ベクトル検索は、セマンティック検索とキーワード検索(トークンベース検索とも呼ばれます)の両方を組み合わせた、情報検索(IR)で一般的なアーキテクチャ パターンであるハイブリッド検索をサポートしています。ハイブリッド検索を使用すると、2 つのアプローチの長所を活かして、検索品質を効果的に高めることができます。
このページでは、ハイブリッド検索、セマンティック検索、トークンベース検索のコンセプトについて説明します。また、トークンベース検索とハイブリッド検索を設定する方法の例も示します。
ハイブリッド検索が重要である理由
ベクトル検索の概要で説明したように、ベクトル検索によるセマンティック検索では、クエリを使用して意味的に類似したアイテムを見つけることができます。
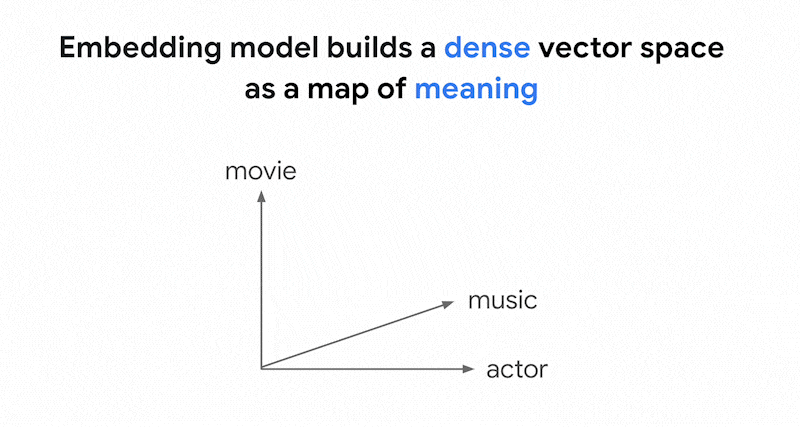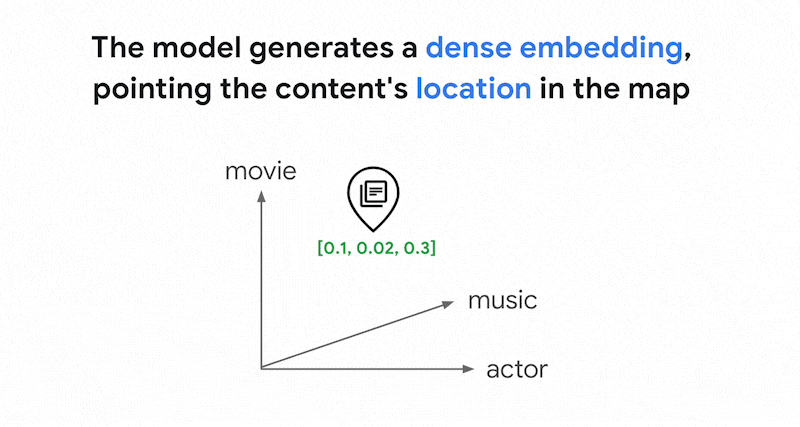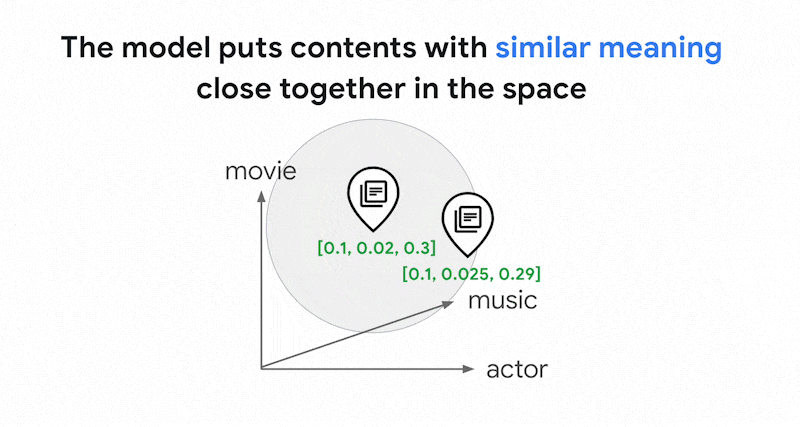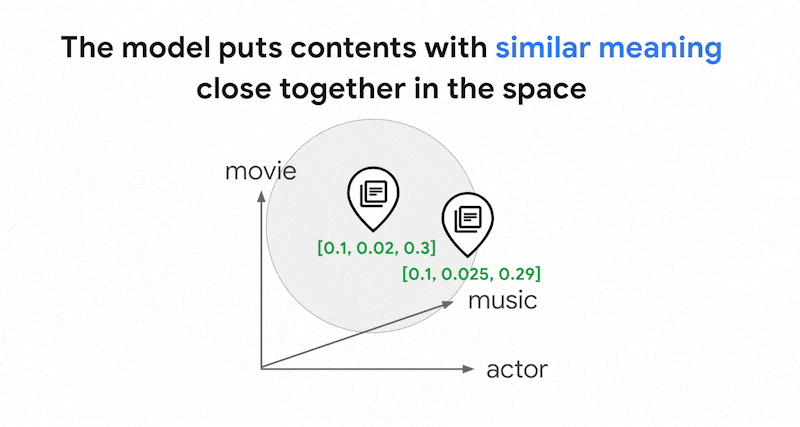
Vertex AI Embeddings などのエンベディング モデルは、コンテンツの意味のマップとしてベクトル空間を構築します。各テキストまたはマルチモーダル エンベディングは、コンテンツの意味を表すマップ内の場所です。簡単な例として、映画が 10%、音楽が 2%、俳優が 30% の割合で言及されているテキストをエンベディング モデルが取得すると、このテキストは [0.1, 0.02,
0.3] というエンベディングで表されます。ベクトル検索を使用すると、近傍の他のエンベディングをすばやく見つけることができます。コンテンツの意味に基づく検索は、セマンティック検索と呼ばれます。
エンベディングとベクトル検索を使用したセマンティック検索により、経験豊富な図書館員やショップ スタッフのように賢い IT システムを作ることができます。エンベディングは、さまざまなビジネスデータをその意味に結び付けるために使用できます。たとえば、クエリと検索結果、テキストと画像、ユーザー アクティビティとおすすめの商品、英語のテキストと日本語のテキスト、センサーデータとアラートの条件などです。この機能により、エンベディングのユースケースは多岐にわたります。
セマンティック検索とキーワード ベースの検索を組み合わせる理由
セマンティック検索は、検索拡張生成(RAG)など情報検索アプリケーションのすべての要件を網羅しているわけではありません。セマンティック検索で見つけることができるのは、エンベディング モデルが理解できるデータのみです。たとえば、任意の商品番号または SKU を含むクエリやデータセット、最近追加されたまったく新しい商品名、企業独自のコードネームは、エンベディング モデルのトレーニング データセットに含まれていないため、セマンティック検索では機能しません。これは「ドメイン外」データと呼ばれます。
このような場合は、セマンティック検索とキーワードベース(トークンベース)検索を組み合わせてハイブリッド検索を形成する必要があります。ハイブリッド検索を使用すると、セマンティック検索とトークンベース検索の両方の長所を活かして、検索品質を高めることができます。
最も一般的なハイブリッド検索システムの一つが Google 検索です。このサービスには、トークンベースのキーワード検索アルゴリズムに加えて、RankBrain モデルによるセマンティック検索が 2015 年に組み込まれています。ハイブリッド検索の導入により、Google 検索は「意味による検索」と「キーワードによる検索」という 2 つの要件に対応し、検索の品質を大幅に向上させることができました。
これまで、ハイブリッド検索エンジンの構築は複雑なタスクでした。Google 検索と同様に、2 種類の検索エンジン(セマンティック検索とトークンベース検索)を構築して運用し、その結果を統合してランク付けする必要があります。ベクトル検索はハイブリッド検索をサポートするため、ビジネス要件に合わせてカスタマイズした単一のベクトル検索インデックスを使用して、独自のハイブリッド検索システムを構築できます。
トークンベース検索の仕組み
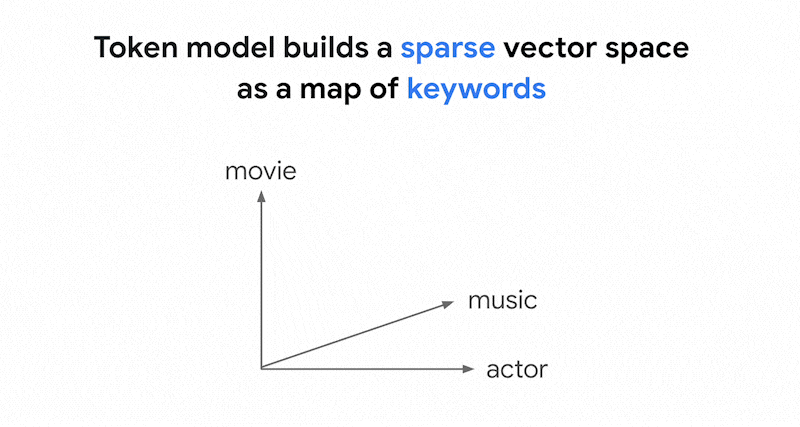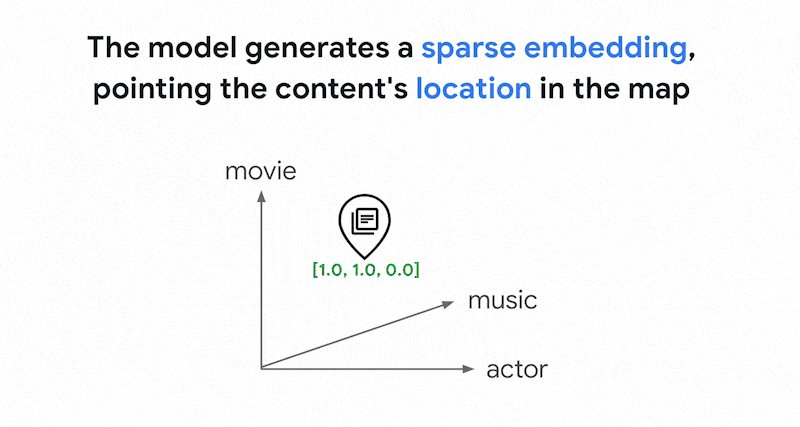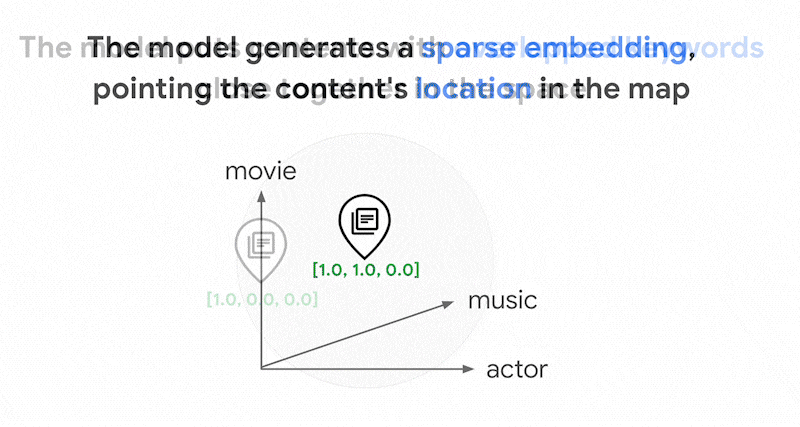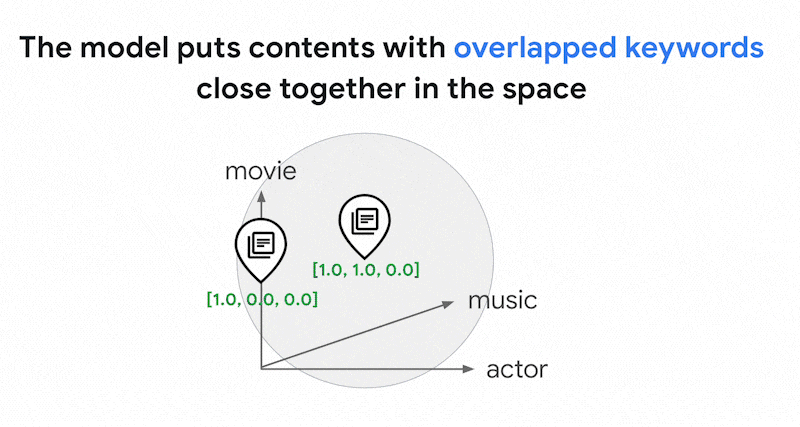
ベクトル検索のトークンベース検索の仕組みテキストをトークン(単語やサブワードなど)に分割した後、TF-IDF、BM25、SPLADE などの一般的なスパース エンベディング アルゴリズムを使用して、テキストのスパース エンベディングを生成できます。
スパース エンベディングを簡単に説明すると、各単語またはサブワードがテキストに出現する回数を表すベクトルです。一般的なスパース エンベディングでは、テキストのセマンティクスは考慮されません。

テキストには数千もの異なる単語が使用されている可能性があります。したがって、このエンベディングには通常数万のディメンションがあり、ゼロ以外の値を持つディメンションは数個のみです。これが「スパース」エンベディングと呼ばれる理由です。値のほとんどはゼロです。このスパース エンベディング空間は、書籍のインデックスと同様に、キーワードのマップとして機能します。
このスパース エンベディング空間では、クエリ エンベディングの近傍を調べることで、類似したエンベディングを見つけることができます。これらのエンベディングは、テキストで使用されるキーワードの分布に関して類似しています。
これは、スパース エンベディングを使用したトークンベース検索の基本的なメカニズムです。ベクトル検索のハイブリッド検索では、高密度エンベディングとスパース エンベディングの両方を 1 つのベクトル インデックスに混在させ、高密度エンベディング、スパース エンベディング、またはその両方を使用してクエリを実行できます。結果は、セマンティック検索とトークンベース検索の結果が組み合わされたものになります。
また、ハイブリッド検索では、転置インデックス設計のトークンベース検索エンジンと比較して、クエリ レイテンシが低くなります。セマンティック検索のベクトル検索と同様に、高密度エンベディングまたはスパース エンベディングを使用した各クエリは、数百万個から数十億個のアイテムがあってもミリ秒単位で完了します。
例: トークンベース検索の使用方法
トークンベース検索の使用方法を説明するため、以降のセクションでは、ベクトル検索でスパース エンベディングを生成し、それを使用してインデックスを作成するコード例を示します。
このサンプルコードを試すには、ノートブック「セマンティック検索とキーワード検索の組み合わせ: Vertex AI ベクトル検索を使用したハイブリッド検索のチュートリアル」を使用します。
最初のステップは、入力データの形式と構造で説明されているデータ形式に基づいて、スパース エンベディングのインデックスを構築するためのデータファイルを準備することです。
JSON では、データファイルは次のようになります。
{"id": "3", "sparse_embedding": {"values": [0.1, 0.2], "dimensions": [1, 4]}}
{"id": "4", "sparse_embedding": {"values": [-0.4, 0.2, -1.3], "dimensions": [10, 20, 30]}}
各アイテムには、values プロパティと dimensions プロパティを持つ sparse_embedding プロパティが必要です。スパース エンベディングには数千のディメンションがあり、ゼロ以外の値はほとんどありません。このデータ形式は、ゼロ以外の値と、空間内におけるそれらの位置のみが含まれているため、効率的に機能します。
サンプル データセットを準備する
サンプル データセットとして、Google ブランドの商品が約 200 行含まれる Google Merch Shop データセットを使用します。
0 Google Sticker
1 Google Cloud Sticker
2 Android Black Pen
3 Google Ombre Lime Pen
4 For Everyone Eco Pen
...
197 Google Recycled Black Backpack
198 Google Cascades Unisex Zip Sweater
199 Google Cascades Womens Zip Sweater
200 Google Cloud Skyline Backpack
201 Google City Black Tote Backpack
TF-IDF ベクトライザーを準備する
このデータセットを使用して、ベクトライザーをトレーニングします。ベクトライザーは、テキストからスパース エンベディングを生成するモデルです。この例では、scikit-learn の TfidfVectorizer を使用します。これは、TF-IDF アルゴリズムを使用する基本的なベクトライザーです。
from sklearn.feature_extraction.text import TfidfVectorizer
# Make a list of the item titles
corpus = df.title.tolist()
# Initialize TfidfVectorizer
vectorizer = TfidfVectorizer()
# Fit and Transform
vectorizer.fit_transform(corpus)
変数 corpus には、200 個のアイテム名のリスト(「Google Sticker」や「Chrome Dino Pin」など)が保持されます。次に、コードは fit_transform() 関数を呼び出して、これらの変数をベクトライザーに渡します。これで、ベクトライザーがスパース エンベディングを生成する準備が整います。
TF-IDF ベクトライザーは、データセット内の特徴的な単語(「Shirts」や「Dino」など)に、大きな意味を持たない単語(「The」、「a」、「of」など)よりも高い重みを付けるよう試み、指定されたドキュメントで特徴的な単語が使用された回数をカウントします。スパース エンベディングの各値は、カウントに基づく各単語の頻度を表します。TF-IDF の詳細については、TF-IDF と TfidfVectorizer の仕組みをご覧ください。
この例では、わかりやすくするために、基本的な単語レベルのトークン化と TF-IDF ベクトル化を使用します。本番環境での開発では、要件に基づいて、別の方法でトークン化とベクトル化を行い、スパース エンベディングを生成できます。トークナイザーには、多くの場合、単語レベルのトークン化と比較してパフォーマンスが優れているサブワード トークナイザーがよく選択されます。ベクトライザーには、TF-IDF の改良版として BM25 がよく使用されます。SPLADE は、スパース エンベディングのセマンティクスを取得する、もう一つの一般的なベクトル化アルゴリズムです。
スパース エンベディングを取得する
ベクトル検索でベクトライザーを簡単に使用できるように、ラッパー関数 get_sparse_embedding() を定義します。
def get_sparse_embedding(text):
# Transform Text into TF-IDF Sparse Vector
tfidf_vector = vectorizer.transform([text])
# Create Sparse Embedding for the New Text
values = []
dims = []
for i, tfidf_value in enumerate(tfidf_vector.data):
values.append(float(tfidf_value))
dims.append(int(tfidf_vector.indices[i]))
return {"values": values, "dimensions": dims}
この関数は、パラメータ「text」をベクトライザーに渡して、スパース エンベディングを生成します。次に、ベクトル検索のスパース インデックスの作成で説明した {"values": ...., "dimensions": ...} 形式に変換します。
次のようにして、この関数をテストできます。
text_text = "Chrome Dino Pin"
get_sparse_embedding(text_text)
次のようなスパース エンベディングが出力されます。
{'values': [0.6756557405747007, 0.5212913389979028, 0.5212913389979028],
'dimensions': [157, 48, 33]}
入力データファイルを作成する
この例では、200 個のアイテムすべてに対してスパース エンベディングを生成します。
items = []
for i in range(len(df)):
id = i
title = df.title[i]
sparse_embedding = get_sparse_embedding(title)
items.append({"id": id, "title": title, "sparse_embedding": sparse_embedding})
このコードは、アイテムごとに次の行を生成します。
{
'id': 0,
'title': 'Google Sticker',
'sparse_embedding': {
'values': [0.933008728540452, 0.359853737603667],
'dimensions': [191, 78]
}
}
次に、これらの行を JSONL ファイル「items.json」として保存し、Cloud Storage バケットにアップロードします。
# output as a JSONL file and save to bucket
with open("items.json", "w") as f:
for item in items:
f.write(f"{item}\n")
! gcloud storage cp items.json $BUCKET_URI
ベクトル検索でスパース エンベディング インデックスを作成する
次に、ベクトル検索でスパース エンベディング インデックスを構築してデプロイします。これは、ベクトル検索のクイックスタートに記載されている手順と同じです。
# create Index
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = f"vs-hybridsearch-index-{UID}",
contents_delta_uri = BUCKET_URI,
dimensions = 768,
approximate_neighbors_count = 10,
)
インデックスを使用するには、インデックス エンドポイントを作成する必要があります。これは、インデックスに対するクエリ リクエストを受け入れるサーバー インスタンスとして機能します。
# create IndexEndpoint
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = f"vs-quickstart-index-endpoint-{UID}",
public_endpoint_enabled = True
)
インデックス エンドポイントでは、デプロイされる一意のインデックス ID を指定してインデックスをデプロイします。
DEPLOYED_INDEX_ID = f"vs_quickstart_deployed_{UID}"
# deploy the Index to the Index Endpoint
my_index_endpoint.deploy_index(
index = my_index, deployed_index_id = DEPLOYED_INDEX_ID
)
デプロイが完了したら、テストクエリを実行できます。
スパース エンベディング インデックスを使用してクエリを実行する
スパース エンベディング インデックスを使用してクエリを実行するには、次の例のように、クエリテキストのスパース エンベディングをカプセル化する HybridQuery オブジェクトを作成する必要があります。
from google.cloud.aiplatform.matching_engine.matching_engine_index_endpoint import HybridQuery
# create HybridQuery
query_text = "Kids"
query_emb = get_sparse_embedding(query_text)
query = HybridQuery(
sparse_embedding_dimensions=query_emb['dimensions'],
sparse_embedding_values=query_emb['values'],
)
このサンプルコードでは、クエリに「Kids」というテキストを使用しています。次に、HybridQuery オブジェクトを使用してクエリを実行します。
# build a query request
response = my_index_endpoint.find_neighbors(
deployed_index_id=DEPLOYED_INDEX_ID,
queries=[query],
num_neighbors=5,
)
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
print(f"{title:<40}")
次のような出力が表示されます。
Google Blue Kids Sunglasses
Google Red Kids Sunglasses
YouTube Kids Coloring Pencils
YouTube Kids Character Sticker Sheet
200 個のアイテムのうち、キーワード「Kids」を含むアイテム名が結果に含まれます。
例: ハイブリッド検索の使用方法
この例では、トークンベース検索とセマンティック検索を組み合わせて、ベクトル検索でのハイブリッド検索を作成します。
ハイブリッド インデックスの作成方法
ハイブリッド インデックスを構築するには、各アイテムに「embedding」(高密度エンベディング用)と「sparse_embedding」の両方が必要です。
items = []
for i in range(len(df)):
id = i
title = df.title[i]
dense_embedding = get_dense_embedding(title)
sparse_embedding = get_sparse_embedding(title)
items.append(
{"id": id, "title": title,
"embedding": dense_embedding,
"sparse_embedding": sparse_embedding,}
)
items[0]
get_dense_embedding() 関数は、Vertex AI Embedding API を使用して、768 次元のテキスト エンベディングを生成します。これにより、次の形式で高密度エンベディングとスパース エンベディングの両方が生成されます。
{
"id": 0,
"title": "Google Sticker",
"embedding":
[0.022880317643284798,
-0.03315234184265137,
...
-0.03309667482972145,
0.04621824622154236],
"sparse_embedding": {
"values": [0.933008728540452, 0.359853737603667],
"dimensions": [191, 78]
}
}
残りのプロセスは、例: トークンベース検索の使用方法と同じです。JSONL ファイルを Cloud Storage バケットにアップロードし、そのファイルでベクトル検索インデックスを作成して、インデックス エンドポイントにデプロイします。
ハイブリッド クエリを実行する
ハイブリッド インデックスをデプロイしたら、ハイブリッド クエリを実行できます。
# create HybridQuery
query_text = "Kids"
query_dense_emb = get_dense_embedding(query_text)
query_sparse_emb = get_sparse_embedding(query_text)
query = HybridQuery(
dense_embedding=query_dense_emb,
sparse_embedding_dimensions=query_sparse_emb['dimensions'],
sparse_embedding_values=query_sparse_emb['values'],
rrf_ranking_alpha=0.5,
)
クエリテキスト「Kids」に対して、その単語の高密度エンベディングとスパース エンベディングの両方を生成し、HybridQuery オブジェクトにカプセル化します。前の HybridQuery との違いは、dense_embedding と rrf_ranking_alpha の 2 つのパラメータが追加されている点です。
今回は、各アイテムの距離を出力します。
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
dense_dist = neighbor.distance if neighbor.distance else 0.0
sparse_dist = neighbor.sparse_distance if neighbor.sparse_distance else 0.0
print(f"{title:<40}: dense_dist: {dense_dist:.3f}, sparse_dist: {sparse_dist:.3f}")
各 neighbor オブジェクトには、高密度エンベディングでのクエリとアイテム間の距離を示す distance プロパティと、スパース エンベディングでの距離を示す sparse_distance プロパティがあります。これらの値は距離の逆数であるため、値が大きいほど距離が短いことを意味します。
HybridQuery を使用してクエリを実行すると、次の結果が得られます。
Google Blue Kids Sunglasses : dense_dist: 0.677, sparse_dist: 0.606
Google Red Kids Sunglasses : dense_dist: 0.665, sparse_dist: 0.572
YouTube Kids Coloring Pencils : dense_dist: 0.655, sparse_dist: 0.478
YouTube Kids Character Sticker Sheet : dense_dist: 0.644, sparse_dist: 0.468
Google White Classic Youth Tee : dense_dist: 0.645, sparse_dist: 0.000
Google Doogler Youth Tee : dense_dist: 0.639, sparse_dist: 0.000
Google Indigo Youth Tee : dense_dist: 0.637, sparse_dist: 0.000
Google Black Classic Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Chrome Dino Glow-in-the-Dark Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Google Bike Youth Tee : dense_dist: 0.629, sparse_dist: 0.000
「Kids」というキーワードを含むトークンベース検索結果に加えて、セマンティック検索結果も含まれます。たとえば、「Google White Classic Youth Tee」が含まれるのは、「Youth」と「Kids」が意味的に類似していることをエンベディング モデルが認識しているためです。
ハイブリッド検索では、トークンベース検索結果とセマンティック検索結果を統合するために、Reciprocal Rank Fusion(RRF)を使用します。RRF と rrf_ranking_alpha パラメータの指定方法の詳細については、Reciprocal Rank Fusion とはをご覧ください。
再ランキング
RRF は、セマンティック検索結果とトークンベース検索結果のランキングを統合する方法を提供します。多くの本番環境の情報検索システムや Recommender システムでは、結果はさらに適合率ランキング アルゴリズムで処理されます(いわゆる再ランキング)。ミリ秒レベルの高速検索をベクトル検索および結果の適合率再ランキングと組み合わせることで、検索品質やレコメンデーションのパフォーマンスを高めるマルチステージ システムを構築できます。
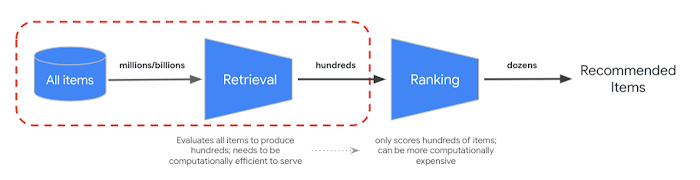
Vertex AI Ranking API では、事前トレーニング済みモデルを使用する、クエリテキストと検索結果テキストの一般的な関連性に基づいたランキングを実装する方法を説明します。TensorFlow Ranking では、さまざまなビジネス要件に合わせてカスタマイズできる高度な再ランキング用に、ランク学習(LTR)モデルを設計してトレーニングする方法についても説明します。
ハイブリッド検索の使用を開始する
ベクトル検索でハイブリッド検索を使用する際に役立つリソースは次のとおりです。
ハイブリッド検索のリソース
- セマンティック検索とキーワード検索の組み合わせ: Vertex AI ベクトル検索を使用したハイブリッド検索のチュートリアル: ハイブリッド検索のスタートガイド用のサンプル ノートブック
- 入力データの形式と構造: スパース エンベディング インデックスの構築に使用する入力データ形式
- パブリック インデックスをクエリして最近傍を取得する: ハイブリッド検索でクエリを実行する方法
- Condorcet および個別のランキング学習方法を上回る Reciprocal Rank Fusion: RRF アルゴリズムの説明
ベクトル検索のリソース
その他のコンセプト
以降のセクションでは、TF-IDF と TfidVectorizer、Reciprical Rank Fusion、α パラメータについて詳しく説明します。
TF-IDF と TfidfVectorizer の仕組み
fit_transform() 関数は、TF-IDF アルゴリズムの 2 つの重要なプロセスを実行します。
Fit: ベクトライザーは、語彙内の各用語の逆文書頻度(IDF)を計算します。IDF は、コーパス全体で用語の重要度を反映します。まれな用語は IDF スコアが高くなります。
IDF(t) = log_e(Total number of documents / Number of documents containing term t)変換:
- トークン化: ドキュメントを個々の用語(単語またはフレーズ)に分割します。
用語頻度(TF)の計算: 各用語が各ドキュメントに出現する頻度を次のようにしてカウントします。
TF(t, d) = (Number of times term t appears in document d) / (Total number of terms in document d)TF-IDF 計算: 各用語の TF と事前計算された IDF を組み合わせて、TF-IDF スコアを作成します。このスコアは、コーパス全体に対する特定のドキュメント内の用語の重要性を表します。
TF-IDF(t, d) = TF(t, d) * IDF(t)TF-IDF ベクトライザーは、データセット内の特徴的な単語(「Shirts」や「Dino」など)に、大きな意味を持たない単語(「The」、「a」、「of」など)よりも高い重みを付けるよう試み、指定されたドキュメントで特徴的な単語が使用された回数をカウントします。スパース エンベディングの各値は、カウントに基づく各単語の頻度を表します。
Reciprocal Rank Fusion とは
ハイブリッド検索では、トークンベース検索結果とセマンティック検索結果を統合するために、Reciprocal Rank Fusion(RRF)を使用します。RRF は、複数のアイテムのランキング リストを組み合わせて単一の統合ランキングにするアルゴリズムです。これは、さまざまなソースや取得方法からの検索結果を統合する一般的な手法で、特に、ハイブリッド検索システムや大規模言語モデルで使用されます。
ベクトル検索のハイブリッド検索の場合、高密度距離とスパース距離は異なる空間で測定されるため、直接比較することはできません。RRF は、2 つの異なる空間の結果を統合してランク付けするうえで効果的です。
RRF の概要は次のとおりです。
- 逆数ランク: ランキング リスト内の各アイテムについて、その逆数ランクを計算します。つまり、リスト内のアイテムの位置(ランク)の逆数を取得します。たとえば、1 位のアイテムは逆数ランク 1/1 = 1 を取得し、2 位のアイテムは 1/2 = 0.5 を取得します。
- 逆数ランクの合計: アイテムごとに、すべてのランキング リストの逆数ランクを合計します。これにより、各アイテムの最終的なスコアが得られます。
- 最終スコアで並べ替え: 最終スコアが高い順にアイテムを並べ替えます。スコアが最も高いアイテムが、最も関連性が高い、または重要な項目と見なされます。
つまり、高密度の結果とスパースの結果の両方でランクが高いアイテムがリストの上位にきます。そのため、高密度の検索結果とスパースの検索結果の両方で上位にランキングされた「Google Blue Kids Sunglasses」が最上位になります。「Google White Classic Youth Tee」などのアイテムは、高密度の検索結果でのみランクが付けられているため、ランクが低くなります。
α パラメータの動作
ハイブリッド検索の使用方法の例では、HybridQuery オブジェクトを作成するときにパラメータ rrf_ranking_alpha を 0.5 に設定しています。rrf_ranking_alpha に次の値を使用して、高密度の検索結果とスパースの検索結果のランキングに重み付けを指定できます。
1、または指定なし: ハイブリッド検索では、高密度の検索結果のみが使用され、スパースの検索結果は無視されます。0: ハイブリッド検索では、スパースの検索結果のみが使用され、高密度の検索結果は無視されます。0~1: ハイブリッド検索では、値で指定された重みを使用して、高密度とスパースの両方の結果が統合されます。0.5 は、同じ重みで統合されることを意味します。