Configure um ambiente antes de iniciar um experimento de pesquisa neural da arquitetura da Vertex AI.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na gcloud CLI com sua identidade federada.
-
Para inicializar a gcloud CLI, execute o seguinte comando:
gcloud init -
Depois que a gcloud CLI é inicializada, ela precisa ser atualizada e os componentes necessários instalados:
gcloud components update gcloud components install beta
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na gcloud CLI com sua identidade federada.
-
Para inicializar a gcloud CLI, execute o seguinte comando:
gcloud init -
Depois que a gcloud CLI é inicializada, ela precisa ser atualizada e os componentes necessários instalados:
gcloud components update gcloud components install beta
- Para conceder a todos os usuários da pesquisa de arquitetura neural os papéis do usuário da Vertex AI (
roles/aiplatform.user), entre em contato com o administrador do projeto. - Instale o Docker.
Se você estiver usando um sistema operacional baseado em Linux, como Ubuntu ou Debian, adicione seu nome de usuário ao grupo
dockerpara executar o Docker sem usarsudo:sudo usermod -a -G docker ${USER}Talvez seja necessário reiniciar o sistema depois de adicionar você mesmo ao grupo
docker. - Abra o Docker. Para garantir que ele esteja funcionando, execute o comando a seguir, que retorna a hora e a data atuais:
docker run busybox date
- Use o
gcloudcomo auxiliar de credencial do Docker:gcloud auth configure-docker
- Opcional se você quer executar o contêiner por meio da GPU no local, instale o
nvidia-docker. -
Especifique um nome para o novo bucket. Ele precisa ser único em todos os buckets no Cloud Storage.
BUCKET_NAME="YOUR_BUCKET_NAME"
Por exemplo, use o nome do seu projeto com
-vertexai-nasanexado:PROJECT_ID="YOUR_PROJECT_ID" BUCKET_NAME=${PROJECT_ID}-vertexai-nas
-
Verifique o nome do bucket que você criou.
echo $BUCKET_NAME
-
Selecione a região do bucket e defina a variável de ambiente
REGION.Use a mesma região em que você planeja executar jobs de pesquisa de arquitetura neural.
Por exemplo, o código a seguir cria
REGIONe a define comous-central1:REGION=us-central1
-
Crie o novo bucket:
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
- Em Serviço, selecione API Vertex AI.
- Em região, selecione a região que você quer filtrar.
- Em Cota, selecione um nome de acelerador com o prefixo
Treinamento de modelo personalizado.
- Para GPUs V100, o valor é GPUs de treinamento personalizado do modelo Nvidia V100 por região.
- Para CPUs, o valor pode ser CPUs de treinamento de modelo personalizado para tipos de máquina
N1/E2 por região. O número da CPU representa a unidade de CPUs. Se você quiser 8 CPUs
highmem-16, faça sua solicitação de cota para 8 * 16 = 128 unidades de CPU. Insira também o valor região.
Configure as variáveis de ambiente básicas:
gcloud config set project PROJECT_ID gcloud auth login gcloud auth application-default loginConfigure a autenticação do docker para o registro de artefatos:
# example: REGION=europe-west4 gcloud auth configure-docker REGION-docker.pkg.dev(Opcional) Configure um ambiente virtual do Python 3. O uso do Python 3 é recomendado, mas não obrigatório:
sudo apt install python3-pip && \ pip3 install virtualenv && \ python3 -m venv --system-site-packages ~/./nas_venv && \ source ~/./nas_venv/bin/activateInstale outras bibliotecas:
pip install google-cloud-storage==2.6.0 pip install pyglove==0.1.0Crie uma conta de serviço:
gcloud iam service-accounts create NAME \ --description=DESCRIPTION \ --display-name=DISPLAY_NAMEAtribua os papéis
aiplatform.userestorage.objectAdminà conta de serviço:gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/aiplatform.user gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/storage.objectAdminAbra um novo terminal do shell.
Execute o comando clone do Git:
git clone https://github.com/google/vertex-ai-nas.git
Configurar o bucket do Cloud Storage
Nesta seção, demonstramos como criar um novo bucket. É possível usar um bucket atual, mas ele precisa estar na mesma região em que você planeja executar os jobs do AI Platform. Além disso, se ele não fizer parte do projeto que você está usando para executar a pesquisa de arquitetura neural, você precisará conceder acesso explicitamente às contas de serviço da pesquisa de arquitetura neural.
Solicitar cota de dispositivo adicional para o projeto
Os tutoriais usam aproximadamente cinco máquinas de CPU e não exigem mais cota. Depois de executar os tutoriais, execute o job de pesquisa de arquitetura neural.
O job de pesquisa de arquitetura neural treina um lote de modelos em paralelo. Cada modelo treinado corresponde a um teste.
Leia a seção sobre como definir a number-of-parallel-trials para estimar a quantidade de CPUs e GPUs necessárias para um job de pesquisa.
Por exemplo, se cada teste usar duas GPUs T4 e você definir number-of-parallel-trials como 20, será necessário uma cota total de 40 GPUs T4 para um job de pesquisa. Além disso, se cada teste estiver usando uma CPU highmem-16, você precisará de 16 unidades de CPU por teste, ou seja, 320 unidades de CPU para 20 testes em paralelo.
No entanto, pedimos no mínimo 10 cotas de teste paralelas (ou 20 cotas de GPU).
A cota inicial padrão de GPUs varia por região e tipo de GPU e costuma ser de 0, 6 ou 12 para Tesla_T4 e 0 ou 6 para Tesla_V100. A cota inicial padrão de CPUs varia por região e geralmente é 20, 450 ou 2.200.
Opcional: se você planeja executar vários jobs de pesquisa em paralelo, escalone o requisito de cota. Solicitar uma cota não cobra imediatamente. Você é cobrado depois de executar um job.
Se você não tiver cota suficiente e tentar iniciar um job que precise de mais recursos do que sua cota, o job não iniciará apresentando um erro semelhante a este:
Exception: Starting job failed: {'code': 429, 'message': 'The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd', 'status': 'RESOURCE_EXHAUSTED', 'details': [{'@type': 'type.googleapis.com/google.rpc.DebugInfo', 'detail': '[ORIGINAL ERROR] generic::resource_exhausted: com.google.cloud.ai.platform.common.errors.AiPlatformException: code=RESOURCE_EXHAUSTED, message=The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd, cause=null [google.rpc.error_details_ext] { code: 8 message: "The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd" }'}]}
Em alguns casos, se vários jobs para o mesmo projeto forem iniciados ao mesmo tempo e a cota não for suficiente para todos eles, um dos jobs permanecerá na fila e não iniciará o treinamento. Nesse caso, cancele o job na fila e solicite mais cota ou aguarde até que o job anterior seja concluído.
É possível solicitar a cota extra de dispositivo na página Cotas.
Também é possível aplicar filtros para encontrar a cota a ser editada:
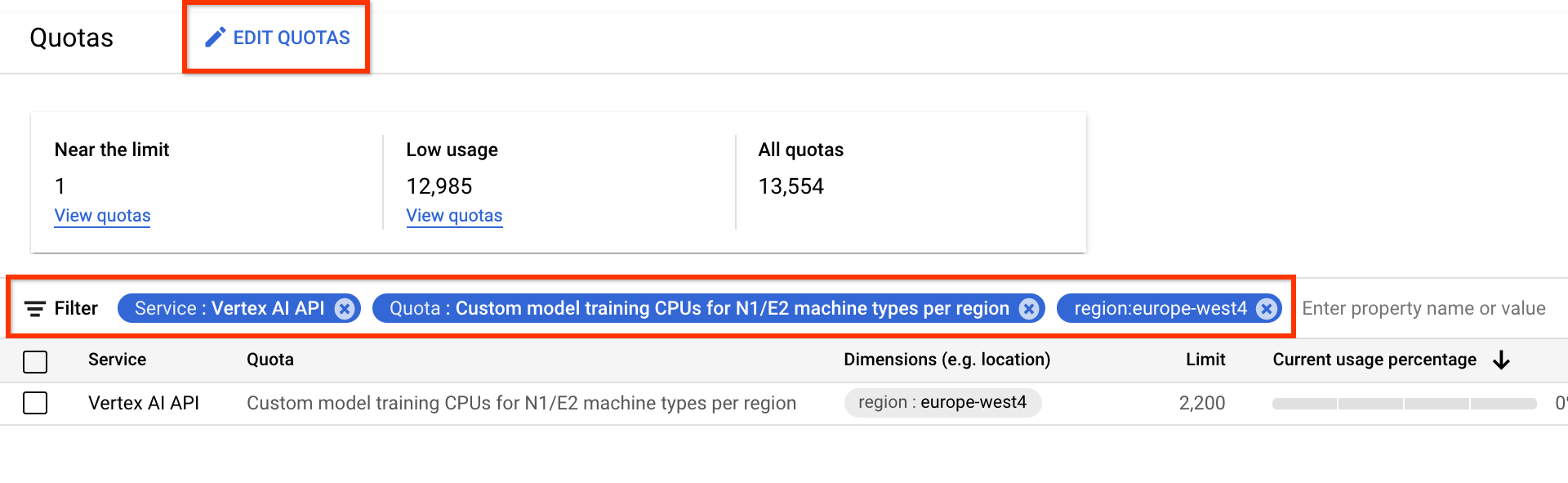
Depois de criar uma solicitação de cota, você recebe um Case number e acompanha e-mails sobre o status da sua solicitação. A aprovação de uma cota de GPU pode levar de dois a cinco dias úteis para ser aprovada. Em geral, a obtenção de uma cota de aproximadamente 20 a 30 GPUs deve ser mais rápida para ser aprovada em aproximadamente dois a três dias, e a aprovação para aproximadamente 100 GPUs pode levar cinco dias úteis. Uma aprovação de cota de CPU pode levar até dois dias úteis para ser aprovada.
No entanto, se uma região estiver passando por uma grande escassez de um tipo de GPU,
não haverá garantia, mesmo com uma pequena solicitação de cota.
Nesse caso, talvez seja solicitado que você escolha uma região ou um tipo de GPU diferente. Em geral, as GPUs T4 são mais fáceis de conseguir do que a V100s. As GPUs T4 levam mais tempo, mas são mais econômicas.
Para mais informações, consulte Solicitar um ajuste de cota.
Configurar o Artifact Registry para seu projeto
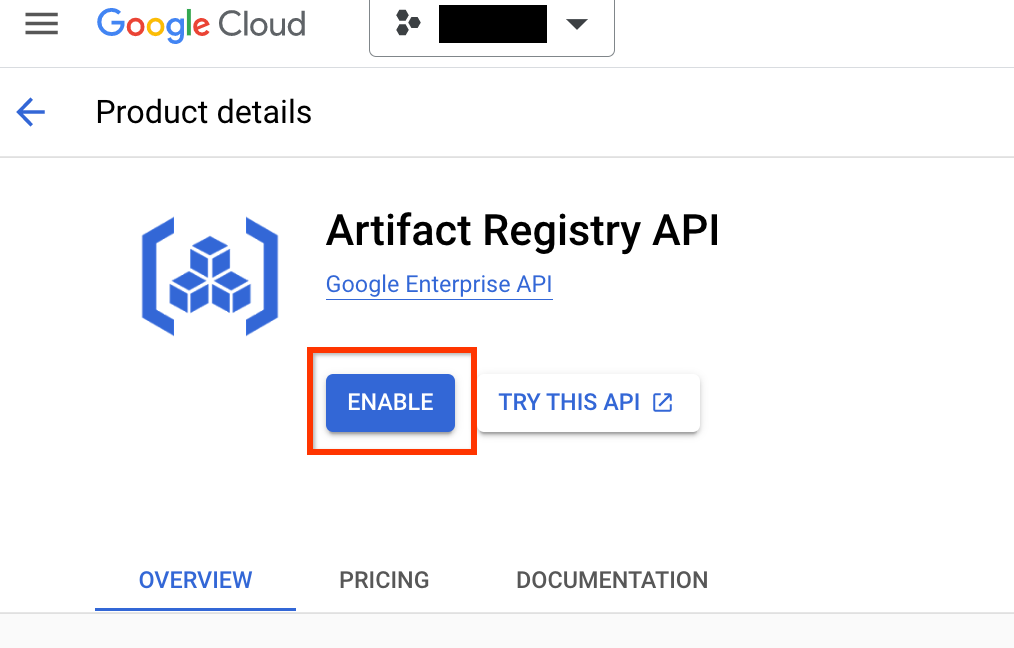
É necessário configurar um registro de artefatos para o projeto e a região em que você envia as imagens do Docker.
Acesse a página do Artifact Registry do projeto. Primeiro, ative a API Artifact Registry para seu projeto:
Depois de ativar, comece a criar um novo repositório clicando em CRIAR REPOSITÓRIO:
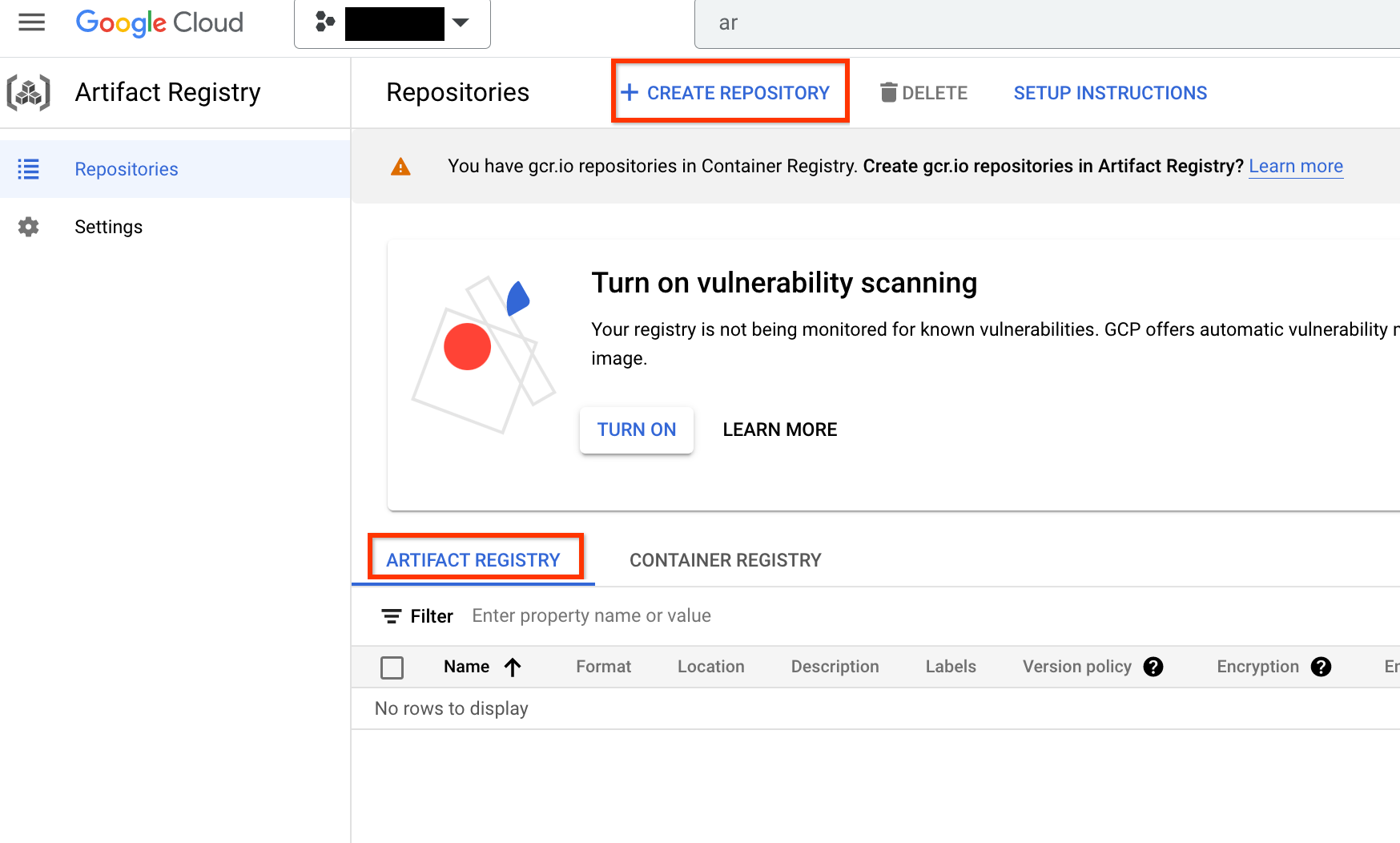
Escolha Nome como nas, Formato como Docker e Tipo de local. como Region. Em Região, selecione o local em que os jobs são executados e clique em CRIAR.
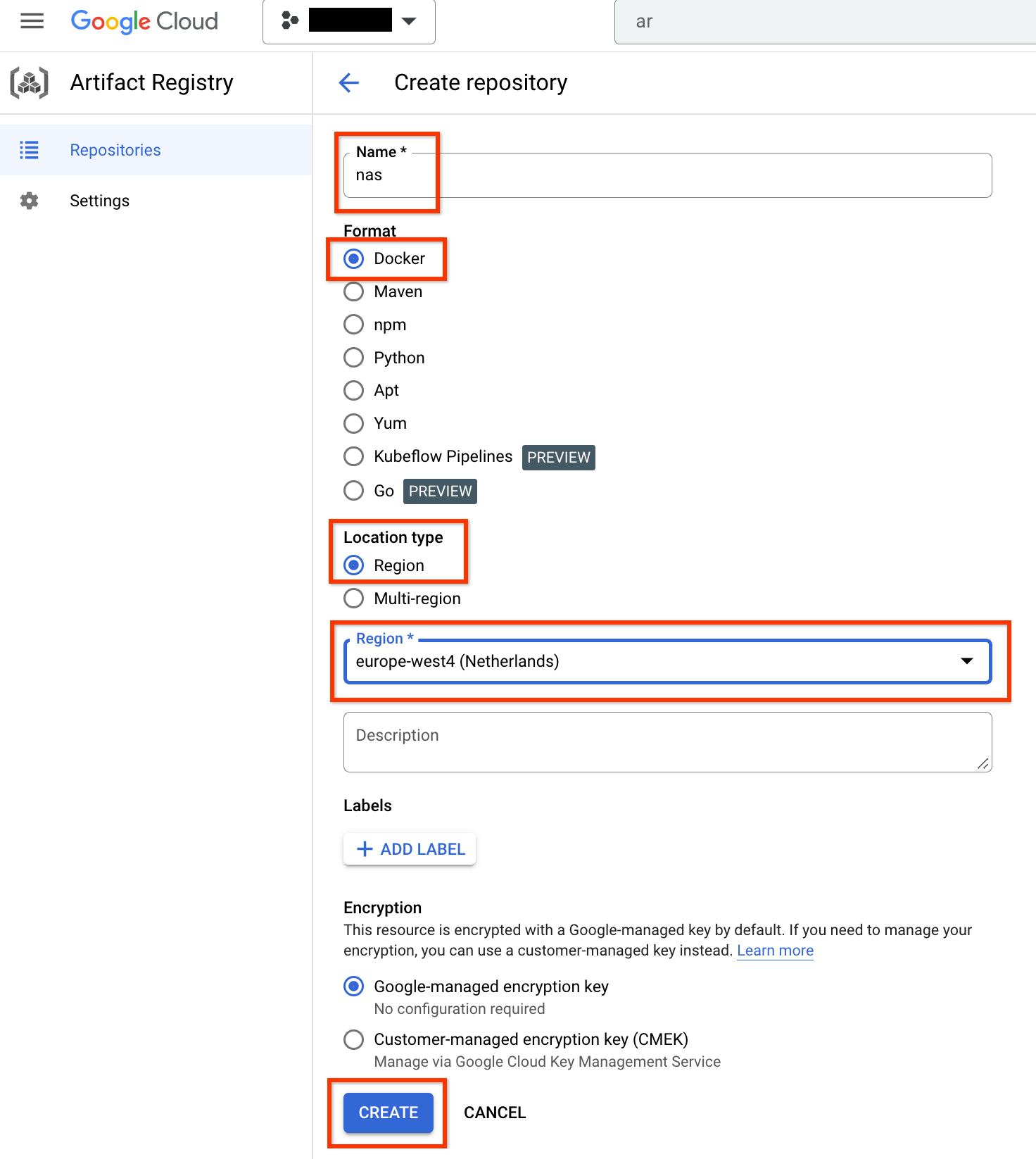
Isso criará o repositório do Docker desejado, como mostrado abaixo:
Você também precisa configurar a autenticação para enviar Dockers para esse repositório. A seção de configuração do ambiente local abaixo contém essa etapa.
Configurar seu ambiente local
É possível executar essas etapas usando o shell do Bash no ambiente local ou em um notebook em uma instância do Vertex AI Workbench.
Configurar uma conta de serviço
É necessário configurar uma conta de serviço antes de executar jobs do NAS. É possível executar essas etapas usando o shell do Bash no ambiente local ou em um notebook em uma instância do Vertex AI Workbench.
Por exemplo, os comandos a seguir criam uma conta de serviço chamada my-nas-sa no projeto my-nas-project com os papéis aiplatform.user e storage.objectAdmin:
gcloud iam service-accounts create my-nas-sa \
--description="Service account for NAS" \
--display-name="NAS service account"
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/aiplatform.user
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/storage.objectAdmin
Baixar o código
Para iniciar um experimento de pesquisa de arquitetura neural, você precisa fazer o download do código Python de amostra, que inclui treinadores pré-criados, definições de espaço de pesquisa e as bibliotecas de cliente associadas.
Execute as etapas a seguir para fazer o download do código-fonte.