ベクトル検索では、ブール値ルールを使用して、ベクトル マッチング検索をインデックスのサブセットに制限できます。ブール述語は、インデックス内で無視するベクトルをベクトル検索に指示します。このページでは、フィルタリングの仕組み、例、ベクトル類似性に基づいて効率的にデータをクエリする方法について説明します。
ベクトル検索では、カテゴリと数値制限で結果を制限できます。制限の追加、つまり、インデックス登録結果のフィルタリングは、次のような理由で有用です。
結果の関連性の向上: ベクトル検索は、意味的に類似したアイテムを見つけるための強力なツールです。フィルタリングを使用すると、言語、カテゴリ、価格、期間が適切でないアイテムなど、無関係な結果を検索結果から除外できます。
結果数の減少: ベクトル検索では、特に大規模なデータセットの場合、多数の結果が返されることがあります。フィルタリングを使用すると、結果の件数を管理しやすい数に減らしながら、最も関連性の高い結果を取得できます。
セグメント化された結果: フィルタリングを使用して、ユーザーの個々のニーズと好みに合わせて検索結果をパーソナライズできます。たとえば、過去に高く評価したアイテムや特定の価格帯に属するアイテムのみが含まれるように、結果をフィルタリングできます。
ベクトル属性
ベクトルのデータベースに対するベクトル類似性検索では、各ベクトルは 0 個以上の属性で記述されます。これらの属性は、トークン(トークン制限の場合)または値(数値制限の場合)と呼ばれます。これらの制限は、名前空間という複数の属性カテゴリから適用できます。
次のサンプル アプリケーションでは、ベクトルに color、price、shape のタグが付けられます。
color、price、shapeは名前空間です。redとblueは、color名前空間のトークンです。squareとcircleは、shape名前空間のトークンです。100と50は、price名前空間の値です。
ベクトル属性を指定する
- 「赤い円」を指定する:
{color: red}, {shape: circle} - 「赤または青の正方形」を指定する:
{color: red, blue}, {shape: square} - 色のないオブジェクトを指定するには、
restrictsフィールドで color 名前空間を省略します。 - オブジェクトに数値制限を指定するには、名前空間と、そのタイプの該当するフィールドの値をメモします。整数値は
value_intに、浮動小数点値はvalue_floatに、倍精度値はvalue_doubleに指定します。特定の名前空間に使用できる数値タイプは 1 つだけです。
このデータの指定に使用するスキーマについては、入力データで名前空間とトークンを指定するをご覧ください。
クエリ
- クエリでは、複数の名前空間を AND 論理演算子で結合し、名前空間内は OR 論理演算子で結合しています。
{color: red, blue}, {shape: square, circle}を指定するクエリは、(red || blue) && (square || circle)を満たすすべてのデータベース ポイントと一致します。 {color: red}を指定するクエリは、shapeの制限なく、任意の種類のすべてのredオブジェクトと一致します。- クエリの数値制限には、
namespace、value_int、value_float、value_doubleのいずれかの数値と、演算子opが必要です。 - 演算子
opは、LESS、LESS_EQUAL、EQUAL、GREATER_EQUAL、GREATERのいずれかです。たとえば、演算子にLESS_EQUALを使用する場合、データポイントの値がクエリで使用されている値以下であれば、データポイントは適格となります。
次のコードサンプルでは、サンプル アプリケーションのベクトル属性を識別しています。
[
{
"namespace": "price",
"value_int": 20,
"op": "LESS"
},
{
"namespace": "length",
"value_float": 0.3,
"op": "GREATER_EQUAL"
},
{
"namespace": "width",
"value_double": 0.5,
"op": "EQUAL"
}
]
拒否リスト
より高度なシナリオを実現するために、Google では拒否リストトークンという否定形式をサポートしています。クエリによってトークンが拒否リストに追加されると、拒否リストに追加されたトークンを持つすべてのデータポイントは照合の対象から除外されます。クエリの名前空間に拒否リストのトークンしかない場合は、拒否リストに明示的に登録されていないすべてのポイントが一致します。これは、空の名前空間がすべてのポイントと一致する場合とまったく同じです。
また、データポイントでトークンを拒否リストに追加し、このトークンを指定するクエリで除外することもできます。
たとえば、トークンを指定してデータポイントを定義します。
A: {} // empty set matches everything
B: {red} // only a 'red' token
C: {blue} // only a 'blue' token
D: {orange} // only an 'orange' token
E: {red, blue} // multiple tokens
F: {red, !blue} // deny the 'blue' token
G: {red, blue, !blue} // An unlikely edge-case
H: {!blue} // deny-only (similar to empty-set)
このシステムは次のように動作します。
- 空のクエリの名前空間は、すべてに一致するワイルドカードです。たとえば、Q:
{}は DB:{color:red}と一致します。 空のデータポイントの名前空間は、すべてに一致するワイルドカードではありません。たとえば、Q:
{color:red}は DB:{}と一致しません。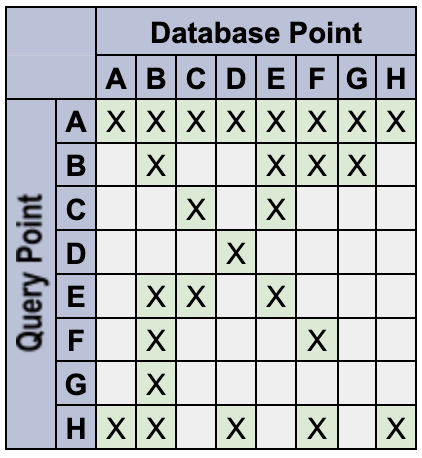
入力データに名前空間とトークン(または値)を指定する
入力データ全般を構築する方法については、入力データ形式と構造をご覧ください。
次のタブでは、各入力ベクトルに関連付けられた名前空間とトークンを指定する方法を説明します。
JSON
各ベクトルのレコードに
restrictsというフィールドを追加し、オブジェクトの配列を指定します。配列の各要素が名前空間になります。- 各オブジェクトには
namespaceというフィールドが必要です。このフィールドはTokenNamespace.namespace(名前空間)です。 allowフィールドの値(存在する場合)は、文字列の配列です。この文字列の配列はTokenNamespace.string_tokensリストです。denyフィールドの値(存在する場合)は、文字列の配列です。この文字列の配列はTokenNamespace.string_denylist_tokensリストです。
- 各オブジェクトには
JSON 形式の 2 つのレコードの例を次に示します。
[
{
"id": "42",
"embedding": [
0.5,
1
],
"restricts": [
{
"namespace": "class",
"allow": [
"cat",
"pet"
]
},
{
"namespace": "category",
"allow": [
"feline"
]
}
]
},
{
"id": "43",
"embedding": [
0.6,
1
],
"sparse_embedding": {
"values": [
0.1,
0.2
],
"dimensions": [
1,
4
]
},
"restricts": [
{
"namespace": "class",
"allow": [
"dog",
"pet"
]
},
{
"namespace": "category",
"allow": [
"canine"
]
}
]
}
]
各ベクトルのレコードに
numeric_restrictsというフィールドを追加し、オブジェクトの配列を指定します。配列の各要素が数値制限になります。- 各オブジェクトには
namespaceというフィールドが必要です。このフィールドはNumericRestrictNamespace.namespace(名前空間)です。 - 各オブジェクトには、
value_int、value_float、value_doubleのいずれかが必要です。 - 各オブジェクトに
opというフィールドは必要ありません。このフィールドはクエリ専用です。
- 各オブジェクトには
JSON 形式の 2 つのレコードの例を次に示します。
[
{
"id": "42",
"embedding": [
0.5,
1
],
"numeric_restricts": [
{
"namespace": "size",
"value_int": 3
},
{
"namespace": "ratio",
"value_float": 0.1
}
]
},
{
"id": "43",
"embedding": [
0.6,
1
],
"sparse_embedding": {
"values": [
0.1,
0.2
],
"numeric_restricts": [
{
"namespace": "weight",
"value_double": 0.3
}
]
}
}
]
Avro
Avro レコードは次のスキーマを使用します。
{
"type": "record",
"name": "FeatureVector",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "embedding",
"type": {
"type": "array",
"items": "float"
}
},
{
"name": "sparse_embedding",
"type": [
"null",
{
"type": "record",
"name": "sparse_embedding",
"fields": [
{
"name": "values",
"type": {
"type": "array",
"items": "float"
}
},
{
"name": "dimensions",
"type": {
"type": "array",
"items": "long"
}
}
]
}
]
},
{
"name": "restricts",
"type": [
"null",
{
"type": "array",
"items": {
"type": "record",
"name": "Restrict",
"fields": [
{
"name": "namespace",
"type": "string"
},
{
"name": "allow",
"type": [
"null",
{
"type": "array",
"items": "string"
}
]
},
{
"name": "deny",
"type": [
"null",
{
"type": "array",
"items": "string"
}
]
}
]
}
}
]
},
{
"name": "numeric_restricts",
"type": [
"null",
{
"type": "array",
"items": {
"name": "NumericRestrict",
"type": "record",
"fields": [
{
"name": "namespace",
"type": "string"
},
{
"name": "value_int",
"type": [ "null", "int" ],
"default": null
},
{
"name": "value_float",
"type": [ "null", "float" ],
"default": null
},
{
"name": "value_double",
"type": [ "null", "double" ],
"default": null
}
]
}
}
],
"default": null
},
{
"name": "crowding_tag",
"type": [
"null",
"string"
]
}
]
}
CSV
トークン制限
各ベクトルのレコードに、
name=value形式のカンマ区切りのペアを追加して、トークンの名前空間制限を指定します。名前空間に複数の値がある場合は、同じ名前を繰り返すことができます。たとえば、
color=red,color=blueは次のTokenNamespaceを表します。{ "namespace": "color" "string_tokens": ["red", "blue"] }各ベクトルのレコードに、
name=!value形式のカンマ区切りのペアを追加して、トークンの名前空間制限から除外する値を指定します。たとえば、
color=!redは次のTokenNamespaceを表します。{ "namespace": "color" "string_blacklist_tokens": ["red"] }
数値制限
各ベクトルのレコードに、
#name=numericValue形式のカンマ区切りのペアと数値型の接尾辞を追加して、数値の名前空間制限を指定します。int の場合、数値型の接尾辞は
iです。float の場合はf、double の場合はdです。名前空間ごとに 1 つの値を関連付ける必要があるため、同じ名前を繰り返さないでください。たとえば、
#size=3iは次のNumericRestrictNamespaceを表します。{ "namespace": "size" "value_int": 3 }#ratio=0.1fは次のNumericRestrictNamespaceを表します。{ "namespace": "ratio" "value_float": 0.1 }#weight=0.3dは次のNumericRestrictionを表します。{ "namespace": "weight" "value_double": 0.3 }次の例は、
id: "6"、embedding: [7, -8.1]、sparse_embedding: {values: [0.1, -0.2, 0.5]、dimensions: [40, 901, 1111]}}、クラウディング タグ(test)、トークンの許可リスト(color: red, blue)、トークンの拒否リスト(color: purple)、数値制限(ratioが浮動小数点数0.1)を持つデータポイントです。6,7,-8.1,40:0.1,901:-0.2,1111:0.5,crowding_tag=test,color=red,color=blue,color=!purple, ratio=0.1f