Vector Search 支持混合搜索,这是一种信息检索 (IR) 中常见的架构模式,可同时结合使用语义搜索和关键字搜索(也称为基于词元的搜索)。借助混合搜索,开发者可以充分利用这两种方法中的优点,从而有效地提供更高的搜索质量。
本页面介绍混合搜索、语义搜索和基于词元的搜索的概念,并举例说明如何设置基于词元的搜索和混合搜索:
为什么混合搜索很重要?
如 Vector Search 概览中所述,使用 Vector Search 进行语义搜索可以通过查询来查找具有语义相似度的项。
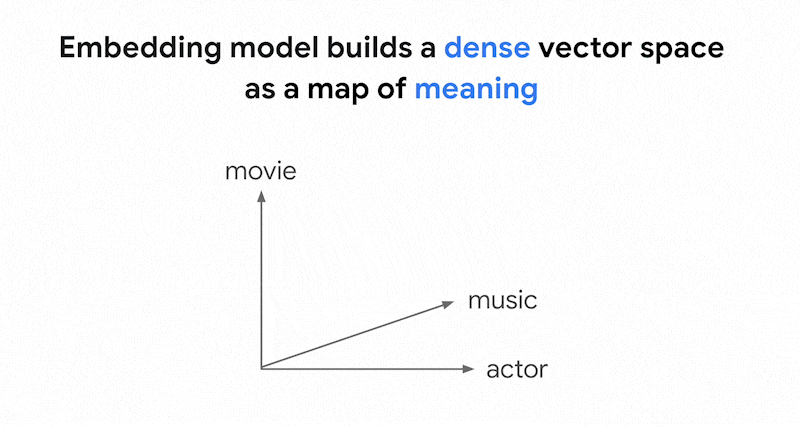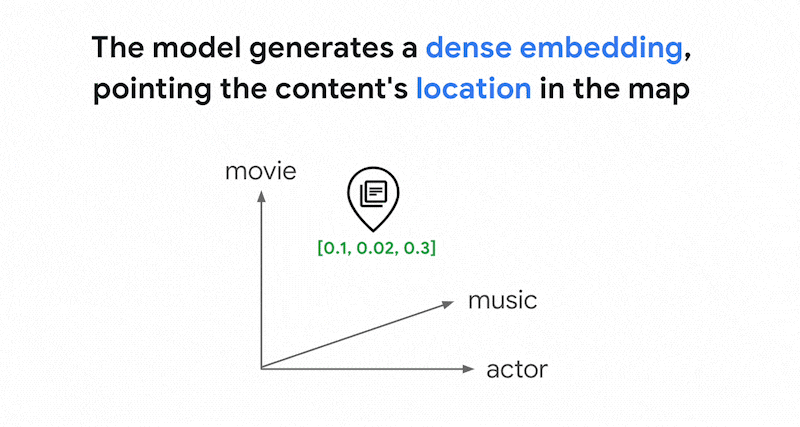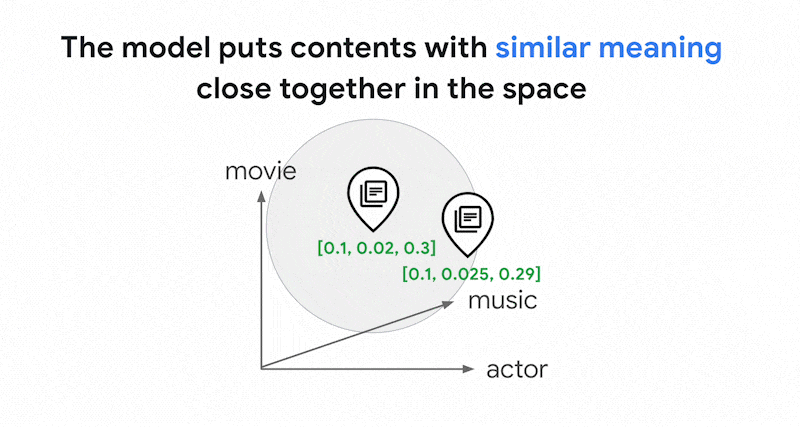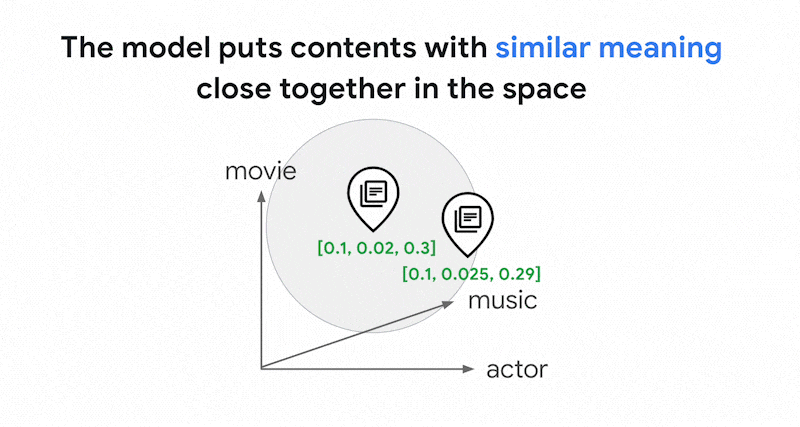
Vertex AI Embedding 等嵌入模型会将向量空间构建为内容含义的映射。每个文本或多模态嵌入都是映射中的一个位置,表示某些内容的含义。举一个简单的示例,当嵌入模型采用一段文本,其中 10% 讨论电影、2% 讨论音乐、30% 讨论演员时,它可以用嵌入 [0.1, 0.02,
0.3] 来表示该文本。借助 Vector Search,您可以快速找到其附近的其他嵌入。这种按内容含义进行搜索的做法称为“语义搜索”。
带有嵌入的语义搜索和 Vector Search 可以帮助 IT 系统变得像经验丰富的图书管理员或商店工作人员一样智能。嵌入可以用于将不同的业务数据与其含义相关联;例如,查询和搜索结果;文本和图片;用户活动和推荐产品;英语文本和日语文本;或传感器数据和提醒条件。凭借此功能,嵌入有多种应用场景。
为何将语义搜索与基于关键字的搜索结合使用?
语义搜索并未涵盖信息检索应用(例如检索增强生成 [RAG])的所有可能要求。语义搜索只能找到嵌入模型能够理解的数据。例如,包含任意商品编号或 SKU、最近添加的全新商品名称以及公司专有代码名称的查询或数据集不适用于语义搜索,因为它们未包含在嵌入模型的训练数据集中。这类数据称为“域外”数据。
在这种情况下,您需要将基于语义的搜索与基于关键字的搜索(也称为基于词元的搜索)相结合,以形成混合搜索。借助混合搜索,您可以同时利用基于语义和基于词元的搜索来提高搜索质量。
Google 搜索是最受欢迎的混合搜索系统之一。该服务除了基于词元的关键字搜索算法外,还于 2015 年结合了采用 RankBrain 模型的语义搜索。随着混合搜索的引入,Google 搜索能够满足两项要求:“按含义搜索”和“按关键字搜索”,从而显著提高搜索质量。
过去,构建混合搜索引擎是一项复杂的任务。与 Google 搜索一样,您必须构建和运维两种不同类型的搜索引擎(语义搜索和基于词元的搜索),然后对它们的结果进行合并和排名。借助 Vector Search 中的混合搜索支持,您可以根据业务需求,使用单个 Vector Search 索引构建您自己的混合搜索系统。
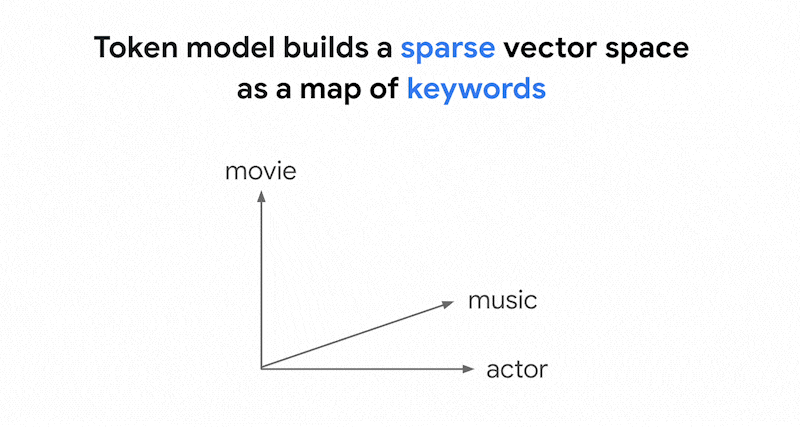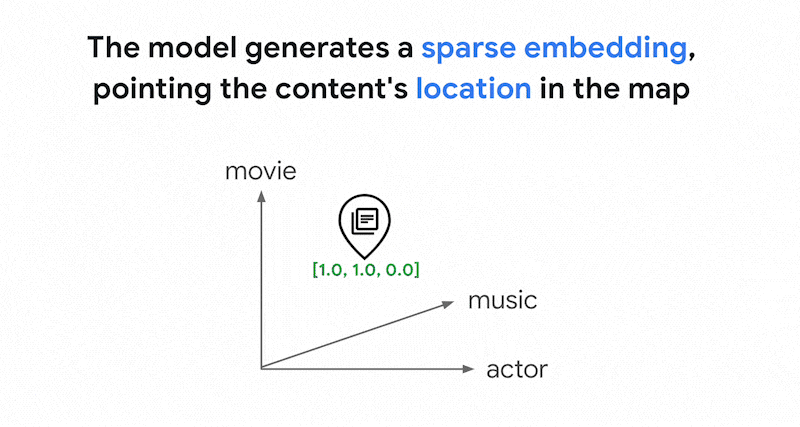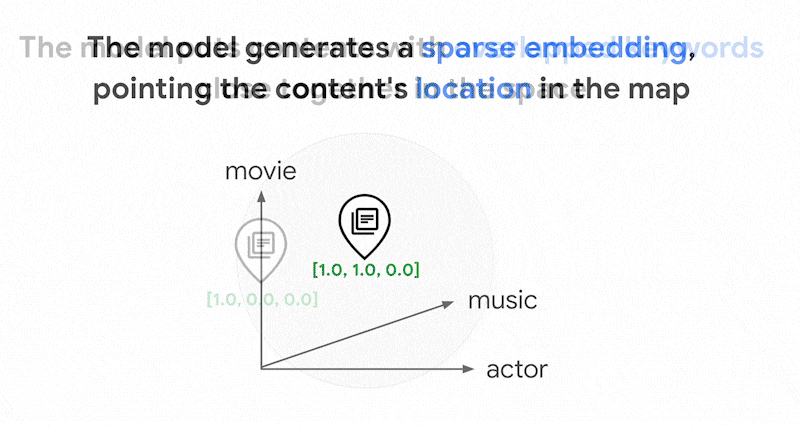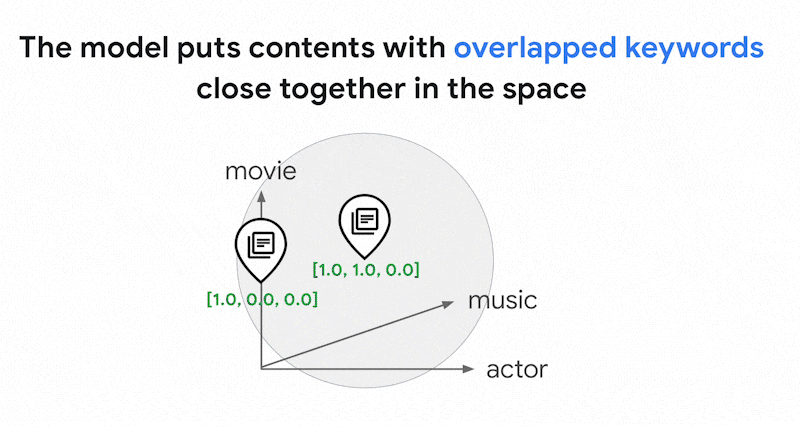
基于词元的搜索的工作原理
Vector Search 中基于词元的搜索的工作原理将文本拆分为词元(例如字词或子字词)后,您可以使用 TF-IDF、BM25 或 SPLADE 等常用稀疏嵌入算法为文本生成稀疏嵌入。
稀疏嵌入的简单解释是,它们是表示每个单词或子词在文本中出现次数的向量。典型的稀疏嵌入不会考虑文本的语义。

文本中可能包含数千个不同的字词。因此,这种嵌入通常有数万个维度,其中只有几个维度具有非零值。因此,它们被称为“稀疏”嵌入。它们的大多数值均为零。这种稀疏嵌入空间可用作关键字映射,类似于图书的索引。
在此稀疏嵌入空间中,您可以通过查看查询嵌入的邻域来找到类似的嵌入。这些嵌入在其文本中使用的关键字分布方面是相似的。
这是使用稀疏嵌入的基于词元的搜索的基本机制。借助 Vector Search 中的混合搜索,您可以将密集嵌入和稀疏嵌入混合到单个向量索引中,并使用密集嵌入和/或稀疏嵌入运行查询。结果是语义搜索和基于词元的搜索结果的组合。
与具有反向索引设计的基于词元的搜索引擎相比,混合搜索还可以缩短查询延迟时间。与用于语义搜索的 Vector Search 一样,使用稠密或稀疏嵌入的每个查询都会在几毫秒内完成,即使有数百万或数十亿项也是如此。
示例:如何使用基于词元的搜索
为了说明如何使用基于词元的搜索,以下部分包含一些代码示例,这些示例会在 Vector Search 中生成稀疏嵌入并使用这些嵌入构建索引。
如需试用此示例代码,请使用以下笔记本:结合语义和关键字搜索:使用 Vertex AI Vector Search 的混合搜索教程
第一步是准备数据文件,以便根据输入数据格式和结构中所述的数据格式为稀疏嵌入构建索引。
在 JSON 中,数据文件如下所示:
{"id": "3", "sparse_embedding": {"values": [0.1, 0.2], "dimensions": [1, 4]}}
{"id": "4", "sparse_embedding": {"values": [-0.4, 0.2, -1.3], "dimensions": [10, 20, 30]}}
每项都应具有一个 sparse_embedding 属性,其中包含 values 和 dimensions 属性。稀疏嵌入具有数千个维度,其中只有少数值不为零。这种数据格式非常高效,因为它仅包含非零值及其在空间中的位置。
准备示例数据集
作为示例数据集,我们将使用 Google Merch Shop 数据集,其中包含约 200 行 Google 品牌商品。
0 Google Sticker
1 Google Cloud Sticker
2 Android Black Pen
3 Google Ombre Lime Pen
4 For Everyone Eco Pen
...
197 Google Recycled Black Backpack
198 Google Cascades Unisex Zip Sweater
199 Google Cascades Womens Zip Sweater
200 Google Cloud Skyline Backpack
201 Google City Black Tote Backpack
准备 TF-IDF 矢量化器
使用此数据集,我们将训练一个矢量化器,这是一种根据文本生成稀疏嵌入的模型。此示例使用 scikit-learn 中的 TfidfVectorizer,这是一个使用 TF-IDF 算法的基本矢量化器。
from sklearn.feature_extraction.text import TfidfVectorizer
# Make a list of the item titles
corpus = df.title.tolist()
# Initialize TfidfVectorizer
vectorizer = TfidfVectorizer()
# Fit and Transform
vectorizer.fit_transform(corpus)
变量 corpus 包含 200 个项目名称的列表,例如“Google 贴纸”或“Chrome Dino Pin”。然后,代码通过调用 fit_transform() 函数将它们传递给矢量化器。这样,矢量化器便可以生成稀疏嵌入。
TF-IDF 矢量化器尝试为数据集中的特征词(例如“Shirts”或“Dino”)赋予比普通词(例如“The”“a”或“of”)更高的权重,并计算这些特征词在指定文档中的使用次数。稀疏嵌入的每个值表示基于计数的每个字词的频率。如需详细了解 TF-IDF,请参阅 TF-IDF 和 TfidfVectorizer 的工作原理。
在此示例中,为简单起见,我们使用了基本词级词法单元化和 TF-IDF 矢量化。在生产开发中,您可以根据需要选择任何其他词元化和矢量化选项来生成稀疏嵌入。对于词元化器,在许多情况下,子词词元化器的效果与词级词元化器相比非常出色,是热门之选。对于矢量化器,BM25 作为 TF-IDF 的改进版本广受欢迎。SPLADE 是另一种常用的矢量化算法,可为稀疏嵌入采用一些语义。
获取稀疏嵌入
为了使矢量化器更易于使用 Vector Search,我们将定义一个封装容器函数 get_sparse_embedding():
def get_sparse_embedding(text):
# Transform Text into TF-IDF Sparse Vector
tfidf_vector = vectorizer.transform([text])
# Create Sparse Embedding for the New Text
values = []
dims = []
for i, tfidf_value in enumerate(tfidf_vector.data):
values.append(float(tfidf_value))
dims.append(int(tfidf_vector.indices[i]))
return {"values": values, "dimensions": dims}
此函数会将参数“text”传递给矢量化器,以生成稀疏嵌入。然后,将其转换为之前提到的 {"values": ...., "dimensions": ...} 格式,以构建 Vector Search 稀疏索引。
您可以测试此函数:
text_text = "Chrome Dino Pin"
get_sparse_embedding(text_text)
这应输出以下稀疏嵌入:
{'values': [0.6756557405747007, 0.5212913389979028, 0.5212913389979028],
'dimensions': [157, 48, 33]}
创建输入数据文件
在此示例中,我们将为所有 200 项生成稀疏嵌入。
items = []
for i in range(len(df)):
id = i
title = df.title[i]
sparse_embedding = get_sparse_embedding(title)
items.append({"id": id, "title": title, "sparse_embedding": sparse_embedding})
此代码会为每项生成以下行:
{
'id': 0,
'title': 'Google Sticker',
'sparse_embedding': {
'values': [0.933008728540452, 0.359853737603667],
'dimensions': [191, 78]
}
}
然后,将其另存为 JSONL 文件“items.json”,并上传到 Cloud Storage 存储桶。
# output as a JSONL file and save to bucket
with open("items.json", "w") as f:
for item in items:
f.write(f"{item}\n")
! gsutil cp items.json $BUCKET_URI
在 Vector Search 中创建稀疏嵌入索引
接下来,我们将在 Vector Search 中构建和部署稀疏嵌入索引。此过程与 Vector Search 快速入门中记录的过程相同。
# create Index
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = f"vs-hybridsearch-index-{UID}",
contents_delta_uri = BUCKET_URI,
dimensions = 768,
approximate_neighbors_count = 10,
)
如要使用索引,您需要创建一个索引端点。它充当接受索引的查询请求的服务器实例。
# create IndexEndpoint
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = f"vs-quickstart-index-endpoint-{UID}",
public_endpoint_enabled = True
)
使用索引端点,通过指定唯一的已部署索引 ID 来部署索引。
DEPLOYED_INDEX_ID = f"vs_quickstart_deployed_{UID}"
# deploy the Index to the Index Endpoint
my_index_endpoint.deploy_index(
index = my_index, deployed_index_id = DEPLOYED_INDEX_ID
)
等待部署后,我们即可运行测试查询。
使用稀疏嵌入索引运行查询
如需使用稀疏嵌入索引运行查询,您需要创建一个 HybridQuery 对象来封装查询文本的稀疏嵌入,如以下示例所示:
from google.cloud.aiplatform.matching_engine.matching_engine_index_endpoint import HybridQuery
# create HybridQuery
query_text = "Kids"
query_emb = get_sparse_embedding(query_text)
query = HybridQuery(
sparse_embedding_dimensions=query_emb['dimensions'],
sparse_embedding_values=query_emb['values'],
)
此示例代码将文本“Kids”用于查询。现在,使用 HybridQuery 对象运行查询。
# build a query request
response = my_index_endpoint.find_neighbors(
deployed_index_id=DEPLOYED_INDEX_ID,
queries=[query],
num_neighbors=5,
)
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
print(f"{title:<40}")
这应该提供如下所示的输出:
Google Blue Kids Sunglasses
Google Red Kids Sunglasses
YouTube Kids Coloring Pencils
YouTube Kids Character Sticker Sheet
在 200 项中,结果包含具有关键字“Kids”的项名称。
示例:如何使用混合搜索
此示例将基于词元的搜索与语义搜索相结合,以便在 Vector Search 中创建混合搜索。
如何创建混合索引
如需构建混合索引,每项都应同时具有“embedding”(用于稠密嵌入)和“sparse_embedding”:
items = []
for i in range(len(df)):
id = i
title = df.title[i]
dense_embedding = get_dense_embedding(title)
sparse_embedding = get_sparse_embedding(title)
items.append(
{"id": id, "title": title,
"embedding": dense_embedding,
"sparse_embedding": sparse_embedding,}
)
items[0]
get_dense_embedding() 函数使用 Vertex AI Embedding API 生成 768 维的文本嵌入。这会按以下格式生成密集嵌入和稀疏嵌入:
{
"id": 0,
"title": "Google Sticker",
"embedding":
[0.022880317643284798,
-0.03315234184265137,
...
-0.03309667482972145,
0.04621824622154236],
"sparse_embedding": {
"values": [0.933008728540452, 0.359853737603667],
"dimensions": [191, 78]
}
}
其余流程与示例:如何使用基于词元的搜索中所述的流程相同:将 JSONL 文件上传到 Cloud Storage 存储桶,使用该文件创建一个 Vector Search 索引,然后将该索引部署到索引端点。
运行混合查询
部署混合索引后,您可以运行混合查询:
# create HybridQuery
query_text = "Kids"
query_dense_emb = get_dense_embedding(query_text)
query_sparse_emb = get_sparse_embedding(query_text)
query = HybridQuery(
dense_embedding=query_dense_emb,
sparse_embedding_dimensions=query_sparse_emb['dimensions'],
sparse_embedding_values=query_sparse_emb['values'],
rrf_ranking_alpha=0.5,
)
对于查询文本“Kids”,请为字词生成密集和稀疏嵌入,并将其封装到 HybridQuery 对象。与之前的 HybridQuery 相比,新增了两个参数:dense_embedding 和 rrf_ranking_alpha。
这次,我们将输出每项的距离:
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
dense_dist = neighbor.distance if neighbor.distance else 0.0
sparse_dist = neighbor.sparse_distance if neighbor.sparse_distance else 0.0
print(f"{title:<40}: dense_dist: {dense_dist:.3f}, sparse_dist: {sparse_dist:.3f}")
在每个 neighbor 对象中,有一个 distance 属性在查询与具有密集嵌入的项之间具有距离,还有一个 sparse_distance 属性具有与稀疏嵌入的距离嵌入。这些值是反距离,因此值越大,距离越短。
使用 HybridQuery 运行查询后,您会得到以下结果:
Google Blue Kids Sunglasses : dense_dist: 0.677, sparse_dist: 0.606
Google Red Kids Sunglasses : dense_dist: 0.665, sparse_dist: 0.572
YouTube Kids Coloring Pencils : dense_dist: 0.655, sparse_dist: 0.478
YouTube Kids Character Sticker Sheet : dense_dist: 0.644, sparse_dist: 0.468
Google White Classic Youth Tee : dense_dist: 0.645, sparse_dist: 0.000
Google Doogler Youth Tee : dense_dist: 0.639, sparse_dist: 0.000
Google Indigo Youth Tee : dense_dist: 0.637, sparse_dist: 0.000
Google Black Classic Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Chrome Dino Glow-in-the-Dark Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Google Bike Youth Tee : dense_dist: 0.629, sparse_dist: 0.000
除了包含“Kids”关键字的基于词元的搜索结果之外,还包含语义搜索结果。例如,之所以包含“Google White Classic Youth Tee”,是因为嵌入模型知道“Youth”和“Kids”在语义上是相似的。
为了合并基于词元的搜索结果和语义搜索结果,混合搜索使用倒数排序融合 (RRF)。如需详细了解 RRF 以及如何指定 rrf_ranking_alpha 参数,请参阅什么是倒数排序融合?。
重排序
RRF 提供了一种将语义和基于词元的搜索结果的排名合并起来的方法。在许多生产信息检索或推荐系统中,结果将经过进一步的精确排名算法(即所谓的重新排名)。通过将毫秒级快速检索与 Vector Search 和结果的精确重新排名相结合,您可以构建多阶段系统,从而提供更高的搜索质量或推荐效果。
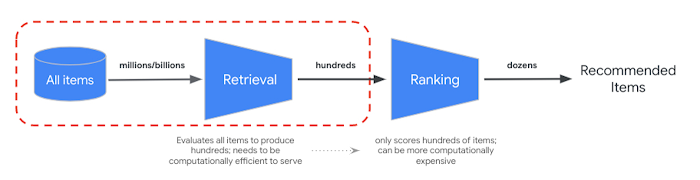
Vertex AI Ranking API 提供了一种方法,可根据预训练模型中查询文本与搜索结果文本之间的一般相关性来实现排名。TensorFlow 排名还介绍了如何设计和训练可针对各种业务需求自定义的高级重排序的 learning to rank (LTR) 模型。
开始使用混合搜索
以下资源可帮助您开始在 Vector Search 中使用混合搜索。
混合搜索资源
- 结合语义和关键字搜索:使用 Vertex AI Vector Search 的混合搜索教程:混合搜索使用入门示例笔记本
- 输入数据格式和结构:用于构建稀疏嵌入索引的输入数据格式
- 查询公共索引以获取最近邻:如何使用混合搜索运行查询
- 倒数排序融合优于 Condorcet 和各种排名学习方法:对 RRF 算法的讨论
Vector Search 资源
其他概念
以下各部分更详细地介绍了 TF-IDF 和 TfidVectorizer、倒数排序融合以及 alpha 参数。
TF-IDF 和 TfidfVectorizer 的工作原理
fit_transform() 函数会执行 TF-IDF 算法的两个重要过程:
拟合:矢量化器会计算词汇表中每个字词的逆向文档频率 (IDF)。IDF 反映了一个字词在整个语料库中的重要性。罕见字词的 IDF 得分更高:
IDF(t) = log_e(Total number of documents / Number of documents containing term t)转换:
- 词法单元化:将文档分解为各个术语(字词或短语)
词频 (TF) 计算:计算每个字词在每个文档中出现的次数,具体公式如下:
TF(t, d) = (Number of times term t appears in document d) / (Total number of terms in document d)TF-IDF 计算:将每个字词的 TF 与预先计算的 IDF 相结合来创建 TF-IDF 得分。此得分表示某个字词在特定文档中相对于整个语料库的重要性。
TF-IDF(t, d) = TF(t, d) * IDF(t)与普通字词(例如“The”“a”或“of”)相比,TF-IDF 矢量化器尝试为数据集中的特征字词(例如“Shirts”或“Dino”)分配更高的权重,并计算这些特征词在指定文档中的使用次数。稀疏嵌入的每个值表示基于计数的每个字词的频率。
什么是倒数排序融合?
如需合并基于词元的搜索结果和基于语义的搜索结果,混合搜索会使用倒数排序融合 (RRF)。RRF 是一种算法,用于将多个项目排名列表合并为一个统一排名。它是一种合并不同来源或检索方法的搜索结果,尤其是在混合搜索系统和大语言模型中。
对于 Vector Search 的混合搜索,密集距离和稀疏距离是在不同的空间中衡量的,因此无法直接相互比较。因此,RRF 可有效地合并和对来自两个不同空间的结果进行排名。
RRF 的工作原理如下:
- 倒数排序:为排名列表中的每项计算其倒数排序。这意味着获取列表中项的位置(排名)的反转值。例如,排名第一的项的倒数排序为 1/1 = 1,排名第二的项的反向排名为 1/2 = 0.5。
- 对倒数排序求和:对所有排名列表中每项的倒数排序求和。这样便可得出每项的最终得分。
- 按最终得分排序:按最终得分按降序对项进行排序。分数最高的项被视为最相关或最重要的项。
简而言之,在密集结果和稀疏结果中排名较高的项将被拉取到列表顶部。因此,“Google Blue Kids Sunglasses”项排名靠前,因为它在密集和稀疏搜索结果中的排名都较高。“Google White Classic Youth Tee”等项的排名较低,因为它们只有在密集搜索结果中才有排名。
alpha 参数的行为方式
在创建 HybridQuery 对象时,如何使用混合搜索的示例会将参数 rrf_ranking_alpha 设置为 0.5。您可以为 rrf_ranking_alpha 使用以下值,指定对密集和稀疏搜索结果进行排名的权重:
1或未指定:混合搜索仅使用稠密搜索结果,并忽略稀疏搜索结果。0:混合搜索仅使用稀疏搜索结果,并忽略密集搜索结果。0到1:混合搜索会将密集和稀疏结果与值指定的权重合并。0.5 表示它们将以相同的权重合并。