Utilizza la Google Cloud console per controllare il rendimento del modello. Analizza gli errori di test per migliorare in modo iterativo la qualità del modello correggendo i problemi relativi ai dati.
Questo tutorial è composto da diverse pagine:
Crea un set di dati per la classificazione delle immagini e importa le immagini.
Addestra un modello di classificazione delle immagini AutoML.
Valutare e analizzare le prestazioni del modello.
Esegui il deployment di un modello in un endpoint e invia una previsione.
Ogni pagina presuppone che tu abbia già eseguito le istruzioni riportate nelle pagine precedenti del tutorial.
1. Informazioni sui risultati della valutazione del modello AutoML
Al termine dell'addestramento, il modello viene valutato automaticamente in base alla suddivisione dei dati di test. I risultati della valutazione corrispondente vengono visualizzati facendo clic sul nome del modello nella pagina Registro dei modelli o nella pagina Set di dati.
Da qui puoi trovare le metriche per misurare le prestazioni del modello.
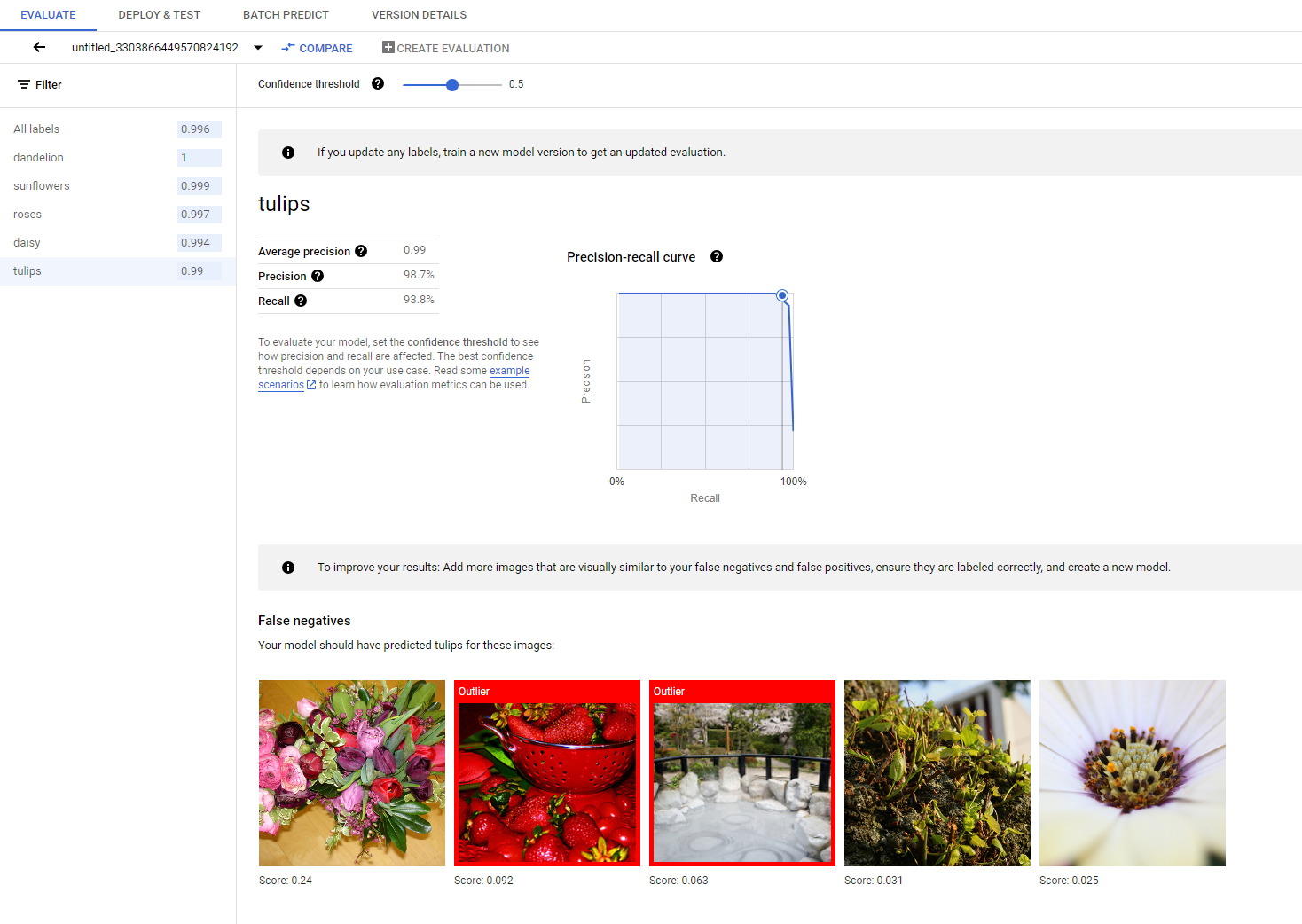
Puoi trovare un'introduzione più dettagliata alle diverse metriche di valutazione nella sezione Valutare, testare ed eseguire il deployment del modello.
2. Analizzare i risultati dei test
Se vuoi continuare a migliorare il rendimento del modello, spesso il primo passaggio consiste nell'esaminare i casi di errore e indagare sulle potenziali cause. La pagina di valutazione di ogni classe presenta immagini di test dettagliate della classe in questione classificate come falsi negativi, falsi positivi e veri positivi. La definizione di ogni categoria è disponibile nella sezione Valutare, testare ed eseguire il deployment del modello.
Per ogni immagine in ogni categoria, puoi controllare ulteriormente i dettagli della previsione facendo clic sull'immagine e accedere ai risultati dell'analisi dettagliata. Sul lato destro della pagina vedrai il riquadro Esamina immagini simili, in cui i campioni più vicini del set di addestramento sono presentati con le distanze misurate nello spazio delle funzionalità.
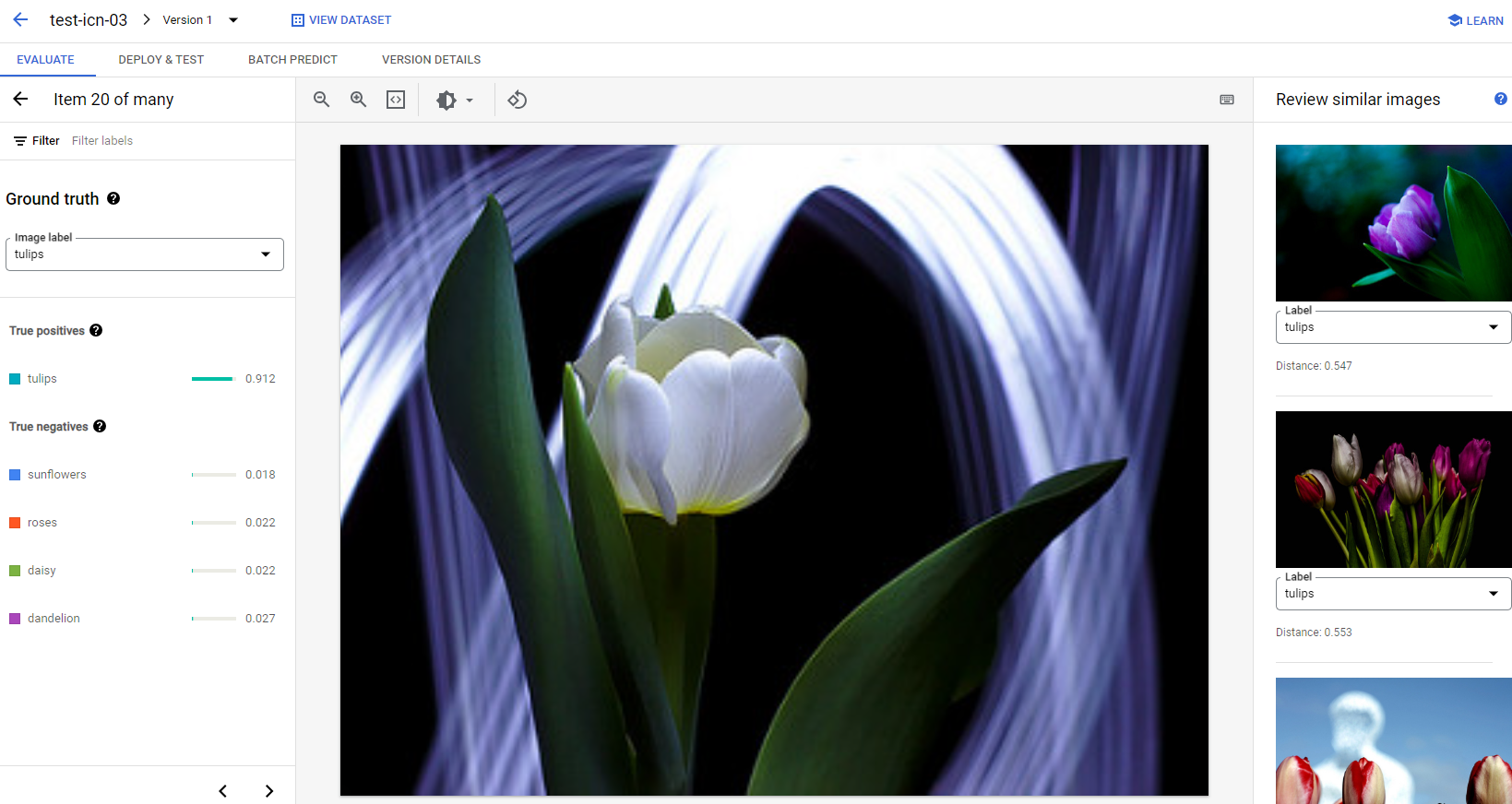
Esistono due tipi di problemi relativi ai dati che potrebbero richiedere la tua attenzione:
Mancata coerenza delle etichette. Se un campione visivamente simile del set di addestramento ha etichette diverse rispetto al campione di test, è possibile che una delle due sia errata, che la differenza sottile richieda più dati per l'apprendimento del modello o che le etichette di classe attuali non siano semplicemente abbastanza precise per descrivere il campione in questione. La revisione di immagini simili può aiutarti a ottenere informazioni accurate sulle etichette correggendo i casi di errore o escludendo il campione problematico dal set di test. Puoi modificare facilmente l'etichetta dell'immagine di test o delle immagini di addestramento nel riquadro Esamina immagini simili nella stessa pagina.
Valori anomali. Se un campione di test è contrassegnato come outlier, è possibile che nel set di addestramento non siano presenti campioni visivamente simili che possano contribuire ad addestrare il modello. Esaminare immagini simili del set di addestramento può aiutarti a identificare questi campioni e ad aggiungere immagini simili al set di addestramento per migliorare ulteriormente le prestazioni del modello in questi casi.
Passaggi successivi
Se ritieni che le prestazioni del modello vadano bene, segui la pagina successiva di questo tutorial per eseguire il deployment del modello AutoML addestrato in un endpoint e inviare un'immagine al modello per la previsione. In caso contrario, se apporti correzioni ai dati, addestra un nuovo modello utilizzando il tutorial Addestramento di un modello di classificazione delle immagini AutoML.