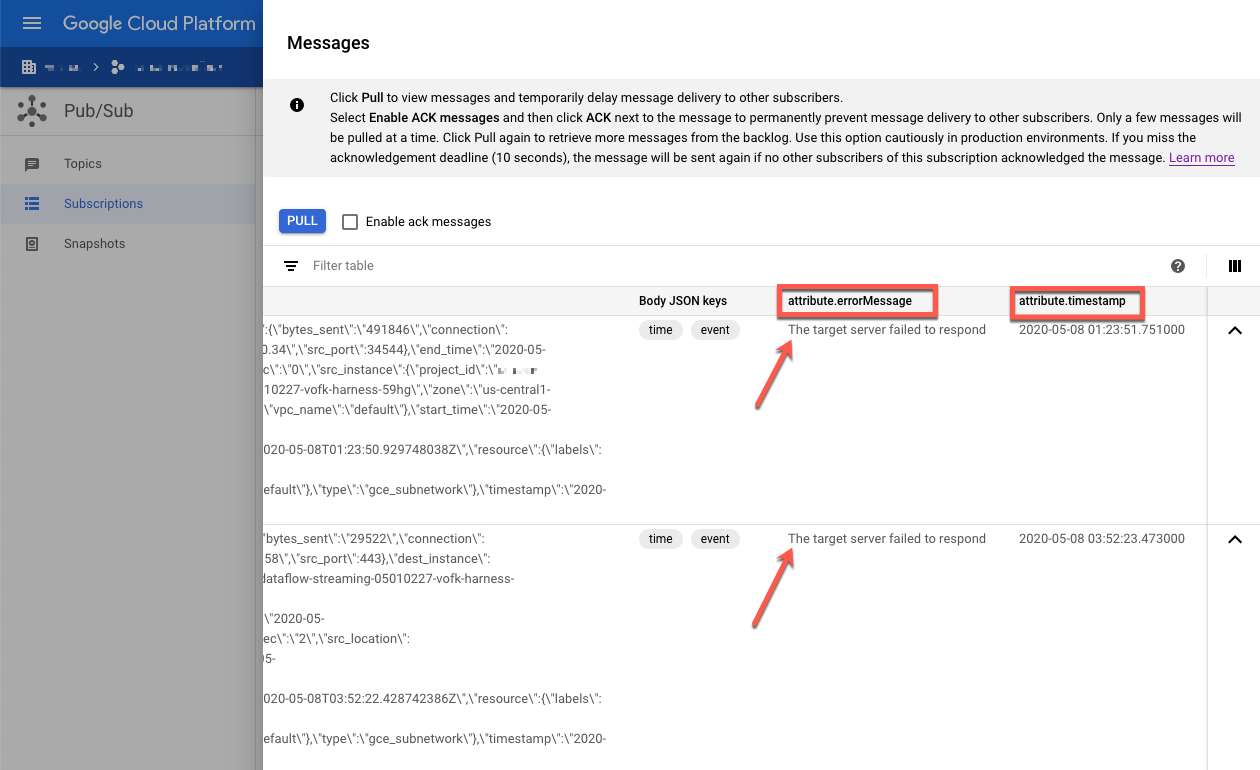
Vuelve a reproducir mensajes con errores
En esta sección, debes reiniciar el servidor de Splunk o habilitar el extremo del HEC de Splunk para corregir el error de entrega. Luego, puedes volver a reproducir los mensajes no procesados.
En Splunk, usa uno de los siguientes métodos para restablecer la conexión conGoogle Cloud:
- Si detuviste el servidor de Splunk, reinicia el servidor.
- Si inhabilitaste el extremo del HEC de Splunk en la sección Activa errores en la entrega, verifica que el extremo del HEC de Splunk ahora funcione.
En Cloud Shell, toma una instantánea de la suscripción no procesada antes de volver a procesar los mensajes de esta suscripción. La instantánea evita la pérdida de mensajes si hay un error de configuración inesperado.
gcloud pubsub snapshots create
SNAPSHOT_NAME \ --subscription=DEAD_LETTER_SUBSCRIPTION_NAME Reemplaza
SNAPSHOT_NAMEpor un nombre que te ayude a identificar la instantánea, comodead-letter-snapshot-date+"%Y%m%d-%H%M%S.Usa la plantilla de Dataflow de Pub/Sub a Splunk para crear una canalización de Pub/Sub a Pub/Sub. La canalización usa otro trabajo de Dataflow para transferir los mensajes de la suscripción no procesada al tema de entrada.
DATAFLOW_INPUT_TOPIC="
INPUT_TOPIC_NAME " DATAFLOW_DEADLETTER_SUB="DEAD_LETTER_SUBSCRIPTION_NAME " JOB_NAME=splunk-dataflow-replay-date +"%Y%m%d-%H%M%S" gcloud dataflow jobs runJOB_NAME \ --gcs-location= gs://dataflow-templates/latest/Cloud_PubSub_to_Cloud_PubSub \ --worker-machine-type=n2-standard-2 \ --max-workers=1 \ --region=REGION \ --parameters \ inputSubscription=projects/PROJECT_ID /subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME ,\ outputTopic=projects/PROJECT_ID /topics/INPUT_TOPIC_NAME Copia el ID de trabajo de Dataflow del resultado del comando y guárdalo para usarlo más adelante. Ingresarás este ID de trabajo como
REPLAY_JOB_IDcuando vacíes tu trabajo de Dataflow.En la consola de Google Cloud, ve a la página Suscripciones de Pub/Sub.
Selecciona la suscripción no procesada. Confirma que el gráfico Recuento de mensajes sin confirmar sea 0, como se muestra en la siguiente captura de pantalla.
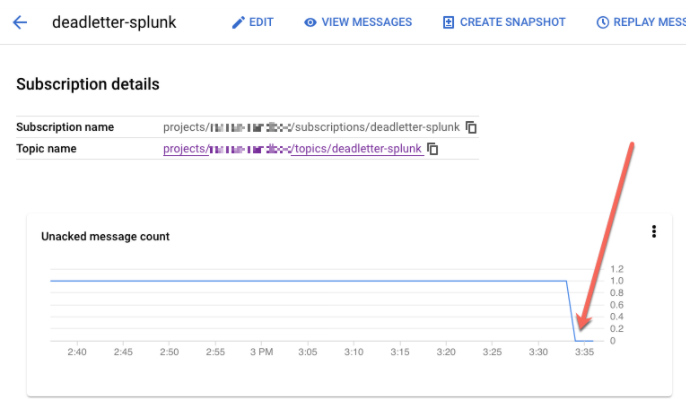
En Cloud Shell, desvía el trabajo de Dataflow que creaste:
gcloud dataflow jobs drain
REPLAY_JOB_ID --region=REGION Reemplaza
REPLAY_JOB_IDpor el ID de trabajo de Dataflow que guardaste antes.
Cuando los mensajes se transfieren de vuelta al tema de entrada original, la canalización principal de Dataflow recoge de forma automática los mensajes con errores y los vuelve a entregar a Splunk.
Confirma mensajes en Splunk
Para confirmar que los mensajes se volvieron a entregar, en Splunk abre Informes y búsqueda de Splunk
Realiza una búsqueda de
delivery_attempts > 1. Este es un campo especial que la UDF de muestra agrega a cada evento para realizar un seguimiento de la cantidad de intentos de entrega. Asegúrate de expandir el intervalo de tiempo de búsqueda para incluir eventos que pueden haber ocurrido antes, ya que la marca de tiempo del evento es la hora original de creación, no la hora de la indexación.
En la siguiente captura de pantalla, los dos mensajes que originalmente fallaron se entregaron y se indexaron de forma correcta en Splunk con la marca de tiempo correcta.
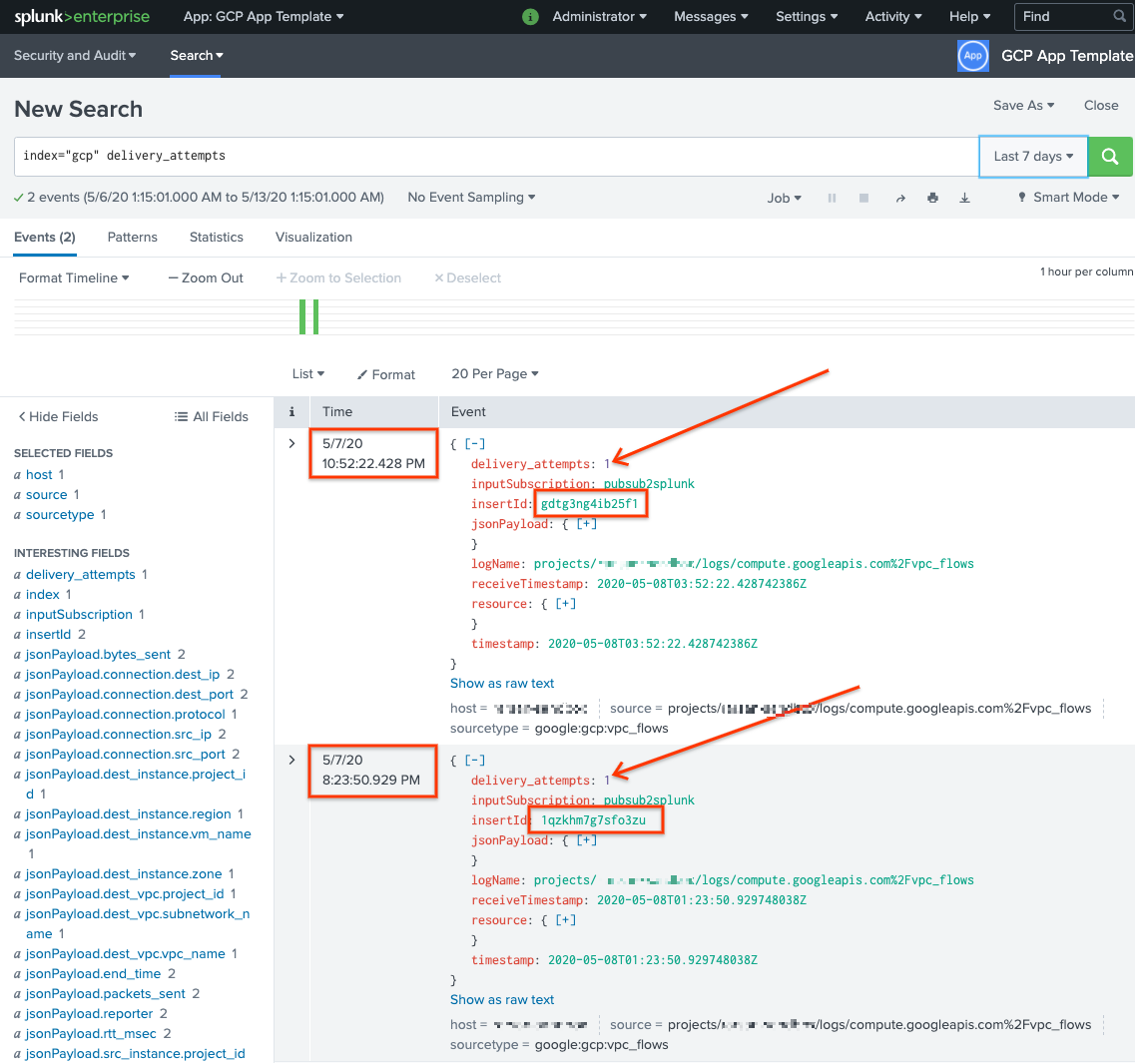
Ten en cuenta que el valor del campo insertId es el mismo que el valor que aparece en los mensajes con errores cuando ves la suscripción no procesada.
El campo insertId es un identificador único que Cloud Logging asigna a la entrada de registro original. El insertId también aparece en el cuerpo del mensaje de Pub/Sub.
Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en esta arquitectura de referencia, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra el receptor a nivel de organización
- Usa el siguiente comando para borrar el receptor de registros a nivel de la organización:
gcloud logging sinks delete
ORGANIZATION_SINK_NAME --organization=ORGANIZATION_ID
Borra el proyecto
Con el receptor de registros borrado, puedes continuar con la eliminación de recursos creados para recibir y exportar registros. La manera más fácil es borrar el proyecto que creaste para la arquitectura de referencia.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
¿Qué sigue?
- Para obtener una lista completa de los parámetros de la plantilla de Pub/Sub a Splunk Dataflow, consulta la documentación de Pub/Sub a Splunk Dataflow.
- Para que las plantillas de Terraform correspondientes te ayuden a implementar esta arquitectura de referencia, consulta el repositorio de GitHub
terraform-splunk-log-export. Incluye un panel precompilado de Cloud Monitoring para supervisar tu canalización de Splunk Dataflow. - Para obtener más información sobre las métricas personalizadas y el registro de Dataflow de Splunk para ayudarte a supervisar y solucionar problemas de las canalizaciones de Dataflow de Splunk, consulta este blog Nuevas funciones de observabilidad para las canalizaciones de transmisión de Splunk Dataflow.
- Para obtener más información sobre las arquitecturas de referencia, los diagramas y las prácticas recomendadas, explora Cloud Architecture Center.