本页面假定您已完成了这些教程并将概述神经架构搜索的最佳实践。第一部分汇总了完整的工作流,您可以在神经架构搜索作业中按照这些工作流执行操作。其他部分提供了每个步骤的详细说明。我们强烈建议您在运行第一个神经架构搜索作业之前先完成这一整个页面的学习。
建议的工作流
下面,我们总结了神经架构搜索的建议工作流,并提供了指向相应部分详细说明的链接:
- 为第 1 阶段搜索拆分训练数据集。
- 确保您的搜索空间遵循相关准则。
- 使用基准模型运行完整训练并获取验证曲线。
- 运行代理任务设计工具以找到最佳代理任务。
- 对代理任务进行最终检查。
- 设置适当的试验总次数和并行试验次数,然后开始搜索。
- 监控搜索曲线图,并在出现收敛或显示大量错误或没有显示任何收敛迹象时停止搜索。
- 使用搜索到的大约前 10 个试验运行完整训练,以获得最终结果。对于完整训练,您可以使用更多增强或预训练权重来获得可能的最佳性能。
- 分析从搜索中保存出来的指标/数据并得出结论,以用于后续的搜索空间迭代。
典型的神经架构搜索

上图显示了典型的神经架构搜索曲线。此处,Y-axis 显示试验奖励,X-axis 显示到目前为止已启动的试验次数。大约前 100 至 200 次试验主要是控制器对搜索空间的随机探索。在这些初始探索期间,奖励会显示出很大的方差值,因为系统正在对搜索空间中的多种模型进行试验。随着试验次数的增加,控制器会开始寻找更好的模型。因此,奖励会首先开始增大,随后奖励方差也会增大,之后奖励增长开始减小,从而呈现收敛。虽然出现收敛所需的试验次数可能会随搜索空间的大小而变化,但通常会在大约 2000 次试验以上才会出现收敛。
神经架构搜索的两个阶段:代理任务和完整训练
神经架构搜索分为两个阶段:
第 1 阶段搜索使用完整训练中非常小的一部分数据作为其表示形式,该阶段通常在大约 1 至 2 小时内完成。该表示法称为代理任务,它有助于降低搜索费用。
第 2 阶段完整训练会对第 1 阶段搜索中的大约前 10 个评分模型进行完整训练。由于搜索具有随机性,第 1 阶段搜索中的最顶层模型在第 2 阶段完整训练期间可能不是最顶层模型,因此务必选择用于完整训练的模型池。
由于控制器从较小的代理任务而不是完整的训练中获取奖励信号,因此为您的任务找到最佳代理任务非常重要。
神经架构搜索费用
神经架构搜索费用可通过以下公式计算:search-cost = num-trials-to-converge * avg-proxy-task-cost。假设代理任务计算时间约为完整训练时间的 1/30,并且出现收敛所需的试验次数约为 2000 次,那么搜索费用约为 67 * full-training-cost。
由于神经架构搜索费用较高,因此建议您花时间微调代理任务,并在首次搜索时使用较小的搜索空间。
在神经架构搜索的两个阶段之间拆分数据集
假设您已有用于基准训练的训练数据和验证数据,那么建议您对 NAS 神经架构搜索的两个阶段进行如下数据集拆分:
- 针对第 1 阶段搜索的训练:约 90% 的训练数据
针对第 1 阶段搜索的验证:约 10% 的训练数据
针对第 2 阶段完整训练的训练:100% 的训练数据
针对第 2 阶段完整训练的验证:100% 的验证数据
第 2 阶段完整训练的数据拆分与常规训练相同。但是,第 1 阶段搜索会在验证过程中拆分训练数据。在第 1 阶段和第 2 阶段中使用不同的验证数据有助于检测由于数据集拆分而导致的任何模型搜索偏差。确保训练数据在经过进一步分区之前进行很好地重排,并且最终 10% 的训练数据拆分具有与原始验证数据类似的分布。
小型数据或不均衡数据
如果训练数据有限,或者对于高度不均衡的数据集(其中某些类非常少),则不建议使用架构搜索。如果您已经由于缺少数据而对基准训练使用大量增强,则不建议使用模型搜索。
在这种情况下,您只能运行增强搜索来搜索最佳增强政策,而不是搜索最优架构。
搜索空间设计
架构搜索不应与增强搜索或超参数搜索(例如学习速率或优化器设置)混用。架构搜索的目标是在只有基于架构的差异时将模型 A 的性能与模型 B 进行比较。因此,增强和超参数设置应该保持不变。
增强搜索可以在架构搜索完成后作为其他阶段完成。
神经架构搜索的搜索空间大小上限为 10^20。但是,如果您的搜索空间较大,则可以将搜索空间划分为多个互斥的部分。例如,您可以首先从解码器或标头单独搜索编码器。如果您仍希望对所有内容进行联合搜索,则可以基于之前找到的最佳个体选项创建较小的搜索空间。
(可选)在设计搜索空间时,您可以将模型扩缩与块设计分离开来。您应首先使用缩减的模型完成块设计搜索;这样可以大幅降低代理任务运行时的费用。然后,您可以执行单独的搜索来将模型扩容。如需了解详情,请参阅
Examples of scaled down models。
优化训练和搜索时间
在运行神经架构搜索之前,请务必先优化基准模型的训练时间。从长远来看,这样将可以为您节省相关费用。以下是用于优化训练的一些方案:
- 最大限度地提高数据加载速度:
- 确保数据所在的存储桶与作业位于同一区域。
- 如果使用 TensorFlow,请参阅
Best practice summary。您还可以尝试为数据使用 TFRecord 格式。 - 如果使用 PyTorch,请遵循高效 PyTorch 训练的准则。
- 使用分布式训练来利用多个加速器或多台机器。
- 使用混合精度训练,以显著提高训练速度并减少内存用量。如需了解 TensorFlow 混合精度训练,请参阅
Mixed Precision。 - 某些加速器(例如 A100)通常更经济实惠。
- 调整批次大小以确保最大限度地提高 GPU 利用率。下图显示了一些利用率低下 (50%) 的 GPU。
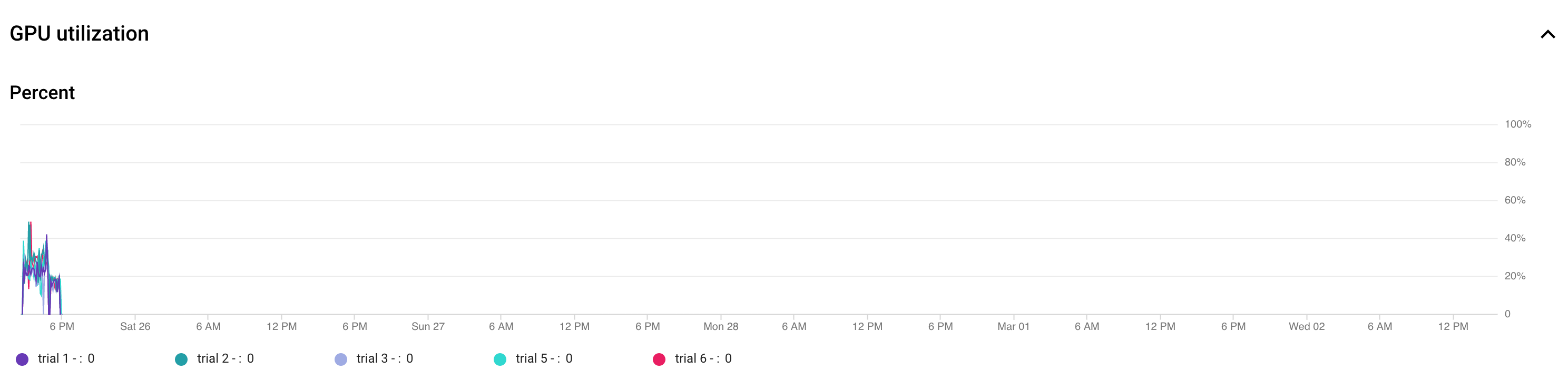 增加批次大小有助于提高 GPU 利用率。但是,应谨慎增加批次大小,因为这样做可能会使搜索期间的内存不足错误增多。
增加批次大小有助于提高 GPU 利用率。但是,应谨慎增加批次大小,因为这样做可能会使搜索期间的内存不足错误增多。 - 如果某些架构块与搜索空间无关,那么您可以尝试为这些块加载预训练的检查点,以加快训练速度。预训练的检查点应在整个搜索空间中保持相同,并且不应引入偏差。例如,如果您的搜索空间仅用于解码器,那么编码器可以使用预训练的检查点。
每个搜索试验使用的 GPU 数量
减少每个试验的 GPU 数量,以缩短开始时间。 例如,2 个 GPU 启动需要 5 分钟,而 8 个 GPU 启动需要 20 分钟。 更高效的做法是每个试验使用 2 个 GPU 来运行神经架构搜索作业的代理任务。
搜索的试验总次数和并行试验次数
试验总次数设置
搜索并选择最佳代理任务后,您就可以启动完整搜索了。您无法事先了解需要进行多少次试验才能达到收敛。 出现收敛所需的试验次数可能因搜索空间大小而异,但通常需要约 2,000 次试验。
我们建议将 --max_nas_trial 设置为非常大的值:大约 5,000-10,000,然后如果搜索曲线图显示收敛,便提前取消搜索作业。您还可以选择使用 search_resume 命令恢复之前的搜索作业。但是,您无法从另一个搜索恢复作业恢复搜索。
因此,原始搜索作业只能恢复一次。
并行试验次数设置
第 1 阶段搜索作业通过同时并行运行 --max_parallel_nas_trial 次试验来执行批处理。这对于缩短搜索作业的整体运行时至关重要。您可以计算预期的搜索天数:days-required-for-search = (trials-to-converge / max-parallel-nas-trial) * (avg-trial-duration-in-hours / 24)
注意:您可以先使用 3000 作为 trials-to-converge 的粗略预估值,这是一个不错的上限值。您可以先使用 2 小时作为 avg-trial-duration-in-hours 的粗略预估值,这是一个不错的代理任务花费时间上限值。建议将 --max_parallel_nas_trial 设置为大约 20 到 50,具体取决于项目的加速器配额以及 days-required-for-search。例如,如果您将 --max_parallel_nas_trial 设置为 20,并且每个代理任务使用两个 NVIDIA T4 GPU,则您应该预留至少 40 个 NVIDIA T4 GPU 的配额。--max_parallel_nas_trial 设置不会影响整体搜索结果,但会影响 days-required-for-search。您也可以将 max_parallel_nas_trial 设置为较小的值(例如 10 左右,需要 20 个 GPU),但您应大致估算 days-required-for-search,并确保其不超过作业超时限制。
默认情况下,第 2 阶段完整训练作业通常并行训练所有试验。通常是并行运行前 10 个试验。但是,如果每个第 2 阶段完整训练试验为您的用例使用过多 GPU(例如,每个试验 八个 GPU),并且您没有足够的配额,则可以手动分批运行第 2 阶段作业。例如,先使用五个试验运行第 2 阶段完整训练,然后使用接下来的五个试验运行另一个第 2 阶段完整训练。
默认作业超时
默认的 NAS 作业超时设置为 14 天,之后作业将被取消。如果您预计作业将运行更长时间,可以尝试恢复搜索作业,使其再运行 14 天。您只能恢复一次。搜索作业总共可以运行 28 天(包括恢复运行)。
失败的试验次数上限设置
失败的试验次数上限应设置为 max_nas_trial 设置的 1/3 左右。当失败的试验次数达到此限制时,作业将被取消。
何时停止搜索
在以下情况下,您应该停止搜索:
搜索曲线开始收敛(方差减小):
注意:如果未使用延迟时间限制,或者将硬性延迟限制与宽松延迟限制一起使用,那么曲线可能不会显示奖励增加,但仍然会显示收敛。这是因为控制器可能在搜索的早期就已经获得了很好的准确率。超过 20% 的试验显示无效奖励(失败):
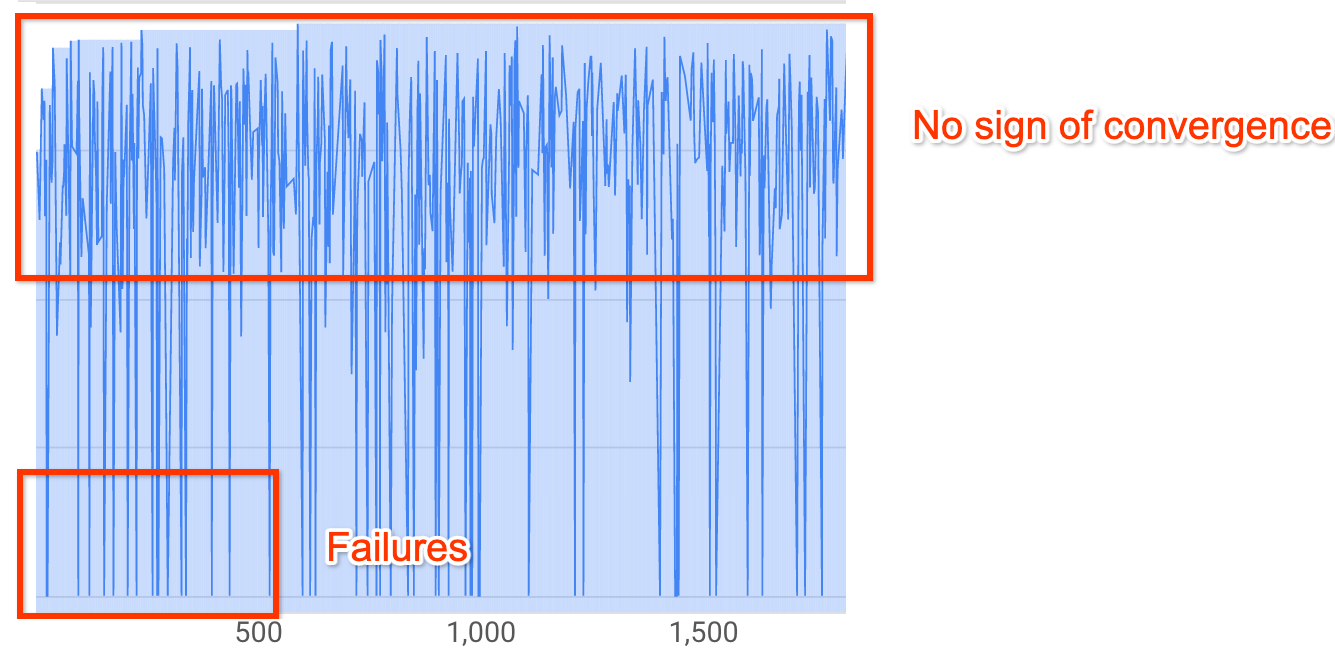
即使在大约 500 次试验之后,搜索曲线仍然既不增加也不收敛(如上图所示)。如果显示出任何奖励增加或方差减小,则您可以继续执行搜索。