Migration von Snowflake zu BigQuery: Übersicht
In diesem Dokument wird beschrieben, wie Sie Ihre Daten von Snowflake zu BigQuery migrieren.
Ein allgemeines Framework für die Migration von anderen Data Warehouses zu BigQuery finden Sie unter Übersicht: Data Warehouses zu BigQuery migrieren.
Migration von Snowflake zu BigQuery: Übersicht
Für eine Snowflake-Migration empfehlen wir, eine Migrationsarchitektur einzurichten, die vorhandene Vorgänge nur minimal beeinflusst. Das folgende Beispiel zeigt eine Architektur, in der Sie Ihre vorhandenen Tools und Prozesse wiederverwenden können, während Sie andere Arbeitslasten zu BigQuery verlagern.
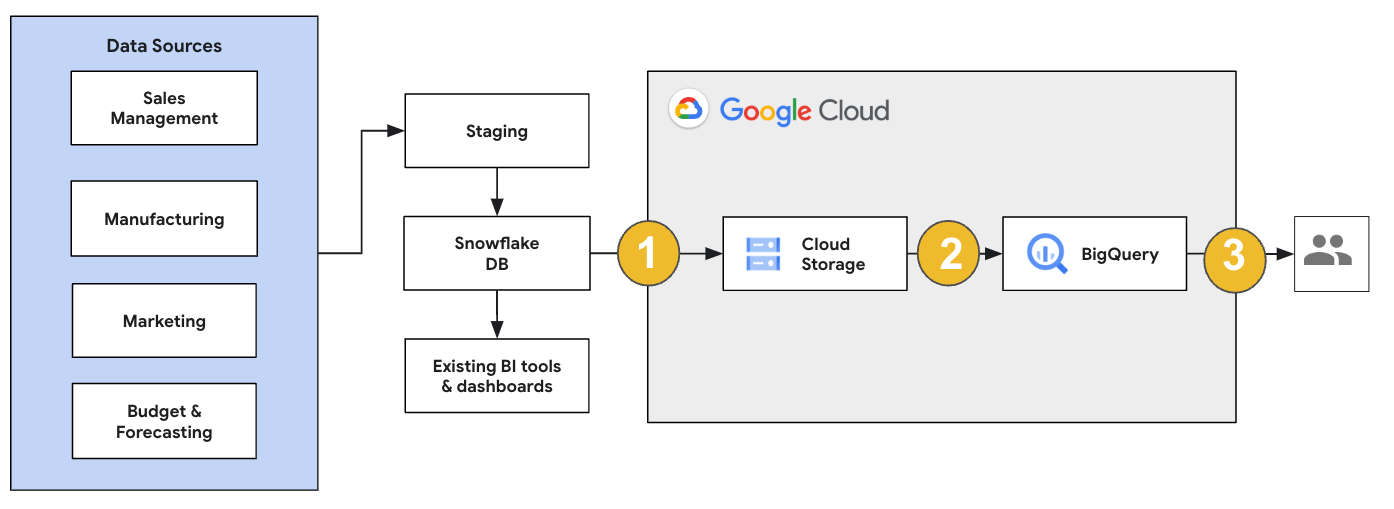
Sie können Berichte und Dashboards auch mit alten Versionen validieren. Weitere Informationen finden Sie unter Data Warehouses zu BigQuery migrieren: Überprüfen und Validieren.
Einzelne Arbeitslasten migrieren
Bei der Planung der Snowflake-Migration empfehlen wir, die folgenden Arbeitslasten einzeln in der folgenden Reihenfolge zu migrieren:
Schema migrieren
Beginnen Sie damit, die erforderlichen Schemas aus Ihrer Snowflake-Umgebung in BigQuery zu replizieren. Wir empfehlen, den BigQuery Migration Service zu verwenden, um Ihr Schema zu migrieren. Der BigQuery Migration Service unterstützt eine Vielzahl von Datenmodell-Designmustern, z. B. Sternschema oder Schneeflockenschema. Dadurch müssen Sie Ihre Upstream-Datenpipelines nicht für ein neues Schema aktualisieren. Der BigQuery-Migrationsdienst bietet auch eine automatisierte Schemamigration, einschließlich Funktionen zum Extrahieren und Übersetzen von Schemas, um den Migrationsprozess zu optimieren.
SQL-Abfragen migrieren
Für die Migration Ihrer SQL-Abfragen bietet der BigQuery-Migrationsdienst verschiedene SQL-Übersetzungsfunktionen, um die Konvertierung Ihrer Snowflake-SQL-Abfragen in GoogleSQL-SQL zu automatisieren. Dazu gehören der Batch-SQL-Übersetzer zum Übersetzen von Abfragen im Bulk, der interaktive SQL-Übersetzer zum Übersetzen einzelner Abfragen und die SQL Translation API. Diese Übersetzungsdienste umfassen auch Gemini-basierte Funktionen, um die Migration von SQL-Abfrage weiter zu vereinfachen.
Prüfen Sie die übersetzten SQL-Abfragen sorgfältig, um sicherzustellen, dass Datentypen und Tabellenstrukturen korrekt behandelt werden. Dazu empfehlen wir, eine Vielzahl von Testläufen mit verschiedenen Szenarien und Daten zu erstellen. Führen Sie diese Testläufe dann in BigQuery aus, um die Ergebnisse mit den ursprünglichen Snowflake-Ergebnissen zu vergleichen. Wenn es Unterschiede gibt, analysieren und beheben Sie die konvertierten Abfragen.
Daten migrieren
Es gibt mehrere Möglichkeiten, Ihre Datenmigrationspipeline einzurichten, um Ihre Daten in BigQuery zu übertragen. Im Allgemeinen folgen diese Pipelines demselben Muster:
Daten aus der Quelle extrahieren: Kopieren Sie die extrahierten Dateien aus der Quelle in den Staging-Speicher in Ihrer lokalen Umgebung. Weitere Informationen finden Sie unter Data Warehouses zu BigQuery migrieren: Quelldaten extrahieren.
Daten in einen Cloud Storage-Staging-Bucket übertragen: Nachdem Sie Daten aus Ihrer Quelle extrahiert haben, übertragen Sie sie in einen temporären Bucket in Cloud Storage. Je nach der übertragenen Datenmenge und der verfügbaren Netzwerkbandbreite haben Sie mehrere Optionen.
Es ist wichtig, dass sich der Speicherort Ihres BigQuery-Datasets und Ihrer externen Datenquelle oder Ihres Cloud Storage-Bucket in derselben Region befinden.
Daten aus dem Cloud Storage-Bucket in BigQuery laden:Ihre Daten befinden sich jetzt in einem Cloud Storage-Bucket. Es gibt verschiedene Möglichkeiten, die Daten in BigQuery hochzuladen. Diese Optionen hängen davon ab, wie stark die Daten transformiert werden müssen. Alternativ können Sie Ihre Daten in BigQuery mithilfe des ELT-Ansatzes transformieren.
Wenn Sie mehrere Daten aus einer JSON-Datei, einer Avro-Datei oder einer CSV-Datei importieren, erkennt BigQuery das Schema automatisch. Sie müssen es also nicht vordefinieren. Eine detaillierte Übersicht über den Schemamigrationsprozess für EDW-Arbeitslasten finden Sie unter Schema- und Datenmigrationsprozess.
Eine Liste der Tools, die eine Snowflake-Datenmigration unterstützen, finden Sie unter Migrationstools.
End-to-End-Beispiele für die Einrichtung einer Snowflake-Datenmigrationspipeline finden Sie unter Beispiele für Snowflake-Migrationspipelines.
Schema und Abfragen optimieren
Nach der Schemamigration können Sie die Leistung testen und anhand der Ergebnisse Optimierungen vornehmen. Sie können beispielsweise die Partitionierung einführen, um die Daten effizienter zu verwalten und abzufragen. Mit der Tabellenpartitionierung können Sie die Abfrageleistung und die Kostenkontrolle durch Partitionierung nach Aufnahmezeit, Zeitstempel oder Ganzzahlbereich verbessern. Weitere Informationen finden Sie unter Einführung in partitionierte Tabellen.
Geclusterte Tabellen sind eine weitere Schemaoptimierung. Sie können Ihre Tabellen clustern, um Tabellendaten anhand des Inhalts im Tabellenschema zu organisieren. Dadurch wird die Leistung von Abfragen mit Filterklauseln oder Abfragen, die Daten aggregieren, verbessert. Weitere Informationen finden Sie unter Einführung in geclusterte Tabellen.
Unterstützte Datentypen, Attribute und Dateiformate
Snowflake und BigQuery unterstützen größtenteils dieselben Datentypen, obwohl sie manchmal unterschiedliche Namen verwenden. Eine vollständige Liste der unterstützten Datentypen in Snowflake und BigQuery finden Sie unter Datentypen. Sie können auch SQL-Übersetzungstools wie den interaktiven SQL-Übersetzer, die SQL Translation API oder den Batch-SQL-Übersetzer verwenden, um verschiedene SQL-Dialekte in GoogleSQL zu übersetzen.
Weitere Informationen zu unterstützten Datentypen in BigQuery finden Sie unter GoogleSQL-Datentypen.
Snowflake kann Daten in den folgenden Dateiformaten exportieren. Sie können die folgenden Formate direkt in BigQuery laden:
- CSV-Daten aus Cloud Storage laden
- Parquet-Daten aus Cloud Storage laden
- JSON-Daten aus Cloud Storage laden
- Daten aus Apache Iceberg abfragen
Migrationstools
In der folgenden Liste werden die Tools beschrieben, mit denen Sie Daten von Snowflake zu BigQuery migrieren können. Beispiele für die gemeinsame Verwendung dieser Tools in einer Snowflake-Migrationspipeline finden Sie unter Beispiele für Snowflake-Migrationspipelines.
- Befehl
COPY INTO <location>:Verwenden Sie diesen Befehl in Snowflake, um Daten aus einer Snowflake-Tabelle direkt in einen bestimmten Cloud Storage-Bucket zu extrahieren. Ein End-to-End-Beispiel finden Sie unter Snowflake zu BigQuery (snowflake2bq) auf GitHub. - Apache Sqoop: Wenn Sie Daten aus Snowflake in HDFS oder Cloud Storage extrahieren möchten, senden Sie Hadoop-Jobs mit dem JDBC-Treiber von Sqoop und Snowflake. Sqoop wird in einer Dataproc-Umgebung ausgeführt.
- Snowflake-JDBC: Verwenden Sie diesen Treiber mit den meisten Clienttools oder Anwendungen, die JDBC unterstützen.
Mit den folgenden generischen Tools können Sie Daten von Snowflake zu BigQuery migrieren:
- BigQuery Data Transfer Service für Snowflake Vorschau: Führen Sie eine automatisierte Batchübertragung von Cloud Storage-Daten nach BigQuery durch.
- Google Cloud CLI: Mit diesem Befehlszeilentool können Sie heruntergeladene Snowflake-Dateien in Cloud Storage kopieren.
- bq-Befehlszeilentool:Über dieses Befehlszeilentool können Sie mit BigQuery interagieren. Gängige Anwendungsfälle sind z. B. das Erstellen von BigQuery-Tabellenschemas, das Laden von Cloud Storage-Daten in Tabellen und das Ausführen von Abfragen.
- Cloud Storage-Clientbibliotheken: Kopieren Sie heruntergeladene Snowflake-Dateien mit einem benutzerdefinierten Tool, das die Cloud Storage-Clientbibliotheken verwendet, in Cloud Storage.
- BigQuery-Clientbibliotheken: Interagieren Sie mit BigQuery mit einem benutzerdefinierten Tool, das auf der BigQuery-Clientbibliothek basiert.
- BigQuery-Abfrageplaner:Planen Sie wiederkehrende SQL-Abfragen mit diesem integrierten BigQuery-Feature.
- Cloud Composer: Verwenden Sie diese vollständig verwaltete Apache Airflow-Umgebung, um BigQuery-Ladejobs und -Transformationen zu orchestrieren.
Weitere Informationen zum Laden von Daten in BigQuery finden Sie unter Daten in BigQuery laden.
Beispiele für Snowflake-Migrationspipelines
In den folgenden Abschnitten finden Sie Beispiele dafür, wie Sie Ihre Daten mit drei verschiedenen Prozessen von Snowflake zu BigQuery migrieren: ELT, ETL und Partnertools.
Extrahieren, Laden und Transformieren
Sie können einen ELT-Prozess (Extrahieren, Laden und Transformieren) mit zwei Methoden einrichten:
- Pipeline zum Extrahieren von Daten aus Snowflake und Laden der Daten in BigQuery verwenden
- Daten aus Snowflake mit anderen Google Cloud Produkten extrahieren
Pipeline zum Extrahieren von Daten aus Snowflake verwenden
Wenn Sie Daten aus Snowflake extrahieren und direkt in Cloud Storage laden möchten, verwenden Sie das Tool snowflake2bq.
Anschließend können Sie Ihre Daten mit einem der folgenden Tools aus Cloud Storage in BigQuery laden:
- BigQuery Data Transfer Service-Connector für Cloud Storage
- Der Befehl
LOADim bq-Befehlszeilentool - BigQuery API-Clientbibliotheken
Andere Tools zum Extrahieren von Daten aus Snowflake
Sie können auch die folgenden Tools verwenden, um Daten aus Snowflake zu extrahieren:
- Dataflow
- Cloud Data Fusion
- Dataproc
- Apache Spark BigQuery-Connector
- Snowflake-Connector für Apache Spark
- Hadoop-BigQuery-Connector
- Der JDBC-Treiber von Snowflake und Sqoop zum Extrahieren von Daten aus Snowflake in Cloud Storage:
Andere Tools zum Laden von Daten in BigQuery
Sie können auch die folgenden Tools verwenden, um Daten in BigQuery zu laden:
- Dataflow
- Cloud Data Fusion
- Dataproc
- Dataprep by Trifacta
Extrahieren, Transformieren und Laden
Wenn Sie Ihre Daten transformieren möchten, bevor Sie sie in BigQuery laden, können Sie die folgenden Tools verwenden:
- Dataflow
- Klonen Sie den Code der JDBC-zu-BigQuery-Vorlage und ändern Sie die Vorlage, um Apache Beam-Transformationen hinzuzufügen.
- Cloud Data Fusion
- Erstellen Sie eine wiederverwendbare Pipeline und transformieren Sie Ihre Daten mit CDAP-Plug-ins.
- Dataproc
- Transformieren Sie Ihre Daten mit Spark SQL oder benutzerdefiniertem Code in einer der unterstützten Spark-Sprachen wie Scala, Java, Python oder R.
Partnertools für die Migration
Es gibt mehrere Anbieter, die sich auf den EDW-Migrationsraum spezialisiert haben. Eine Liste der wichtigsten Partner und ihrer Lösungen finden Sie unter BigQuery-Partner.
Anleitung zum Exportieren von Snowflake-Daten
Im folgenden Tutorial wird ein Beispiel für den Export von Daten von Snowflake nach BigQuery gezeigt, bei dem der Befehl COPY INTO <location> von Snowflake verwendet wird.
Eine detaillierte Schritt-für-Schritt-Anleitung, die Codebeispiele enthält, finden Sie im Artikel zum Google Cloud Tool „Snowflake to BigQuery“ der Professional Services.
Auf Export vorbereiten
Sie können Ihre Snowflake-Daten für einen Export vorbereiten, indem Sie sie mit den folgenden Schritten in einen Cloud Storage- oder Amazon Simple Storage Service-Bucket (Amazon S3) extrahieren:
Cloud Storage
In dieser Anleitung wird die Datei im Format PARQUET vorbereitet.
Verwenden Sie Snowflake-SQL-Anweisungen, um eine benannte Dateiformatspezifikation zu erstellen.
create or replace file format NAMED_FILE_FORMAT type = 'PARQUET'
Ersetzen Sie
NAMED_FILE_FORMATdurch einen Namen für das Dateiformat. Beispiel:my_parquet_unload_format.Erstellen Sie eine Integration mit dem Befehl
CREATE STORAGE INTEGRATION.create storage integration INTEGRATION_NAME type = external_stage storage_provider = gcs enabled = true storage_allowed_locations = ('BUCKET_NAME')
Ersetzen Sie Folgendes:
INTEGRATION_NAME: ein Name für die Speicherintegration. z. B.gcs_int.BUCKET_NAME: der Pfad zum Cloud Storage-Bucket. z. B.gcs://mybucket/extract/.
Rufen Sie das Cloud Storage-Dienstkonto für Snowflake mit dem Befehl
DESCRIBE INTEGRATIONab.desc storage integration INTEGRATION_NAME;
Die Ausgabe sieht etwa so aus:
+-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+ | property | property_type | property_value | property_default | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | gcs://mybucket1/path1/,gcs://mybucket2/path2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | gcs://mybucket1/path1/sensitivedata/,gcs://mybucket2/path2/sensitivedata/ | [] | | STORAGE_GCP_SERVICE_ACCOUNT | String | service-account-id@iam.gserviceaccount.com | | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+
Gewähren Sie dem als
STORAGE_GCP_SERVICE_ACCOUNTaufgeführten Dienstkonto Lese- und Schreibzugriff auf den im Befehl zur Speicherintegration angegebenen Bucket. In diesem Beispiel gewähren Sie dem Dienstkontoservice-account-id@Lese- und Schreibzugriff auf den Bucket<var>UNLOAD_BUCKET</var>.Erstellen Sie eine externe Cloud Storage-Phase, die auf die zuvor erstellte Integration verweist.
create or replace stage STAGE_NAME url='UNLOAD_BUCKET' storage_integration = INTEGRATION_NAME file_format = NAMED_FILE_FORMAT;
Ersetzen Sie Folgendes:
STAGE_NAME: Ein Name für das Cloud Storage-Staging-Objekt. z. B.my_ext_unload_stage.
Amazon S3
Das folgende Beispiel zeigt, wie Sie Daten aus einer Snowflake-Tabelle in einen Amazon S3-Bucket verschieben:
Konfigurieren Sie in Snowflake ein Speicherintegrationsobjekt, damit Snowflake in einen Amazon S3-Bucket schreiben kann, auf den in einer externen Cloud Storage-Phase verwiesen wird.
Dieser Schritt umfasst die Konfiguration von Zugriffsberechtigungen für den Amazon S3-Bucket, das Erstellen der AWS IAM-Rolle und das Erstellen einer Speicherintegration in Snowflake mit dem Befehl
CREATE STORAGE INTEGRATION:create storage integration INTEGRATION_NAME type = external_stage storage_provider = s3 enabled = true storage_aws_role_arn = 'arn:aws:iam::001234567890:role/myrole' storage_allowed_locations = ('BUCKET_NAME')
Ersetzen Sie Folgendes:
INTEGRATION_NAME: ein Name für die Speicherintegration. z. B.s3_int.BUCKET_NAME: der Pfad zum Amazon S3-Bucket, in den Dateien geladen werden sollen. z. B.s3://unload/files/.
Rufen Sie den AWS IAM-Nutzer mit dem Befehl
DESCRIBE INTEGRATIONab.desc integration INTEGRATION_NAME;
Die Ausgabe sieht etwa so aus:
+---------------------------+---------------+================================================================================+------------------+ | property | property_type | property_value | property_default | +---------------------------+---------------+================================================================================+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | s3://mybucket1/mypath1/,s3://mybucket2/mypath2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | s3://mybucket1/mypath1/sensitivedata/,s3://mybucket2/mypath2/sensitivedata/ | [] | | STORAGE_AWS_IAM_USER_ARN | String | arn:aws:iam::123456789001:user/abc1-b-self1234 | | | STORAGE_AWS_ROLE_ARN | String | arn:aws:iam::001234567890:role/myrole | | | STORAGE_AWS_EXTERNAL_ID | String | MYACCOUNT_SFCRole=
| | +---------------------------+---------------+================================================================================+------------------+ Erstellen Sie eine Rolle mit der Berechtigung
CREATE STAGEfür das Schema und der BerechtigungUSAGEfür die Speicherintegration:CREATE role ROLE_NAME; GRANT CREATE STAGE ON SCHEMA public TO ROLE ROLE_NAME; GRANT USAGE ON INTEGRATION s3_int TO ROLE ROLE_NAME;
Ersetzen Sie
ROLE_NAMEdurch einen Namen für die Rolle. Beispiel:myrole.Gewähren Sie dem AWS IAM-Nutzer Berechtigungen zum Zugriff auf den Amazon S3-Bucket und erstellen Sie eine externe Phase mit dem Befehl
CREATE STAGE:USE SCHEMA mydb.public; create or replace stage STAGE_NAME url='BUCKET_NAME' storage_integration = INTEGRATION_NAMEt file_format = NAMED_FILE_FORMAT;
Ersetzen Sie Folgendes:
STAGE_NAME: Ein Name für das Cloud Storage-Staging-Objekt. z. B.my_ext_unload_stage.
Snowflake-Daten exportieren
Nachdem Sie Ihre Daten vorbereitet haben, können Sie sie zu Google Cloudverschieben.
Verwenden Sie den Befehl COPY INTO, um Daten aus der Snowflake-Datenbanktabelle in einen Cloud Storage- oder Amazon S3-Bucket zu kopieren. Geben Sie dazu das Objekt der externen Phase STAGE_NAME an.
copy into @STAGE_NAME/d1 from TABLE_NAME;
Ersetzen Sie TABLE_NAME durch den Namen Ihrer Snowflake-Datenbanktabelle.
Als Ergebnis dieses Befehls werden die Tabellendaten in das Staging-Objekt kopiert, das mit dem Cloud Storage- oder Amazon S3-Bucket verknüpft ist. Die Datei enthält das Präfix d1.
Andere Exportmethoden
Wenn Sie Azure Blob Storage für Ihre Datenexporte verwenden möchten, folgen Sie der Anleitung unter In Microsoft Azure entladen. Übertragen Sie dann die exportierten Dateien mit Storage Transfer Service nach Cloud Storage.
Preise
Berücksichtigen Sie bei der Planung der Snowflake-Migration die Kosten für die Übertragung und Speicherung von Daten sowie die Nutzung von Diensten in BigQuery. Weitere Informationen finden Sie unter Preise.
Für die Übertragung von Daten aus Snowflake oder AWS können Kosten für ausgehenden Traffic anfallen. Außerdem können zusätzliche Kosten anfallen, wenn Daten zwischen Regionen oder zwischen verschiedenen Cloud-Anbietern übertragen werden.