Supondo que você já tenha executado os tutoriais, esta página descreve as práticas recomendadas para a pesquisa de arquitetura neural. A primeira seção resumimos um fluxo de trabalho completo que pode ser seguido para o job de pesquisa de arquitetura neural. As outras seções fornecem uma descrição detalhada de cada etapa. É altamente recomendável percorrer esta página antes de executar seu primeiro job de pesquisa de arquitetura neural.
Fluxo de trabalho sugerido
Aqui, resumimos um fluxo de trabalho sugerido para a pesquisa de arquitetura neural e fornecemos links para as seções correspondentes para mais detalhes:
- Dividir o conjunto de dados de treinamento para a pesquisa de nível 1.
- Verifique se o espaço de pesquisa segue nossas diretrizes.
- Executar treinamento completo com o modelo de valor de referência e conseguir uma curva de validação.
- Execute ferramentas de design de tarefa de proxy para encontrar a melhor tarefa de proxy.
- Faça as verificações finais para a tarefa de proxy.
- Defina o número adequado de testes totais e paralelos e inicie a pesquisa.
- Monitore o gráfico de pesquisa e interrompa-o quando ele converge ou mostra um grande número de erros ou não mostra sinais de convergência.
- Faça um treinamento completo com os 10 testes principais selecionados da sua pesquisa para o resultado final. Para o treinamento completo, é possível usar mais pesos de aumento ou pré-treinado para ter o melhor desempenho possível.
- Analise as métricas/os dados salvos da pesquisa e tire conclusões para futuras iterações de espaço de pesquisa.
Pesquisa de arquitetura neural típica

A figura acima mostra uma típica curva de pesquisa de arquitetura neural.
O Y-axis mostra aqui as recompensas do teste, e o
X-axis mostra o número de testes lançados até o momento.
Os primeiros 100 a 200 testes são, na maioria das vezes, explorações aleatórias do espaço de pesquisa pelo controlador.
Durante essas explorações iniciais, as recompensas mostram
uma grande variação porque muitos tipos de modelos no
espaço de pesquisa estão sendo testados.
À medida que o número de testes aumenta, o controlador começa a encontrar modelos melhores. Portanto, primeiro o prêmio começa a aumentar e, depois, a variação e o crescimento do prêmio começa a diminuir assim, mostrando a convergência. O número de testes
em que a convergência acontece pode variar com base no
tamanho do espaço de pesquisa, mas normalmente fica na ordem de aproximadamente 2.000 testes.
Duas etapas da pesquisa de arquitetura neural: treinamento de proxy e treinamento completo
A pesquisa de arquitetura neural funciona em dois estágios:
O Stage1-search usa uma representação muito menor do treinamento completo, que normalmente termina dentro de aproximadamente uma ou duas horas. Essa representação é chamada de tarefa de proxy e ajuda a manter o custo da pesquisa baixo.
O Stage2-full-training envolve treinamento completo para os cerca de 10 modelos de pontuação superiores a partir da stage1-search. Devido à natureza estocástica da pesquisa, o modelo de nível superior da stage1-search pode não ser o modelo superior durante o stage2-full-training e, portanto, é importante selecionar um pool de modelos para treinamento completo.
Como o controlador recebe o sinal de recompensa da tarefa menor de proxy em vez do treinamento completo, é importante encontrar uma tarefa de proxy ideal para a tarefa.
Custo da pesquisa de arquitetura neural
O custo da pesquisa de arquitetura neural é determinado pelo seguinte:
search-cost = num-trials-to-converge * avg-proxy-task-cost.
Supondo que o tempo de computação da proxy-tarefa seja de cerca de 1/30 do tempo de treinamento completo e que o número de testes necessários para convergência seja de cerca de 2.000, então o
custo de pesquisa torna-se aproximadamente 67 * full-training-cost.
Como o custo da pesquisa de arquitetura neural é alto, é aconselhável reservar um tempo para o ajuste da tarefa de proxy e usar um espaço de pesquisa menor para a primeira pesquisa.
Divisão de conjunto de dados entre dois estágios da pesquisa de arquitetura neural
Se você já tem os dados de treinamento e os dados de validação para seu treinamento de valor de referência, a divisão com conjunto de dados a seguir é recomendada para as duas etapas da Pesquisa de arquitetura neural NAS:
- Treinamento da Stage1-search: aproximadamente 90% dos dados de treinamento
Validação da Stage1-search: aproximadamente 10% dos dados de treinamento
Treinamento do Stage2-full-training: 100% dos dados de treinamento
Validação do Stage2-full-training: 100% dos dados de validação
A divisão de dados do stage2-full-training é igual ao treinamento regular. Mas a stage1-search usa uma divisão de dados de treinamento para validação. O uso de diferentes dados de validação no estágios 1 e 2 ajuda a detectar qualquer viés de pesquisa de modelos devido à divisão do conjunto de dados. Verifique se os dados de treinamento estão bem embaralhados antes de particionar ainda mais e se a divisão de dados de treinamento dos 10% finais tem distribuição semelhante aos dados de validação originais.
Dados pequenos ou desequilibrados
A pesquisa de arquitetura não é recomendada com dados de treinamento limitados ou para conjuntos de dados altamente desequilibrados em que algumas classes são muito raras. Se você já estiver usando aumentos pesados no treinamento de referência por causa da falta de dados, a pesquisa de modelos não é recomendada.
Nesse caso, só é possível executar augmentation-search para procurar a melhor política de ampliação, em vez de procurar uma arquitetura ideal.
Design de espaço de pesquisa
A pesquisa de arquitetura não deve ser combinada com a pesquisa de ampliação ou de hiperparâmetros (como taxa de aprendizado ou configurações do otimizador). O objetivo da pesquisa de arquitetura é comparar o desempenho do modelo-A com o modelo-B quando há apenas diferenças baseadas na arquitetura. Portanto, as configurações de aumento e de hiperparâmetros precisam permanecer as mesmas.
A pesquisa de ampliação pode ser feita como outra etapa após a conclusão da pesquisa de arquitetura.
A pesquisa de arquitetura neural pode chegar a 10^20 no tamanho do espaço de pesquisa. No entanto, se o espaço de pesquisa for maior, será possível dividi-lo em partes mutuamente exclusivas. Por exemplo, é possível pesquisar o codificador separadamente do decodificador ou do cabeçalho. Se você ainda quiser fazer uma pesquisa conjunta em todos eles, crie um espaço de pesquisa menor em torno das melhores opções individuais encontradas anteriormente.
(Opcional) É possível dimensionar o modelo a partir do block-design ao projetar um espaço de pesquisa. Essa pesquisa deve ser feita primeiro com um modelo reduzido. Isso pode manter o custo do ambiente de execução da tarefa de proxy muito mais baixo. Em seguida, faça uma pesquisa separada para escalonar o modelo. Para ver mais informações, consulte
Examples of scaled down models.
Como otimizar o tempo de treinamento e pesquisa
Antes de executar a pesquisa de arquitetura neural, é importante otimizar o tempo de treinamento do modelo de referência. Isso reduzirá os custos a longo prazo. Veja a seguir algumas opções para otimizar o treinamento:
- Maximize a velocidade de carregamento de dados:
- Verifique se o bucket em que os dados estão armazenados está na mesma região do job.
- Se você estiver usando o TensorFlow, consulte
Best practice summary. Você também pode usar o formato TFRecord para seus dados. - Se estiver usando o PyTorch, siga as diretrizes para treinamento eficiente do PyTorch.
- Use o treinamento distribuído para aproveitar vários aceleradores ou várias máquinas.
- Use o treinamento de precisão mista
para ter uma aceleração significativa no treinamento e reduzir o uso de memória.
Para o treinamento de precisão mista do TensorFlow,
consulte
Mixed Precision. - Alguns aceleradores (como o A100) normalmente são mais econômicos.
- Ajuste o tamanho do lote para maximizar a utilização da GPU.
O gráfico a seguir mostra a subutilização das GPUs (a 50%).
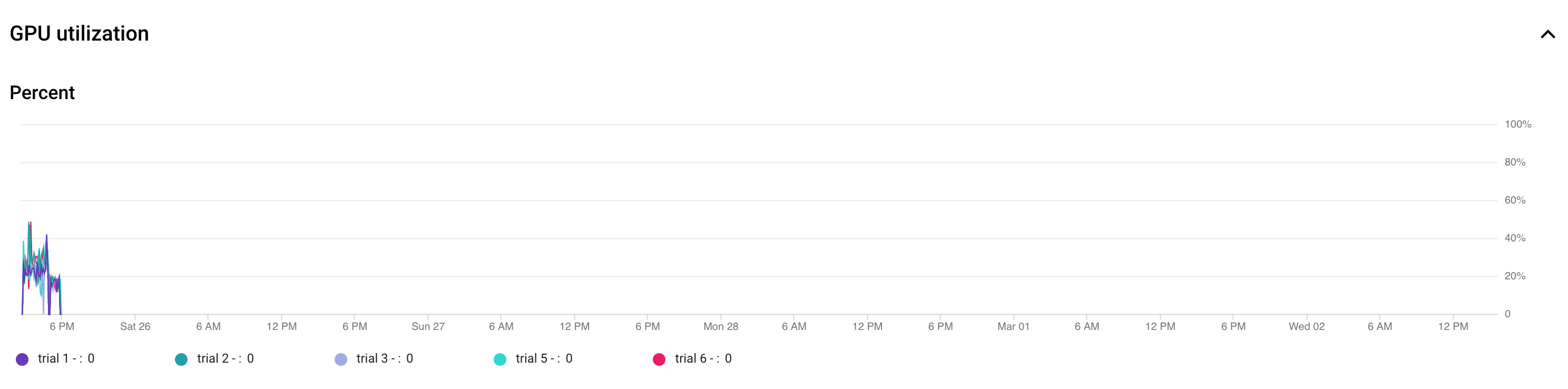 Aumentar o tamanho do lote pode ajudar mais a usar GPUs. No entanto, o tamanho do lote
precisa ser aumentado com cuidado, já que isso pode aumentar
erros de falta de memória durante a pesquisa.
Aumentar o tamanho do lote pode ajudar mais a usar GPUs. No entanto, o tamanho do lote
precisa ser aumentado com cuidado, já que isso pode aumentar
erros de falta de memória durante a pesquisa. - Se determinados blocos de arquitetura forem independentes do espaço de pesquisa, tente carregar checkpoints pré-treinados para esses blocos para treinamento mais rápido. Os checkpoints pré-treinados precisam ser iguais sobre o espaço de pesquisa e não introduzirão um viés. Por exemplo, se o espaço de pesquisa for apenas para o decodificador, o codificador poderá usar checkpoints pré-treinados.
Número de GPUs de cada teste de pesquisa
Use um número menor de GPUs por teste para reduzir o tempo de início. Por exemplo, duas GPUs levam cinco minutos para iniciar, enquanto oito GPUs levam 20 minutos. É mais eficiente usar duas GPUs por teste para executar uma tarefa de proxy do job de pesquisa de arquitetura neural.
Total de testes e testes paralelos da pesquisa
Configuração do teste total
Depois de pesquisar e selecionar a melhor tarefa de proxy, você já pode iniciar uma pesquisa completa. Não é possível saber antecipadamente quantos testes serão necessários para convergir. O número de testes em que a convergência ocorre pode variar com base no tamanho do espaço de pesquisa, mas normalmente é da ordem de aproximadamente 2.000 testes.
Recomendamos uma configuração muito alta para a --max_nas_trial: aproximadamente de 5.000 a 10.000 e, em seguida,cancelar o job de pesquisa mais cedo se o gráfico de pesquisa mostrar convergência
Também é possível retomar um job de pesquisa anterior usando
o comando search_resume.
No entanto, não é possível retomar a pesquisa de outro job de retomada.
Portanto, você pode retomar uma vaga de pesquisa original apenas uma vez.
Configuração dos testes paralelos
O job de pesquisa fase 1 realiza o processamento em lote executando --max_parallel_nas_trial número de testes em paralelo por vez. Isso é fundamental para reduzir o tempo de execução geral da vaga de pesquisa. É possível calcular o número esperado de
dias para pesquisa:
days-required-for-search = (trials-to-converge / max-parallel-nas-trial) * (avg-trial-duration-in-hours / 24)
Observação: é possível usar 3000 inicialmente como uma estimativa aproximada de trials-to-converge, o que é uma boa limite superior para começar. Inicialmente, é possível usar 2 horas
como uma estimativa aproximada para avg-trial-duration-in-hours, que
é um bom limite superior para o tempo gasto por cada tarefa de proxy.
É aconselhável usar a configuração --max_parallel_nas_trial de aproximadamente 20 a 50, dependendo de quanta cota do acelerador seu projeto tem e days-required-for-search.
Por exemplo, se você definir --max_parallel_nas_trial como 20 e cada tarefa de proxy usar duas GPUs NVIDIA T4, reserve uma cota de pelo menos 40 GPUs NVIDIA T4. A configuração --max_parallel_nas_trial não afeta o resultado geral da pesquisa, mas afeta o days-required-for-search.
Uma configuração menor para max_parallel_nas_trial, como aproximadamente 10, também é possível (20 GPUs). No entanto, é necessário estimar o days-required-for-search de forma aproximada e verificar se ele está dentro do tempo limite do job.
Por padrão, o job "stage2-full-training" treina todos os testes em paralelo. Normalmente, são as 10 principais tentativas em paralelo. No entanto, se cada teste "stage2-full-training" usar muitas GPUs (por exemplo, oito GPUs cada) para o caso de uso, e você não tiver uma cota suficiente, poderá executar manualmente o "stage2". jobs em lotes, como primeiro executar um "stage2-full-training" para apenas cinco testes e depois executar outro "stage2-full-training" para os próximos cinco testes.
Tempo limite padrão do job
O tempo limite padrão do job NAS é definido como 14 dias e, depois disso, ele é cancelado. Se você pretende executar a vaga por mais tempo, tente retomá-la apenas mais uma vez por mais 14 dias. No geral, é possível executar um job de pesquisa por 28 dias, incluindo o currículo.
Máximo de configurações de testes com falha
O máximo de testes com falha precisa ser definido como 1/3 da configuração de max_nas_trial. O job será cancelado quando o número de testes com falha atingir esse limite.
Quando interromper a pesquisa
Você deve parar a pesquisa quando:
A curva de pesquisa começa a convergir (a variação é reduzida):
Observação: se nenhuma restrição de latência for usada ou se a restrição de latência
rígida for usada com limite de latência livre, a curva pode não mostrar um
aumento na recompensa, mas ainda mostrar a convergência. Isso ocorre porque
o controlador pode já ter visto boas precisões
no início da pesquisa.Mais de 20% dos seus testes têm recompensas inválidas (falhas):
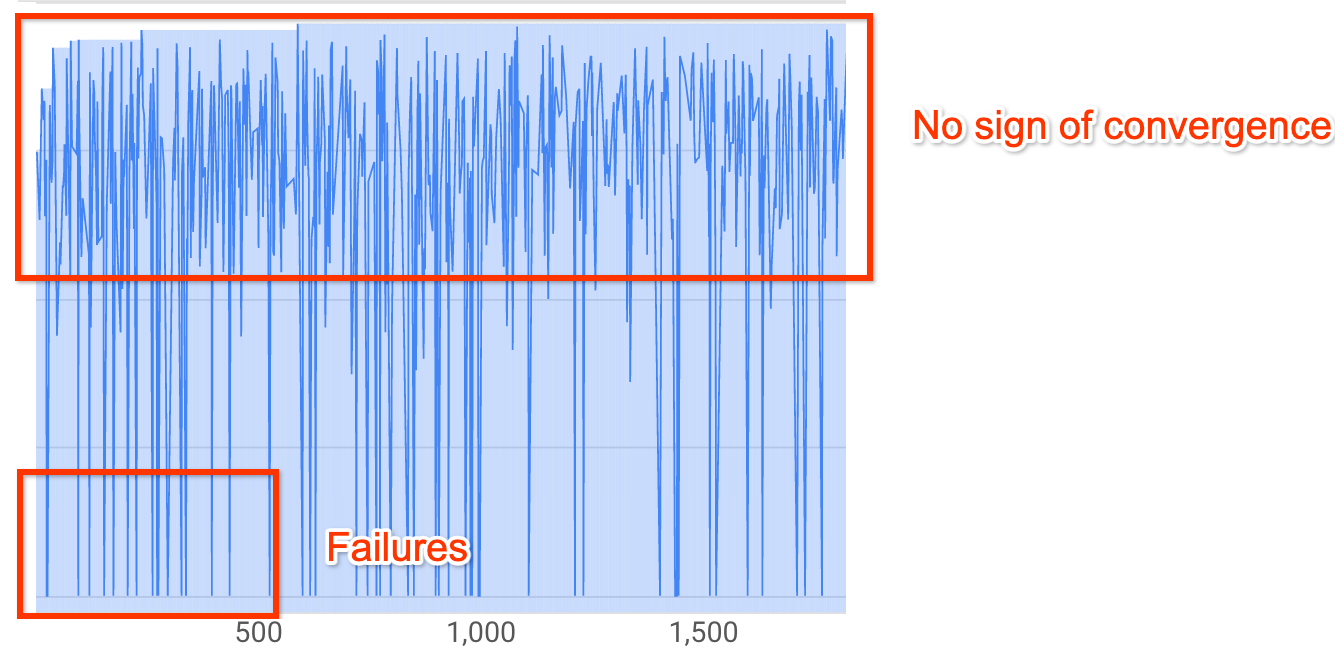
A curva de pesquisa não aumenta nem converge (conforme mostrado acima), mesmo após aproximadamente 500 testes. Se ela mostrar qualquer aumento na recompensa ou diminuição na variação, será possível continuar.